Dit artikel is ook beschikbaar in het Nederlands.
De nombreuses organisations expérimentent actuellement l’IA générative. Dans ce cadre, elles utilisent souvent des applications qui fonctionnent sur des LLM (Large Language Models), soutenues par une architecture RAG (Retrieval-Augmented Generation). Cela signifie que le système extrait d’abord les informations pertinentes d’une source de connaissances pour les transmettre au modèle de langage en guise de contexte. Il en résulte un output solidement ancré dans le domaine de connaissances concerné. Dans le jargon, on parle de grounding. Cette approche est surtout populaire dans les applications de questions-réponses et les chatbots.
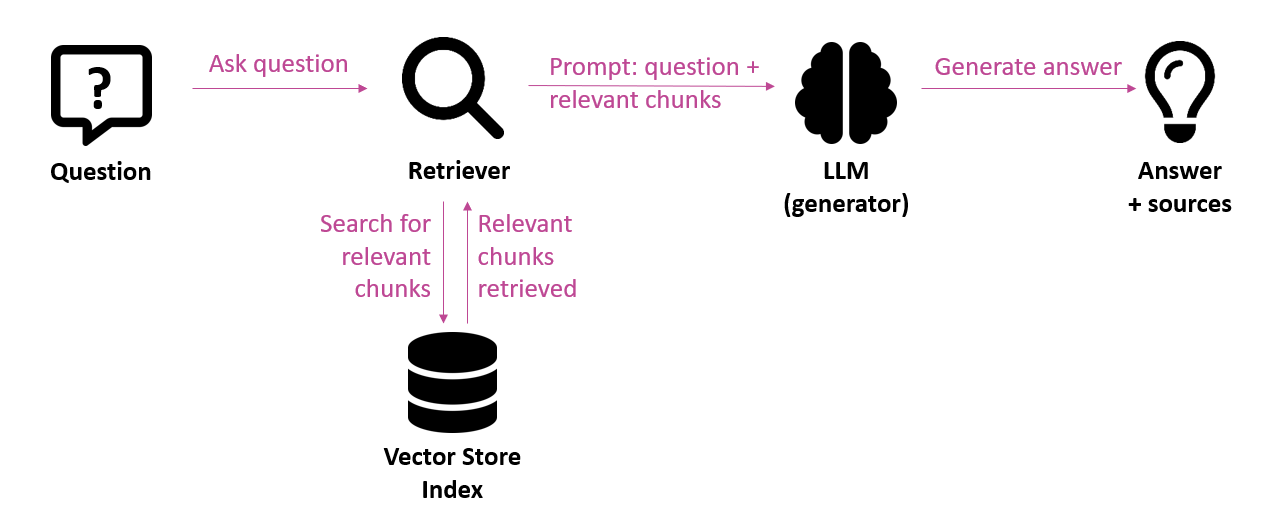
Malgré le grand potentiel de ces applications basées sur des LLM, l’output généré n’est pas toujours fiable dans la pratique. Des problèmes peuvent déjà survenir au niveau de l’extraction, si les informations pertinentes ne sont pas trouvées ou ne le sont que partiellement. Mais même si le bon contexte est fourni, un modèle de langage peut commettre des erreurs. Le modèle peut mal interpréter les informations, établir des liens incorrects ou générer des hallucinations, c’est-à-dire des réponses qui semblent convaincantes, mais qui sont en fait erronées. Cette incertitude quant à la qualité constitue l’un des principaux obstacles à la mise en production de telles applications, en particulier dans les domaines où la fiabilité est essentielle.
Dans cet article, nous nous pencherons sur les méthodes d’évaluation de la qualité des applications basées sur la RAG.
Évaluations manuelles et automatiques
Évaluer des applications d’IA générative est tout sauf simple. Cela s’explique principalement par le fait que l’output est souvent non structuré et non déterministe, à savoir qu’un même input peut chaque fois produire un output différent. De plus, il existe rarement une seule bonne réponse, de sorte qu’il est difficile d’évaluer objectivement la qualité de l’output généré. Beaucoup dépend de critères subjectifs comme la pertinence ou la précision, qui peuvent varier d’un évaluateur à l’autre.
La manière la plus évidente de contrôler la qualité est manuelle. Elle consiste à exécuter manuellement un certain nombre de tests, à mesurer le résultat et éventuellement à ajouter un commentaire indiquant la cause d’une qualité moindre. Une personne disposant des connaissances nécessaires dans le domaine peut correctement effectuer une telle évaluation, mais celle-ci est chronophage et peu extensible.
Pour ces raisons, il peut être intéressant de se tourner vers des systèmes d’évaluation automatique, appelés “auto-evals“. Comme ces évaluations s’effectuent automatiquement, elles sont aisément extensibles. Des techniques telles que “exact-string matching” et “regular expressions” peuvent être mises en œuvre pour le matching exact d’un texte ou d’un schéma. Mais si l’output d’un LLM peut varier en termes de choix de mots, de séquence ou de longueur, par exemple lorsque plusieurs formulations sont correctes, ces méthodes échouent. Dans ces cas, une évaluation sémantique ou basée sur un modèle s’impose. Une technique qui suscite actuellement beaucoup d’intérêt s’appelle “LLM-as-judge“. Elle consiste à faire évaluer l’output par un (second) modèle de langage selon certains critères.
LLM-as-judge : un LLM évalué par un LLM
À première vue, l’intervention d’un modèle de langage pour évaluer l’output d’un autre modèle de langage peut sembler étrange. Cependant, il s’avère plus facile de critiquer un output que de générer l’output original : même pour les LLM, il est plus facile de détecter les erreurs a posteriori que de les éviter.
Un LLM désigné comme juge peut évaluer plusieurs aspects, tels que l’exactitude factuelle, l’exhaustivité, les hallucinations et la pertinence de l’output par rapport à la question. Cette évaluation peut se faire par rapport à une référence (basée sur une référence) ou non (sans référence). Ainsi, pendant la phase de développement, une batterie de tests peut être prévue avec des questions, complétées de réponses de référence : un expert du domaine peut fournir des réponses correctes à titre de référence. Dans un environnement de production, il est toutefois impossible de prévoir une réponse de référence pour chaque question possible. Dans la pratique, il faut dès lors se rabattre sur des évaluations sans référence.
Nous avons concrètement mis en œuvre quelques métriques LLM-as-judge issues de la boîte à outils OpenEvals de LangChain, appliquées à un système de questions-réponses basé sur des LLM. L’approche est la suivante :
- Élaboration d’une batterie de tests – Dans un premier temps, une batterie de tests est élaborée avec des questions représentatives de la base de connaissances concernée. Une réponse de référence est prévue pour chacune des questions.
- Génération des réponses – Ensuite, le système de questions-réponses génère une réponse pour chacune des questions de la batterie de tests.
- Évaluation manuelle – Afin de vérifier l’efficacité d’un LLM-as-judge automatique, on procède d’abord à une évaluation manuelle : chaque réponse générée se voit attribuer un score de 0 (réponse incorrecte), 1 (réponse partiellement correcte / incomplète) ou 2 (réponse correcte et complète).
- Exécution des évaluations – Au cours de cette étape, on produit un script qui évalue tous les cas de test au regard d’une certaine métrique. On utilise comme métrique l’évaluateur de correctness (“exactitude” en français) proposé par défaut dans la bibliothèque OpenEvals.
Celui-ci mesure le degré d’exactitude d’une réponse générée par rapport à la réponse de référence. En output, on obtient pour chaque réponse générée un score binaire (true = correct ; false = incorrect) et une motivation textuelle du score, par exemple :Question : À partir de quel âge puis-je travailler comme étudiant?
Réponse générée : Tu peux t’engager comme jobiste dès que tu as 15 ans et que tu as suivi le premier degré de l’enseignement secondaire, ou dès que tu as 16 ans.
Réponse de référence : Vous pouvez travailler comme étudiant dès que vous avez 16 ans ou si vous avez 15 ans et avez suivi les deux premières années de l’enseignement secondaire.
Score : true
Motivation : The provided answer states that a student can work at 15 years old if they have completed the first cycle (“premier degré”) of secondary education, equivalent to the two first years of secondary education mentioned in the reference. It also notes that one can work at 16 years old. This information is factually accurate, complete, and addresses the question using precise terminology. Thus, the score should be: true.
Alignement des évaluations automatiques et manuelles
Si l’on compare les résultats de cet évaluateur d’exactitude avec les scores manuels, on constate dans notre test que le score LLM-as-judge est identique au score manuel dans 70 % des cas. Cela veut donc dire que les deux scores ne correspondent pas dans de nombreux cas. Cela s’explique par plusieurs raisons :
- Évaluations subjectives – Les évaluations manuelles sont subjectives. Ainsi, les réponses incomplètes sont évaluées de manière plus ou moins stricte selon l’évaluateur.
- Qualité des réponses de référence – La qualité des réponses de référence livrées par un expert du domaine joue un rôle important, car elle sert de référence. Elles doivent être complètes et clairement formulées.
- Méthode d’évaluation : l’évaluation manuelle repose sur trois scores (2 = correct, 1 = incomplet, 0 = incorrect). L’évaluateur d’exactitude testé utilise deux scores par défaut (true ou false). Il lui manque la nuance nécessaire pour attribuer, à une réponse correcte mais incomplète, un score qui soit tout de même positif dans une certaine mesure.
- Modèle de langage – Enfin, le modèle de langage utilisé par le LLM-as-judge joue également un rôle. Un reasoning model sera mieux à même de procéder à une bonne évaluation qu’un modèle de chat moins performant.
Dans le cas idéal, un évaluateur automatique juge de la même manière qu’un évaluateur humain, mais dans la pratique, il s’avère difficile d’aligner correctement les scores des évaluations automatiques sur ceux des évaluations manuelles.
Pour améliorer cet alignement, le LLM-as-judge peut être amélioré de manière itérative, par exemple par l’adaptation du prompt (instructions, méthode d’évaluation). En fait, le recours à un LLM en tant qu’évaluateur est en soi également un projet LLM dont la qualité doit être évaluée et peut être améliorée de manière itérative. Tout l’art consistera à commencer simplement et à améliorer progressivement la qualité de l’évaluateur. Dans tous les cas, la motivation textuelle de l’évaluateur d’exactitude peut être précieuse pour évaluer les réponses générées.
Quelles métriques utiliser ?
Dans la phase de développement, on dispose souvent de réponses de référence, ce qui nous permet de recourir à un évaluateur de correctness qui détermine simplement dans quelle mesure la réponse générée correspond à la réponse de référence. Des métriques complémentaires peuvent fournir des informations sur d’autres aspects de la RAG, comme la context precision, qui détermine quelle partie des chunks est pertinente, et le context recall, qui détermine combien de chunks pertinents ont été fournis. Dans l’illustration ci-dessous, ces métriques basées sur des références sont indiquées en jaune.
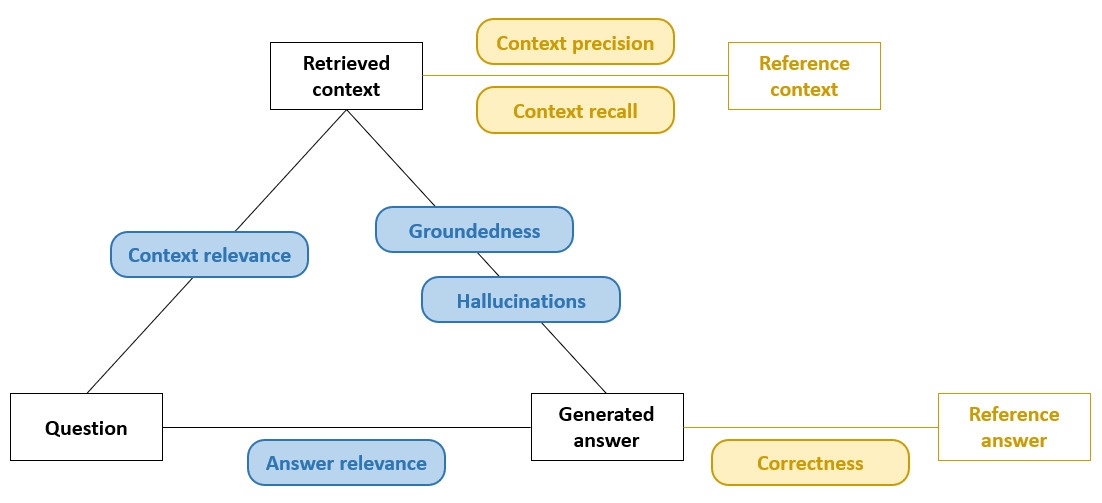
Lorsque de telles métriques sont nécessaires mais qu’aucune référence explicite n’est disponible, on peut recourir à des variantes approximatives (voir les métriques indiquées en bleu dans l’illustration ci-dessus) : par exemple, un LLM-as-judge qui compare la réponse générée au contexte extrait et restitue un score sémantique “close-enough”. Dans un environnement de production, les réponses de référence font presque toujours défaut ; l’accent est alors mis sur des métriques telles que l’hallucination detection ou la groundedness, qui déterminent si chaque affirmation dans l’output est réellement étayée par le contexte fourni. La qualité reste ainsi mesurable, même sans référence absolue. D’autres métriques approximatives sont la context relevance, qui évalue la correspondance sémantique des passages extraits à la question et peuvent donc servir de base à la génération, et l’answer relevance (helpfulness), qui évalue la correspondance de la réponse finale à la question.
Conclusion
L’IA générative est aujourd’hui en pleine effervescence, mais pour les organisations, la fiabilité de l’output figure parmi les critères majeurs pour pouvoir utiliser cette technologie en toute confiance. Dans un pipeline RAG, l’output généré est basé sur des connaissances du domaine, mais sans cadre d’évaluation robuste, sa qualité n’est pas suffisamment garantie. Il est donc important de miser sur la mesurabilité.
Commencez la phase de développement avec une batterie de tests compacte et représentative et des réponses de référence claires. Des métriques basées sur des références peuvent ensuite être appliquées, telles que la correctness, afin d’identifier rapidement les points sensibles. Une fois en production, vous pouvez passer à des métriques sans référence, telles que la groundedness et l’hallucination detection, afin de pouvoir également monitorer les questions inconnues.
Les évaluations automatiques basées sur le LLM‑as‑judge ne sont pas une solution miracle. Leur principal défi réside dans l’alignement : s’assurer que les scores automatiques correspondent autant que possible à l’avis des experts du domaine. Elles offrent néanmoins échelle et continuité : elles peuvent passer en revue de grands volumes d’output, signaler d’éventuels problèmes de qualité et procurer des points de référence objectifs pour ajuster de manière ciblée une application LLM ou RAG. La comparaison systématique de leur évaluation avec les évaluations manuelles et l’ajustement des prompts de l’évaluateur permettent d’améliorer continuellement l’application et l’évaluateur grâce à un processus itératif.
Ce post est une contribution individuelle de Bert Vanhalst, IT consultant chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.