Dans l’article précédent, nous exprimions que les bases de données relationnelles n’étaient pas toujours la meilleure solution quand il s’agissait de focaliser une analyse sur les relations (ce qui peut en effet sembler un petit peu contradictoire et ironique). Nous suggérons au lecteur de d’abord lire l’article en question, car nous nous baserons sur les exemples qui y sont présents.
Base de données orientée graphe
Les bases de données orientées graphe (ou Graph DB) placent les relations au cœur du problème, et plus particulièrement le parcours de ces relations. Elles ont pour but à la fois d’éviter à l’utilisateur (plus précisément à la personne interrogeant la base de données) de se préoccuper de la façon dont sont structurées et implémentées les relations, et d’offrir un mécanisme plus efficace que les JOIN pour parcourir les relations.
Un des leaders des bases de données orientées graphe est Neo4j2. Dans la suite de cet article, nous utiliserons son langage de requête, “Cypher” (proche de SQL).
Syntaxe : plus proche du modèle
Si nous reprenons l‘exemple de l’article précédent, avec les travailleurs et les entreprises, nous pourrions naturellement représenter notre modèle comme dans la figure ci-contre. 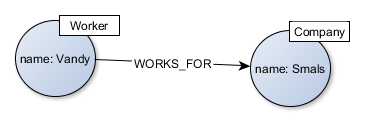 Deux “nœuds” (ou entités), l’un de type “Worker”, l’autre de type “Company”, sont liées par une relation “WORKS_FOR”. Les nœuds ont des attributs (ici : “Name”), les relations peuvent également en avoir (non représentées dans le schéma). Dans le langage “Cypher”, la requête SQL décrite dans l’article précédent permettant de retrouver les travailleurs employés par la compagnie “Smals” pourra s’écrire de la façon suivante :
Deux “nœuds” (ou entités), l’un de type “Worker”, l’autre de type “Company”, sont liées par une relation “WORKS_FOR”. Les nœuds ont des attributs (ici : “Name”), les relations peuvent également en avoir (non représentées dans le schéma). Dans le langage “Cypher”, la requête SQL décrite dans l’article précédent permettant de retrouver les travailleurs employés par la compagnie “Smals” pourra s’écrire de la façon suivante :
MATCH (w:Worker)-[:WORKS_FOR]->(c:Company {c.Name:"Smals"})
RETURN w.Name
Dans cette requête, les nœuds sont symbolisés par des parenthèses, alors que les relations le sont par des crochets au milieu d’une flèche. Nous précisons ici que nous recherchons les travailleurs (w), ayant une relation de type “WORKS_FOR” avec une compagnie (c) dont l’attribut “Name” vaut “Smals”. Remarquons que nous devons juste préciser le type de la relation, et non comment elle est implémentée, contrairement aux requêtes SQL décrites précédemment. Par ailleurs, ce modèle vaut aussi bien pour le cas où un travailleur ne peut être employé que par une entreprise que pour le cas où il peut travailler pour plusieurs sociétés.
Nous avons donc une requête très proche du schéma métier que l’on a dessiné. En exagérant à peine, il suffit d’avoir dessiné au tableau la requête que l’on veut exécuter pour pouvoir directement l’écrire.
Autre exemple
Considérons un exemple un petit peu plus complexe, dans lequel nous fusionnons les deux exemples de l’article précédent : nous avons donc des personnes, des compagnies, des relations de travail entre personnes et compagnies, ainsi que des relations d’amitié entre les personnes.
Si nous voulons connaître la liste de collègue de Bob que celui-ci apprécie, nous écrirons ceci :
MATCH
(bob:Person {Name:"Bob"})-[:LIKES]->(colleague:Person),
(bob)-[:WORKS_FOR]->(:Company)<-[:WORKS_FOR]-(colleague)
RETURN colleague.Name
La première partie de la requête cherche une relation de type “LIKES” entre un nœud, de type Person (dénommé “bob” dans la requête), dont l’attribut “Name” vaut “Bob”, et un autre nœud de type Person (dénommé “colleague”). Grâce à la seconde partie, nous ne considérons ce nœud “colleague” que si l’on trouve deux relations “WORKS_FOR”, liant “bob” et “colleague” à une même compagnie.
Si l’on veut maintenant plutôt savoir quelles sont les personnes qui aiment Bob dans sa société, on changera simplement “-[:LIKES]->” par “<-[:LIKES]-“, sans devoir, comme c’était le cas avec SQL, mettre à jour une série de clés. Et si le sens de la relation importe peu, on écrira simplement “-[:LIKES]-“.
On peut également s’intéresser à des chemins de plus d’une relation : les amis des amis seront dénotés “-[:LIKES*2]-” ; si l’on veut un chemin de longueur entre 4 et 6, on écrira “-[:LIKES*4..6]-“, et si la longueur importe peu, “-[:LIKES*]-“.
Gestion des clés
Les requêtes Cypher décrites ci-dessus ne comprennent aucune clé, qu’elle soit primaire ou étrangère. La gestion des clés ne sert en effet souvent qu’à gérer les relations, et cette gestion est complètement déléguée à la base de données. On peut bien sûr avoir des clés “métier” : identifiant national, numéro de TVA, numéro d’employé… mais elles seront alors traitées comme les autres attributs.
Chaque attribut, comme dans une base de données relationnelle classique, pourra à la demande, recevoir une contrainte d’unicité (pour les clés métier), ou être indexée, pour une recherche rapide (comme typiquement pour l’attribut “Name” décrit ci-dessus). Il n’y aura par contre pas lieu de décrire des contraintes d’intégrité référentielle, (permettant dans une base de données relationnelle de s’assurer qu’une clé étrangère existe bien comme clé primaire de la table référencée), ni pour le concepteur de la base de données, ni pour le développeur de requête.
Un parcours plus efficace
L’implémentation du moteur est ici très différente du cas de la base de données relationnelle. Reprenons la requête évoquée plus haut :
MATCH (w:Worker)-[WORKS_FOR]->(c:Company {c.name:"Smals"})
RETURN w.name
Une fois qu’on a trouvé le nœud “Smals” (grâce à un index, typiquement), celui-ci contient directement une liste de pointeurs, lui permettant de trouver les nœuds “Worker” concernés dans un temps qui ne dépendra pas de la taille de la base de données, mais uniquement du nombre de nœuds directement voisins. Le parcours d’index nécessaire pour un “JOIN” classique est donc évité.
C’est grâce à ce mécanisme d’arithmétique de pointeur qu’une requête Cypher peut être exécutée beaucoup plus rapidement qu’une requête SQL classique comprenant un certain nombre de “JOINs“.
Certains auteurs considèrent par ailleurs que c’est cette caractéristique qui définit une base de données orientée graphe : dans une telle base de données, chaque nœud contient une référence qui permet d’accéder directement à tous ses voisins.
Chez eBay, qui utilise Neo4j pour un système de routage de colis, Volket Pacher (Senior Developper) explique :
“We found Neo4j to be literally thousands of times faster than our prior MySQL solution, with queries that require 10-100 times less code. Today, Neo4j provides eBay with functionality that was previously impossible.”
Des recherches ont été menées2,3 pour comparer les performances entre Neo4j et une base de données relationnelle, dans le cas de l’exploration d’un réseau d’amitiés, comme présenté ci-dessus. Pour un réseau d’un million de nœuds, en moyenne 50 voisins par nœud et profondeur de 2 (amis d’amis), les performances des deux systèmes étaient comparables. Pour une profondeur de 3, les 30 secondes nécessaires au RDBMS ont été réduites à 170 millisecondes avec Neo4j. Il n’était donc plus envisageable d’utiliser le RDBMS dans un système interactif, alors que ça le restait pour Neo4j.
| Depth | RDBMS exec. time (s) | Neo4j exe. time (s) |
| 2 | 0.016 | 0.010 |
| 3 | 30.264 | 0.168 |
| 4 | 1543.505 | 1.359 |
| 5 | Unfinished | 2.132 |
Pour une profondeur de 4, la base de données orientée graphe a permis de passer de 25 minutes à 1,3 secondes.
Notons que cette amélioration notable de performances dans certaines circonstances ne se fait pas au prix de la cohérence de la base de données : Neo4j garantit en effet les propriétés ACID.
Tout n’est pas rose
Au vu de ce qui est dit ci-dessus, doit-on tout simplement abandonner les bases de données relationnelles au profit des bases de données orientées graphe ? Certainement pas. Les Graph DB ont bien sûr quelques inconvénients. En voici quelques-uns (liste non exhaustives) :
- Les Graph DB n’ont pas encore atteint la maturité des RDBMS : l’offre de produit est nettement plus réduite, la communauté également. La robustesse ou la haute disponibilité doivent encore faire leur preuve.
- D’autres modèles de bases de données alternatives aux RDBMS, comme les bases Orienté Objets, un temps très à la mode, ne sont pas parvenu à s’imposer. Rien ne dit que les Graph DB pourront faire mieux.
- Pour des recherches (“Trouver toutes les entités de type T”) ou des agrégations (“Quel est le salaire moyen par province”), une Graph DB ne sera pas efficace. Idem pour appliquer une même transformation à toutes les lignes d’une table.
- Il faut être très attentif à l’explosion combinatoire. Par exemple, si l’on demande tous les chemins possibles entre deux nœuds, il ne faut pas grand chose pour que le nombre de ces chemins explose.
- Neo4j repose sur le principe que chaque nœud peut avoir des attributs différents, déterminés à la création du nœud. Il est donc vite arrivé de faire une faute de frappe, et d’avoir deux noms d’attributs légèrement différents, et du coup inutilisables.
RDBMS ou Graph DB ?
Il existe probablement peu de situations dans laquelle une base de données orientée graphe pourra être la seule base de données d’une application. Une cohabitation sera dans la plupart des cas l’option la plus viable. Même Neo4j ne conseille pas nécessairement d’envisager un environnement 100% Graph DB. Trois scenarii principaux peuvent se présenter :
- Les données sont intimement connectées, et la plupart des requêtes concernent des parcours de relations. Dans ce cas très théorique seulement, une base de données orientée graphe unique peut s’envisager.
- Certaines données sont intimement connectées, mais pas toutes. On peut alors envisager de gérer la partie “connectée” dans une Graph DB. L’application interroge alors la Graph DB avec Cypher, et la RDBMS avec SQL.
- On peut également envisager une duplication complète synchronisée. En fonction des requêtes, l’application peut alors choisir soit Cypher, soit SQL.
Un exemple classique consisterait à avoir toutes les données transactionnelles de production dans une RDBMS, et tout ce qui permet de faire des analyses (statistiques, recherche de fraudes, recommandations…) dans une copie “Graph DB” en lecture seule.
Dans la plupart des cas, la question ne sera donc pas “RDBMS ou Graph DB”, mais plutôt “RDBMS et Graph DB”. La difficulté, que ça soit à la conception du système ou lors d’une migration, sera de déterminer le terrain de chacun.
Conclusions
Si les bases de données orientées graphe n’ont pas vocation à remplacer les bases de données relationnelles dans toutes les circonstances, il existe de nombreuses situations où elles peuvent avoir un grand intérêt, seule ou en complément. En particulier quand on se focalise sur les relations qui existent entre des entités de type différent, plutôt qu’entre les attributs de ces entités.
Le champ d’application des Graph DB est bien plus large que l’analyse ou la gestion des réseaux sociaux ; systèmes de recommandation en temps-réel, Master Data Management, détection de la fraude, gestion des infrastructures IT et des réseaux, sont autant de secteurs dans lesquelles des logiciels tels que Neo4j (mais également OrientDB, ou, dans une moindre mesure FlockDB) s’avèrent particulièrement efficaces.
L’adoption d’une base de données orientée graphe demande en général de penser ses données d’une façon complètement différente, mais souvent plus intuitive et plus proche de la réalité. La migration vers une Graph DB ne s’avère par toujours rentable, mais il serait judicieux, quand un nouveau projet démarre, d’au moins se demander si une base de données relationnelle est bien la solution la plus appropriée.
Références
- Graph Databases, New opportunities for connected data ; Ian Robinson,
Jim Webber & Emil Eifrem ; O’Reilly, 2015 - www.neo4j.com
- Neo4j in Action. Aleksa Vukotic and Nicki Watt, Mannings, 2015.
Leave a Reply