Cet article fait suite à une première partie qui s’est penchée sur la sécurité du code généré par les outils d’IA générative (IAGén). Dans cette seconde partie, nous considérons la tâche de détecter des vulnérabilités dans du code existant et comment l’IAGén pourrait peut-être aider.
Les vulnérabilités de sécurité dans le code sont un problème récurrent affectant la plupart des logiciels et ayant un impact sur l’intégrité, la confidentialité et la disponibilité. L’utilisation de certains langages de programmation connus pour être moins susceptibles que d’autres à des problèmes classiques est recommandée (par exemple Rust plutôt que C). L’examen du code par d’autres programmeurs experts est aussi une méthode largement répandue. Mais l’IAGén pourrait-elle faciliter la tâche ?
Recherche de vulnérabilités
Il existe plusieurs façons de rechercher des vulnérabilités à partir du code ou du binaire et ce, de manière automatique ou manuelle, statique ou dynamique, et systématique ou exploratoire. En 2022, dans une étude très détaillée, Elder et al. [1] ont comparé plusieurs de ces méthodes sur une application d’ampleur dans le domaine médical : OpenMRS. Celle-ci contient près de 4 millions de lignes de code Java et JavaScript. Les auteurs font plusieurs recommandations en fonction des objectifs recherchés et des ressources (expertise, temps, équipement) disponibles et confirment une étude plus ancienne : chaque méthode de détection de vulnérabilité trouve des vulnérabilités qui n’ont pas été trouvées par d’autres méthodes. Cependant, dans leur expérimentation, la méthode manuelle exploratoire par tests d’intrusion a permis de trouver les vulnérabilités les plus dangereuses.
IAGén et analyse statique
Le Tableau 1 compare deux approches d’analyse de code : l’analyse statique (classique) et une analyse utilisant une IAGén. Selon certaines études, l’IAGén aurait commencé à montrer quelques avantages par rapport aux outils d’analyse statiques classiques.
Tableau 1 – Aperçu des principales différences et similitudes entre deux approches d’analyse du code : analyse statique et analyse avec IAGén (d’après [2]).
| Critère | Analyse statique « classique » | Analyse avec IA générative |
|---|---|---|
| Objectif et conception | Identifier les vulnérabilités de sécurité connues dans le code | Comprendre et générer un texte de type humain, y compris du code informatique |
| Représentation du code | Arbres syntaxiques abstraits ou graphes de flux de contrôle | Code comme séquences de jetons |
| Apprentissage et adaptation | Utilisation de règles et de signatures prédéfinies ; pas « d’apprentissage » traditionnel | « Apprentissage » continu à partir de données d’entraînement ; adaptation en fonction des modèles observés |
| Généralisation | Précis et spécifique ; basé sur des modèles/signatures connus | Peut généraliser les différents modèles/styles de codage |
| Retour d’information et itération | Retour d’information déterministe basé sur la correspondance des règles | Retour d’information contextuel et descriptif |
| Couverture des vulnérabilités | Limitée à un ensemble de règles/signatures prédéfinies | Potentiellement plus large en raison de la formation généralisée, mais peut manquer de précision |
| Base de fonctionnement | Règles | Reconnaissance des motifs basée sur des données d’entraînement |
| Adaptabilité | Fixe à moins que les règles ne soient mises à jour | Flexible en raison des capacités de reconnaissance des motifs |
Par exemple, Noever [2] a étudié la performance de certaines IAGén pour identifier et rectifier des vulnérabilités dans des logiciels. Son étude portait sur divers dépôts de GitHub et comparait les IAGén avec des outils d’analyse statique. L’auteur a utilisé la requête (« prompt » en anglais) suivante :
“Act as the world’s greatest static code analyzer for all major programming languages. I will give you a code snippet, and you will analyze the code and rewrite it, removing any identified vulnerabilities. Do not explain, just return the corrected code and format alone.”
Les tests de l’auteur utilisent le cycle suivant pour une base de code donnée :
- Utiliser un outil d’analyse statique pour évaluer le nombre et le niveau de gravité des vulnérabilités ;
- Demander à l’IAGén d’identifier les vulnérabilités ;
- Demander à l’IAGén de corriger les vulnérabilités trouvées ;
- Utiliser l’outil d’analyse statique sur le code corrigé et comparer le nombre et le niveau de gravité des vulnérabilités trouvées.
Les résultats de l’auteur sont plutôt positifs sur la base de code choisie : l’IAGén a permis de réduire de manière significative le nombre de vulnérabilités très graves.
Performance de l’IAGén
Cependant, même les meilleurs outils utilisant l’IA pour la détection de défauts ont une précision inférieure à 70 % selon CodeXGLUE. Une étude de Steenhoek [3] rapporte que les modèles de pointe n’ont obtenu qu’une précision équilibrée de 54,5 %1 dans leur évaluation de la détection des vulnérabilités, même pour les modèles pré-entraînés sur de grandes quantités de code source. En d’autres termes, « tous les modèles et toutes les requêtes ont donné des résultats proches de ceux des réponses aléatoires aux devinettes. » Les auteurs expliquent cela par la difficulté qu’ont les IAGén à raisonner sur la sémantique du code. Cette difficulté de raisonnement ne se limite d’ailleurs pas au code [3].
Nous avions déjà pu remarquer quelque chose de similaire lors de nos propres tests sur une base de code avec des vulnérabilités de type CWE connues : le nombre de faux-positifs2 était souvent aussi important que le nombre de vrai-positifs3 lorsque nous avons demandé à différents modèles (gpt-40-mini, gpt-4o, mistral-large-2411, Llama-4-Scout, DeepSeek-V3, Qwen2.5) d’indiquer si un fichier de code contenait des vulnérabilités potentielles. Même en envoyant une base de code entière nos résultats n’ont pas été plus concluants. En effet, Llama permet de fournir un contexte très large (10 millions de symboles), et après lui avoir fourni l’entièreté de WebGoat – un logiciel spécialement écrit avec des vulnérabilités – aucune vulnérabilité significative n’a été identifiée !
Dans une étude plus récente et plus systématique, Ullah et al. [4] montrent – en utilisant 8 modèles et 17 méthodes de requête sur 228 exemples de code – que les IAGén fournissent des réponses non déterministes, un raisonnement incorrect et infidèle, et qu’elles sont peu performantes dans des scénarios du « monde réel ». Plus grave, l’étude confirme aussi un manque de robustesse lors de la détection de vulnérabilités potentielles. De nombreuses études avaient déjà souligné que les techniques d’apprentissage automatique manquaient de robustesse aux transformations de code préservant la sémantique comme le renommage d’identifiants, l’insertion de déclarations non exécutées ou encore le remplacement de code par du code équivalent [5]. Sans grande surprise, les méthodes d’amplifications permettant à un modèle d’apprendre ce type de transformations, ne permettent d’augmenter la robustesse que pour les transformations spécifiques auxquelles le modèle a été entrainé [5].
Dans un autre exemple, plus anecdotique, Heelan [6] discute de la capacité de ChatGPT-o3 à trouver la vulnérabilité CVE-2025-37778 dans le noyau de Linux. Outre le fait que la requête envoyée par l’auteur à l’IAGén était très précise (extrait de code soigneusement sélectionné, instructions détaillées), l’IAGén n’a trouvé la vulnérabilité que 8 fois sur 100 (la même requête a été envoyée 100 fois, et seulement 8 fois l’IAGén a trouvé la vulnérabilité). Dans un autre exemple l’auteur décrit comment, par hasard, l’IAGén lui a permis de découvrir une nouvelle vulnérabilité ; là encore il a envoyé cent fois sa requête à ChatGPT et, dans une seule réponse, il a trouvé un élément le mettant sur la voie. C’est sans compter le coût environnemental et financier de l’exercice et surtout le fait que la nouvelle vulnérabilité est liée sémantiquement à la précédente.
Dès lors, on ne s’étonnera pas que l’expérience de plusieurs projets de logiciels libres tend à montrer que les bogues découverts avec l’aide de l’IAGén ont en réalité peu de valeur [7], [8].
Intégration de l’IAGén dans l’analyse statique
Afin d’améliorer la détection de vulnérabilités par une IAGén dans un échantillon de code, Yue Li et al. [9] suggèrent de rassembler le plus d’informations contextuelles possibles (p. ex., liste de dépendances et informations spécifiques à un type de vulnérabilité recherché). C’est ce qui est mis en pratique dans l’outil IRIS de Ziyang Li et al. [10].
IRIS combine l’IAGén avec l’analyse statique pour détecter les vulnérabilités de sécurité dans les logiciels tout en essayant de réduire le taux de faux positifs. Cet outil suit un processus systématique de détection des failles de sécurité :
- Extraction de candidats potentiels pour être des sources ou des récepteurs contaminés dans les interfaces de programmation externes et internes grâce à un outil d’analyse statique.
- Interrogation d’une IAGén pour étiqueter en tant que source ou puit (fonction vulnérable) spécifique à une classe de vulnérabilité4, les interfaces candidates.
- Les sources et les puits étiquetés sont transformés en spécifications qui peuvent être introduites dans CodeQL afin d’effectuer une analyse des souillures (les variables entachées par des entrées de l’utilisateur et pouvant atteindre un puit) spécifique à une classe de vulnérabilité. Cette étape génère un ensemble de chemins de code vulnérables (ou alertes) dans le projet.
- Enfin l’IAGén est utilisée pour réduire le nombre de faux-positifs signalés par l’analyse statique de CodeQL tout en fournissant une explication.
Nos tests de l’outil IRIS-v15, sur la base de code WebGoat avec les modèles Codegen25-7b-instruct, qwen2.5-coder-7b et GPT-4 ont pu confirmer une réduction d’environ 18 % du nombre de vulnérabilités potentielles détectées, mais ce, au prix d’un grand nombre d’appels au modèle d’IAGen (1130 appels par type de CWE testé, pour une base de 259 fichiers Java).
Cet outil encore expérimental montre néanmoins une tendance plus générale de l’introduction de l’IAGén dans les outils de détection existants. C’est le cas, par exemple, de DeepCode, d’ETH Zurich, récemment intégré dans le logiciel Snyk. Il a pour ambition de permettre aux programmeurs de trouver rapidement des vulnérabilités dans leur code. Mais la convergence d’outils d’IAGén examinant du code généré par d’autres outils d’IAGén, crée des boucles de rétroaction qui pourraient s’avérer dangereuses [11].
Conclusion et recommandations
Même si quelques études ont montré que les IAGén peuvent résoudre des problèmes simples de correction de vulnérabilités (par exemple, des fuites de mémoire), on constate qu’ils rencontrent des difficultés à résoudre des défauts complexes. La plupart des études que nous avons rencontrées montrent aussi des performances incohérentes et une tendance générale à des taux élevés de faux-positifs, dans la détection des failles de sécurité, confirmant nos propres tests. Les meilleures performances de détection semblent être atteintes sur les vulnérabilités pour lesquelles les IAGén ont été entraînées. Ces observations sont confirmées par une étude systématique et extensive de Basic et Giaretta [12].
Par conséquent, avant de pouvoir utiliser l’IAGén pour la détection de vulnérabilité dans le code, il faudra attendre que des progrès importants soient faits. Pour le moment, il faut prendre conscience des limites actuelles de ces outils. Outre celles mentionnées précédemment, quelle que soit la méthode retenue, de nombreux appels à l’IAGén peuvent s’avérer être très coûteux (ou très lents s’ils sont exécutés localement sans matériel adéquat). De plus il manque encore une méthodologie scientifique solide permettant de comparer efficacement différents outils d’analyse et de mesurer l’apport objectif de l’IAGén.
Chez SMALS, par exemple, une initiative issue du fruit d’une collaboration (groupe de travail « SAST6 ») entre l’équipe de développement des applications & projets et celle de recherche travaille sur la performance des outils d’analyse statique et l’apport possible de l’IAGén.
Enfin, on note que CodeQL est repris par beaucoup d’études comme une base de référence pour la comparaison de l’efficacité des modèles d’IAGén à détecter des vulnérabilités. Cela n’est pas étonnant car des outils comme celui-ci ont fait leur preuve. Alors avant de se lancer tête baissée dans l’utilisation de l’IAGén pour améliorer la sécurité du code, il est probablement plus sage d’intégrer progressivement dans les indispensables revues de code habituelles, des outils d’analyse statique ou dynamique. Nul doute qu’une IAGén sera intégrée à ces outils au moment opportun.
Références
[1] S. Elder et al., « Do I really need all this work to find vulnerabilities? An empirical case study comparing vulnerability detection techniques on a Java application », 2 août 2022, arXiv: arXiv:2208.01595. doi: 10.48550/arXiv.2208.01595.
[2] D. Noever, « Can large language models find and fix vulnerable software? », août 2023, [En ligne]. Disponible sur: https://arxiv.org/abs/2308.10345
[3] P. Shojaee, I. Mirzadeh, K. Alizadeh, M. Horton, S. Bengio, et M. Farajtabar, « The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity », [En ligne]. Disponible sur: https://arxiv.org/abs/2506.06941
[4] S. Ullah, M. Han, S. Pujar, H. Pearce, A. Coskun, et G. Stringhini, « LLMs cannot reliably identify and reason about security vulnerabilities (yet?): A comprehensive evaluation, framework, and benchmarks », 24 juillet 2024, arXiv: arXiv:2312.12575. doi: 10.48550/arXiv.2312.12575.
[5] N. Risse et M. Böhme, « Uncovering the limits of machine learning for automatic vulnerability detection », 6 juin 2024, arXiv: arXiv:2306.17193. doi: 10.48550/arXiv.2306.17193.
[6] S. Heelan, « How I used o3 to find CVE-2025-37899, a remote zeroday vulnerability in the Linux kernel’s SMB implementation », Sean Heelan’s Blog. Consulté le: 12 juin 2025. [En ligne]. Disponible sur: https://sean.heelan.io/2025/05/22/how-i-used-o3-to-find-cve-2025-37899-a-remote-zeroday-vulnerability-in-the-linux-kernels-smb-implementation/
[7] T. Claburn, « AI-assisted bug reports make developers bear cost of cleanup », The Register. Consulté le: 14 mai 2025. [En ligne]. Disponible sur: https://www.theregister.com/2024/01/04/aiassisted_bug_reports_make_developers/
[8] C. Jones, « Curl takes action against time-wasting AI bug reports », The Register. Consulté le: 14 mai 2025. [En ligne]. Disponible sur: https://www.theregister.com/2025/05/07/curl_ai_bug_reports/
[9] Y. Li et al., « Everything you wanted to know about LLM-based vulnerability detection but were afraid to ask », 18 avril 2025, arXiv: arXiv:2504.13474. doi: 10.48550/arXiv.2504.13474.
[10] Z. Li, S. Dutta, et M. Naik, « IRIS: LLM-assisted static analysis for detecting security vulnerabilities », 6 avril 2025, arXiv: arXiv:2405.17238. doi: 10.48550/arXiv.2405.17238.
[11] S. Varma, A. Batchu, et N. Tyagi, « Innovation insight: AI code review tools », Gartner, G00834019, juill. 2025.
[12] E. Basic et A. Giaretta, « Large language models and code security: A systematic literature review », 19 décembre 2024, arXiv: arXiv:2412.15004. doi: 10.48550/arXiv.2412.15004.
1 Les auteurs préfèrent le score de précision équilibrée (« balanced accuracy ») au score classique F1 afin de mieux prémunir des biais potentiels du modèle évalué. Il est défini comme :
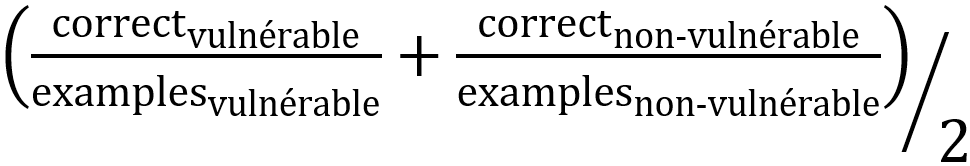
2 Code déclaré contenant une vulnérabilité alors qu’il n’en contient pas.
3 Code correctement déclaré comme contenant une vulnérabilité.
4 Actuellement, IRIS ne prend en charge que les CWE suivants : CWE-022 (Traversée de chemin), CWE-078 (injection de commande du système d’exploitation), CWE-079 (Script inter-site) et CWE-094 (injection de code).
5 La version 2 a été publiée après l’écriture de cet article.
6 « Static application security testing »