Graphs, en meer bepaald knowledge graphs, maken het mogelijk om informatie op een gestructureerde manier weer te geven. Zo krijgt een persoon een visuele samenvatting van de inhoud van een of meerdere documenten en kan een machine deze structuur gebruiken om bijvoorbeeld de inhoud ervan te analyseren (met behulp van graphalgoritmen) en/of redeneringen te maken op basis van de graph (bijvoorbeeld in het kader van een graphRAG-toepassing of om impliciete informatie te ontdekken (af te leiden)).
Dit artikel gaat in op de manieren waarop een graph kan worden verkregen op basis van tekstuele data, de verschillende soorten graphs die kunnen worden geëxtraheerd en de tools die vaak worden gebruikt, afhankelijk van het type extractie dat men wil uitvoeren.
Aangezien grote taalmodellen (LLM’s) bijzonder geschikt zijn voor tekstverwerking, zal dit artikel zich voornamelijk richten op de presentatie van LLM-gebaseerde benaderingen en vervolgens kort ingaan op verschillende alternatieve benaderingen.
Knowledge graphs: een kort overzicht
Een graph is een structuur die bestaat uit een reeks nodes en bogen (die paren van nodes met elkaar verbinden). Een knowledge graph voegt een extra semantische laag toe aan een klassieke graph, waarbij elke node een concept vertegenwoordigt (entiteit, persoon, enz.) en elke boog een relatie tussen twee concepten vertegenwoordigt (“werkt voor”, “is bevriend met”, enz.). Het is dus een weergave van kennis in de vorm van een reeks onderling verbonden entiteiten. Meer details over de verschillende soorten graphs en de bijbehorende tools vindt u hier.
Voorbereiding van het documentcorpus
Voor de eenvoud gaan we ervan uit dat de tekstdocumenten die worden gebruikt om de graph op te bouwen, correct zijn opgeschoond. Dit artikel is namelijk niet bedoeld om de voorbewerking van tekstdocumenten (scrapen van webpagina’s, extraheren van tekst uit pdf-bestanden, enz.) te bespreken, aangezien deze voorbewerking op zich al een uitgebreid onderwerp is dat ongetwijfeld een apart artikel verdient.
Fragmentatie van de tekst in “chunks”
Een belangrijke stap in de voorbereiding van tekstdata voordat entiteiten en relaties worden geëxtraheerd, is het opsplitsen van de tekst in fragmenten (meestal ‘chunks’ genoemd). We hebben het concept van chunking al meerdere keren besproken in vorige blogposts. Wanneer een document te lang is (meer dan enkele paragrafen), is het raadzaam om het op te splitsen in chunks (tekstfragmenten van redelijke omvang) die één voor één door de LLM worden verwerkt. Deze procedure maakt het mogelijk om de hoeveelheid informatie in elke chunk te beperken, zodat deze niet te veel entiteiten en relaties bevat die moeten worden geëxtraheerd. Deze opsplitsing in chunks kan op verschillende manieren gebeuren, hetzij op basis van het aantal woorden in de chunk, hetzij op basis van een vooraf gedefinieerd scheidingsteken (bijvoorbeeld een regeleinde dat het einde van de paragraaf aangeeft).
De informatie weergeven of de structuur weergeven
Laten we beginnen met de twee belangrijkste soorten graphs die kunnen worden geconstrueerd op basis van een reeks tekstdocumenten.
De eerste is een graph die de structuur van het document weergeeft (document structure graph), en niet de informatie die in de tekst staat. Bijvoorbeeld door de chunks te koppelen aan het document waaruit ze zijn gehaald en de volgorde waarin ze in het document voorkomen:
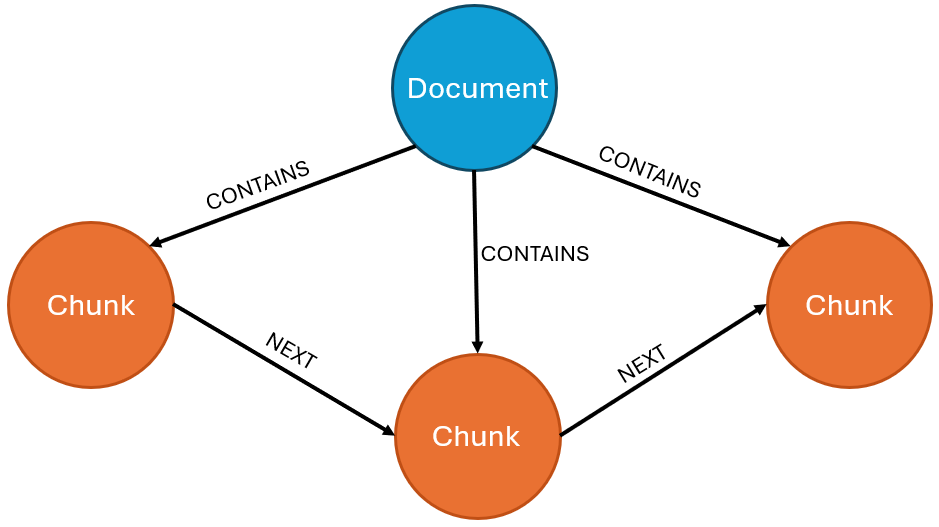
Dit type graph kan ook worden verrijkt door relaties toe te voegen tussen semantisch vergelijkbare chunks of, indien van toepassing, door de hiërarchische organisatie van het document weer te geven in secties, subsecties, enz. Dit gebeurt via nodes die de secties/subsecties vertegenwoordigen en relaties van het type “HAS_SECTION”, “HAS_SUBSECTION”, evenals relaties die de volgorde van de secties/subsecties aangeven. Zodra de graph is opgebouwd, kan deze bijvoorbeeld worden gebruikt in RAG-toepassingen voor indexeringsdoeleinden om context te bieden aan de gebruikte chunks (zie onze blogpost over graphRAG).
Het tweede type graph bestaat uit het opnemen van de informatie in de documenten in de vorm van nodes en relaties:

In het kader van deze blogpost zullen we ons concentreren op dit tweede type graph. Merk op dat beide benaderingen elkaar niet uitsluiten. Als men voor het tweede type graph kiest, is het trouwens vaak nuttig om ook de documentstructuur weer te geven. Zo kan men indien nodig teruggaan naar de bron van de informatie in de graph.

Opbouw van een knowledge graph met behulp van een LLM
Eerst zullen we de algemene procedure voor het aanmaken van een knowledge graph op basis van tekstdocumenten via LLM voorstellen, alvorens te bekijken hoe deze aan de eigen behoeften kan worden aangepast.
LLM’s ontvangen standaard tekst als input (prompt) en sturen tekst terug als output in reactie op de prompt. Afhankelijk van de instructies bieden LLM’s echter de mogelijkheid om gestructureerde outputs te genereren, zoals JSON-bestanden. Vaak wordt deze functionaliteit gebruikt als basis voor het extraheren van kennis naar een graph, omdat deze gestructureerde output systematisch kan worden verwerkt.
Een script (bv. Python) haalt de chunks op en stuurt ze een voor een naar de LLM door een gestructureerd antwoord op te leggen (bv. LangChain met de methode llm.with_structured_output()), met instructies over de taak, het type informatie dat in de tekst moet worden gedetecteerd en de structuur van het verwachte antwoord in de output. De gestructureerde output (meestal in JSON) wordt vervolgens eenvoudigweg ontleed in Python om de door de LLM gedetecteerde informatie (nodes/relaties) op te halen, die vervolgens rechtstreeks aan de graph kan worden toegevoegd (via een databasedriver).
Interessant is dat LLM’s een grote verscheidenheid aan antwoorden kunnen geven en dat het gebruik van gestructureerde output niet altijd nodig is. In sommige gevallen is het nog steeds het eenvoudigst om de LLM te vragen zijn extracties te leveren in de vorm van queries (bijvoorbeeld queries die de gedetecteerde nodes/relaties direct toevoegen), die als zodanig kunnen worden uitgevoerd, of in de vorm van RDF triples.
Na de algemene procedure, kijken we nu meer in detail naar de verschillende manieren om de informatie in de chunks binnen een graph te extraheren en weer te geven, te beginnen met de eenvoudigste benadering (thema-extractie) tot de meest complete (extractie van entiteiten en relaties).
Thematische extractie
In deze eerste benadering richten we ons op het opsporen en extraheren van de thema’s die in het document aan bod komen. We bouwen dus een thematische weergave van de verschillende documenten in het corpus om een structuur te verkrijgen van het type:

De graph heeft dus een lichte structuur en wordt gebruikt voor referentiedoeleinden, om gemakkelijk en snel documenten te identificeren die betrekking hebben op een (of meerdere) bepaald(e) onderwerp(en) van belang. Met dit type graph kunnen ook gelijkenissen tussen documenten (of tussen chunks) worden vastgesteld op basis van de gemeenschappelijke onderwerpen, of kan eenvoudigweg een schematische weergave worden gegeven van hun corpus van documenten en de thema’s die daarin aan bod komen.
Dit kan op een niet-gestuurde manier (de LLM vrij laten bepalen welke thema’s in de chunk aan bod komen) of op een gestuurde manier gebeuren (de LLM kiest een of meer thema’s uit een vooraf gedefinieerde lijst met thema’s die in de instructies van de prompt wordt gegeven).
Extractie van named entities
De extractie (of herkenning) van named entities (named-entity recognition, vaak afgekort tot NER) is een bekend domein van natuurlijke taalverwerking (natural language processing (NLP)) dat bestaat uit het detecteren en categoriseren van entiteiten (personen, organisaties, plaatsen, enz.) die in een tekst worden genoemd. Het doel is dus vergelijkbaar met dat van thematische extractie: een graph maken door tekstfragmenten te koppelen aan de entiteiten die erin worden genoemd. We krijgen dus een graph met het volgende standaard schema:
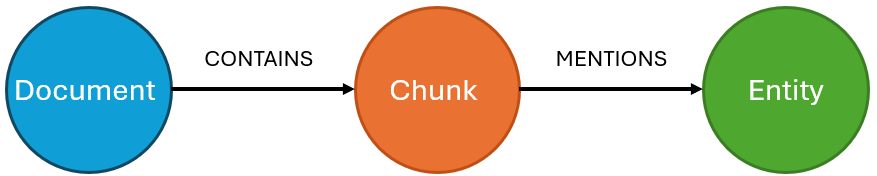
Met dit type graph kunnen ook gelijkenissen tussen documenten (of tussen chunks) worden vastgesteld op basis van de entiteiten die ze gemeenschappelijk hebben. Het is interessant om op te merken dat deze extractie vergelijkbaar is met een volledige extractie (inclusief entiteiten en relaties, zie onderstaande paragraaf), behalve dat hier alleen de entiteiten worden geëxtraheerd en niet de relaties die ze met elkaar verbinden. Dit is een lichtere en gemakkelijker te implementeren oplossing wanneer een volledige extractie niet nodig is.
Dit soort extractie kan gemakkelijk worden uitgevoerd met behulp van een LLM met gestructureerde outputs. Met het pydantic-pakket kunnen op maat gemaakte templates worden gemaakt voor de verwachte outputstructuur. Bijvoorbeeld:
from pydantic import BaseModel, Field
from typing import List
class Entity(BaseModel):
category: str = Field(description="The category of the entity.")
name: str = Field(description="The name of the entity.")
class Extraction(BaseModel):
entityList: List[Entity] = Field(description="The list of extracted entities.")
structured_llm = llm.with_structured_output(Extraction)
extracted=structured_llm.invoke(myPrompt)
In dit eenvoudige voorbeeld wordt de LLM gevraagd om een gestructureerde output van het type “Extraction” terug te geven, met als attribuut “entityList”, een lijst van “Entity”-objecten “ die net daarvoor zijn gedefinieerd.
Het is interessant om op te merken dat dit type template kan worden uitgebreid wanneer we extra informatie willen extraheren of het type gedetecteerde entiteiten willen beperken. Als we bijvoorbeeld alleen entiteiten van het type “persoon” en “onderneming” willen detecteren, kan de template worden aangepast door de klassen “ Persoon” en “Onderneming” aan te maken, waarin de attributen worden opgesomd die voor elke instantie van deze entiteiten moeten worden geëxtraheerd, en door het veld ”entityList“ te vervangen door twee velden “personList” en ”enterpriseList” in het uiteindelijke object dat moet worden teruggegeven.
Het voordeel van het gebruik van de methode with_structured_output is dat LangChain automatisch controleert of de output van de LLM overeenkomt met de template.
Extractie van entiteiten en relaties
Het doel hier is het bouwen van een graph die de kennis in het document of de documenten weergeeft in de vorm van onderling verbonden entiteiten (nodes) en relaties. Dit is de meest uitgebreide (en meest ingewikkelde) taak die we in detail zullen bekijken.
Laten we het volgende stukje tekst nemen om te illustreren wat voor soort extractie we hier willen uitvoeren:
“The San Fransisco-based 9th U.S. Circuit Court of Appeals rejected the legal challenge by the Federal Trade Commission to Microsoft’s $69 billion acquisition of Activision Blizzard, the developer of “Call of Duty.” A three‑judge panel unanimously upheld a lower court’s decision denying a preliminary injunction, finding that the FTC had not demonstrated a likelihood of success in proving the merger would harm competition. The acquisition, completed in late 2023 following UK regulatory approval, is the largest ever in the video gaming industry.”
(Source: adapted from Reuters, 2025).
Zodra de informatie is geëxtraheerd, is dit een voorbeeld van een graph die op basis van deze tekst kan worden gemaakt:
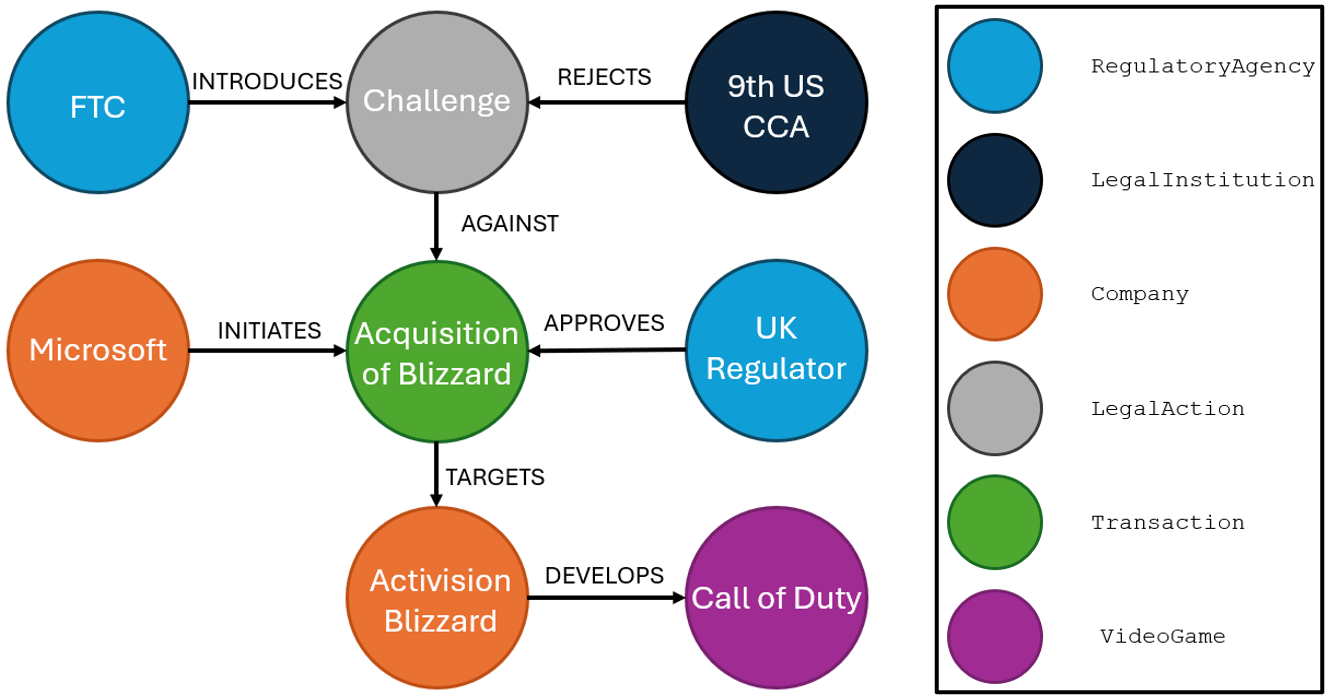
Dit type extractie kan op veel verschillende manieren worden uitgevoerd. Het volgende deel is speciaal gewijd aan de verschillende benaderingen om een volledige extractie uit te voeren, en aan de voor- en nadelen daarvan.
Welke benaderingen zijn er voor het extraheren van entiteiten en relaties?
Handmatige extractie versus speciale tools
Een dergelijke graph kan manueel worden opgebouwd volgens de techniek die in het vorige deel werd voorgesteld (een prompt met instructies en de chunk naar de LLM sturen, de gestructureerde output ophalen en ontleden, en vervolgens de graph bijwerken via queries), ofwel biedt LangChain een tool aan om deze verschillende taken te automatiseren via de LLM Graph Transformer.
Deze tool vereenvoudigt de procedure door de instructies aan de LLM, het opstellen van de template en de verwerking van de gestructureerde output voor zijn rekening te nemen. De tool biedt verschillende instelmogelijkheden, zoals de mogelijkheid om de soorten nodes die gedetecteerd moeten worden te beperken (bv. alleen nodes van het type “Person”, “Company” en “Location”), de soorten relaties te beperken of de instructieprompt aan te passen.
Bovendien geeft een LLMGraphTransformer-instantie een lijst terug met objecten van het type GraphDocument, die de gedetecteerde nodes en relaties bevat en die direct kan worden gebruikt door verschillende LangChain-drivers naar graph-gerichte databases (zoals Memgraph, TigerGraph, Neo4j, enz.), om de geëxtraheerde entiteiten en relaties direct in de graph te importeren.
Hieronder volgt een voorbeeld van het extraheren van data uit een lijst met chunks met behulp van de LLMGraphTransformer-tool, gevolgd door het importeren van de entiteiten en relaties naar Neo4j:
doc_transformer=LLMGraphTransformer(llm=llm)
graph_docs=doc_transformer.convert_to_graph_documents(listOfChunks)
from langchain_neo4j import Neo4jGraph
graph=Neo4jGraph(
url='XXXXX',
username='YYYYY',
password='ZZZZZ'
)
graph.add_graph_documents(graph_docs)
Er bestaat ook een gratis alternatief voor Neo4j, waarvoor geen programmering nodig is: de Neo4j LLM Knowledge Graph Builder. Deze online tool neemt alle stappen voor zijn rekening, van de voorbewerking van documenten (pdf, webpagina) tot de opbouw van de resulterende knowledge graphs, en biedt tal van personaliseringsopties (het beperken van de te detecteren entiteit- en/of relatietypes, enz.). Zie hier voor meer details.
Vrije extractie versus begeleide extractie
Merk op dat als er met deze tools geen beperkingen (op de soorten entiteiten en relaties die moeten worden geëxtraheerd) worden gedefinieerd, ze in alle vrijheid alle informatie zullen extraheren die ze kunnen vinden. Dit soort “blinde” extractie kan eventueel worden gebruikt voor kleine documenten, of in gevallen waarin men van tevoren niet weet wat voor soort structuur men kan extraheren, maar het is over het algemeen beter om van tevoren de gewenste ontologie voor de graph vast te leggen.
Vrije extractie is namelijk vaak een probleem om verschillende redenen:
Explosie van entiteitstypen en relaties
Naarmate de omvang of het aantal documenten toeneemt, bestaat het risico dat er al snel een zeer groot aantal verschillende soorten entiteiten en relaties in de graph terechtkomen, waardoor deze moeilijk te gebruiken kan worden (bijvoorbeeld voor RAG-toepassingen).
Inconsistentie van types
Bij gebrek aan een ontologie die een duidelijke nomenclatuur biedt, bestaat het risico van inconsistentie in de gedetecteerde types (een bedrijf kan bijvoorbeeld worden gelabeld als “Enterprise”, een ander als “Company” en een derde als “Organization”). In de praktijk kunnen dit soort problemen achteraf worden opgelost door alle soorten nodes op te sommen en semantisch verwante soorten te groeperen.
Problemen met reïficatie
Per definitie verbindt een relatie in een graph een node met een ander node. Er kan een probleem ontstaan wanneer een entiteit moet worden gekoppeld aan informatie die in de vorm van een relatie is gemodelleerd. Om het probleem te illustreren, nemen we als voorbeeld de overname van Activision Blizzard door Microsoft. Stel dat een eerste stuk tekst alleen deze overname vermeldt zonder verdere details, dan wordt deze hoogstwaarschijnlijk opgeslagen in de vorm:
(Microsoft)-[ACQUIRES]->(Activision Blizzard)
Stel dat de volgende chunk de informatie “The FTC challenged the acquisition…” vermeldt, dan hebben we een probleem omdat het niet meer mogelijk is om
(FTC)-[CHALLENGES]->(Acquisition)
te modelleren, aangezien de overname eerder werd gemodelleerd in de vorm van een relatie en niet als een node waarnaar door een relatie kan worden verwezen.
In dit geval kan de relatie bijvoorbeeld worden verwijderd en vervolgens worden vervangen door een node, zodat ernaar kan worden verwezen:
(Microsoft)-[INITIATES]->(Acquisition)-[TARGETS]->(Activision Blizzard)
Dit proces, dat reïficatie wordt genoemd, verloopt niet automatisch en vereist een extra verrijkingsstap om mogelijke verwijzingen naar informatie die in de vorm van relaties is gemodelleerd, op te sporen en indien nodig te reïficeren.
Enkele alternatieven voor LLM’s
Nu we een reeks benaderingen hebben bekeken die specifiek op LLM’s zijn gebaseerd, worden in dit gedeelte enkele alternatieve tools voorgesteld die zijn gebaseerd op klassieke NLP-methoden.
Voor wie alleen named entities wil extraheren, is hier een blogpost over dit onderwerp te vinden, evenals een voorbeeld van de toepassing van NER bij PII-filtering. Er zijn tal van vooraf getrainde NER-modellen beschikbaar op platforms zoals Hugging Face.
Het extraheren van entiteiten en relaties kan doorgaans op twee verschillende manieren gebeuren:
- Extractie in twee afzonderlijke stappen: eerst wordt een NER gebruikt voor het detecteren en categoriseren van entiteiten, gevolgd door een extractie van relaties op basis van de tekst en de gedetecteerde entiteiten, om de relaties tussen deze entiteiten te bepalen. Enkele voorbeelden van tools voor het extraheren van relaties zijn openNRE, spacy-relation-extraction en GliREL.
- End-to-end-extractie: tools die entiteiten en relaties in één stap extraheren, zoals OpenIE, Relik, REBEL of Diffbot (commerciële oplossing).
Nagaan of de gedetecteerde gegevens conform zijn
De grote kracht van LLM’s voor dit soort extractietaken is hun begrip van natuurlijke taal, waardoor de extractie kan worden gepersonaliseerd door de instructieprompt aan te passen. Als er bijvoorbeeld geen outputtemplate bestaat voor het gestructureerde antwoord (waar de LLM moeite mee kan hebben als de template te ingewikkeld wordt), is het mogelijk om ontologieconforme nodes en relaties te verkrijgen door de ontologie rechtstreeks in de instructieprompt te beschrijven, maar het is belangrijk om alert te blijven voor extracties. Er is namelijk geen garantie dat de LLM geen fouten maakt en geen niet-conforme relatie/entiteit als output teruggeeft.
In het algemeen geldt dat wanneer een LLM (of een andere tool) wordt gebruikt om automatisch informatie uit een tekst te extraheren naar een knowledge graph, het nuttig is om te controleren of datgene dat is geëxtraheerd wel degelijk in overeenstemming is met de ontologie en trouw is aan de informatie in de bron.
- Controleren of de extractie voldoet aan de ontologie
In een vorige blogpost hebben we al vermeld dat het mogelijk is om de structuur en inhoud van een knowledge graph te valideren met behulp van de SHACL-standaard. Dit is een taal die de verschillende beperkingen bevat die van toepassing zijn op een knowledge graph. Het is mogelijk om ofwel een definitieve validatie van de graph uit te voeren, om te controleren of de inhoud daadwerkelijk voldoet aan de in SHACL geformuleerde beperkingen (en de data die deze beperkingen overtreden op te sommen), ofwel deze validaties transactioneel uit te voeren bij elke nieuwe toevoeging van informatie, om elke nieuwe onrechtmatige toevoeging te weigeren. Hoewel SHACL oorspronkelijk bedoeld was voor graphs in RDF, kunnen sommige databases toch SHACL-beperkingen interpreteren en de graph valideren, zoals Neo4j met het neosemantics package (n10s).
- Nagaan of de extractie correct is
Het risico van automatische extractie is dat informatie die in de graph wordt ingevoerd feitelijk onjuist is ten opzichte van de oorspronkelijke tekst, wat in het bijzonder problematisch kan zijn als deze graph wordt gebruikt als potentiële informatiebron (bijvoorbeeld voor een graphRAG-toepassing). Er kunnen verschillende benaderingen worden gevolgd. De eenvoudigste is een menselijke controle van de geëxtraheerde informatie, maar dit kan moeilijk of zelfs onhaalbaar worden wanneer de documenten te lang/talrijk worden. De andere aanpak bestaat erin een tweede LLM te gebruiken om te controleren wat uit elk fragment is geëxtraheerd. Zoals we in de post over de evaluatie van LLM’s hebben vermeld, is het voor LLM’s gemakkelijker om achteraf fouten op te sporen dan ze te vermijden.
Conclusie
Deze technologieën zijn weliswaar krachtig, maar nooit perfect. Behalve vrije (blinde) extractie, die kan resulteren in een moeilijk bruikbare graph, vormt het opstellen van een knowledge graph op basis van tekst een taak die veel werk vereist. En dit zowel vooraf (voorbewerking van teksten, opstellen van een ontologie voor de graph op basis van de inhoud van de tekst), als achteraf (validatie van de structuur van de graph ten opzichte van de ontologie en controle van de juistheid en betrouwbaarheid van de inhoud).
Dit is een ingezonden bijdrage van Pierre Leleux, data scientist et network data analyst bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.