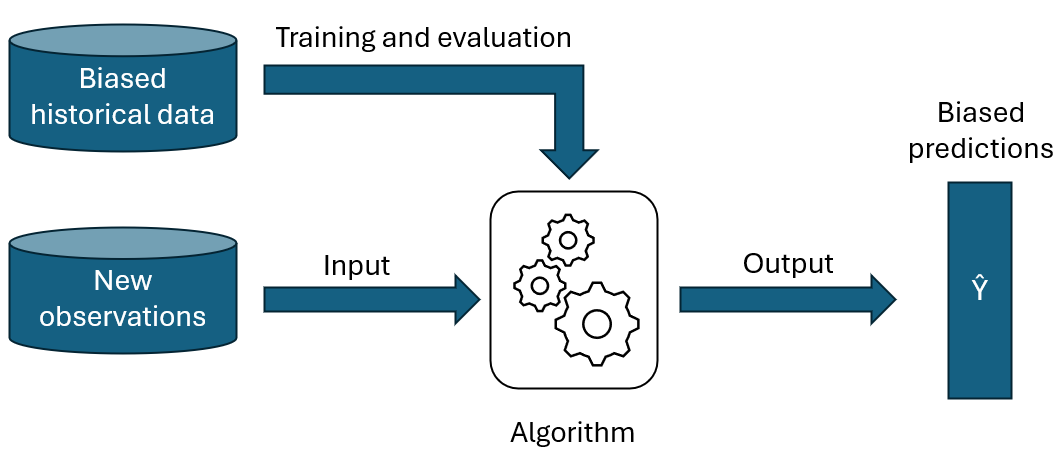
Tandis que l’intelligence artificielle et le machine learning jouent un rôle croissant dans la société humaine pour soutenir les processus de prise de décision, les préoccupations concernant leur équité (fairness) ont attiré l’attention au cours des dernières années. Les modèles prédictifs peuvent en effet devenir problématiques lorsqu’ils commencent à reproduire ou renforcer des biais qu’ils ont appris dans les données historiques utilisées durant leur phase d’entrainement. Ce biais crée souvent une discrimination injuste à l’encontre d’un ou plusieurs groupe(s) d’individus, ce qui est particulièrement problématique dans le cadre de décisions sensibles, telles que le traitement de candidatures d’emploi, l’accord de prêts ou la justice, entre autres. Cet article s’intéresse à la manière dont ces biais algorithmiques peuvent être mesurés et les différentes façons de les corriger pour générer des prédictions équitables.
Comme nous en avions déjà discuté dans un précédent article de blog, un biais peut avoir plusieurs sources. Il peut par exemple s’agir d’un problème de design de l’algorithme en lui-même, d’un souci de sous-représentation d’un groupe dans les données d’entrainement, ou de données historiques biaisées par du racisme/sexisme présent dans la société [1]. Dans le cadre de cet article, nous nous concentrerons sur le cas où le problème vient des données et non pas du modèle en lui-même, à savoir lorsque le modèle apprend sur des données biaisées et reproduit ensuite ce biais dans ses prédictions.
L’un des exemples les plus connus est le cas COMPAS. L’algorithme COMPAS était utilisé aux États-Unis pour estimer le risque de récidive de détenus dans le cadre d’une potentielle libération anticipée. En 2016, une étude de ProPublica affirmait que les Afro-Américains étaient discriminés par l’algorithme car ils avaient plus de chance d’être classifiés comme « high-risk ». Plus précisément, l’étude mentionnait qu’une personne noire avait plus de chance d’être erronément classifiée comme « high-risk » et, qu’à l’inverse, une personne blanche avait plus de chance d’être erronément classifiée comme « low-risk ». Cette affaire entraina un grand débat et la publication de centaines d’articles sur le sujet.
Dans le cas de COMPAS, le problème n’était pas l’algorithme en lui-même, mais les données sur lesquelles il a été entrainé. Le modèle a en effet été entrainé sur des données historiques de la justice pénale qui reflètent un biais raciste systémique, telles que des pratiques policières discriminatoires. Ces données biaisées ont donc entrainé un modèle produisant des prédictions elles aussi biaisées.
Comment mesurer l’iniquité d’un modèle ?
Les problèmes de fairness supposent l’existence d’une variable appelée variable sensible. Il s’agit de la variable vis-à-vis de laquelle on souhaite qu’il n’y ait pas de discrimination. Il peut par exemple s’agir du genre de la personne, ou de son origine ethnique. La variable sensible est souvent catégorielle, mais suivant le cas de figure, elle peut aussi être continue (e.g. l’âge d’une personne). Pour des raisons de simplicité, nous faisons l’hypothèse qu’il n’y a qu’une seule variable sensible, mais dans certains problèmes il peut y en avoir plusieurs.
Sur base de cette variable sensible, on définit généralement deux groupes. Le groupe qui est discriminé négativement par le modèle est appelé « groupe protégé ».
Supposons un modèle prédictif ayant pour objectif de fournir des prédictions concernant l’accord d’un prêt. Cet algorithme sera considéré comme « équitable » si la probabilité pour un individu d’être sélectionné pour le prêt (décision positive du modèle) est la même peu importe le groupe dont est issu l’individu. Mathématiquement, on cherche donc à imposer :
P(Yd = 1 | Z = 1) = P(Yd = 1 | Z = 0)
Où Yd est la décision du modèle et Z est une variable binaire indiquant l’appartenance ou non au groupe protégé. Ces probabilités sont calculées à l’échelle du groupe, et non pas de façon individuelle.
Une mesure bien connue de l’iniquité algorithmique consiste donc simplement à calculer la différence entre ces deux termes. S’il y a une différence, cela implique que le modèle favorise l’un des deux groupes. Cette mesure de la différence entre les prédictions au sein des deux groupes est appelée la « demographic parity » ou « statistical parity ».
Bien que relativement simple, il s’agit de l’une des mesures les plus connues dans le domaine de l’équité algorithmique, largement reconnue et utilisée. Cependant, ce n’est évidemment pas la seule mesure qui existe (pour quelques alternatives, voir e.g., [2, 3]). Il est à noter que, puisqu’elle se mesure à l’échelle des groupes, la demographic parity est donc une mesure d’équité de groupe (group fairness), il existe aussi des mesures alternatives au niveau des individus (individual fairness).
Pourquoi ne pas simplement enlever la variable sensible du modèle ?
Le problème semble, à première vue, simple à régler. Un modèle prédictif de machine learning prend en entrée des données X et prédit une variable Y en sortie sur base des données contenues dans X. Il suffirait donc, a priori, simplement d’enlever la variable Z de la base de données X pour que les prédictions du modèle ne soient plus impactées par Z.
Malheureusement, dans la pratique, les variables qui composent X sont rarement indépendantes les unes des autres. La base de données X peut donc contenir des variables corrélées avec la variable sensible, et le modèle pourra se servir de ces variables comme d’un proxy de la variable sensible et fournir des prédictions biaisées, bien que Z ne fasse pas explicitement partie des données utilisées en entrée. Par exemple, dans un échantillon, le revenu d’une personne peut être utilisée comme proxy de son âge, car les revenus des individus ont tendance à augmenter avec l’âge.
Dans le cas COMPAS par exemple, l’origine ethnique du détenu n’était pas explicitement utilisée en tant que variable du modèle, mais à cause de la présence de variables proxy corrélées (e.g., le code postal, des indicateurs socio-économiques), le biais racial se reflétait toujours dans les prédictions du modèle.
Comment corriger un biais algorithmique en pratique ?
Il existe 3 grandes familles de corrections : le prétraitement (« pre-processing » : enlever le biais des données d’entrainement), le traitement en cours (« in-processing » : enlever le biais durant l’entrainement du modèle) et le post-traitement (« post-processing » : enlever le biais d’un modèle entrainé). Chacune de ces approches a ses avantages et ses inconvénients et a fait l’objet de nombreuses publications. Le lecteur intéressé pourra se référer au survey suivant [4], qui rassemble et organise les différentes publications dans le domaine de la fairness par approche (pre-, in-, post-processing), type d’algorithme utilisé (régression logistique, random forest, réseaux de neurones, etc.), mesure de fairness utilisée, etc., offrant une vue d’ensemble bien structurée de ce qui se fait dans le domaine.
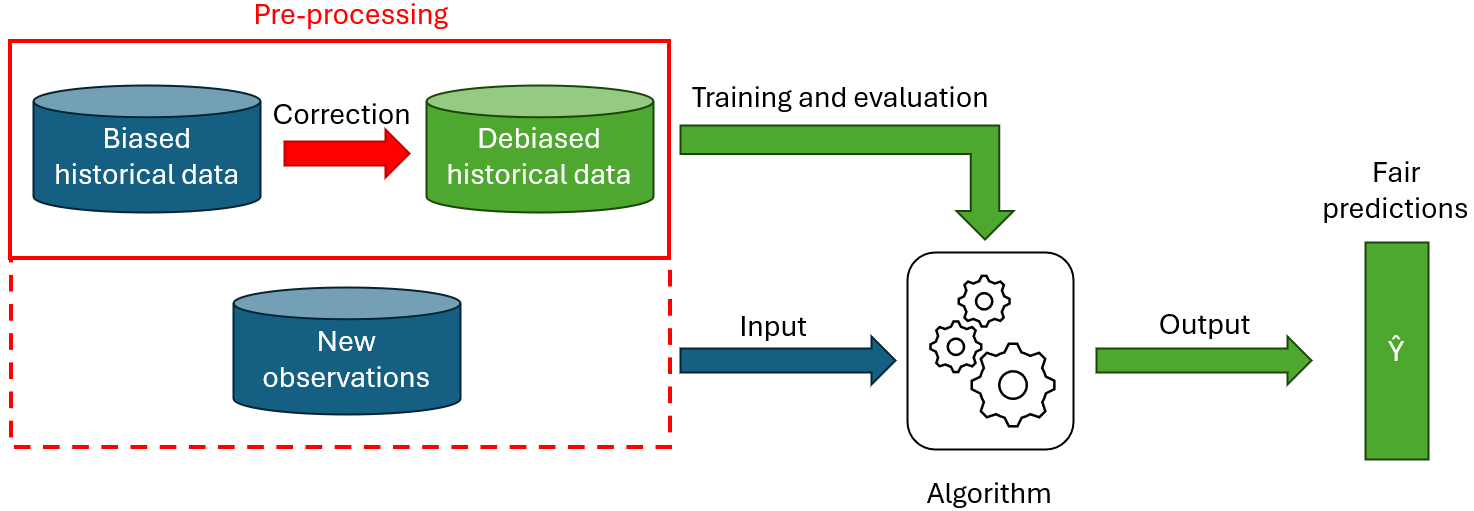
Les méthodes « pre-processing »
L’idée est simple : il s’agit simplement de débiaiser les données d’entrainement pour les rendre plus proches de la réalité, de sorte que le biais ne parvienne pas jusqu’au modèle de machine learning. Quelques exemples de méthodes de pre-processing incluent par exemple :
- Rééquilibrer l’échantillonnage (en ajoutant ou supprimant des observations) ;
- Corriger le contenu de certaines variables des données X, voire complètement remplacer les variables par des nouvelles (representation learning) qui ne contiennent pas d’information sensible ;
- Changer le label (variable Y) de certaines observations.
Le pre-processing offre l’avantage de ne pas dépendre du modèle utilisé et d’être (généralement) facile à expliquer et à comprendre. Cependant, corriger adéquatement les données historiques peut être compliqué à réaliser, et il est difficile de garantir l’équité du modèle résultant. Il faut aussi mentionner le risque de perte de précision, car altérer les données peut potentiellement enlever des patterns pertinents des données.
La figure 2 montre l’ajout d’équité via une approche pre-processing. Comme visible sur le schéma, le pre-processing ne s’applique pas toujours nécessairement aux nouvelles données. Certaines méthodes (e.g. rééchantillonnage, relabeliser) ne demandent que de modifier les données d’entrainement, pour éviter que l’algorithme n’apprenne le biais. Par contre, certains algorithmes (e.g. representation learning) nécessitent aussi de modifier les nouvelles observations à prédire.
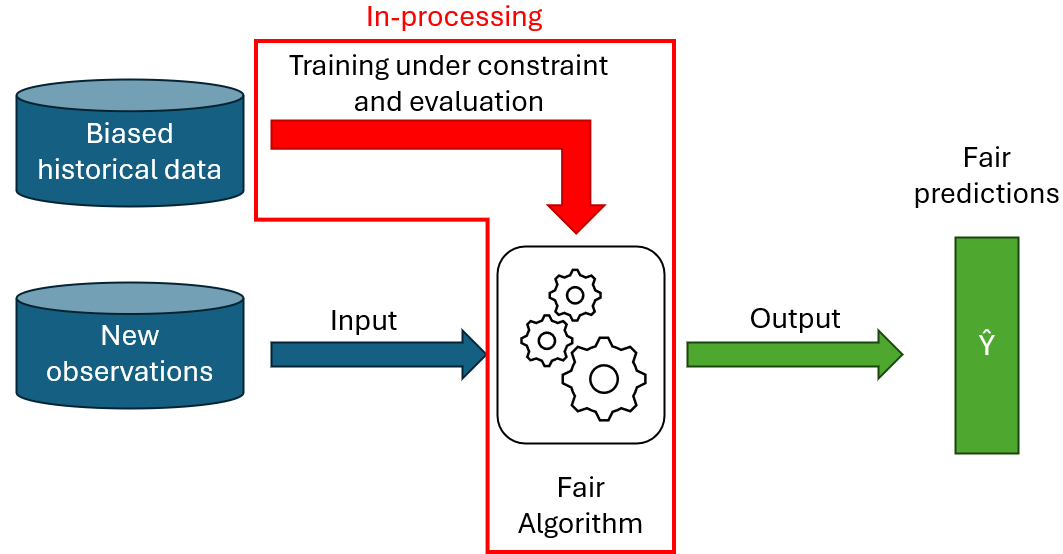
Les méthodes « in-processing »
Ces méthodes consistent à modifier directement le modèle prédictif en lui-même, de sorte que ses prédictions soient équitables. Cela peut par exemple se faire en ajoutant un terme de régularisation sur la fonction objectif de l’algorithme, ou en lui ajoutant des contraintes de fairness.
Les méthodes in-processing ont l’avantage qu’une fois le modèle entrainé, la fairness est directement inclue dans le modèle et celui-ci peut être utilisé librement, sans nécessiter de modification supplémentaire des données entrées ou des prédictions du modèle. De plus, modifier directement le modèle offre une grande flexibilité, car on peut y encoder des contraintes de fairness complexes.
Cette grande flexibilité requiert, en contrepartie, des connaissances théoriques et pratiques suffisamment approfondies pour pouvoir modifier l’algorithme en lui-même. En outre, introduire des modifications dans un modèle, telles que des contraintes, peut significativement augmenter son temps d’entrainement. Enfin, puisque les méthodes d’in-processing modifient l’entrainement d’un algorithme, la plupart des méthodes publiées sont généralement spécifiques à un modèle précis.
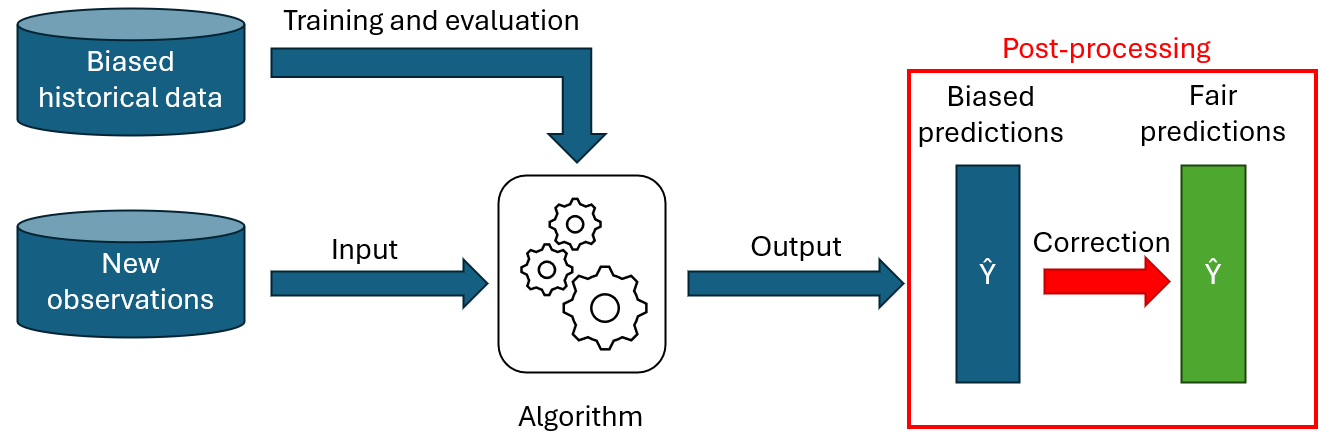
Les méthodes « post-processing »
Pour la dernière approche, on ne touche pas au modèle ou aux données historiques, on va simplement appliquer un ajustement aux prédictions fournies par le modèle de sorte à satisfaire les contraintes de fairness. Un algorithme de post-processing va donc généralement soit modifier les probabilités d’appartenance aux classes prédites par le modèle, soit directement modifier les décisions (classifications finales) pour certaines observations.
Les algorithmes de post-processing sont des solutions simples à mettre en place : ils sont indépendants du modèle prédictif utilisé, et peuvent donc s’utiliser avec des modèles « black-box ». De plus, le post-processing ne demande aucune modification ni des données, ni du modèle, et préserve donc l’intégrité du processus existant.
Ce genre de méthodes tend cependant généralement à dégrader plus fortement les performances du modèle que l’utilisation de méthodes d’in-processing. En effet, entrainer un modèle librement et ensuite altérer ses prédictions a posteriori pour que ces dernières remplissent des contraintes sera souvent moins efficace que d’avoir un modèle ayant été spécifiquement optimisé pour fournir des prédictions remplissant les contraintes.
Evaluer les prédictions équitables
Par définition, à partir du moment où on ajoute des contraintes sur les prédictions d’un modèle, ou si on limite l’accès à certaines informations, cela va logiquement réduire les performances de classification du modèle. Par conséquent, incorporer de l’équité dans un problème de classification implique de trouver la juste balance entre la précision du modèle et sa fairness.
De plus, même une fois qu’un équilibre entre précision et équité a été trouvé, il convient toujours de vérifier les modifications qui résultent de l’ajout des contraintes de fairness.
Prenons un exemple illustratif : supposons un algorithme fournissant des prédictions biaisées, qui a tendance à donner relativement plus de décisions favorables aux membres du groupe A comparé au groupe B. Il y a un risque qu’à l’introduction d’une contrainte de fairness, l’algorithme réponde en réduisant simplement le nombre de décisions favorables pour le groupe A pour atteindre le même niveau que le groupe B. Ce nouveau modèle est donc théoriquement plus équitable que le précédent, mais il est manifestement pire puisque cette équité a été réalisée uniquement en pénalisant l’un des groupes.
Cet exemple illustre l’importance, lors de l’introduction d’équité dans un modèle, de ne pas regarder uniquement les mesures de performance (accuracy, demographic parity, etc.), mais aussi d’investiguer la façon dont les décisions du modèle sont impactées en pratique.
Conclusion
Dans cet article, nous avons vu comment mesurer l’iniquité d’un modèle de machine learning, et présenté un aperçu des différentes approches utilisées pour éviter que le modèle ne reproduise ou ne renforce un biais appris dans les données historiques.
Il est important de signaler que les différentes approches ne sont pas mutuellement exclusives, et peuvent souvent être combinées (e.g. un pre-processing des données d’entrainement, suivi d’une méthode in-processing sur le modèle). Certaines publications dans le domaine proposent d’ailleurs des méthodes qui agissent à plusieurs niveaux du processus de classification.
Références
[1] Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. (2021). A survey on bias and fairness in machine learning. ACM computing surveys (CSUR), 54(6), 1-35.
[2] Castelnovo, A., Crupi, R., Greco, G., Regoli, D., Penco, I. G., & Cosentini, A. C. (2022). A clarification of the nuances in the fairness metrics landscape. Scientific Reports, 12(1), 4209.
[3] Corbett-Davies, S., Gaebler, J. D., Nilforoshan, H., Shroff, R., & Goel, S. (2023). The measure and mismeasure of fairness. Journal of Machine Learning Research, 24(312), 1-117.
[4] Hort, M., Chen, Z., Zhang, J. M., Harman, M., & Sarro, F. (2024). Bias mitigation for machine learning classifiers: A comprehensive survey. ACM Journal on Responsible Computing, 1(2), 1-52.
Sur un sujet similaire, voir le post IA: L’éthique en pratique.
Ce post est une contribution individuelle de Pierre Leleux, data scientist et network data analyst chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.
Leave a Reply