Les graphes, et plus particulièrement les graphes de connaissances, permettent de représenter l’information de manière structurée. Cela permet, pour un humain, d’avoir une représentation (synthèse visuelle) du contenu d’un ou de plusieurs documents et, pour une machine, d’exploiter cette structure afin, par exemple, d’en analyser le contenu (via l’utilisation d’algorithmes de graphe) et/ou de raisonner sur le graphe (par exemple dans le cadre d’une application de graphRAG ou pour découvrir (inférer) de l’information implicite).
Cet article s’intéresse aux façons dont une représentation graphe peut être obtenue à partir de données textuelles, les différents types de graphe qui peuvent être extraits, et les outils fréquemment utilisés suivant le type d’extraction que l’on souhaite effectuer.
Il est à noter que, puisque les grands modèles de langage (LLM) sont particulièrement adaptés pour le traitement de texte, cet article se concentrera principalement sur la présentation d’approches basées sur les LLM et discutera rapidement, dans un second temps, de différentes approches alternatives.
Les graphes de connaissances : un rappel rapide
Un graphe est une structure composée d’un ensemble de nœuds et d’arcs (qui lient des paires de nœuds). Un graphe de connaissances ajoute une couche sémantique supplémentaire à un graphe classique, où chaque nœud représente un concept (entité, personne, etc.) et chaque arc représente une relation entre deux concepts (« travaille pour », « est ami avec », etc.). Il s’agit donc d’une représentation de la connaissance sous forme d’un ensemble d’entités interconnectées. Plus de détails sur les différentes formes de graphes et les outils associés peuvent être trouvés ici.
Préparation du corpus de documents
Il est à noter que, pour des raisons de simplicité, nous faisons l’hypothèse que les documents de texte utilisés pour construire le graphe ont été correctement nettoyés. En effet, cet article n’a pas pour but de discuter de l’aspect relatif au prétraitement des documents de texte (scrapping de pages web, extraction de texte à partir de fichiers pdf, etc.), car ce prétraitement est déjà, en tant que tel, un vaste sujet méritant sans doute un article dédié.
Fragmentation du texte en « chunks »
Une étape importante de la préparation des données de texte avant d’en extraire les entités et relations est la division du texte en fragments (généralement appelés « chunks »). Nous avons déjà mentionné le concept de chunking à plusieurs reprises dans de précédents articles. Si un document est trop long (plus de quelques paragraphes…) il convient de le séparer en chunks (fragments de texte de taille raisonnable) qui seront traités un à un par le LLM. Cette procédure permet de limiter la quantité d’information présente dans chaque chunk, pour éviter que celui-ci ne contienne une quantité trop importante d’entités et de relations à extraire. Cette séparation en chunks peut se faire de différentes manières, soit sur la base du nombre de mots dans le chunk, soit sur la base d’un séparateur prédéfini (par exemple : un passage à la ligne qui indiquerait la fin du paragraphe).
Représenter l’information ou représenter la structure
Commençons par regarder les deux principaux types de graphe qui peuvent être construits à partir d’un ensemble de documents textuels.
Le premier est un graphe qui va présenter la structure du document (document structure graph), et non pas l’information qui est contenue dans le texte. Par exemple, en reliant les chunks au document d’où ils sont tirés ainsi que l’ordre d’apparition de ceux-ci dans le document :
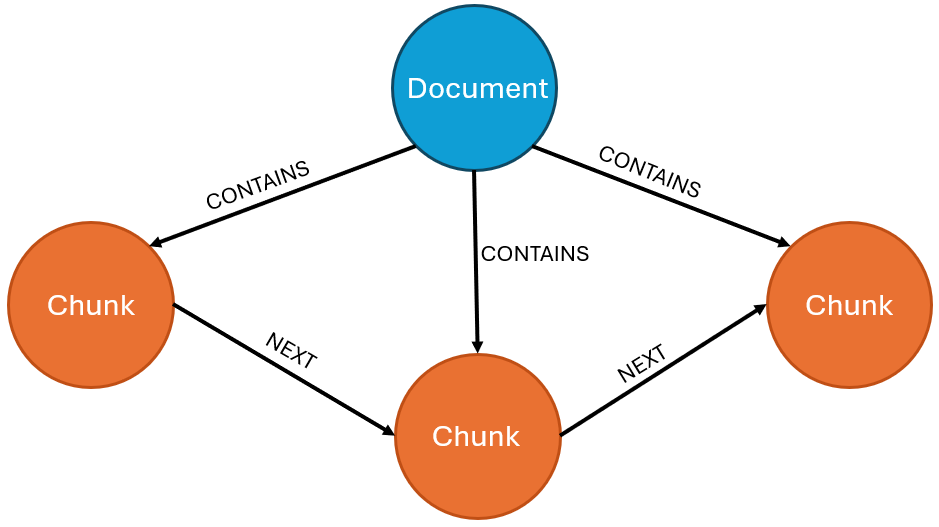
Ce type de graphe peut aussi être enrichi en ajoutant des relations entre chunks sémantiquement similaires ou, le cas échéant, en représentant l’organisation hiérarchique du document en sections, sous-sections, etc. Cela se fait via des nœuds représentant les sections/sous-sections et des relations de type « HAS_SECTION », « HAS_SUBSECTION », ainsi que des relations indiquant l’ordre des sections/sous-sections. Une fois le graphe construit, il peut par exemple être utilisé dans des applications de RAG à des fins d’indexation pour fournir du contexte aux chunks utilisés (voir notre article sur le graphRAG).
Le second type de graphe consiste à capturer l’information contenue dans les documents sous la forme de nœuds et de relations :

Dans le cadre de cet article, nous nous concentrerons sur ce second type de graphe. Il est à noter que les deux approches ne sont pas mutuellement exclusives. D’ailleurs, il est souvent utile, si l’on souhaite opter pour le deuxième type de graphe, de représenter également la structure des documents. Cela permet, si nécessaire, de pouvoir remonter à la source des informations présentes dans le graphe.

Construction d’un graphe de connaissances à l’aide d’un LLM
Dans un premier temps, nous allons présenter la procédure générale à suivre pour la création d’un graphe de connaissances à partir de documents textuels via LLM, avant de voir comment l’adapter suivant ses besoins.
Les LLMs, par défaut, reçoivent en entrée du texte (prompt) et renvoient en sortie du texte généré en réponse au prompt. Cependant, suivant les instructions, les LLM offrent la possibilité de générer des outputs structurés tels que des fichiers JSON. C’est souvent sur la base de cette fonctionnalité que se base l’extraction de connaissances vers un graphe, car cet output structuré pourra être traité de façon systématique.
Un script (par ex. python) va récupérer les chunks et les envoyer un à un au LLM en imposant une réponse structurée (par ex. langchain avec la méthode llm.with_structured_output()), avec des instructions concernant la tâche, le genre d’information à détecter dans le texte, et la structure de la réponse attendue en sortie. L’output structuré (typiquement en JSON) est ensuite simplement décomposé en python afin de récupérer les informations (nœuds/relations) détectées par le LLM, qui peuvent ensuite être directement ajoutées au graphe (via un database driver).
Il est intéressant de noter que les LLM peuvent fournir une grande diversité de réponses, et l’utilisation d’une sortie structurée n’est pas forcément toujours nécessaire. Dans certains cas, le plus simple est encore de demander au LLM de fournir ses extractions sous la forme de requêtes (par exemple, de requêtes qui ajoutent directement les nœuds/relations détectées), qui peuvent être exécutées telles quelles, ou sous forme de triplets RDF.
Maintenant que nous avons vu la procédure générale, nous allons regarder plus en détail les différentes façons d’extraire et de représenter l’information contenue dans les chunks au sein d’un graphe, en commençant par l’approche la plus simple (extraction de thèmes) jusqu’à la plus complète (extraction d’entités et de relations).
Extraction thématique
Dans cette première approche, on va s’intéresser à la détection et l’extraction des thèmes abordés dans le document. On y construit donc une représentation thématique des différents documents du corpus de sorte à obtenir une structure de type :

Le graphe a donc une structure légère et est utilisé à des fins de référencement, afin d’identifier facilement et rapidement les documents traitant d’un (ou plusieurs) sujet(s) d’intérêt donné(s). Ce type de graphe permet aussi d’établir des similarités entre documents (ou entre chunks) sur la base des sujets qu’ils ont en commun, ou simplement d’avoir une représentation schématique du corpus de documents et des thèmes qui y sont abordés.
Cela peut se faire soit de façon non-dirigée (laisser le LLM déterminer librement de la liste des thèmes abordés dans le chunk), soit dirigée (le LLM choisit un ou plusieurs thèmes parmi une liste prédéfinie de thèmes fournie dans les instructions du prompt).
Extraction d’entités nommées
L’extraction (ou reconnaissance) d’entités nommées (named-entity recognition, souvent abrégé en NER) est un domaine bien connu du traitement du langage naturel (natural language processing (NLP)) qui consiste à détecter et catégoriser les entités (personne, organisation, lieu, etc.) qui sont nommées dans un texte. L’objectif va donc être similaire à celui de l’extraction thématique : créer un graphe en liant les chunks de texte aux entités qui y sont mentionnées. Nous obtenons donc un graphe avec le schéma-type suivant :
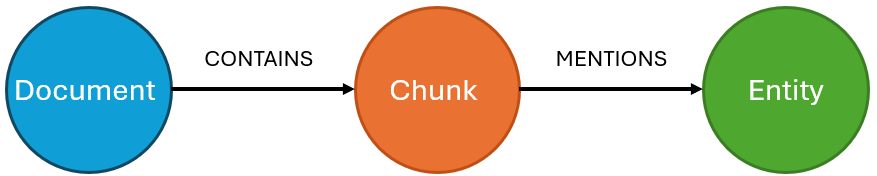
Ce type de graphe permet aussi d’établir des similarités entre documents (ou entre chunks) sur la base des entités qu’ils ont en commun. Il est intéressant de noter que cette extraction est similaire à une extraction complète (incluant entités et relations, voir section ci-dessous), si ce n’est qu’ici seules les entités sont extraites, et pas les relations qui les interconnectent. Il s’agit d’une solution plus légère et facile à mettre en place, lorsqu’une extraction complète n’est pas nécessaire.
Ce genre d’extraction peut se faire facilement par l’utilisation de LLM avec outputs structurés. Le package pydantic permet de créer des templates sur mesure pour la structure attendue en sortie. Par exemple :
from pydantic import BaseModel, Field
from typing import List
class Entity(BaseModel):
category: str = Field(description="The category of the entity.")
name: str = Field(description="The name of the entity.")
class Extraction(BaseModel):
entityList: List[Entity] = Field(description="The list of extracted entities.")
structured_llm = llm.with_structured_output(Extraction)
extracted=structured_llm.invoke(myPrompt)
Dans cet exemple simple, on demande au LLM de retourner une sortie structurée de type « Extraction », avec comme attribut « entityList » qui est une liste d’objets « Entity » définis juste avant.
Il est intéressant de noter que ce type de template peut être enrichi si l’on souhaite extraire des informations supplémentaires ou contraindre le type d’entités détectées. Par exemple, si l’on souhaite uniquement détecter des entités de type « personne » et « entreprise », le template peut être modifié en créant des classes « Personne » et « Entreprise », dans lesquelles on listera les attributs que l’on souhaite extraire pour chaque instance de ces entités, et en remplaçant le champs « entityList » par deux champs « personList » et « enterpriseList » dans l’objet final à retourner.
L’avantage d’utiliser la méthode with_structured_output est que langchain vérifiera automatiquement que la sortie du LLM est bien conforme au template.
Extraction d’entités et de relations
L’objectif ici est la construction d’un graphe qui va représenter la connaissance contenue au sein du ou des documents sous la forme d’entités (nœuds) interconnectées (relations). Il s’agit de la tâche la plus complète (et la plus compliquée), sur laquelle nous allons nous pencher le plus en détail.
Prenons le chunk de texte suivant, afin d’illustrer le genre d’extraction que nous souhaitons réaliser ici :
“The San Fransisco-based 9th U.S. Circuit Court of Appeals rejected the legal challenge by the Federal Trade Commission to Microsoft’s $69 billion acquisition of Activision Blizzard, the developer of “Call of Duty.” A three‑judge panel unanimously upheld a lower court’s decision denying a preliminary injunction, finding that the FTC had not demonstrated a likelihood of success in proving the merger would harm competition. The acquisition, completed in late 2023 following UK regulatory approval, is the largest ever in the video gaming industry.”
(Source: adapted from Reuters, 2025).
Une fois l’information extraite, voici un exemple de graphe qu’il est possible de construire depuis ce texte :
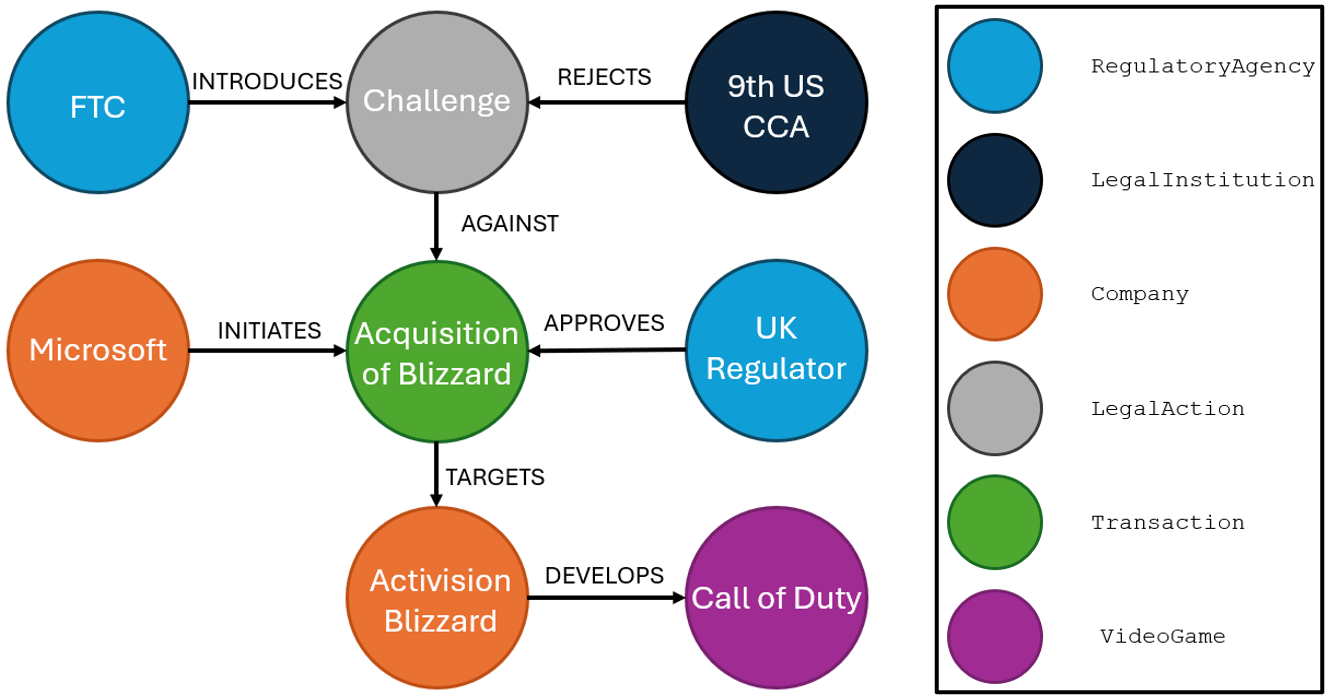
Ce type d’extraction peut se faire de nombreuses façons différentes. La prochaine section sera spécialement dédiée aux différentes approches qui peuvent être adoptées pour réaliser une extraction complète, leurs avantages et inconvénients.
Quelles approches pour réaliser une extraction d’entités et de relations ?
Extraction manuelle VS outils dédiés
La construction d’un graphe de ce type peut se faire de manière manuelle en suivant la technique présentée dans la section précédente (envoyer un prompt incluant les instructions et le chunk au LLM, récupérer et décomposer l’output structuré renvoyé en sortie, puis mettre à jour le graphe via requêtes), ou alors langchain propose un outil permettant d’automatiser ces différentes tâches via le LLM Graph Transformer.
Cet outil permet de simplifier la procédure, en prenant en charge les instructions au LLM, la construction du template et le traitement de la sortie structurée. Il offre plusieurs possibilités de personnalisation, comme la possibilité de restreindre les types de nœud que l’on souhaite détecter (par ex. uniquement des nœuds de type « Person », « Company » et « Location »), de restreindre les types de relation, ou encore de personnaliser le prompt d’instructions.
De plus, une instance LLMGraphTransformer renvoie en sortie liste d’objets de type GraphDocument, contenant les nœuds et relations détectés, qui est exploitable directement par plusieurs drivers langchain vers des bases de données orientées graphe (telles que Memgraph, TigerGraph, Neo4j, etc.), afin de réaliser directement l’importation des entités et relations extraites vers le graphe.
Ci-dessous, un exemple illustratif de l’extraction des données depuis une liste de chunks via l’outil LLMGraphTransformer, suivie de l’importation des entités et relations vers Neo4j :
doc_transformer=LLMGraphTransformer(llm=llm)
graph_docs=doc_transformer.convert_to_graph_documents(listOfChunks)
from langchain_neo4j import Neo4jGraph
graph=Neo4jGraph(
url='XXXXX',
username='YYYYY',
password='ZZZZZ'
)
graph.add_graph_documents(graph_docs)
Il existe aussi une alternative gratuite pour Neo4j, qui ne requiert aucune programmation, le Neo4j LLM Knowledge Graph Builder. Cet outil en ligne prend toutes les étapes en charge, en allant du prétraitement des documents (pdf, page web) jusqu’à la construction du graphe de connaissances résultant, et offre de multiples options de personnalisation (contraindre les types d’entité et/ou de relation à détecter, etc.). Voir ici pour plus de détails.
Extraction libre VS extraction supervisée
Il est à noter que si aucune contrainte (sur les types d’entité et de relation à extraire) n’est définie avec ces outils, ils vont librement extraire toutes les informations qu’ils peuvent trouver. Ce genre d’extraction « à l’aveugle » peut éventuellement être utilisée pour des petits documents, ou dans des cas où l’on ne sait pas à l’avance le genre de structure que l’on peut extraire, mais il est généralement préférable d’établir à l’avance l’ontologie que l’on souhaite adopter pour le graphe.
Une extraction libre est en effet souvent problématique pour plusieurs raisons :
Explosion des types d’entité et de relation
Lorsque la taille ou le nombre de documents augmente, l’on risque rapidement de se retrouver avec un très grand nombre de types différents d’entités et de relations au sein du graphe, ce qui peut le rendre difficile à exploiter (par ex. pour des applications de RAG).
Incohérence de types
En l’absence d’une ontologie fournissant une nomenclature claire, il y a des risques d’incohérence dans les types détectés (par exemple, une entreprise pourra être labelisée comme « Enterprise », une autre comme « Company », et une troisième comme « Organization »). En pratique, ce genre de soucis peut potentiellement être réglé a posteriori en listant tous les types de nœud et en rassemblant les types sémantiquement proches.
Soucis de réification
Par définition, une relation dans un graphe relie un nœud à un autre nœud. Un souci peut émerger lorsqu’une entité doit se connecter à une information qui a été modélisée sous la forme d’une relation. Pour illustrer le problème, reprenons en guise d’exemple l’acquisition d’Activision Blizzard par Microsoft. Supposons qu’un premier chunk de texte mentionne simplement cette acquisition sans plus de détails, elle sera fort potentiellement enregistrée sous la forme :
(Microsoft)-[ACQUIRES]->(Activision Blizzard)
Si maintenant le chunk suivant mentionne l’information « The FTC challenged the acquisition… », nous avons un problème car il n’est plus possible de modéliser
(FTC)-[CHALLENGES]->(Acquisition)
puisque l’acquisition a été précédemment modélisée sous la forme d’une relation, et non d’un nœud pouvant être référencé par une relation.
Dans ce cas, la relation peut par exemple être supprimée puis remplacée par un nœud, afin de la rendre référençable :
(Microsoft)-[INITIATES]->(Acquisition)-[TARGETS]->(Activision Blizzard)
Ce processus, appelé réification, n’est pas automatique et demande l’ajout d’une étape d’enrichissement pour détecter de potentielles références à des informations modélisées sous forme de relations, et les réifier si nécessaire.
Quelques alternatives aux LLM
Maintenant que nous avons vu une série d’approches basées spécifiquement sur les LLM, cette section propose quelques outils alternatifs basés sur des méthodes de NLP classique.
Si l’objectif est uniquement de faire l’extraction d’entités nommées, vous pouvez trouver ici un article de blog dédié à ce sujet, ainsi qu’un exemple d’application de NER en PII filtering. Il existe de nombreux modèles de NER préentrainés disponibles sur des plateformes telles que Hugging Face.
Concernant l’extraction d’entités et de relations, elle peut se faire typiquement de 2 façons distinctes :
- L’extraction en 2 étapes séparées : l’on commence par l’utilisation d’un NER pour la détection et la catégorisation des entités, suivie d’une extraction de relations sur la base du texte et des entités détectées, afin de déterminer les relations entre ces dernières. Quelques exemples d’outils pour l’extraction de relations incluent openNRE, spacy-relation-extraction ou encore GliREL.
- L’extraction conjointe (end-to-end) : il s’agit d’outils qui réalisent l’extraction d’entités et de relations en une seule étape, tels que OpenIE, Relik, REBEL ou Diffbot (solution commerciale).
Vérifier la conformité de ce qui a été détecté
La grande force des LLM pour ce genre de tâche d’extraction est leur compréhension du langage naturel, ce qui permet de personnaliser l’extraction en adaptant le prompt d’instructions. Par exemple, en l’absence de template de sortie pour la réponse structurée (que le LLM peut peiner à respecter si le template devient trop compliqué), il est possible d’obtenir des nœuds et relations conformes à l’ontologie en décrivant l’ontologie directement dans le prompt d’instructions, mais il est important de rester vigilant aux extractions. En effet, il n’y a aucune garantie que le LLM ne fasse pas d’erreur, et ne renvoie pas en sortie une relation/entité non-conforme.
De manière générale, lorsqu’un LLM (ou tout autre outil) est utilisé pour extraire de l’information de façon automatique depuis un texte vers un graphe de connaissances, il est utile de vérifier que ce qui a été extrait est bien conforme à l’ontologie et fidèle à l’information qui se trouve dans la source.
- Vérifier que l’extraction respecte l’ontologie
Comme nous l’avons déjà mentionné dans un précédent article de blog, il est possible de valider la structure et le contenu d’un graphe de connaissances à l’aide du standard SHACL. Il s’agit d’un langage qui va contenir les différentes contraintes qui s’appliquent sur un graphe de connaissances. Il est possible soit d’effectuer une validation finale du graphe, pour vérifier que le contenu respecte effectivement les contraintes énoncées en SHACL (et de lister les données qui violent ces contraintes), soit d’effectuer ces validations de façon transactionnelle à chaque nouvelle information qui est ajoutée, afin de refuser tout nouvel ajout illégal. Bien qu’initialement prévu pour des graphes en RDF, certaines bases de données peuvent tout de même interpréter des contraintes en SHACL et valider le graphe, comme neo4j avec le package neosemantics (n10s).
- Vérifier que l’extraction est correcte
Le risque d’une extraction automatique est qu’une information introduite dans le graphe soit factuellement incorrecte vis-à-vis du texte d’origine, ce qui peut être particulièrement problématique si ce graphe est utilisé comme potentielle source d’information (par exemple pour une application de graphRAG). Plusieurs approches peuvent être suivies. La plus simple est une vérification humaine des informations extraites, mais cela peut devenir difficile, voire infaisable, lorsque les documents deviennent trop longs/nombreux. L’autre approche consiste à utiliser un second LLM afin de vérifier ce qui a été extrait de chaque chunk. Comme nous l’avons mentionné dans l’article d’évaluation de LLM, il est plus facile, pour les LLM, de détecter les erreurs a posteriori que de les éviter.
Conclusion
Ces technologies, bien que performantes, ne sont jamais parfaites. Sauf extraction libre (à l’aveugle), mais qui risque d’aboutir à la création d’un graphe difficilement exploitable, la construction d’un graphe de connaissances à partir de texte est une tâche qui demande du travail, tant en amont (prétraitement des textes, établissement d’une ontologie pour le graphe sur la base du contenu du texte) qu’en aval (validation de la structure du graphe vis-à-vis de l’ontologie et vérification de la véracité et la fiabilité de son contenu).
Ce post est une contribution individuelle de Pierre Leleux, data scientist et network data analyst chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.