Dans notre article précédent, nous présentons une méthode permettant de mesurer et visualiser l’importance des valeurs rares dans une liste de données où l’on s’attend à une grande redondance, souvent signes d’un problème de qualité. La méthode en question se basait uniquement sur un comptage des occurrences des valeurs, sans du tout en examiner le contenu.
Classiquement, pour standardiser des données, les outils rechercheront les valeurs similaires pour éventuellement sélectionner, de façon automatique ou (semi-)manuelle, une seule formulation (“golden record” ou “survivor” suivant les outils) : Si l’on trouve “Bruxelles” (2580 occurrences), “BRUXELLES” (230 occurrences), “Bruxelle” (5 occurrences) et “brxuelles” (1 occurrences), il y a des chances que l’on choisisse de favoriser la formulation la plus fréquente.
Cette phase de standardisation peut être complexe et coûteuse. Avant de se lancer dans un tel processus, il peut être judicieux d’évaluer la quantité de telles valeurs similaires que l’on risque de trouver dans les données. De façon similaire, on voudra pouvoir évaluer la progression de l’état des données avant et après nettoyage ou standardisation.
Nous allons dans cet article tenter de répondre à la question : “à quel point les valeurs dans une liste sont-elles similaires entre elles”. Nous voulons d’une certaine façon pouvoir dire qu’il y a plus de similarité dans la liste [Bruxelles, bruxelles, Namur] que dans [Bruxelles, Anvers, Namur]. Il y aura également plus de similarité dans la première liste que dans [Bruxelles, Bruxelles, Namur], qui contient deux valeurs distinctes, qui ne se ressemblent pas entre elles.
Dans les méthodes présentées ci-dessous, il ne s’agira pas de corriger ou de standardiser, mais simplement de se faire une image globale : ça ne sera donc pas un problème si de façon marginale deux valeurs sont considérées erronément comme “suspicieusement similaires”. Il peut très bien dans une même ville y avoir une “Avenue Louise” et une “Avenue Louis”. En fonction du contexte, une haute similarité interne sera cependant un signe d’une faible standardisation.
Nous proposons ci-dessous trois approches, de complexité croissante :
- Nous déterminons le nombre de valeurs qui deviennent exactes après un nettoyage basique : Bruxelles et BRUXELLES, après une mise en majuscule générale ;
- Nous déterminons la proportion de valeurs qui contiennent une autre valeur. Supposons deux occurrences de “Avenue Fonsny 20” et 25 de “Avenue Fonsny” : la première valeur contient la seconde ;
- Nous déterminons la proportion de valeurs qui sont similaires à une autre valeur, comme par exemple “Avenue Fonsny” et “Avenue Fonsy”.
Données de test
Nous reprenons pour illustrer notre méthodologie les données que nous avons déjà exploitées dans notre article précédent, qui contient les adresses de toutes les sociétés enregistrées en Belgique avec un code postal correspondant à la région de Bruxelles-Capitale (les 19 communes ainsi que leurs sous-sections si applicables). Nous nous concentrons sur la colonne “Street”, qui contient la rue telle qu’encodée dans la source, et ne doit normalement pas contenir le numéro du bâtiment, ainsi les versions nettoyées par nos soins “Street_batch” et “Street_cluster”, présentées dans notre article précédent. Nos métriques seront évaluées isolément sur chaque colonne, permettant de quantifier la progression en termes de qualité.
Pour chaque colonne, nous regroupons toutes les valeurs identiques et en comptons le nombre d’occurrences. Les listes que nous analysons par la suite ne contiennent donc aucun doublon stricte, puisque ceux-ci ont déjà été regroupés.
Méthode par nettoyage
La méthode la plus simple consiste à appliquer des méthodes basiques de nettoyage de données pour évaluer le nombre de valeurs qui deviennent, après ce nettoyage, identique à une autre valeur (après le même nettoyage). Plus précisément, on ne regarde que les valeurs avec plus d’occurrences.
Supposons l’exemple suivant :
| Valeur | Nombre d’occurrences |
| Bruxelles | 890 |
| Namur | 100 |
| bruxelles | 8 |
| BRUXELLES | 2 |
Après une mise en majuscule de toutes les valeurs, deux valeurs (bruxelles et BRUXELLES) deviennent identiques avec une valeur plus fréquente (Bruxelles). Nous avons donc un taux de similarité “par nettoyage” de 50 % en terme des valeurs. Par contre, si nous considérons les occurrences, les valeurs en question correspondent à 10 enregistrements (8 + 2) sur un total de 1000, donc 1 % de similarité.
Dans l’illustration ci-dessous (Figure 1), nous avons considéré deux méthodes de nettoyage :
- “cleansed” : Mise en majuscule, suppression des accents et autres signes diacritiques, remplacement des certains caractères (tiret, point, apostrophe, slash) par des espaces, suppression de tous les autres caractères non alphanumériques et suppression des espaces superflus ;
- “cleansed_nodigit” : Idem, mais avec en plus suppression de tous les chiffres.
Rappelons que, étant donné que nous ne cherchons pas à réellement nettoyer les données, mais uniquement à en évaluer la qualité, nous pouvons nous permettre d’être plus agressif. Nous ne cherchons par exemple pas à extraire un numéro de maison qui se trouverait dans le champ “Street”, nous le supprimons. Et nous supprimons également des chiffres légitimes : “Rue des 2 églises” devient “Rue des églises”. Nous prenons simplement l’hypothèse que ces cas sont bien plus rares que des cas où le numéro de maison se trouve erronément dans le mauvais champ.
Nous pourrions également avoir des méthodes plus spécifiques au contenu, en remplaçant par exemple, s’il s’agit de noms de rue, toute séquence “AV ” en début de champ par “AVENUE ” (à nouveau, sans se soucier des quelques cas rares où ce remplacement ne serait pas adéquat).
Nous avons donc deux axes de “nettoyage” :
- Celui évoqué dans notre blog précédent, dont l’objectif est de réellement nettoyer les données. Il s’agit des colonnes “Street”, “Street_batch”, et “Street_cluster” du fichier de données que nous analysons. Il va de soi que nous avons été prudents lors de ces opérations et que celles-ci étaient considérées comme (raisonnablement) sûres.
- Celui évoqué ci-dessus, et qui a uniquement pour but d’évaluer la similarité entre les valeurs. Nous avons appliqué ces opérations (“cleansed”, et “cleansed_nodigit”) sur chacune des colonnes. Ces opérations peuvent donc être plus agressives.
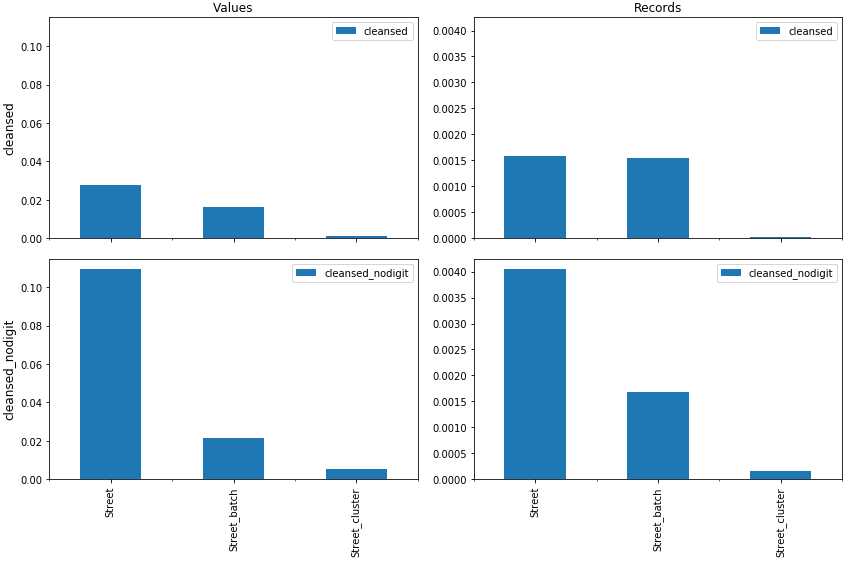
La figure 1, ci-dessus, reprend les valeurs pour le dataset utilisé. On y voit par exemple qu’après le nettoyage le plus complet (cleansed_nodigit) appliqué sur les données d’origine (Street), presque 11 % des valeurs (0.4 % des données) distinctes présentes dans les données sont identiques à une autre valeur. Ce nombre chute à 0.5 % des valeurs (0.01 % des données) après le nettoyage effectué dans la colonne “Street_cluster”, ce qui illustre le gain important des opérations.
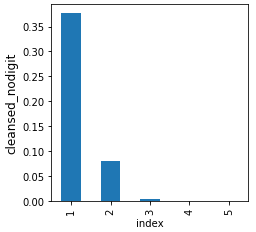
Il est intéressant de se demander là où l’on trouve le plus de redondance. Le graphique ci-contre (Figure 2), illustre, pour la colonne “Street” et la méthode de nettoyage “cleansed_nodigit”, que plus de 35 % des valeurs uniques (avec une seule occurrence, valeur indiquée en abscisse), sont, après nettoyage, identique à une valeur déjà présente. Cette proportion passe à moins de 10 % pour les valeurs présentes deux fois, et devient négligeable pour toutes les valeurs plus fréquentes. Ceci confirme l’intuition que nous avons déjà partagée dans notre blog précédent : c’est dans les valeurs uniques, et plus généralement les valeurs rares, que l’on a le plus de chances de trouver des problèmes de qualité.
Méthode par inclusion
Une autre façon de mesurer la similarité entre deux chaînes de caractères est de voir si l’une contient l’autre. Par exemple, “Avenue Fonsny 20” contient “Avenue Fonsny”, et sont en effet similaires. Par contre, “Rue Léopold Van Overstraat” contient bien “Rue Léopold”, mais il est peu probable qu’il s’agisse d’une erreur. Nous considérons qu’une inclusion est “suspecte” si la différence est courte. Dans les exemples ci-dessous, on ne considère une inclusion qu’en dessous d’un écart de 5 caractères, ou 50 % de la longueur.
Sur chacune des méthodes de nettoyage effectuées ci-dessus, nous avons recherché les inclusions. Pour ce faire, nous avons regardé si chaque valeur contenait une autre valeur (avec au moins autant d’occurrences).
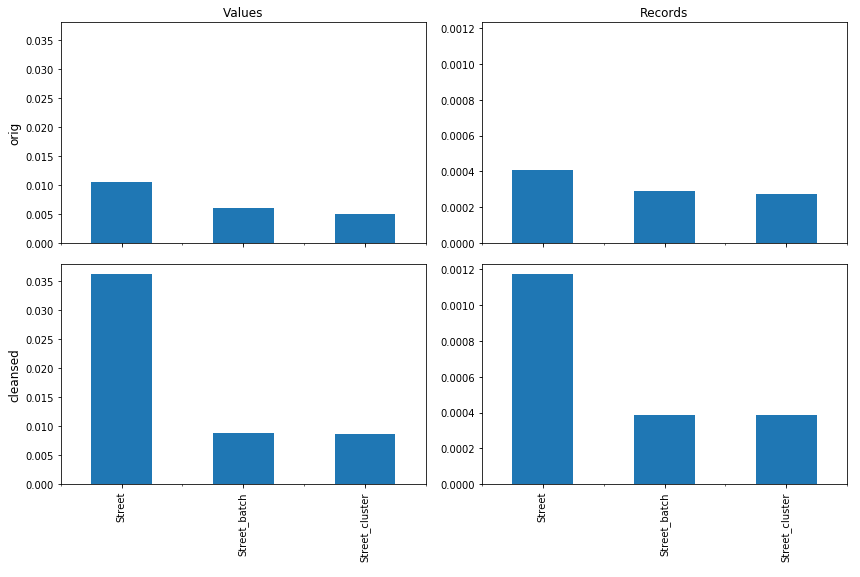
La figure ci-contre (Figure 3) nous montre que, dans les données originales, 1 % des valeurs contiennent une autre valeur (ligne “orig”, colonne “Values”, barre “Street”). Cette proportion monte à 3.5 % pour les inclusions dans les valeurs nettoyées (“cleansed”). Ceci s’explique par le fait que, dans le dataset considéré et pour des raisons historiques, la plupart des adresses qui contenaient le numéro étaient en majuscules, alors que les adresses correctement découpées étaient en minuscules. “AVENUE FONSNY 20” ne contenait donc pas “Avenue Fonsny”, alors que c’était le cas après le nettoyage.
Notons que l’inclusion est recherchée sur les valeurs uniques après le nettoyage : les 3.5% de similarité se rajoutent donc d’une certaine manière à la similarité déterminée par le nettoyage (de l’ordre de 3%, voir Figure 1, ligne “cleansed”, colonne “Values”, barre “Street”).
On observe que si le gain entre les données originales (Street) et celles ayant subi la première salve d’opérations de nettoyage décrites dans notre article précédent (Street_batch) est important, il est négligeable entre “Street_batch” et “Street_cluster”, ce qui peut aisément se comprendre : Dans “Street_batch”, en plus d’uniformisations simples (mise en majuscules, suppressions d’espaces superflus…), nous avons appliqué une série d’opérations visant à extraire le numéro de bâtiment se trouvant dans le champ “Street” (“Avenue Fonsny 20”, qui contenait “Avenue Fonsny”, est devenu “Avenue Fonsny”, qui ne contient plus une autre valeur). Une grande partie des cas d’inclusions que l’on trouvait dans “Street” ne se trouvent donc plus dans “Street_batch”. Par contre, dans Street_cluster, nous avons regroupé des valeurs similaires, telles que par exemple “Avenue Fonsny” et “Avenue Fonsni”, ce qui a moins d’impact sur l’inclusion.
Calcul de similarité
La troisième méthode que nous avons examinée, et la plus complexe, consiste à calculer le nombre de valeurs qui “ressemblent” à une autre. Une façon relativement classique de calculer la similarité entre deux chaînes de caractères est d’utiliser des métriques comme la distance de (Damerau)-Levenshtein, ou la similarité de Jaro. Ceci nécessite cependant de comparer chaque valeur avec chaque autre, ce qui n’est pas raisonnable quand on considère plusieurs dizaines de milliers de valeurs ou plus. Il existe des méthodes de “clustering” ou de “keying” qui permettent de réduire l’espace de recherche, mais nous avons choisi ici une méthode plus efficace, basée sur TF-IDF et les N-Grams, décrite par Chris van den Berg.
Comme ci-dessus, nous pouvons calculer la proportion de valeurs (ou de données) similaires à une autre valeur (ayant au moins autant d’occurrences).
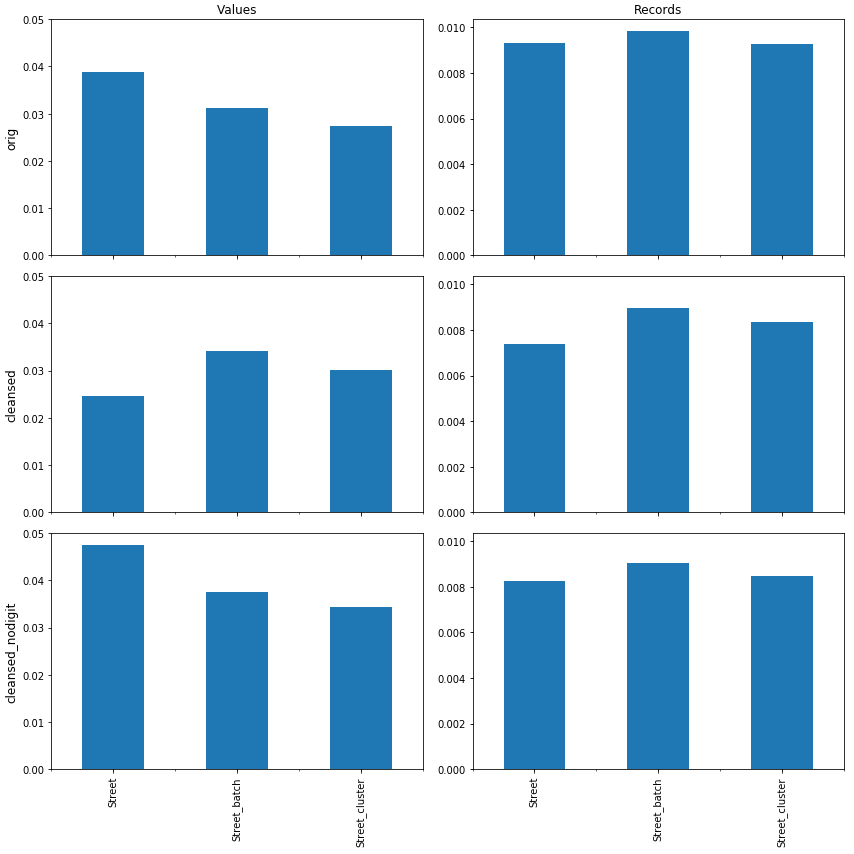
Nous pouvons par exemple y constater qu’après nettoyage et suppression de chiffres (cleansed_nodigit, Street, Values) qui permettait de réduire la similarité de 11 %, nous détectons encore ici presque 5 % des valeurs proches d’autres, dans les données sources (Street). Ce taux étant nettement plus bas dans les versions nettoyées (Street_cluster), qui combine 0.5 % (Figure 1, cleansed_nodigit, Street_cluster, Values) et ~3.5 % (Figure 4).
Conclusions
En combinaison avec la méthode présentée dans notre article précédent, nous montrons ici qu’il est facile de se faire une image de la quantité de valeurs similaires qui existent dans une liste de valeurs, telle qu’une colonne dans une base de données. Cela permet principalement deux choses. Premièrement, se faire une idée de la quantité des valeurs proches dans les données, à la fois en termes de valeurs distinctes, mais également en termes de nombre d’enregistrements. En fonction du contexte, cela aiguillera les décideurs vers la nécessité et le bénéfice d’un nettoyage des données, voire d’une réorganisation du flux des données.
Deuxièmement, on pourra mesurer le bénéfice qu’a pu apporter un nettoyage ou une standardisation des données, faite dans un outil dédié.
Le code source utilisé pour réaliser les analyses ci-dessus est disponible sur GitLab.
____________
Ce post est une contribution individuelle de Vandy Berten, Data Science Expert chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.