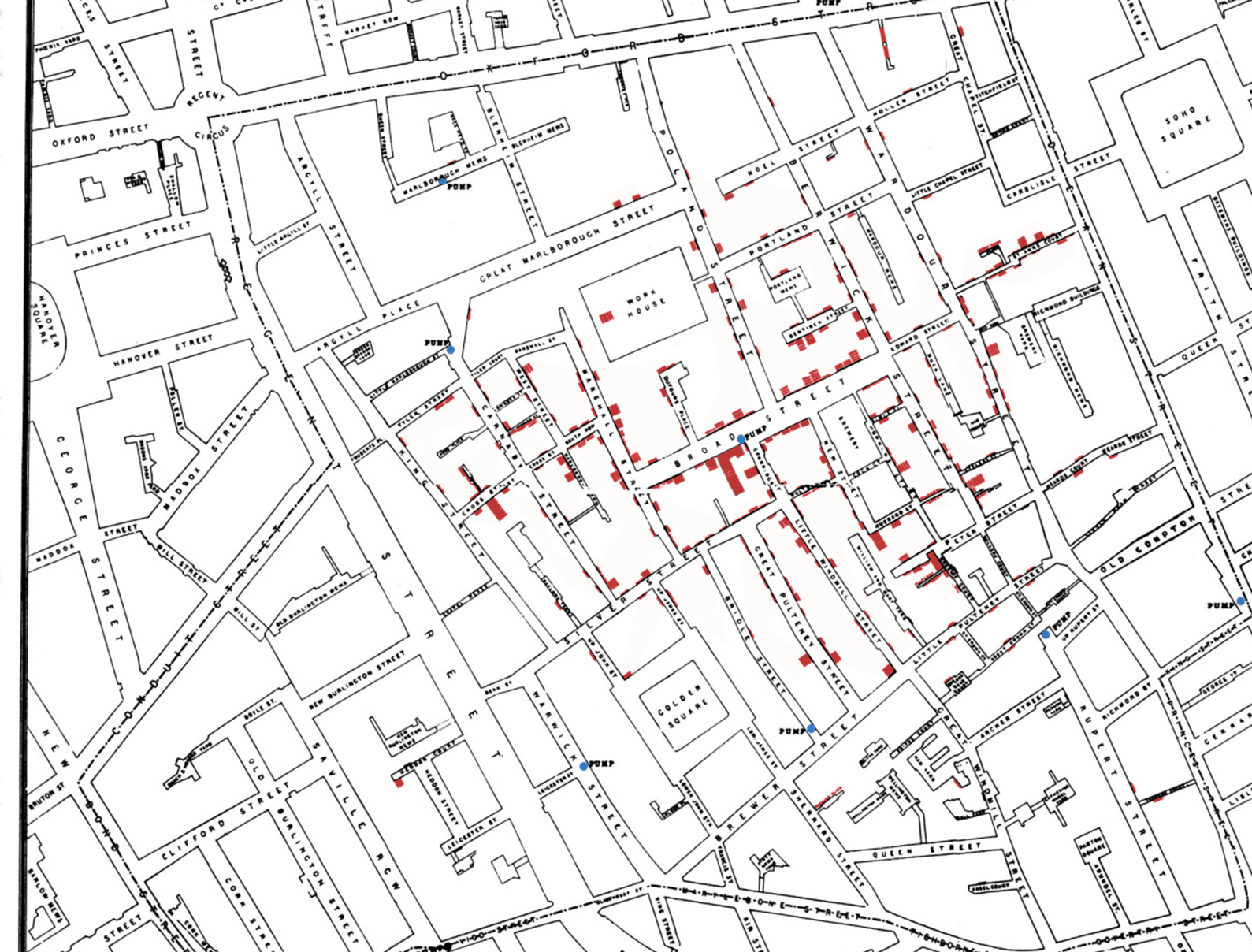
Nous sommes en plein cœur de Londres, quartier Soho. Fin août 1854, une épidémie de choléra fait rage, 616 personnes perdent la vie. La “théorie des miasmes”, qui estime que le choléra – comme la peste – se propage par l’air, convainc la majorité des scientifiques. Sauf un certain John Snow. Pour étayer son intuition, il a une idée aussi simple que géniale. Il répertorie l’adresse de chacun des décès, et les replace sur une carte (voir ci-contre, en rouge). L’évidence apparaît alors : les cas se répartissent de façon concentrique, autour du milieu de “Broad Street” (aujourd’hui “Broadwick Street”), et diminue à mesure qu’on s’en éloigne. Et au milieu de cette rue, se trouve justement une pompe à eau (point bleu sur la carte, encore visible à l’heure actuelle) !
Le contexte d’aujourd’hui a changé, mais le besoin est plus que jamais présent : à partir d’une liste d’adresses de clients, de patients, de citoyens, de chantiers, de succursales, de nombreuses sociétés ou organismes publiques ont besoin de visualiser des données sur une carte. Si John Snow, connaissant bien le quartier, a pu localiser sur une carte chaque adresse de sa liste, cette opération peut aujourd’hui se faire automatiquement : c’est le rôle d’un géocodeur.
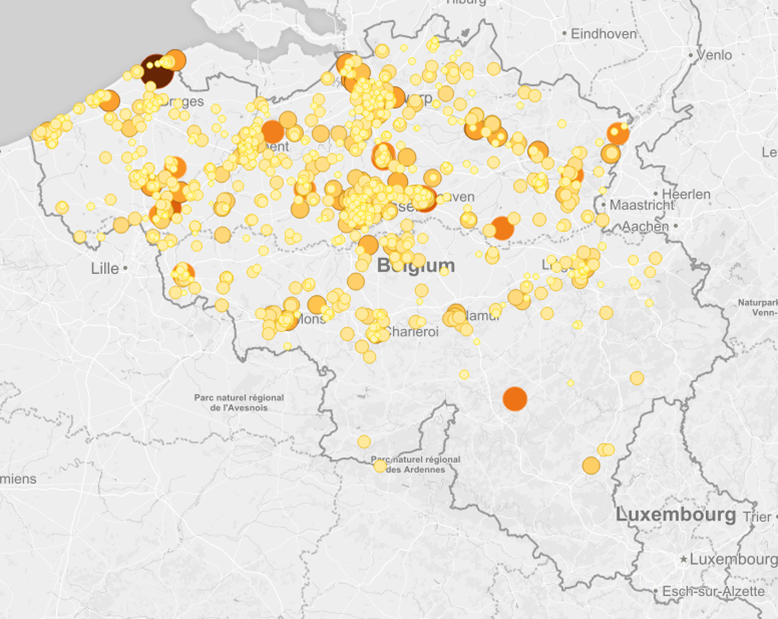
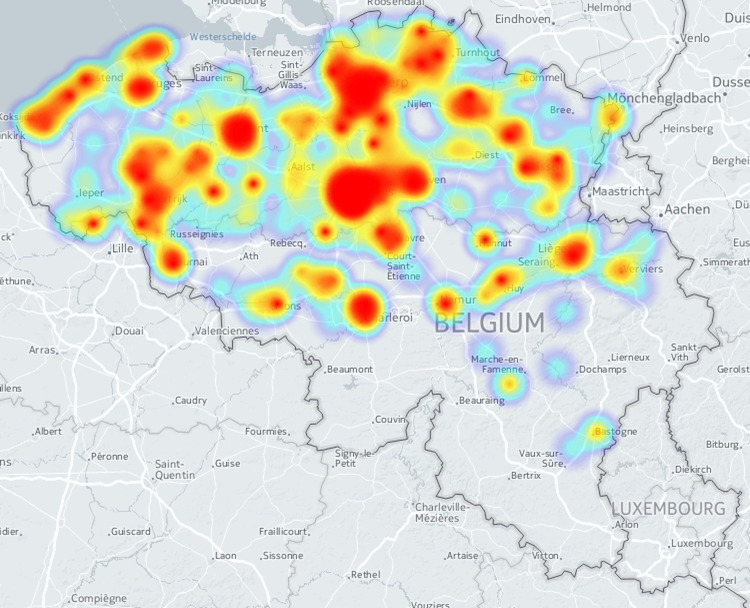
À partir d’une adresse postale (Rue Fonsny 20, 1060 Bruxelles), un géocodeur fournit typiquement un couple de coordonnées géographiques : 50.8361263, 4.3382716 (selon le standard WGS84, utilisé entre autres par les GPS, et qui diffère de la notation traditionnelle apprise à l’école : 50°50’10.1″N, 4°20’17.8″E). Une fois la liste des coordonnées obtenue, on peut typiquement en réaliser une carte de type “bubble” (la taille et la couleur des points pouvant dépendre d’un paramètre quelconque), ou une “heatmap”, mettant en évidence la densité des points.
Géocodeurs
Il existe de nombreux outils permettant ce géocodage. Une partie de ces outils sont des interfaces web simples, dans lesquelles on envoie typiquement un fichier (listing Excel, par exemple), dont chaque adresse est géocodée avant, pour certains, d’être affichée sur une carte : Google Fusion Table, CartoDB, BatchGeo ou EasyMapMaker en sont quelques exemples. En version gratuite, ces outils sont cependant assez contraignants. Soit le débit est fortement limité, soit le nombre de requêtes est limité à quelques dizaines, voire quelques centaines par mois.
Dans la suite de cet article, nous allons nous intéresser à des outils moins “grand public”, nécessitant un peu de programmation (dont nous passerons les détails), et ayant des contraintes nettement moins limitatives. Il s’agit d’API (Application Programming Interface) que l’on invoque soit via un script, soit, dans notre cas, via un outil tel qu’OpenRefine. Nous allons considérer les API de Google (Google Maps), OpenStreetMap, Microsoft (Bing), Nokia (Here), MapQuest, OpenCageData, ainsi qu’une version Beta de l’Institut Géographique National belge (uniquement pour les adresses en Belgique).
L’usage est en général assez simple. Par exemple, avec Google Maps, pour géocoder l’adresse “Avenue Fonsny 20, 1060 Bruxelles”, il suffit d’invoquer l’URL suivante (cliquer dessus pour voir le résultat) :
Deux informations nous intéressent dans le résultat : les coordonnées géographiques, bien sûr, mais également la fiabilité (ou confidence, en anglais) du résultat. Dans notre cas, “RANGE_INTERPOLATED”, qui signifie que Google ne connaît pas la position exacte du numéro 20 de l’Avenue Fonsny, mais qu’il l’a interpolée à partir d’autres numéros de la même rue pour lesquelles il connait la localisation. Il se peut par exemple que Google Maps soit capable de localiser la ville, mais pas la rue. Il donnera alors la position du centre de la ville, et précisera comme qualité “GEOMETRIC_CENTER”.
Toutes les API n’ont cependant pas la même façon de préciser la fiabilité du résultat. Il s’agit parfois d’une valeur entre 0 (très précis) et 10 (très peu précis), parfois de valeurs telles que “High”, “Medium” ou “Low”.
Comparer la qualité
Ce n’est bien sûr pas parce qu’un géocodeur retourne des coordonnées et précise qu’elles sont d’une fiabilité optimale que le résultat est correct. Par exemple, la commune de Mons (province du Hainaut) est composée de plusieurs localités, dont Frameries (Code postal : 7022) et Jemappes (Code postal : 7012). À Frameries, il existe une rue nommée “Avenue Général Leman”, et à Jemappes, à 5 kilomètres de là, une “Rue du Général Leman”. Si l’on demande à Bing de localiser “Rue Léman, 7012 Mons”, il localise en fait l’Avenue Léman à 7022 Frameries, alors que Google Maps propose bien celle de Jemappes. Les deux géocodeurs annoncent par ailleurs un niveau de fiabilité élevé.
Si l’on veut comparer les performances de plusieurs géocodeurs, on trouve dans la littérature (par exemple ici) une méthodologie qui consiste à se construire un grand ensemble d’adresses, dont on connaît les coordonnées géographiques précises, puis de les soumettre aux géocodeurs à tester pour voir à quel point les réponses sont compatibles avec la connaissance préalablement acquise.
Méthodologie
L’inconvénient majeur de cette méthodologie est qu’il faut construire une telle base de connaissance, représentative de données qui seront ensuite utilisées. On ne pourra avec une telle méthodologie que comparer des régions connues des testeurs. Si deux géocodeurs orthographient une rue différemment, il faudrait quasiment se rendre sur place pour voir lequel se trompe. Nous proposons ici d’utiliser une méthodologie plus abordable, ne nécessitant aucune connaissance au préalable. L’idée est très simple : on part d’une liste d’adresses importante, et on géocode ensuite chacune de ces adresses avec une série de géocodeurs différents.
Supposons que pour une adresse, cinq géocodeurs la localise dans un périmètre restreint, mais qu’un sixième géocodeur la situe à plusieurs kilomètres. On va supposer dans nos tests que ce dernier se trompe probablement, et on considère que si un géocodeur, pour un grand nombre d’adresses, se situe loin des autres, c’est qu’il est vraisemblablement de qualité moindre. Cette méthodologie n’a aucune prétention scientifique sérieuse. Il s’agit juste d’une réflexion, qui n’a pas été poussée aussi loin que si l’on se plaçait dans un contexte scientifique, mais qui nous a permis de nous éclairer dans une situation concrète rencontrée dans un contexte professionnel.
Pour nos tests, nous avons considéré un ensemble de 10.000 adresses provenant de la Banque Carrefour des Entreprises en Belgique, disponibles en Open Data. 98.4% de ces entreprises ont leur adresse en Belgique, les autres à l’étranger. Il conviendra bien sûr de prendre des données propres à la région ou au pays pour lequel on souhaite tester les géocodeurs. La qualité des données est quelque part conforme à ce que l’on trouve en pratique. Par exemple, il manque le nom de la rue dans 0.4% des cas, le champ “numéro” contient autre chose qu’un numéro dans 2.1% des cas.
Nous avons réalisé les géocodages en utilisant l’outil OpenRefine, et l’analyse a ensuite été faite avec Qlik Sense.
Match rate
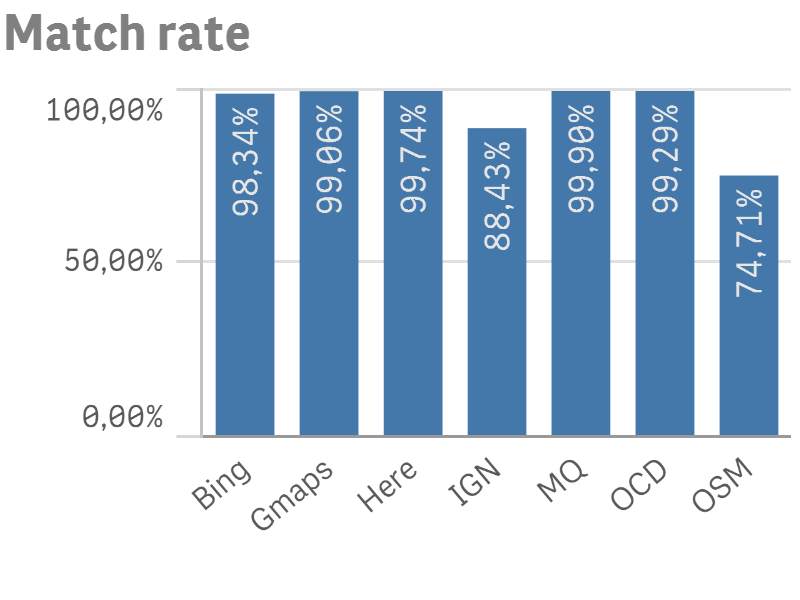
Une première métrique simple que nous avons considérée est le “Match rate”, à savoir la proportion d’adresses pour laquelle un géocodeur fournissait une réponse. On voit par exemple qu’OpenStreetMap (OSM) n’a pas pu géocoder à peu près un quart de nos adresses, alors que MapQuest (MQ) arrive à 0.01% d’échec. Le géocodeur (en phase Beta) de l’IGN (belge) a également encore du progrès à faire.
Un haut “match rate” n’implique bien sûr pas une bonne qualité, mais on pourrait déjà être amené, à ce stade, à écarter l’IGN et OpenStreetMap des compétiteurs.
Écart par rapport à la médiane

Pour évaluer si un géocodeur est éloigné de la majorité, nous considérons comme référence le point médian, c’est-à-dire un point laissant autant de points à droite qu’à gauche, et autant en bas qu’en haut. En effet, s’il y a un consensus, ce point se trouvera en général au cœur de ce consensus. Notons que ce point médian peut faire partie de l’ensemble (si la latitude médiane est fournie par le même point que la longitude médiane) ou être virtuellement ajouté.
Dans l’exemple ci-dessus, le point médian est en rouge. On peut voir qu’un résultat est très éloigné du point médian, alors que 5 en sont très proches. Notons que si nous avions pris la moyenne et non la médiane, le point moyen aurait été situé entre agrégat de gauche et le point à droite, et tous les résultats auraient été considérés comme éloignés de la référence.
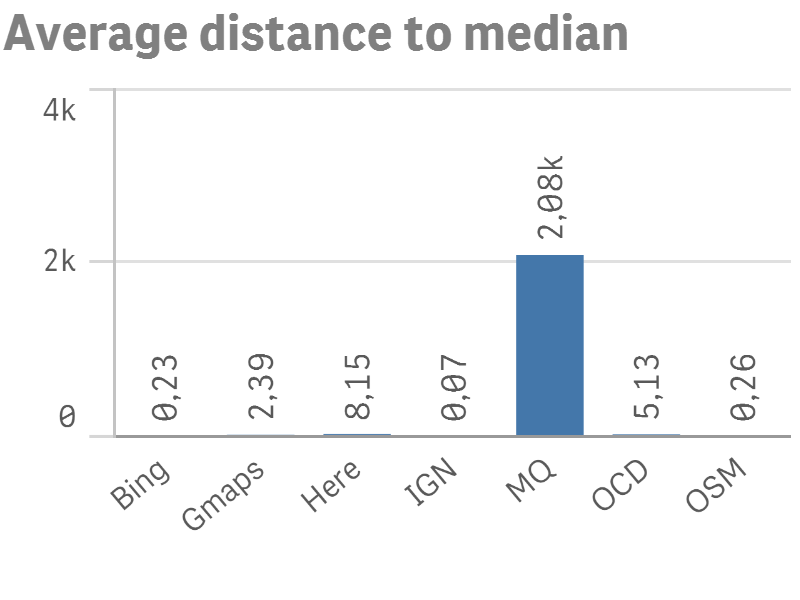
Le graphique ci-contre reprend la distance moyenne en kilomètres (par approximation équirectangulaire) pour l’ensemble des adresses par rapport à leur médiane respective, pour chaque géocodeur. Plus la valeur est élevée, plus on s’éloigne souvent du consensus, et donc, selon notre méthodologie, moins bon est le géocodeur.
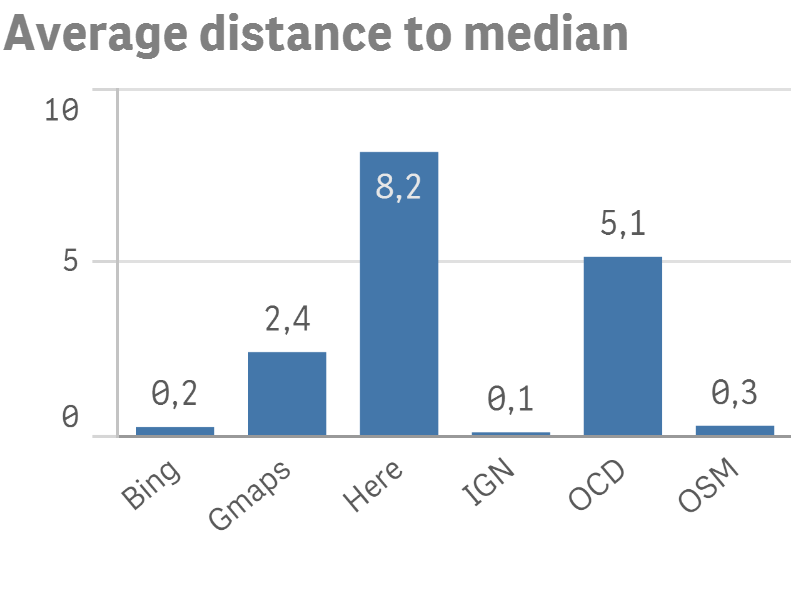
On constate très facilement que MapQuest, qui obtenait le meilleur match rate, est de très loin moins performant que tous les autres. En moyenne, les adresses géocodées par MapQuest sont localisées à plus de 2000 km des autres géocodeurs ! En poussant un peu plus loin l’analyse, on se rend compte que pour à peu près 25% des adresses, MapQuest ne parvient pas à localiser l’adresse, et, plutôt que de retourner un code d’erreur ou un résultat vide, localise l’adresse … au milieu des États-Unis ! Clairement donc à éliminer, en tout cas pour des adresses sur le territoire belge. Le graphique de droite supprime MapQuest.
Ce qui surprend maintenant, ce sont les mauvais résultats de Here (8 kilomètres du point médian en moyenne !), et OpenCageData (OCD), près de 5 kilomètres. Ces mauvais scores ont en fait des raisons très différentes, que nous allons maintenant détailler.
Here victime de son succès
Comme on a pu le voir plus haut, le “match rate” (proportion d’adresses pour lequel un géocodeur a fourni une réponse) est loin d’atteindre 100 % pour chaque adresse. Ce qui signifie que chaque adresse n’a pas 7 points (le nombre de géocodeurs de notre analyse) à comparer. Dans les faits, 70 % des adresses ont pu être géocodées (correctement ou non) par chacune des 7 API, 23 % par seulement 6, puis 5.7 % (5 géocodeurs), 1.1% (4), 0.2 % (3), 0.3 % (2) et 0.07 % (1).
Or, Here et MapQuest sont les deux géocodeurs avec le meilleur match rate, et un nombre non négligeable d’adresses ont été situées uniquement par MapQuest aux États-Unis (comme expliqué ci-dessus), et par Here au bon endroit, avec un écart dépassant souvent les 10.000 kilomètres. Or la médiane entre deux nombres est, dans l’outil que nous avons utilisé (Qlik Sense), la moyenne de ceux-ci. Ce qui nous fait un point de référence au milieu de l’océan Atlantique, les deux points étant alors considérés comme de 4 à 5000 kilomètres du point médian.
Pour éviter ce biais, nous pouvons supprimer toutes les adresses ayant été géocodées avec succès par moins de quatre géocodeurs (soit une soixantaine d’adresses). En supprimant de la comparaison 0.6 % des adresses, on obtient un résultat pour Here nettement meilleur, comme le montre le graphique ci-dessous.
OpenCageData : souvent uniquement la ville
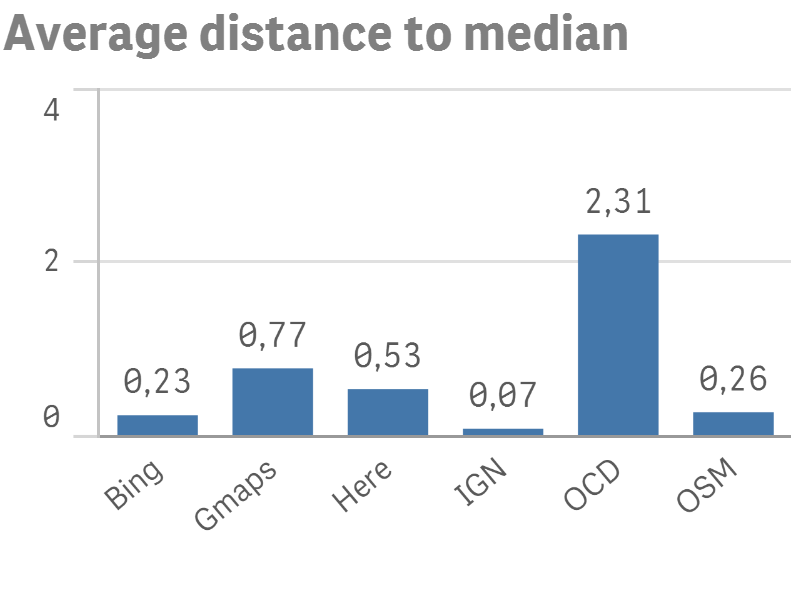
On voit maintenant qu’OpenCageData (OCD) possède la distance moyenne à la médiane la plus élevée : plus de deux kilomètres ! Si un GPS avait cette précision-là, on aurait du mal à trouver son chemin !
Mais l’on peut s’intéresser au niveau de fiabilité associé à ces adresses. Pour chaque adresse géocodée, OpenCageData retourne également une valeur entre 0 (peu fiable) et 10 (très fiable). Sur les 10.000 adresses à géocoder, 3800 ont reçu un code “0”. Et en effet, pour la plupart de ces adresses, l’API a été capable de trouver la ville, mais pas la rue. On a donc des coordonnées qui correspondent au centre de la ville. Si l’on ne s’intéresse qu’à ces adresses-là, la distance moyenne à la médiane est de 4 kilomètres (pour un peu moins d’un kilomètre pour les autres, ce qui reste important).
On peut également remarquer que l’IGN et OpenStreetMap, même si elles n’ont pas un très bon “match rate”, semblent avoir une bonne précision (si l’on accepte le postulat que le point médian est, en générale, une approximation acceptable de la bonne réponse). Il semblerait que ces outils, contrairement à MapQuest, préfèrent, quand ils ne sont pas sûrs de la réponse, ne pas répondre plutôt que de donner une réponse aléatoire.
En dehors de l’IGN (qui n’a marché que sur 88% des adresses), le géocodeur qui se comporte le mieux par rapport au point médian est Bing, de Microsoft. La distance moyenne par rapport au point médian est de 230 mètres.
Distribution

Si la moyenne d’un ensemble de valeurs donne une information intéressante sur cet ensemble, la distribution complète est beaucoup plus riche. C’est ce que montre le graphique ci-contre. Il y regroupe les adresses par distance à la médiane, pour chaque géocodeur. On peut par exemple y voir que pour Bing et Here (bleu clair et turquoise), 85 % des adresses ont été géocodées dans un rayon de 100 mètres par rapport à la médiane et 10% entre 100 mètres et un kilomètre. On y voit également que pour OpenCageData, environ un tiers des adresses sont dans un rayon de 100 mètres par rapport à la médiane ; un autre (petit) tiers entre 100 mètres et 1 kilomètres, et un dernier tiers entre 1 et 10 kilomètres. On peut aussi apercevoir le pic que MapQuest présente entre 1000 et 10.000 kilomètres ; il s’agit des +/-25% d’adresses localisées aux États-Unis.
Selon notre méthodologie, on peut estimer que plus une distribution est “collée sur la gauche” (c’est-à-dire place un maximum de résultats dans la case 0-100 mètres), meilleure elle est. Google Maps et l’IGN restent dans le groupe de tête, juste derrière Here et Bing.
Conclusion
Si le postulat de base (le point médian est une bonne approximation de la position correcte) est contestable, il nous a permis néanmoins de mettre en évidence des problèmes que nous aurions difficilement pu localiser autrement : les 25% d’adresses que MapQuest localise erronément au milieu des États-Unis, ou les 38% d’adresses pour lesquelles OpenCageData localise la ville mais pas la rue. Nous avons le sentiment, suite à notre analyse, que Here et Bing fournissent des réponses de meilleure qualité que Google Maps, mais une étude plus poussée serait clairement nécessaire pour en avoir la certitude.
Si la méthodologie peut s’appliquer pour toute région géographique, les conclusions que nous tirons ici ne sont valables que pour des adresses majoritairement localisées sur le territoire belge. Il se pourrait par exemple très bien que pour des adresses américaines, MapQuest surpasse tous les autres.
Le modèle souffre encore de certains défauts, sources d’améliorations futures. On pourrait par exemple, avant de considérer le point médian comme référence, s’assurer qu’il se situe bien au sein d’un cluster de petite taille. Il arrive par exemple qu’une adresse soit localisée par seulement trois géocodeurs, une fois à la côte belge, une fois dans le fin fond des Ardennes et troisième fois en Amérique du Sud. Ce genre de cas devrait être éliminés de la comparaison, parce qu’aucun de ces trois points n’a de raison de servir de point de référence. Nous l’avons fait, mais cela n’a pas eu un impact notable sur les conclusions (si ce n’est que Here dépasse alors légèrement Bing en termes de distance moyenne par rapport au point médian).
Il serait également intéressant, avoir d’effectuer le géocodage, de faire passer la liste d’adresses par un outil de “Data Quality”, de façon à nettoyer toutes les adresses incomplètes ou mal formatées. Ou encore, quand cela s’applique, de comparer la différence entre fournir une adresse sous forme d’une seule chaîne de caractères, ou bien déjà découpée en ses différents composants (rue, numéro, code postal…).
On peut aussi, au lieu de s’intéresser à la distance au point médian, au nombre de fois que l’on s’en éloigne de, par exemple, plus d’un kilomètre. Nous serons bien évidemment heureux de faire une analyse plus poussée avec nos clients et partenaires qui en feront la demande !