Taalmodellen
De laatste maanden heeft iedereen kunnen kennismaken met de kracht van generatieve AI, met ChatGPT als grote blikvanger. Aan de basis liggen grote taalmodellen (large language models – LLM’s): grootschalige neurale netwerken met heel veel parameters die getraind zijn op grote hoeveelheden tekst. Een aantal toepassingen van dergelijke LLM’s zijn:
- Genereren van tekst: denk bijvoorbeeld aan een draft voor een email;
- Samenvatten van tekst;
- Vertalingen uitvoeren;
- Classificeren van tekst: hieronder valt sentiment analyse, zoals het classificeren van klantenreviews als positief of negatief;
- Vragen beantwoorden;
- Entiteiten herkennen, zoals persoonsnamen;
- Assisteren bij het schrijven van code: zie de blogpost over De AI-Augmented Developer.
Een populaire toepassing is het beantwoorden van vragen. Naar aanleiding van de lancering van ChatGPT duiken er massaal tools op die toelaten om vragen te beantwoorden over je eigen content. Het wordt heel eenvoudig voorgesteld: upload je documenten (PDF, Word, etc.) en je kan quasi onmiddellijk vragen beginnen stellen, typisch in een chatbot-achtige omgeving.
In dit artikel geven we aan hoe zo’n question answering systeem in elkaar steekt en vertellen we wat meer over de kwaliteit die we kunnen verwachten van de output.
Question answering op basis van taalmodellen
Onderstaand schema geeft in grote lijnen weer welke componenten onderdeel uitmaken van een question answering systeem op basis van taalmodellen. Het bovenste gedeelte (blauw) zijn alle stappen die nodig zijn om de content klaar te zetten:
- Als startpunt hebben we een knowledge base met één of meerdere documenten. Het kan gaan om verschillende formaten, zoals PDF, Word of webpagina’s. In deze eerste stap wordt de tekst uit de documenten gehaald;
- Vervolgens wordt de tekst opgesplitst in kleinere stukken (chunks);
- Die stukken tekst worden dan omgezet naar embeddings, dat is een numerieke voorstelling van tekst die het gemakkelijker maakt om semantisch vergelijkbare stukken tekst terug te vinden;
- Uiteindelijk worden de embeddings bijgehouden in een databank (vector store).
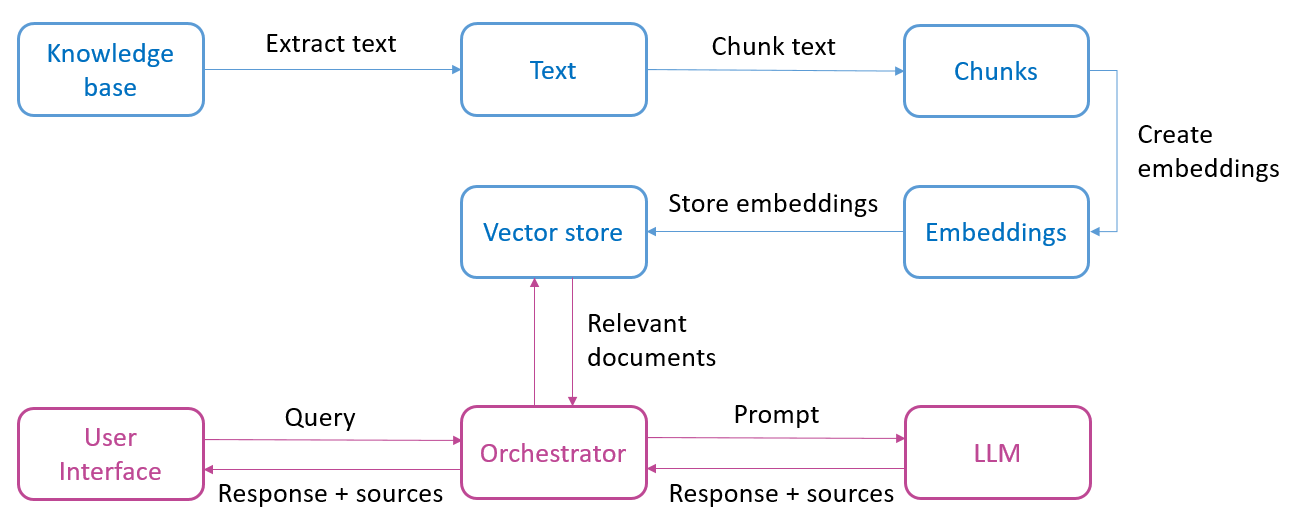
Na deze voorbereidingsfase kunnen we als eindgebruiker een vraag stellen aan het systeem (zie onderste gedeelte in het schema). Dit gaat als volgt: de vraag van de gebruiker (query) wordt omgezet naar embeddings, wat toelaat om in de vector store de documenten op te zoeken (retrieval) die het meest semantisch verwant zijn met deze vraag. Vervolgens wordt een prompt naar het taalmodel gestuurd, dit is alle informatie die nodig is om een antwoord te bekomen van het taalmodel: de originele vraag van de gebruiker, de relevante gevonden documenten en de specifieke opdracht (instructie) voor het taalmodel. We krijgen tenslotte een gegenereerd antwoord terug, indien gewenst samen met vermelding van de bronnen (paginanummers of website URL’s).
We kunnen ons afvragen waarom we niet meteen alle documenten uit de knowledge base als context meegeven aan het taalmodel. Daar zijn hoofdzakelijk twee redenen voor. Eerst en vooral is er een beperking op de grootte van de context die we kunnen meegeven. Het populaire GPT-3.5-turbo model heeft bijvoorbeeld een limiet van 4000 tokens. Met tokens wordt de kleinste betekenisvolle eenheid bedoeld waarin tekst kan worden opgesplitst. Een token kan een volledig woord zijn, maar het kan ook een deel van een woord zijn of een leesteken, afhankelijk van de gebruikte methode voor tokenization.
Een tweede reden is de kost voor het aanroepen van een taalmodel. Die is namelijk afhankelijk van het aantal tokens in de input en de output. Hoe meer context we meegeven met de input, hoe hoger dus de kost.
Frameworks
Toepassingen op basis van de bovenstaande architectuur kunnen snel ontwikkeld worden dankzij frameworks zoals Langchain. Ze bieden typisch abstracties aan om in enkele lijnen code de taken uit te voeren uit het schema hierboven (tekst extraheren, tekst opsplitsen, embeddings aanmaken en opslaan). En ze fungeren als een soort orchestrator om de gebruikersinput te verbinden met de vector store en het taalmodel.
Als experiment gingen we aan de slag met Langchain om een question answering toepassing te bouwen op basis van een PDF of webpagina’s. Met de nodige kennis van het framework is dit heel snel opgezet.
Kwaliteit van de output
De hamvraag is natuurlijk hoe accuraat de antwoorden zijn die we terugkrijgen. Uit onze experimenten blijkt dat de antwoorden soms indrukwekkend goed zijn: accuraat, mooi samengevat en soms met correcte redenering zoals het interpreteren of een bedrag uit de vraag boven of onder een bepaald grensbedrag ligt.
Maar we moeten helaas ook constateren dat de antwoorden dikwijls onnauwkeurig zijn of onvolledig, tot zelfs ronduit fout. Intuïtief kan men denken dat dit intrinsiek is aan het generatieve karakter van taalmodellen en het fenomeen van hallucinaties. Een minstens even belangrijke factor is echter de retrieval stap: het opzoeken van de meest relevante stukken tekst waarin het taalmodel de informatie moet vinden om een antwoord op te stellen. Indien de informatie die nuttig is voor een antwoord niet in die aangeleverde stukken tekst staat, kunnen we niet verwachten dat het taalmodel een accuraat antwoord teruggeeft.
Los van waar het fout gaat, zijn er een aantal technieken om de kwaliteit van de output te verhogen, waaronder:
- Semantische retrieval combineren met een klassieke lexicale retrieval;
- Bijkomende relevante bronnen opnemen in de knowledge base;
- Prompt engineering: de instructie aanpassen die gegeven wordt aan het taalmodel;
- Het aanpassen van de grootte van de chunks en de grootte van de overlap tussen de chunks. We merken hierbij op dat de limiet op de context van de taalmodellen groter wordt. Zo biedt OpenAI een model met een context van 16.000 tokens. Daardoor kan meer context meegegeven worden. Het verhogen van de grootte van de chunks kan ervoor zorgen dat semantisch verwante informatie meer samenblijft in één chunk.
- Tenslotte kan er ook gedacht worden aan het finetunen van een taalmodel, maar dat is veel omslachtiger.
Conclusie
Het zou mooi zijn om met een heel beperkte inspanning een systeem te kunnen opzetten dat in staat is om vragen te beantwoorden over onze eigen data. De accuraatheid van het antwoord is echter nog een groot aandachtspunt. Er is een goede reden waarom er bij dergelijke toepassingen steevast een disclaimer te zien is die stelt dat de antwoorden onnauwkeurig of foutief kunnen zijn en dat het steeds aangeraden is om het resultaat te controleren.
Dit is een ingezonden bijdrage van Bert Vanhalst, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.