 Le Plan de recherche 2019 a été approuvé au conseil d’administration de Smals du 13 mars dernier. Pour cette année, nous avons décidé de mettre l’accent sur quatre axes : Security & Privacy, Artificial Intelligence, Analytics et Resilience. Le research radar 2019 a ici servi de point de départ.
Le Plan de recherche 2019 a été approuvé au conseil d’administration de Smals du 13 mars dernier. Pour cette année, nous avons décidé de mettre l’accent sur quatre axes : Security & Privacy, Artificial Intelligence, Analytics et Resilience. Le research radar 2019 a ici servi de point de départ.
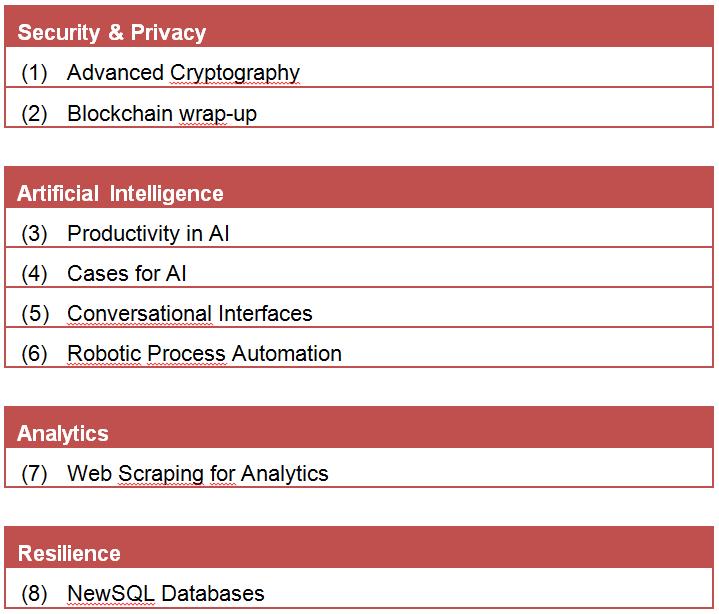
Les études proposées doivent nous permettre de tâter des opportunités pour Smals et les clients ainsi que de développer les études menées dans le passé, de manière à offrir une valeur ajoutée concrète. Une attention particulière est accordée à l’adoption des technologies et concepts que nous proposons.
Advanced Cryptography
La cryptographie est connue depuis des décennies pour ses trois éléments constitutifs : l’authentification forte, le chiffrement des données (confidentialité) et l’apposition et la vérification de signatures numériques (intégrité). La cryptographie est par ailleurs un domaine en pleine évolution, qui offre souvent des possibilités inédites et autorise même des choses qui semblent intuitivement impossibles. Aussi est-il intéressant de voir ce que la cryptographie a de plus à offrir que les trois fondements rudimentaires susmentionnés, mais aussi de vérifier comment elle peut être appliquée concrètement dans la sécurité sociale et les soins de santé en vue d’une meilleure protection des données et de la vie privée.
 L’étude “Advanced Cryptography” doit nous permettre d’examiner quels outils cryptographiques avancés existent et dans quelle mesure ils sont concrètement applicables. Une partie de l’étude consiste à trouver de bons cas. Au moins un cas concret sera élaboré dans la mesure du possible sous forme de preuve de concept.
L’étude “Advanced Cryptography” doit nous permettre d’examiner quels outils cryptographiques avancés existent et dans quelle mesure ils sont concrètement applicables. Une partie de l’étude consiste à trouver de bons cas. Au moins un cas concret sera élaboré dans la mesure du possible sous forme de preuve de concept.
Blockchain wrap-up
Ces dernières années, nous avons assisté à un énorme battage médiatique autour de la monnaie virtuelle et de la blockchain, même si peu d’applications opérationnelles concrètes et utiles sont apparues en même temps. La contribution de Smals Research au cours de la période écoulée fut double. D’une part, nous avons découragé les institutions membres d’investir dans des projets blockchain inutiles. D’autre part, nous sommes parvenus à détecter et à élaborer un cas d’utilisation utile, à savoir le “Service de démontrabilité BeSure“, sous la forme d’une analyse approfondie et d’une preuve de concept. Enfin, Smals Research a le mérite d’avoir toujours gardé une vision réaliste de la technologie, en dépit de l’engouement massif qu’elle suscite, ce qui lui a donné une solide autorité.
 Pour 2019, Smals Research ne prendra pas de nouvelles initiatives dans le domaine de la blockchain, mais entretiendra ses connaissances afin de pouvoir prodiguer des conseils et, en cas d’approbation, offrira son soutien pour opérationnaliser BeSure. Nous continuerons à participer à la Beltug Blockchain Task Force et au projet Validata.
Pour 2019, Smals Research ne prendra pas de nouvelles initiatives dans le domaine de la blockchain, mais entretiendra ses connaissances afin de pouvoir prodiguer des conseils et, en cas d’approbation, offrira son soutien pour opérationnaliser BeSure. Nous continuerons à participer à la Beltug Blockchain Task Force et au projet Validata.
Productivity in AI
 Le projet d’étude “Exploration of AI” de l’année dernière a permis à l’équipe de recherche d’acquérir les connaissances de base nécessaires dans le domaine de l’intelligence artificielle et du machine learning. Divers experiments ont été réalisés dans ce cadre. Il s’est avéré que l’intelligence artificielle est plus qu’une tendance et qu’il existe clairement des possibilités d’appliquer des techniques de machine learning dans un contexte administratif, notamment chez les membres de Smals.
Le projet d’étude “Exploration of AI” de l’année dernière a permis à l’équipe de recherche d’acquérir les connaissances de base nécessaires dans le domaine de l’intelligence artificielle et du machine learning. Divers experiments ont été réalisés dans ce cadre. Il s’est avéré que l’intelligence artificielle est plus qu’une tendance et qu’il existe clairement des possibilités d’appliquer des techniques de machine learning dans un contexte administratif, notamment chez les membres de Smals.
L’étude “Productivity in AI” vise à examiner les outils, plateformes et services invoquables (API) qui permettraient d’élaborer plus rapidement des solutions d’intelligence artificielle. En d’autres termes, une meilleure approche pour pouvoir fournir des résultats plus rapidement. L’accent sera mis sur la recherche de possibilités en vue de renforcer les capacités des membres de l’équipe de recherche en matière d’intelligence artificielle.
Cases for AI
L’année dernière, l’équipe de recherche s’est familiarisée avec diverses techniques de base de machine learning/deep learning et de NLP (Natural Language Processing). En ce qui concerne le NLP, diverses expériences ont pu être réalisées en matière de clustering, de classification de documents, d’entity recognition et d’entity linking sur la base de données réelles non structurées (textes). En ce qui concerne les données structurées, nous avons également mené une vaste expérience permettant de comparer les techniques du machine learning traditionnel avec le populaire et “nouveau” deep learning.
 L’étude “AI Cases” a pour but d’identifier des cas pertinents (réalisables) et d’y appliquer les techniques d’IA les plus pertinentes, en vue de leur implémentation ultérieure. Dans ce cadre, nous allons non seulement nous pencher sur le back-office, mais aussi nous concentrer sur l’utilisation parmi des services qui s’adressent directement au public.
L’étude “AI Cases” a pour but d’identifier des cas pertinents (réalisables) et d’y appliquer les techniques d’IA les plus pertinentes, en vue de leur implémentation ultérieure. Dans ce cadre, nous allons non seulement nous pencher sur le back-office, mais aussi nous concentrer sur l’utilisation parmi des services qui s’adressent directement au public.
Conversational Interfaces
 Le projet d’étude “Chatbot pour Student@Work” de l’année dernière nous a permis de mettre en pratique dans une réalisation concrète les compétences déjà acquises concernant les chatbots. Le chatbot pour les étudiants est textuel : l’utilisateur saisit sa question et reçoit une réponse sous forme textuelle.
Le projet d’étude “Chatbot pour Student@Work” de l’année dernière nous a permis de mettre en pratique dans une réalisation concrète les compétences déjà acquises concernant les chatbots. Le chatbot pour les étudiants est textuel : l’utilisateur saisit sa question et reçoit une réponse sous forme textuelle.
Outre les interactions textuelles, nous voyons toutefois aussi de plus en plus d’interactions vocales. Pensons par exemple à l’arrivée des assistants vocaux tels que Google Assistant, Amazon Alexa et Apple Siri ou encore des “smart speakers” où la parole est la seule forme d’interaction. Nous pensons que les interfaces conversationnelles basées sur la parole ont de bonnes chances de devenir très importantes pour l’e-gouvernement.
Les interactions vocales posent des défis uniques sur le plan de la conception de la conversation et de l’authentification de l’utilisateur, par exemple lors de la consultation de son propre dossier ou de l’exécution d’une transaction.
L’objectif de ce projet est de développer nos premières expériences avec les assistants vocaux en concertation avec les parties prenantes et d’aboutir à un prototype totalement fonctionnel, lequel pourra être repris par une équipe de projet pour une mise en production. Concrètement, nous nous concentrerons sur deux cas : la déclaration Dimona sous forme vocale et l’application Check Obligation de Retenue sous forme vocale.
Robotic Process Automation
 Au cours de l’année écoulée, nous avons acquis beaucoup d’expérience dans le domaine du Robotic Process Automation. Le potentiel de cette technologie est élevé, mais soulève également des questions en matière de gouvernance et de maintenance. En 2019, nous souhaitons approfondir le sujet en cherchant une réponse sur la base de cas concrets. Nous élaborerons deux cas dans la mesure du possible en vue de leur mise en production. L’équipe de recherche est en mesure de développer les preuves de concept nécessaires en concertation avec les utilisateurs chez les clients et, le cas échéant, de traduire ces preuves de concept en réalisations concrètes en collaboration avec les services opérationnels de Smals.
Au cours de l’année écoulée, nous avons acquis beaucoup d’expérience dans le domaine du Robotic Process Automation. Le potentiel de cette technologie est élevé, mais soulève également des questions en matière de gouvernance et de maintenance. En 2019, nous souhaitons approfondir le sujet en cherchant une réponse sur la base de cas concrets. Nous élaborerons deux cas dans la mesure du possible en vue de leur mise en production. L’équipe de recherche est en mesure de développer les preuves de concept nécessaires en concertation avec les utilisateurs chez les clients et, le cas échéant, de traduire ces preuves de concept en réalisations concrètes en collaboration avec les services opérationnels de Smals.
Web Scraping for Analytics
Dans le domaine de l’analyse, nous continuons à chercher des possibilités novatrices pouvant être mises à profit dans le secteur. En 2018, nous nous concentrions sur l’analyse de graphes et de réseaux et introduisions Neo4J comme base de données orientée graphe. En 2019, nous mettrons l’accent sur le web scraping dans le contexte de l’analyse avancée et nous pourrons exploiter un nouveau type de données encore inexploré dans notre lutte contre la fraude sociale entre autres. Le web scraping est un ensemble de techniques et d’outils permettant d’extraire le contenu de sites web à l’aide de scripts/programmes en vue d’analyser les données ainsi obtenues. On parle aussi de web crawling, de web harvesting ou de web data extraction.
 Ce projet d’étude dois nous permettre de nous familiariser avec les plus importantes techniques de web scraping et de les appliquer à un certain nombre de cas concrets afin d’y appliquer les techniques d’analyse (avancée) nécessaires en fonction du cas retenu.
Ce projet d’étude dois nous permettre de nous familiariser avec les plus importantes techniques de web scraping et de les appliquer à un certain nombre de cas concrets afin d’y appliquer les techniques d’analyse (avancée) nécessaires en fonction du cas retenu.
La technique du web scraping n’est pas à proprement parler novatrice. En effet, elle existe depuis de nombreuses années. Le web scraping nous offrira néanmoins la possibilité d’exploiter un type de données encore inexploré dans notre lutte contre la fraude sociale.
NewSQL Databases
Dans le sillon d’études précédentes telles que les études “Extreme Transaction Processing” et “High Availability”, dans lesquelles nous avons largement abordé des principes tels que la performance, la disponibilité et la cohérence des données et des systèmes, les bases de données NewSQL apparaissent comme un composante possible mais important. L’étude répond à la quête de Smals quant à la haute disponibilité de ses applications et systèmes.
![]() Avec les bases de données NewSQL, il s’agit de combiner les avantages des NOSQL et RDBMS. Ce type de base de données est décrit comme la solution permettant de mettre sur pied une base de données horizontalement extensible et distribuée, à l’instar des bases de données NOSQL. L’objectif est donc d’égaler la performance et la disponibilité des bases de données NOSQL, généralement bien supérieures à celles des RDBMS.
Avec les bases de données NewSQL, il s’agit de combiner les avantages des NOSQL et RDBMS. Ce type de base de données est décrit comme la solution permettant de mettre sur pied une base de données horizontalement extensible et distribuée, à l’instar des bases de données NOSQL. L’objectif est donc d’égaler la performance et la disponibilité des bases de données NOSQL, généralement bien supérieures à celles des RDBMS.
Il est donc possible que les bases de données NewSQL puissent augmenter la résilience des applications, étant donné que la résilience de la base de données sous-jacente augmente, éventuellement avec un effort de migration limité, en raison de la compatibilité avec le RDBMS actuellement utilisé.
Le but de cette étude est de se faire une idée à ce sujet, ainsi que d’explorer le marché des bases de données NewSQL et de mieux comprendre leur fonctionnement
Consultance
Outre les activités de recherche, une grande partie du temps sera comme chaque année consacrée aux activités de consultance pour les institutions membres. Citons ici notre participation à plusieurs projets d’analyse business stratégique, à des projets en matière de data quality et cryptographie ainsi qu’à l’assistance concrète des membres dans la lutte contre la fraude sociale.
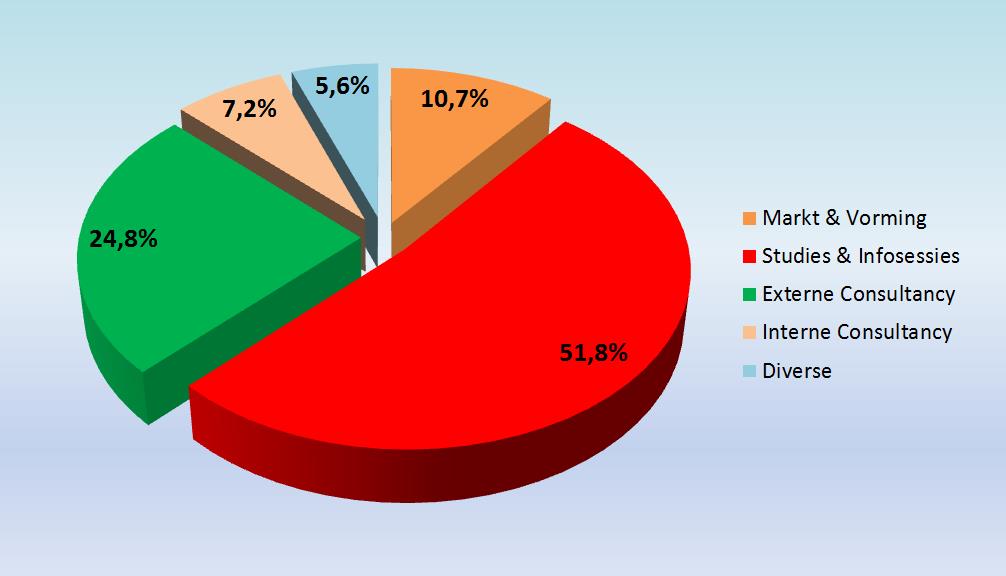
En 2018, nous avons consacré 32 % de notre temps aux activités de consultance. Quelque 52 % de nos activités ont été consacrées aux projets de recherche et 11 % à la veille technologique et à la formation permanente.
Activités 2018