Dans un blog précédent, nous avons démontré l’importance d’adopter les principes d’éthique by design dans les projets d’intelligence artificielle dans le secteur public. Bien qu’il existe de nombreuses directives et guidances, il n’est pas toujours facile de les mettre en pratique. Les difficultés de la mise en œuvre des principes d’éthiques découlent, entre autres, de :
- la complexité croissante des algorithmes qui les rend difficilement “compréhensibles”
- la nécessité de garder certaines informations cachées tout en restant transparent
- la définition des responsabilités
- la difficulté de trouver les outils techniques appropriés
Des directives telles que le RGPD sont vues par certains praticiens comme trop contraignantes et de nombreuses recherches sont en cours pour trouver un juste équilibre entre innovation, protection des données et régulation des algorithmes.
Le but de ce blog n’est pas de fournir une description complète des méthodologies et technologies à adopter pour une IA éthique mais plutôt de décrire quelques bonnes pratiques et outils qui permettent d’intégrer l’éthique dans un projet d’IA.
L’explicabilité des algorithmes décisionnels (XAI)
L’utilisation d’algorithmes décisionnels implique que, conformément au RGPD, toute décision prise de façon automatique avec des données personnelles soit expliquée. Un humain doit pouvoir expliquer la logique qui sous-tend la décision, dire quelles données ont été utilisées et déterminer s’il y a eu erreur ou pas. Cependant, l’explicabilité des algorithmes n’est pas facile à mettre en place dans la pratique soit pour des raisons techniques comme c’est le cas des algorithmes dits black-box, soit pour des questions d’IP ou de non-divulgation des détails du développement de l’algorithme pour des raisons de sécurité. Néanmoins comme suggéré dans cet article “Counterfactual explanations without opening the black box: automated decisions and the GDPR“, plutôt que de se focaliser sur la simple compréhension de l’algorithme, les explications doivent pouvoir donner au sujet dont les données sont collectées et évaluées les moyens d’agir. Les auteurs de l’article proposent trois objectifs à atteindre sans avoir à ouvrir la ‘boîte noire’, en se basant sur des méthodes d’analyse contrefactuelle. Ces objectifs consistent à:
- informer et aider le sujet à comprendre pourquoi une décision particulière a été prise
- fournir au sujet les éléments qui permettent de contester une décision
- comprendre ce qui pourrait être altérer pour obtenir un résultat souhaité (favorable)
Les approches décrites ci-dessous sont les plus couramment utilisées pour l’explicabilité des algorithmes. Celles-ci sont disponibles sur la plupart des plateformes de big data et machine learning ainsi qu’en open source :
- LIME – Local Interpretable Model-Agnostic Explanations. Le principe consiste à approximer un modèle complexe de type black-box par un modèle local simple et facilement interprétable, obtenu en perturbant légèrement le point pour lequel on fait une prédiction. L’explication locale ainsi générée est une approximation propre à une région du modèle et ne peut être généralisée.
- SHAP – SHapley Additive exPlanations. Cette méthode donne une idée de la contribution de chaque variable indépendante à la prédiction en comparant les prédictions du modèle avec et sans cette variable. Comparée à la méthode LIME, la méthode SHAP permet d’obtenir une explication globale en plus d’une explication locale. La contribution des différentes variables au modèle global est calculée en moyennant les valeurs SHAP locales pour tous les points.
- PD-ICE plot (Partial Dependence – Individual Conditional Expectation). Le graphe PD illustre la dépendance entre un nombre limité de variables et le résultat d’inférence basés sur les prédictions faites sur un set de données. Quant au graphe ICE, il représente la dépendance entre quelques variables et le résultat d’inférence pour une donnée prise individuellement.
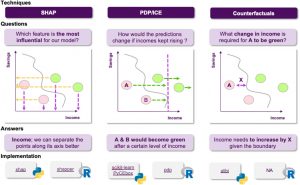
Comparaison entre les méthodes LIME, PD-ICE et contrefactuelle. Chacune des méthodes répond à une question différente (source: https://www.frontiersin.org/articles/10.3389/fdata.2021.688969/full)

Il existe en plus des méthodes LIME et SHAP, une méthode d’analyse contrefactuelle type « what-if » qui est l’objet de nombreuses recherches récentes. Son implémentation est disponible en open source via la librairie Python DiCE. Le principe de l’analyse contrefactuelle est de donner une idée sur ce qu’il faudrait faire pour modifier une décision. Cette méthode permet de comprendre les facteurs sur lesquels on peut agir pour changer le résultat de la prédiction.
La détection de biais
La collecte de données est une étape importante dans le développement d’un algorithme. Les données contiennent bien souvent des biais qui se reflètent sur les prédictions faites par le modèle. Il est possible de les détecter et d’y remédier en utilisant un mélange de bonnes pratiques et d’outils techniques.
Une première étape est de former en début de projet une équipe composée de data scientists, d’experts business et d’utilisateurs du système d’IA pour identifier selon le contexte les éléments (ex. le genre, le revenu salarial) susceptibles d’introduire des biais. L’équipe doit être variée et inclure si possible le groupe ciblé par les algorithmes.
Leurs efforts peuvent être soutenus par des outils dédiés à cet effet:
- AI Fairness 360. Cet outil open source développé dispose de nombreuses mesures qui permettent de détecter les biais ainsi que des algorithmes qui permettent de mitiger les biais. Ceux-ci s’appliquent à toutes les étapes du cycle de vie du modèle : à la préparation des données, à l’entrainement de l’algorithme et pendant l’inférence.
- What-if Tool de Google. C’est un outil de visualisation interactif pour l’analyse de modèles faisant parti de l’application TensorBoard. What-if est dédié à l’analyse contrefactuelle dont le principe est de comparer deux points similaires pour lesquels le modèle a donné des prédictions différentes.
- Fairlearn de Microsoft. Comme What-If Tool, FATE dispose d’un outil de visualisation interactif en plus d’algorithmes de mitigation.
Une fois le modèle développé, il est préférable de le faire auditer par une équipe externe. Une façon d’évaluer le modèle est de comparer les données qui entrent dans le système (ex. CV pour des groupes susceptibles d’être discriminés) et les résultats qui en découlent.
Enfin il est important d’instaurer une stratégie de suivi et contrôle du modèle, d’identifier les métriques à surveiller (quand estime-t-on qu’il y a un biais ?) et les mesures à prendre en cas d’introduction de biais.
Gouvernance de modèles et monitoring
Une IA éthique et conforme c’est aussi une gouvernance de modèles transparente et documentée. Une bonne gouvernance doit garantir que les lois et régulations en matière de protection de données et utilisation d’algorithmes décisionnels sont respectées. Cela passe par le maintien d’un catalogue documenté de modèles et des données utilisées pour leurs développements, l’enregistrement des métriques et métadonnées relatives aux modèles, la gestion des accès aux modèles et l’implémentation d’un cycle d’approbation à différentes étapes du développement. Pour cela, on peut s’appuyer sur des plateformes type mlops commerciales ou open source. Généralement, les plateformes open source ne proposent pas une gouvernance complète et il est souvent nécessaire de les combiner avec d’autres outils. Les plateformes open source les plus couramment utilisées sont MLFlow et KubeFlow. Notons aussi des outils commerciaux tels que Algorithmia ou Valohia qui sont spécialisés dans la gouvernance de modèles.
En plus des éléments décrits ci-dessus, il est important pour une bonne gouvernance de monitorer les modèles car tout modèle se dégrade au fil du temps et perd en robustesse. Soit parce que la nature des données a changée (data drift) ou parce que le contexte a changé et la relation (captée par le modèle ) entre les données et la prédiction a changé (concept drift). On retrouve pour le monitoring des outils commerciaux tels que :
- Qualdo spécialisé dans le data quality et le monitoring des données,
- Fiddler AI pour le monitoring et le XAI
- la librairie open source Evidently AI qui propose un monitoring de base
Gestion des modèles avec la librairie MLFlow
Conclusions
L’éthique est devenu un sujet de recherche important dans l’industrie de l’IA, l’adoption de directives telles que le RGPD pousse les acteurs à adopter de nouveaux standards en matière d’éthique. Dans cet article, nous avons présenté quelques outils utiles à l’adoption de l’éthique dans les projets d’IA. Cependant, ils ne disent pas quel est l’impact d’un algorithme sur la société et comment le mesurer. Au commencement de tout projet d’IA, une réflexion de fond est nécessaire pour identifier les effets potentiellement délétères d’un algorithme sur la société et définir les objectifs qu’on se fixe pour les mitiger, les outils techniques sont alors des moyens parmi d’autres d’atteindre ces objectifs.
_________________________
Ce post est une contribution individuelle de Katy Fokou, spécialisée en intelligence artificielle chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.
Leave a Reply