Artificiële intelligentie en machine learning spelen een steeds grotere rol in de menselijke samenleving ter ondersteuning van besluitvormingsprocessen. De aandacht naar hun eerlijkheid (fairness) is de afgelopen jaren dan ook steeds belangrijker geworden. Predictieve modellen kunnen namelijk problematisch worden wanneer ze biases (vooringenomenheden) die ze tijdens hun trainingsfase uit historische gegevens hebben geleerd, beginnen te reproduceren of versterken. Deze bias leidt vaak tot discriminatie van een of meer groepen individuen. Dit is vooral problematisch in het kader van gevoelige beslissingen, zoals het verwerken van sollicitaties, het toekennen van leningen of justitie. Dit artikel gaat in op de manier waarop deze algoritmische bias kan worden gemeten en op de verschillende manieren om deze te corrigeren om eerlijke voorspellingen te genereren.
Zoals we al in een eerdere blogpost hebben besproken, kan een bias verschillende oorzaken hebben. Het kan bijvoorbeeld gaan om een designfout in het algoritme zelf, een ondervertegenwoordiging van een groep in de trainingsdata, of om historische data die bevooroordeeld is door racisme/seksisme in de samenleving [1]. In dit artikel richten we ons op het geval waarin het probleem bij de gegevens ligt en niet bij het model zelf, namelijk wanneer het model leert op basis van bevooroordeelde gegevens en deze vooringenomenheid vervolgens reproduceert in zijn voorspellingen.
Een van de bekendste voorbeelden is de COMPAS-case. Het COMPAS-algoritme werd gebruikt in de Verenigde Staten om het risico op recidive van gedetineerden in het kader van een mogelijke vervroegde vrijlating in te schatten. In 2016 stelde een studie van ProPublica dat Afro-Amerikanen door het algoritme werden gediscrimineerd omdat ze meer kans hadden om als “high-risk” te worden geclassificeerd. De studie stelde meer bepaald dat een persoon met een donkere huidskleur meer kans had om ten onrechte als “high-risk” te worden geclassificeerd en dat een blanke daarentegen meer kans had om ten onrechte als “low-risk” te worden geclassificeerd. Deze zaak leidde tot een groot debat en de publicatie van honderden artikelen over dit onderwerp.
In het geval van COMPAS, lag het probleem niet bij het algoritme zelf, maar eerder bij de gegevens waarop het was getraind. Het model was namelijk getraind op historische strafrechtelijke gegevens die een systematische racistische vooringenomenheid weerspiegelen, zoals discriminerende politiepraktijken. Deze bevooroordeelde gegevens leidden er dus toe dat het model eveneens vooroordelen vertoonde in zijn voorspellingen.
Hoe meet je de oneerlijkheid van een model?
Problemen met fairness veronderstellen het bestaan van een zogenaamde gevoelige variabele. Dit is de variabele waarvoor men geen discriminatie wenst. Het kan bijvoorbeeld gaan om het geslacht of de etnische afkomst van een persoon. De gevoelige variabele is vaak categorisch, maar kan, afhankelijk van het geval, ook continu zijn (bijvoorbeeld de leeftijd van een persoon). Voor het gemak gaan we ervan uit dat er slechts een gevoelige variabele is, maar in sommige problemen kunnen er meerdere zijn.
Op basis van deze gevoelige variabele worden doorgaans twee groepen gedefinieerd. De groep die door het model negatief wordt gediscrimineerd, wordt de “beschermde groep” genoemd.
Stel dat we een predictief model hebben dat voorspellingen moet doen over het toekennen van een lening. Dit algoritme wordt als “eerlijk” beschouwd als de kans dat een persoon voor de lening wordt geselecteerd (positieve beslissing van het model) gelijk is, ongeacht de groep waartoe de persoon behoort. Wiskundig gezien willen we dus het volgende opleggen:
P(Yd = 1 | Z = 1) = P(Yd = 1 | Z = 0)
waarbij Yd de beslissing van het model is en Z een binaire variabele die aangeeft of een persoon al dan niet behoort tot de beschermde groep. Deze kansen worden berekend op groepsniveau, niet op individueel niveau.
Een bekende maatstaf voor algoritmische oneerlijkheid is dus gewoon het verschil tussen deze twee termen. Indien er een verschil is, betekent het dat het model een van de twee groepen bevoordeelt. Deze maatstaf voor het verschil tussen voorspellingen binnen de twee groepen wordt “demographic parity” of “statistical parity” genoemd.
Hoewel deze maatstaf relatief eenvoudig is, is dit een van de bekendste op het gebied van algoritmische rechtvaardigheid, die algemeen wordt erkend en gebruikt. Het is echter duidelijk niet de enige maatstaf die bestaat (voor enkele alternatieven, zie bijvoorbeeld [2, 3]). Opgemerkt moet worden dat, aangezien demographic parity wordt gemeten op groepsniveau, het een maatstaf is voor groepsrechtvaardigheid (group fairness). Er bestaan ook alternatieve maatstaven op individueel niveau (individual fairness).
Waarom wordt de gevoelige variabele niet gewoon uit het model verwijderd?
Op het eerste gezicht lijkt het probleem eenvoudig op te lossen. Een voorspellend machine learning-model neemt gegevens X als input en voorspelt een variabele Y als output op basis van de gegevens in X. Het zou dus in principe voldoende zijn om de variabele Z niet op te nemen in de gegevens X, zodat de voorspellingen van het model niet meer worden beïnvloed door Z.
Helaas zijn de variabelen waaruit X bestaat in de praktijk zelden onafhankelijk van elkaar. De database X kan dus variabelen bevatten die gecorreleerd zijn met de gevoelige variabele, het model kan deze variabelen gebruiken als proxy van de gevoelige variabele en vertekende voorspellingen geven, ook al maakt Z niet expliciet deel uit van de gebruikte inputgegevens. Zo kan in een steekproef het inkomen van een persoon worden gebruikt als proxy voor zijn leeftijd, omdat het inkomen van personen doorgaans stijgt naarmate ze ouder worden.
In het geval van COMPAS werd de etnische afkomst van de gedetineerde bijvoorbeeld niet expliciet gebruikt in het model als variabele, maar door de aanwezigheid van gecorreleerde proxyvariabelen (bijv. postcode, sociaaleconomische indicatoren) werd de raciale vertekening altijd weerspiegeld in de voorspellingen van het model.
Hoe een algoritmische bias in de praktijk corrigeren?
Er onderscheiden zich drie grote families van correcties: voorbewerking (“pre-processing”: het verwijderen van de bias uit de trainingsdata), verwerking (“in-processing”: het verwijderen van de bias tijdens het trainen van het model) en nabewerking (“post-processing”: het verwijderen van de bias uit een getraind model). Deze benaderingen hebben elk hun voor- en nadelen en zijn uitgebreid beschreven in tal van publicaties. De geïnteresseerde lezer kan de volgende survey raadplegen [4], waarin de verschillende publicaties op het gebied van fairness zijn verzameld en geordend per aanpak (pre-, in-, post-processing), per type algoritme (logistische regressie, random forest, neurale netwerken, enz.), per gebruikte fairness-maatstaf, enz. Dit biedt een goed gestructureerd overzicht van wat er op dit gebied wordt gedaan.
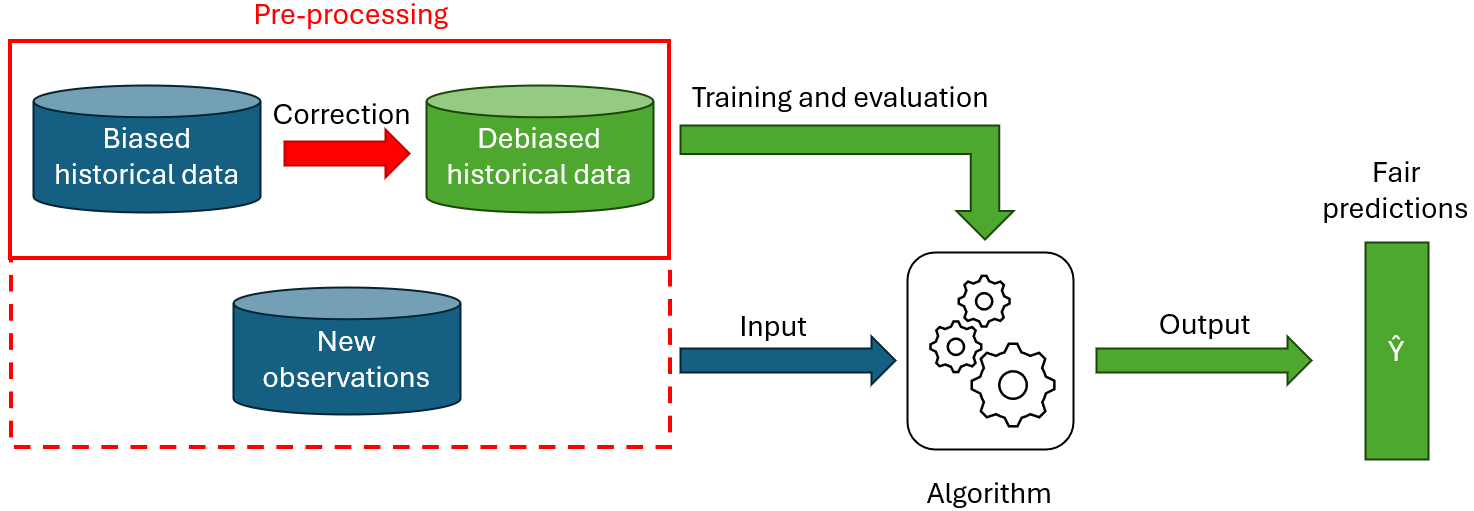
Pre-processingsmethoden
Het idee is eenvoudig: de trainingsgegevens ontdoen van vooringenomenheid om ze dichter bij de werkelijkheid te brengen, zodat de vooroordelen niet in het machine learning-model terechtkomen. Enkele voorbeelden van pre-processingsmethoden zijn:
- De steekproef (sampling) opnieuw in evenwicht brengen (door waarnemingen toe te voegen of te verwijderen);
- De inhoud van bepaalde variabelen van data X corrigeren of zelfs volledig vervangen door nieuwe variabelen (representational learning) die geen gevoelige informatie bevatten;
- Het label (variabele Y) van bepaalde waarnemingen wijzigen.
Pre-processing biedt het voordeel dat het niet afhankelijk is van het gebruikte model en dat het doorgaans eenvoudig uit te leggen en te begrijpen is. Het correct corrigeren van historische gegevens kan echter ingewikkeld zijn en het is moeilijk om de fairness van het resulterende model te garanderen. Ook moet het risico van verlies aan nauwkeurigheid worden vermeld, aangezien het wijzigen van data mogelijk relevante patterns uit de data verwijdert.
Figuur 2 toont hoe fairness wordt toegevoegd via een pre-processing-aanpak. Zoals uit het schema blijkt, is pre-processing niet altijd noodzakelijk voor nieuwe data. Sommige methoden (bijv. resampling, relabeling) vereisen enkel een wijziging van de trainingsdata om te voorkomen dat het algoritme de bias leert. Sommige algoritmen (bijv. representation learning) vereisen echter ook dat de nieuwe te voorspellen waarnemingen worden gewijzigd.
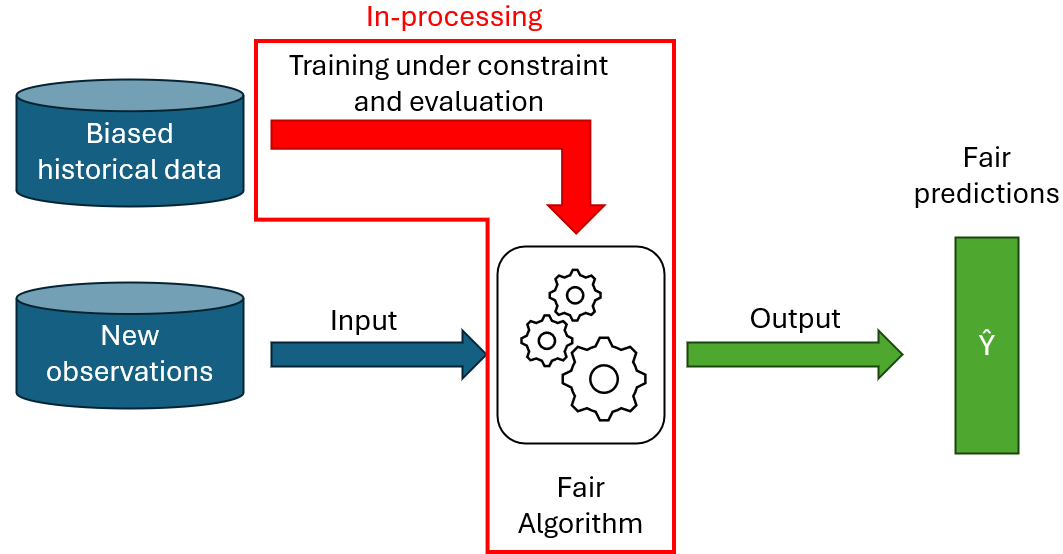
In-processing-methoden
Deze methoden bestaan uit het rechtstreeks wijzigen van het voorspellingsmodel zelf, zodat de voorspellingen fair zijn. Dit kan bijvoorbeeld worden gedaan door een regularisatieterm toe te voegen aan de doelfunctie van het algoritme, of door er fairness-beperkingen aan toe te voegen.
In-processing-methoden hebben het voordeel dat, zodra het model is getraind, fairness direct in het model wordt opgenomen en het model vrij kan worden gebruikt, zonder dat de invoergegevens of de voorspellingen van het model verder hoeven te worden aangepast. Bovendien biedt het rechtstreeks wijzigen van het model een grote flexibiliteit, omdat complexe fairness-beperkingen kunnen worden gecodeerd.
Deze grote flexibiliteit vereist echter voldoende theoretische en praktische kennis om het algoritme zelf te kunnen wijzigen. Bovendien kan het aanbrengen van wijzigingen in een model, zoals beperkingen, de trainingstijd aanzienlijk verlengen. Aangezien in-processing-methoden de training van een algoritme wijzigen, zijn de meeste gepubliceerde methoden doorgaans specifiek voor een bepaald model.
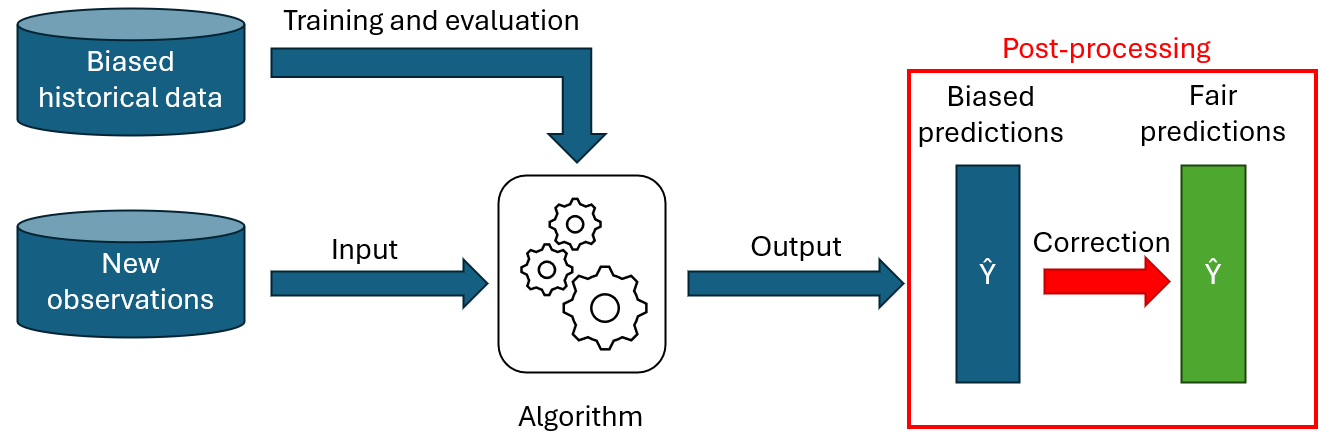
Post-processingsmethoden
Bij de laatste benadering worden het model en de historische data niet aangepast, maar worden de voorspellingen van het model aangepast om aan de fairness-beperkingen te voldoen. Een post-processing-algoritme wijzigt dus meestal ofwel de waarschijnlijkheid dat een waarneming tot de door het model voorspelde klassen behoort, ofwel rechtstreeks de beslissingen (definitieve classificaties) voor bepaalde waarnemingen.
Post-processingsalgoritmen zijn eenvoudig te implementeren: ze zijn onafhankelijk van het gebruikte voorspellingsmodel en kunnen dus worden gebruikt met ‘black-box’-modellen. Bovendien vereist post-processing geen wijzigingen aan de gegevens of het model en blijft de integriteit van het bestaande proces dus behouden.
Dit soort methoden leidt echter doorgaans tot een groter verlies aan modelprestaties dan het gebruik van in-processingsmethoden. Een model vrij trainen en vervolgens achteraf de voorspellingen aanpassen om aan bepaalde beperkingen te voldoen, is namelijk vaak minder effectief dan een model dat specifiek is geoptimaliseerd om voorspellingen te doen die aan de beperkingen voldoen.
Eerlijke voorspellingen evalueren
Vanaf het moment dat beperkingen aan de voorspellingen van een model worden toegevoegd of de toegang tot bepaalde informatie wordt beperkt, zal dit de classificatieprestaties van het model logischerwijs verminderen. Het integreren van fairness in een classificatieprobleem houdt dus in dat er een juiste balans moet worden gevonden tussen de nauwkeurigheid van het model en de fairness ervan.
Bovendien is het raadzaam om, zelfs wanneer een evenwicht tussen nauwkeurigheid en eerlijkheid is gevonden, altijd te controleren welke wijzigingen het toevoegen van fairness-beperkingen met zich meebrengt.
Een voorbeeld ter illustratie: stel dat een algoritme voorspellingen doet die bevooroordeeld zijn en relatief meer gunstige beslissingen neigt te nemen voor leden van groep A dan voor leden van groep B. Het risico bestaat dat het algoritme bij de invoering van een fairness-beperking reageert door simpelweg het aantal gunstige beslissingen voor groep A te verminderen om hetzelfde niveau als groep B te bereiken. Dit nieuwe model is dus in theorie eerlijker dan het vorige, maar het is duidelijk slechter omdat deze eerlijkheid alleen is bereikt door een van de groepen te benadelen.
Dit voorbeeld illustreert hoe belangrijk het is om bij het invoeren van eerlijkheid in een model niet alleen te kijken naar prestatiemaatstaven (accuracy, demographic parity, enz.), maar ook te onderzoeken hoe de beslissingen van het model in de praktijk worden beïnvloed.
Conclusie
In dit artikel hebben we gezien hoe de oneerlijkheid van een machine learning-model kan worden gemeten. Ook hebben we een overzicht gegeven van de verschillende benaderingen die worden gebruikt om te voorkomen dat het model een in de historische gegevens aangeleerde bias reproduceert of versterkt.
Belangrijk is dat de verschillende benaderingen elkaar niet uitsluiten en vaak kunnen worden gecombineerd (bijvoorbeeld voorbewerking van de trainingsdata, gevolgd door een in-processing-methode op het model). Sommige publicaties op dit gebied stellen methoden voor die op verschillende niveaus van het classificatieproces werken.
Referenties
[1] Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. (2021). A survey on bias and fairness in machine learning. ACM computing surveys (CSUR), 54(6), 1-35.
[2] Castelnovo, A., Crupi, R., Greco, G., Regoli, D., Penco, I. G., & Cosentini, A. C. (2022). A clarification of the nuances in the fairness metrics landscape. Scientific Reports, 12(1), 4209.
[3] Corbett-Davies, S., Gaebler, J. D., Nilforoshan, H., Shroff, R., & Goel, S. (2023). The measure and mismeasure of fairness. Journal of Machine Learning Research, 24(312), 1-117.
[4] Hort, M., Chen, Z., Zhang, J. M., Harman, M., & Sarro, F. (2024). Bias mitigation for machine learning classifiers: A comprehensive survey. ACM Journal on Responsible Computing, 1(2), 1-52.
Voor een soortgelijk onderwerp, zie de blogpost IA : L’éthique en pratique.
Dit is een ingezonden bijdrage van Pierre Leleux, data scientist et network data analyst bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.
Leave a Reply