Cet article est aussi disponible en français.
Heel wat organisaties zijn druk aan het experimenteren met generatieve AI. Vaak maken ze daarbij gebruik van toepassingen die draaien op LLM’s (Large Language Models), ondersteund door een RAG-architectuur (Retrieval-Augmented Generation). Dit betekent dat het systeem eerst relevante informatie uit een kennisbron ophaalt en die als context meegeeft aan het taalmodel. Zo ontstaat een output die stevig verankerd is in de juiste domeinkennis. In het jargon spreken we van grounding. Deze aanpak is vooral populair in vraag-en-antwoordtoepassingen en chatbots.
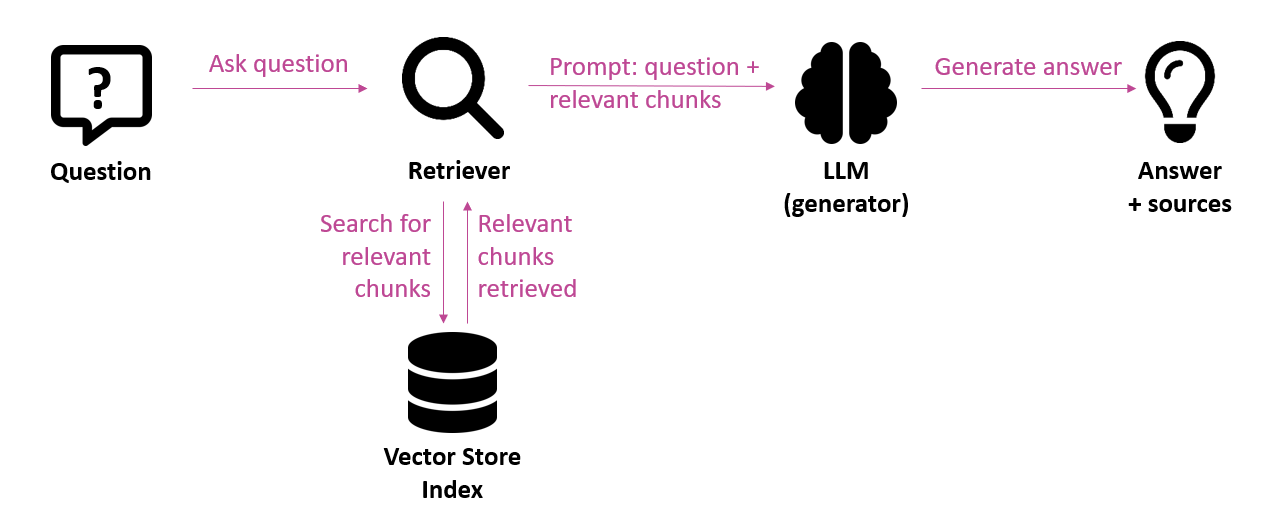
Hoewel het potentieel van dergelijke LLM-gebaseerde toepassingen groot is, blijkt de kwaliteit van de gegenereerde output in de praktijk niet altijd even betrouwbaar. Het kan al mislopen op niveau van de retrieval-stap, als de relevante informatie niet teruggevonden wordt of slechts gedeeltelijk. Maar zelfs als de juiste context wél wordt aangeleverd, kan een taalmodel alsnog fouten maken. Het model kan de informatie verkeerd interpreteren, onnauwkeurige verbanden leggen of hallucinaties genereren — antwoorden die overtuigend klinken, maar feitelijk onjuist zijn. Deze onzekerheid over de kwaliteit is één van de belangrijkste belemmeringen voor het in productie nemen van zulke toepassingen, zeker in domeinen waar betrouwbaarheid essentieel is.
In dit artikel gaan we dieper in op de methodes voor het evalueren van de kwaliteit van RAG-gebaseerde toepassingen.
Manuele & automatische evaluaties
Het evalueren van generatieve AI-toepassingen is allesbehalve eenvoudig. Dat komt vooral doordat de output vaak ongestructureerd is en niet-deterministisch: eenzelfde input kan telkens een andere output opleveren. Daarbovenop bestaat er zelden één juist antwoord, wat het moeilijk maakt om objectief te beoordelen of een gegenereerde output “goed” is. Veel hangt af van subjectieve criteria zoals relevantie of nauwkeurigheid, die per evaluator kunnen verschillen.
De meest voor de hand liggende manier om de kwaliteit te controleren is manueel: handmatig een aantal testen uitvoeren, het resultaat inschalen en eventueel commentaar toevoegen met een indicatie van de oorzaak van minder goede kwaliteit. Iemand met de nodige domeinkennis kan zo’n evaluatie goed uitvoeren, maar het is tijdrovend en schaalt niet goed.
Om die redenen kan het interessant zijn om te kijken naar systemen voor automatische evaluaties, zogeheten “auto-evals”. Aangezien ze automatisch uitgevoerd worden, zijn ze goed te schalen. Technieken zoals exact-string matching en regular expressions kunnen gebruikt worden voor het exact matchen van tekst of het matchen van een patroon. Maar als de output van een LLM kan variëren in woordkeuze, volgorde of lengte, bijvoorbeeld in het geval van meerdere juiste formuleringen, lopen zo’n methodes vast. In die gevallen heb je semantische of model-gebaseerde evaluatie nodig. Een techniek die momenteel in de belangstelling staat is “LLM-as-judge”, waarbij een (tweede) taalmodel de gegenereerde output beoordeelt op bepaalde criteria.
LLM-as-judge: LLM beoordeelt LLM
Op het eerste zicht is het wat vreemd dat een taalmodel wordt ingeschakeld om de output van een taalmodel te beoordelen. Maar het blijkt eenvoudiger om kritiek te geven op een output dan om de originele output te genereren: zelfs voor LLM’s is het eenvoudiger om fouten achteraf te detecteren dan ze te voorkomen.
Er zijn een aantal aspecten die door een LLM-rechter kunnen beoordeeld worden, zoals feitelijke correctheid, volledigheid, hallucinaties en relevantie van de output ten opzichte van de vraag. Die beoordeling kan gebeuren ten opzichte van een referentie (referentie-gebaseerd) of niet (referentievrij). Zo kan in de ontwikkelfase een vaste testset voorzien worden van vragen, aangevuld met referentie-antwoorden: een domeinexpert kan correcte antwoorden aanleveren die gelden als een gouden standaard. Het is echter onmogelijk om in een productie-omgeving voor elke mogelijke vraag een referentie-antwoord te voorzien, waardoor je in de praktijk moet terugvallen op referentievrije evaluaties.
We gingen concreet aan de slag met enkele LLM-as-judge metrieken uit de OpenEvals toolbox van LangChain, toegepast op een LLM-gebaseerd vraag- en antwoordsysteem. Dit is de gevolgde aanpak:
- Opstellen testset – In een eerste stap wordt een testset opgesteld met vragen die representatief zijn voor de betrokken knowledge base. Voor elk van de vragen wordt een referentie-antwoord voorzien.
- Antwoordgeneratie – Vervolgens laten we voor elk van de vragen uit de testset een antwoord genereren door het vraag-antwoordsysteem.
- Manuele beoordeling – Om te kunnen nagaan hoe goed een automatische LLM-as-judge evaluator presteert, doen we eerst een manuele beoordeling: elk gegeneerd antwoord krijgt een score van 0 (fout antwoord), 1 (deels correct / onvolledig) of 2 (correct en volledig).
- Uitvoeren evaluaties – In deze stap voorzien we een script dat alle testcases beoordeelt op vlak van een bepaalde metriek. Als metriek gebruiken we de correctness evaluator die de OpenEvals library standaard aanbiedt. Deze meet hoe correct een gegenereerd antwoord is ten opzichte van het referentie-antwoord. Als output krijgen we voor elk gegenereerd antwoord een binaire score (true = correct; false = niet correct) en een tekstuele motivatie van de score, bijvoorbeeld:
Vraag: A partir de quel âge puis-je travailler comme étudiant?
Gegenereerd antwoord: Tu peux t’engager comme jobiste dès que tu as 15 ans et que tu as suivi le premier degré de l’enseignement secondaire, ou dès que tu as 16 ans.
Referentie-antwoord: Vous pouvez travailler comme étudiant dès que vous avez 16 ans ou si vous avez 15 ans et avez suivi les deux premières années de l’enseignement secondaire.
Score: true
Motivatie: The provided answer states that a student can work at 15 years old if they have completed the first cycle (“premier degré”) of secondary education, equivalent to the two first years of secondary education mentioned in the reference. It also notes that one can work at 16 years old. This information is factually accurate, complete, and addresses the question using precise terminology. Thus, the score should be: true.
Alignering van automatische en manuele beoordeling
Als we de resultaten van deze correctness evaluator vergelijken met de manuele scores, dan zien we in onze test dat de LLM-as-judge score in 70% van de gevallen gelijk is aan de manuele score. Er zijn dus heel wat gevallen waar beide scores niet overeenkomen. Daar zijn diverse redenen voor:
- Subjectieve beoordelingen – Manuele beoordelingen zijn subjectief, zo worden onvolledige antwoorden al dan niet streng beoordeeld naargelang de persoon die de evaluatie uitvoert.
- Kwaliteit referentie-antwoorden – De kwaliteit van de referentie-antwoorden die opgesteld worden door een domein-expert spelen een belangrijke rol omdat dit de maatstaf is. Ze moeten compleet zijn en duidelijk geformuleerd.
- Beoordelingsmethode: Bij de manuele beoordeling wordt gebruik gemaakt van een driedelige score (2 = correct, 1 = onvolledig, 0 = fout). De geteste correctness evaluator maakt standaard gebruikt van een tweedelige score (true of false). Deze mist de nodige nuance om een correct maar onvolledig antwoord toch enigszins positief te scoren.
- Taalmodel – Tenslotte speelt ook het taalmodel dat door de LLM-as-judge gebruikt wordt een rol. Een reasoning model zal beter in staat zijn om een goede beoordeling te doen dan een minder performant chat model.
In het ideale geval oordeelt een automatische evaluator op dezelfde manier als een menselijke evaluator, maar in de praktijk blijkt het dus moeilijk om de scores van automatische evaluaties goed te aligneren met de manuele scores.
Om deze alignering te verbeteren kan de LLM-as-judge iteratief verbeterd worden door bijvoorbeeld de prompt aan te passen (instructies, beoordelingsmethode). In feite is het inschakelen van een LLM als evaluator op zich ook een LLM-project waarvan de kwaliteit moet geëvalueerd worden en iteratief verbeterd kan worden. De kunst zal erin bestaan om eenvoudig te starten en de kwaliteit van de evaluator geleidelijk aan te verbeteren. Sowieso kan de tekstuele motivatie van de correctness evaluator nuttige input leveren voor het beoordelen van gegenereerde antwoorden.
Welke metrieken gebruiken?
In de ontwikkelfase beschikken we vaak over referentie-antwoorden; daardoor kunnen we een correctness evaluator inzetten die simpelweg meet in hoeverre het gegenereerde antwoord overeenkomt met het referentie-antwoord. Aanvullende metrieken kunnen zicht bieden op andere RAG-aspecten, zoals context precision, die meet welk deel van de aangeleverde chunks relevant zijn, en context recall, die meet hoeveel van de relevante chunks werden aangeleverd. In de figuur hieronder zijn deze referentie-gebaseerde metrieken aangeduid in geel.
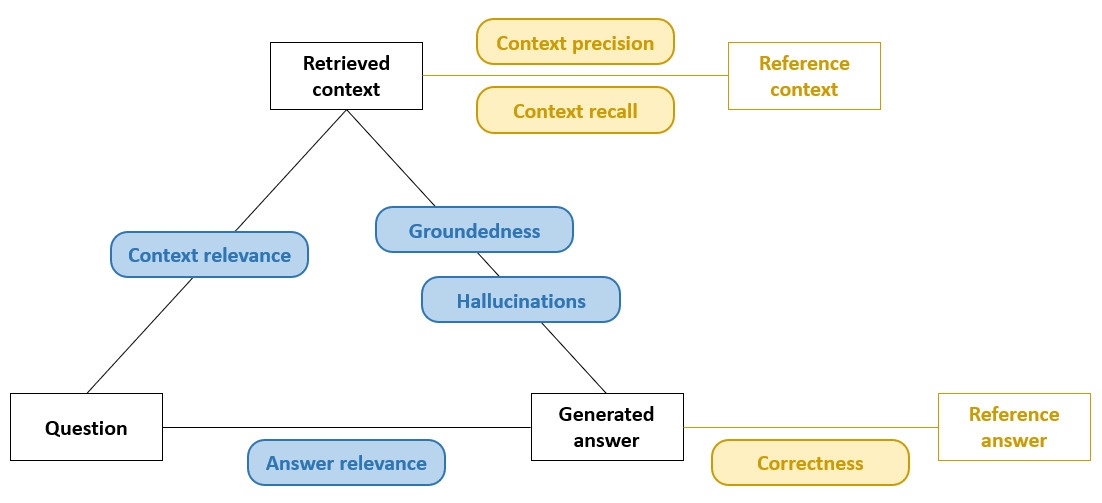
Wanneer zulke metrieken nodig zijn maar er geen expliciete referentie beschikbaar is, kan men teruggrijpen naar benaderende varianten (zie metrieken aangeduid in blauw in de figuur hierboven): bijvoorbeeld een LLM-as-judge die het gegenereerde antwoord vergelijkt met de opgehaalde context en een semantische “close-enough” score teruggeeft. In een productie-omgeving ontbreken referentie-antwoorden vrijwel altijd; daar verschuift de focus naar metrieken als hallucination detection of groundedness, die beoordelen of elke bewering in de output daadwerkelijk ondersteund wordt door de aangeleverde context. Zo blijft de kwaliteit toch meetbaar, ook zonder gouden standaard. Andere benaderende metrieken zijn context relevance, die meet hoe sterk de opgehaalde passages semantisch aansluiten bij de vraag en dus bruikbaar zijn als basis voor generatie, en answer relevance (helpfulness), die beoordeelt in welke mate het uiteindelijke antwoord daadwerkelijk de vraag beantwoordt.
Conclusie
Generatieve AI zit vandaag in een hypefase, maar voor organisaties is betrouwbare kwaliteit van de output één van de belangrijkste criteria om dergelijke technologie met vertrouwen te kunnen inzetten. Bij een RAG-pipeline is de gegenereerde output gebaseerd op domeinkennis, maar zonder een robuust evaluatiekader is er onvoldoende zicht op de kwaliteit. Daarom is het belangrijk om in te zetten op meetbaarheid.
Begin in de ontwikkelfase met een compacte, representatieve testset en duidelijke gouden standaard‑antwoorden. Daarop kunnen referentie‑gebaseerde metrieken toegepast worden zoals correctness om snel pijnpunten bloot te leggen. Eens je naar productie opschuift, kan je overschakelen op referentievrije metrieken zoals groundedness en hallucination detection, zodat je ook onbekende vragen kunt monitoren.
Automatische evaluaties op basis van LLM‑as‑judge zijn geen wondermiddel. Hun grootste uitdaging is alignering: ervoor zorgen dat de automatische scores zo dicht mogelijk aansluiten bij het oordeel van domeinexperts. Toch leveren ze schaal en continuïteit: ze kunnen grote volumes outputs screenen, kunnen potentiële kwaliteitsproblemen aanduiden en bieden objectieve meetpunten om een LLM- of RAG-toepassing gericht bij te sturen. Door hun oordeel systematisch te vergelijken met manuele beoordelingen en de prompts van de evaluator bij te sturen, worden zowel de toepassing als de evaluator steeds beter via een iteratief proces.
Dit is een ingezonden bijdrage van Bert Vanhalst, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.