Bon nombre de systèmes dans le secteur public stockent des données personnelles, parfois très sensibles. Il s’agit entre autres de données sociales, fiscales et médicales. Il faut éviter que quiconque – de l’extérieur ou de l’intérieur – accédant illégalement à ces systèmes puisse établir un lien entre ces données et des personnes physiques. Une mesure précieuse à cet égard consiste à ne plus stocker les données sous des numéros de registre national, mais sous des pseudonymes. Ces pseudonymes sont des codes uniques qui ne peuvent être reconvertis en numéro de registre national qu’à l’aide d’une clé.
Afin de maximiser la sécurité et la confiance, cette clé ne doit être connue que par une partie indépendante du système stockant les données personnelles pseudonymisées. Nous appelons cette partie le service de pseudonymisation. Une telle approche permet également à un grand nombre de systèmes d’utiliser ce service. Nous obtenons ainsi un service de pseudonymisation générique.
Cet article est une introduction à un tel service de pseudonymisation conçu par Smals Research, qui offre un niveau de sécurité particulièrement élevé. Le service est opérationnel depuis décembre 2023 en tant que nouveau service de eHealth.
Disclaimer: Les numéros de registre national étant mieux connus que la catégorie plus large des numéros NISS, nous nous référons uniquement aux numéros de registre national dans cet article, bien que le type d’identifiant considéré ne constitue pas une limitation pour le service de pseudonymisation.
Rôles et opérations
Sans service de pseudonymisation, il y a deux rôles : le propriétaire qui stocke les données à caractère personnel et les clients qui envoient des demandes au propriétaire. Nous présentons trois scénarios à titre illustratif :
- Scénario 1 : Un médecin (client) demande au service de prescription (propriétaire) d’enregistrer une prescription électronique.
- Scénario 2 : Un pharmacien (client) demande une ordonnance au service de prescription (propriétaire) pour un citoyen en particulier.
- Scénario 3 : Une médecin (client) demande au service de prescription (propriétaire) de consulter les ordonnances électroniques qu’il a émises la veille.
Le troisième rôle est celui du service de pseudonymisation, qui est chargé de convertir le numéro de registre national du patient en pseudonyme correspondant (opération pseudonymize) ou, inversement, le pseudonyme en numéro de registre national (opération identify). Le numéro de registre national du médecin ou son numéro INAMI peuvent également être pseudonymisés de la même manière.
Les systèmes (propriétaires) communiquent également entre eux. Un service sur la plateforme eHealth pourrait demander au service TherLink si un patient a une relation thérapeutique avec un médecin en particulier. Si TherLink utilise également des pseudonymes, le pseudonyme d’un service/propriétaire devra être converti en pseudonyme de l’autre service/propriétaire (opération convert). En effet, afin de minimiser le risque d’identification, il convient de ne pas réutiliser les pseudonymes dans plusieurs services.
Ainsi, les trois opérations que le service de pseudonymisation doit prendre en charge sont pseudonymize, identify et convert. Le présent article se concentre sur l’opération pseudonymize.
Interactions
En cas d’utilisation d’un service de pseudonymisation, il convient de déterminer comment il sera possible de communiquer avec lui. À un niveau élevé, on a le choix entre le mode relay (relais) et le mode reply (réponse), illustré dans la figure ci-dessous.
- Le mode relay est le plus courant. Dans ce mode, le service de pseudonymisation agit comme un relais entre le client et le propriétaire : il reçoit du client les numéros de registre national, ainsi que d’autres données, effectue des opérations sur ces numéros (par exemple, la pseudonymisation) et transmet le résultat au propriétaire. Le service TTP eHealth est un service de pseudonymisation dans ce mode. Healthdata.be – partie de Sciensano – utilise ce service. Le système de pseudonymisation avancé conçu par le professeur néerlandais Verheul utilise également ce mode.
- En mode reply, le service de pseudonymisation reçoit une demande du client et renvoie la réponse au même client. Ce client peut, par exemple, demander qu’un pseudonyme soit converti en un numéro de registre national (identify). Entre autres, le service eHealth WS SEALS utilise ce mode
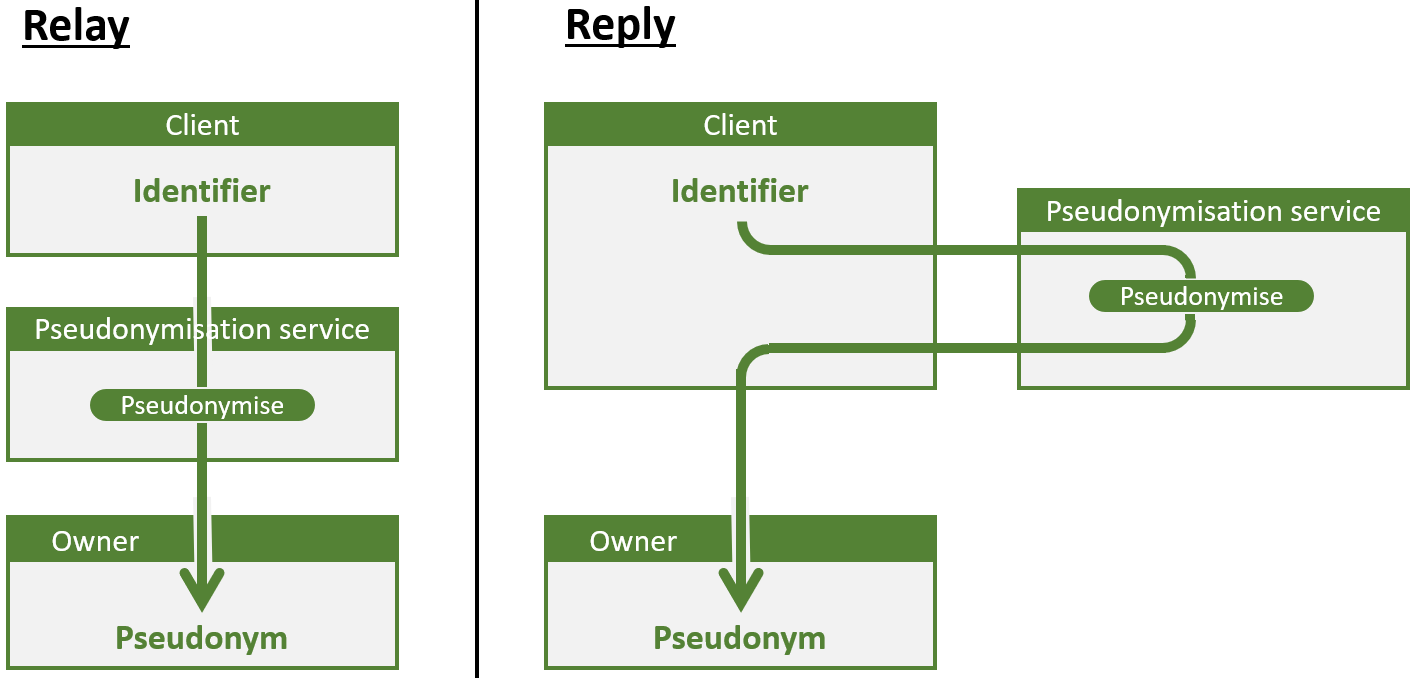
Mode reply et mode relay
Les deux approches ont leurs avantages et inconvénients. Le mode reply répond mieux aux besoins des client de Smals dans le cadre de la protection des données médicales à caractère personnel. Après tout, le mode reply a un impact moins intrusif sur des interactions existantes ; le client et le propriétaire (ou propriétaire et propriétaire en cas d’une opération convert) communiquent encore en direct et ne doivent pas se reposer sur un tiers intermédiaire afin d’envoyer les bonnes données à la bonne partie par le biais d’un canal de communication sécurisé. Les interactions de bas niveau se trouvent ainsi plus proches des interactions fonctionnelles.
Le flux de base pour le scénario 1 est représenté dans la figure ci-dessous. Les flux de base pour les deux autres scénarios sont analogues. Contrairement à la flèche épaisse, la flèche fine ne contient pas de numéro de registre national ou de pseudonyme.
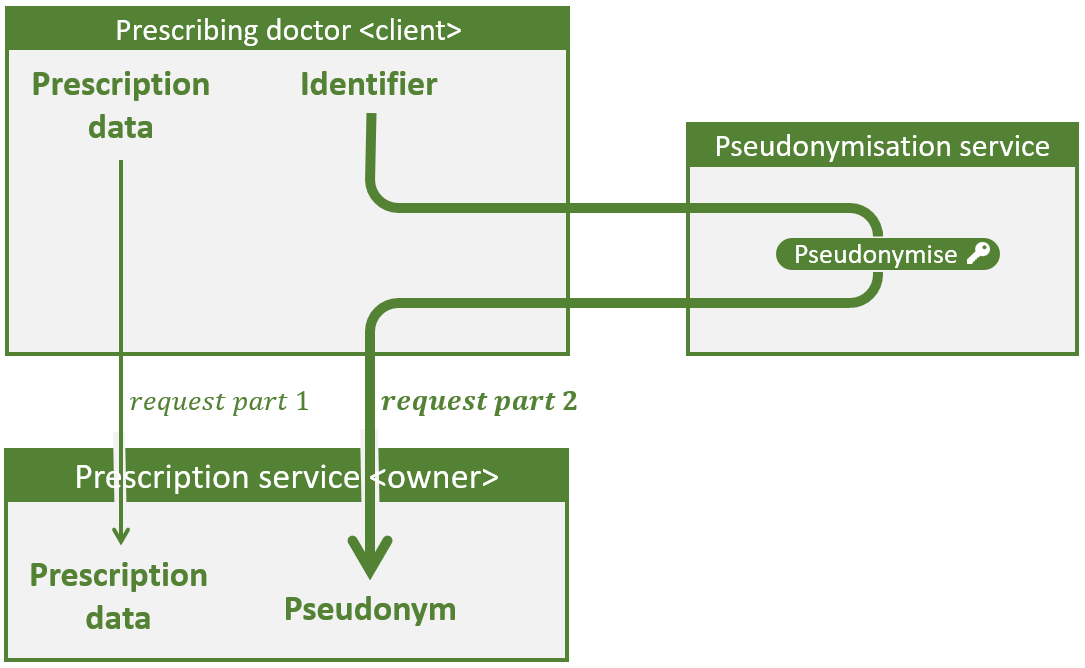
Flux de base pour le scénario 1 : Un médecin (client) demande au service de prescription (propriétaire) d’enregistrer une prescription électronique.
Garanties de sécurité élevées
Le risque pour la vie privée est que l’une des parties concernées, ou un hacker, puisse d’une manière ou d’une autre extraire des données personnelles et les relier à une personne identifiée. Ce risque se trouve considérablement réduit si chaque partie est informée uniquement de ce qui est strictement nécessaire. Concrètement, il faudrait satisfaire exigences suivantes :
- Le propriétaire ne connaît que les pseudonymes.
- Le client ne connaît que les numéros de registre national.
- Le service de pseudonymisation ne connaît ni l’un ni l’autre.
En appliquant uniquement le flux de base illustré dans la figure précédente, seul le premier point est satisfait. Dans ce qui suit, nous examinons un certain nombre de mesures visant à renforcer la sécurité. Si ces mesures sont appliquées au flux de base du scénario 1, nous obtenons la figure ci-dessous. Une clé à côté d’une opération signifie qu’une clé secrète ou privée est nécessaire, un dé que l’opération est probabiliste, c-à-d que le résultat est différent à chaque fois, même avec la même entrée.
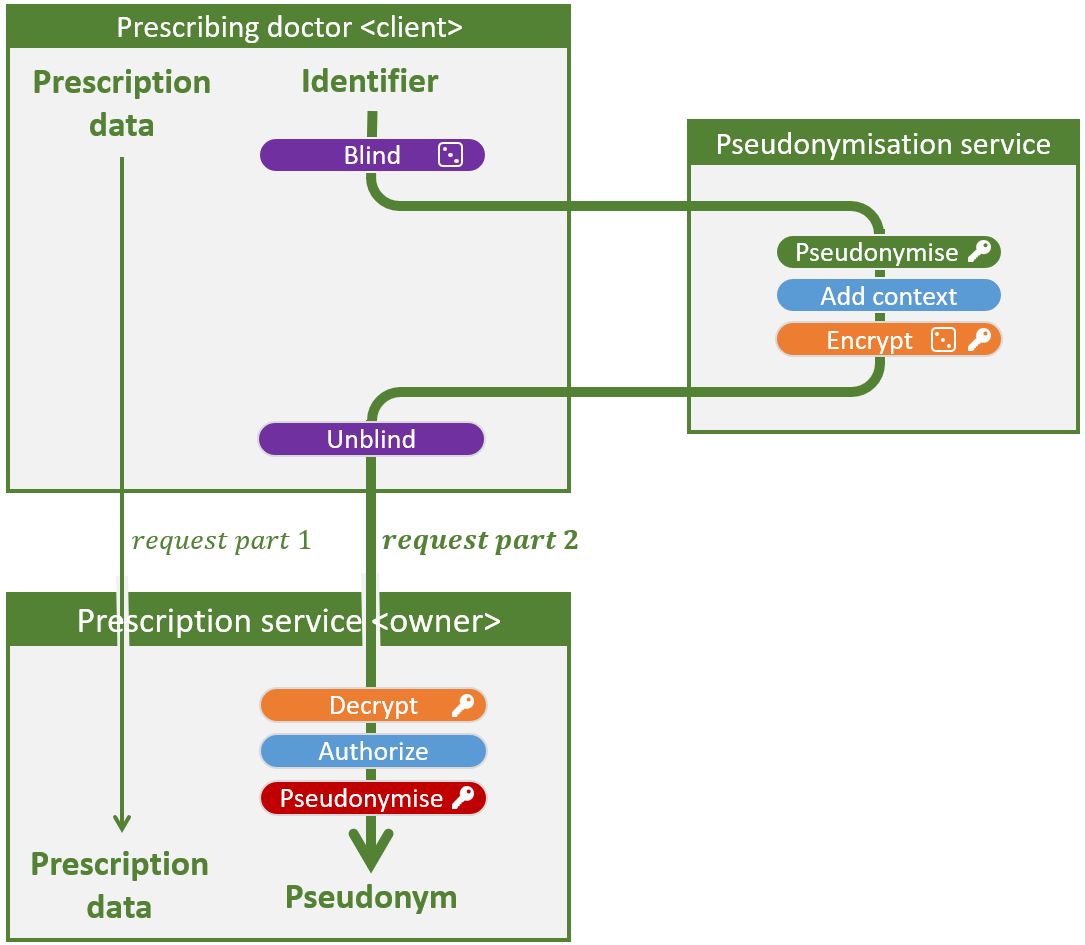
Flux de haute sécurité pour le scénario 1 : Un médecin (client) demande au service de prescription (propriétaire) d’enregistrer une prescription électronique.
Service de pseudonymisation à l’aveugle
Une première mesure est le service de pseudonymisation aveugle, qui est réalisé par les deux opérations violettes (blind et unblind). Il garantit que le service de pseudonymisation ne peut plus voir les pseudonymes et identifiants entrants et sortants, ce qui permet à un service de pseudonymisation curieux de collecter beaucoup moins d’informations et donc d’avoir moins besoin qu’on lui fasse confiance.
Pseudonymes confidentiels
Dans un flux comportant uniquement des opérations blind et unblind, le médecin (client) peut voir le pseudonyme après l’opération unblind. Ainsi, le médecin – ou un hacker – peut le lier à un numéro de registre national. Ce risque de sécurité est mitigé dans le flux de haute sécurité grâce aux pseudonymes confidentiels (orange), où une couche de chiffrement supplémentaire garantit que le client ne découvre jamais le pseudonyme, étant donné qu’il ne connaît pas la clé de déchiffrement.
En appliquant les pseudonymes aveugles aux pseudonymes confidentiels sur notre flux initial, nous réalisons les propriétés suivantes :
- Le client est hypermétrope ; il ne voit que les identifiants globaux (numéros de registre national).
- Le propriétaire est myope ; il ne voit que les identifiants locaux (pseudonymes).
- Le service de pseudonymisation est aveugle ; il ne voit ni les identifiants ni les pseudonymes.
Nous introduisons deux mesures supplémentaires pour renforcer la sécurité : l’autorisation explicite et la double pseudonymisation facultative.
Autorisation explicite
Bien entendu, tout le monde ne doit pas pouvoir utiliser le service de pseudonymisation. Le droit d’envoyer telle ou telle demande au service et à telle ou telle fin est donc strictement réglementé. En outre, ces règles changent constamment : de nouveaux prestataires de soins de santé (clients) et de nouveaux services (propriétaires) sont ajoutés, et d’anciens disparaissent. Par ailleurs, les clients des dizaines de milliers de prestataires de soins de santé de ce pays n’ont pas toujours le même niveau de sécurité ; l’utilisation du service de pseudonymisation par des clients compromis devrait donc être refusée dans certaines circonstances.
Dans cette optique, il est logique de limiter la durée de validité des codes de pseudonymisation (obtenus par le client dans la figure précédente après l’opération unblind). Plus généralement, le contexte dans lequel un pseudonyme chiffré peut être utilisé peut ainsi être limité. Cela permet d’éviter la réutilisation non autorisée des algorithmes de chiffrement des pseudonymes.
C’est exactement ce que l’autorisation explicite empêche. La figure ci-dessus illustre cela à l’aide des opérations en bleu ; le service de pseudonymisation attache des règles d’autorisation (par exemple expiration time) au pseudonyme avant qu’il soit chiffré. Dès réception, le propriétaire vérifie à l’aide d’informations contextuelles (par exemple current time) si ces règles sont respectées. La capacité d’utilisation d’un chiffrement de pseudonyme peut par exemple être limitée à 5 minutes. Des règles plus avancées sont, bien évidemment, toujours possibles.
Double pseudonymisation
Malgré les règles de sécurité évoquées précédemment, il est toujours possible pour le service de pseudonymisation d’effectuer lui-même les attaques suivantes :
- Il dresse une liste de toutes les séquences de caractères possibles qui ont la structure d’un numéro de registre national. Il y en a quelques dizaines de millions, ce qui permet une réalisation rapide.
- Pour chacune de ces séquences, il effectue une opération pseudonymize.
Le service de pseudonymisation dispose maintenant d’un tableau composé de quelques dizaines de millions de paires. Environ 12 millions de ces paires contiennent un numéro de registre national effectivement attribué à un citoyen vivant.
Le fait que ce service connaisse le lien entre le numéro de registre national et le pseudonyme constitue un risque ; si un hacker peut établir un lien avec des données pseudonymisées ayant fait l’objet d’une fuite de la part du propriétaire, il peut facilement procéder à une réidentification
Ce risque peut être atténué par la double pseudonymisation (rouge). Afin de convertir un numéro de registre national en pseudonyme final ou, inversement, de reconvertir un pseudonyme en numéro de registre national, deux clés sont alors nécessaires : l’une n’est connue que du service de pseudonymisation, l’autre que du propriétaire. L’inconvénient est que le propriétaire doit maintenant sécuriser une clé et effectuer davantage d’opérations cryptographiques. Étant donné que cela n’est pas toujours évident et que le risque est limité, cette étape est facultative.
Conclusions
Le service de pseudonymisation décrit dans cet article offre des garanties de sécurité extrêmement élevées, tout en restant d’une complexité gérable. En particulier du côté du client (par exemple le médecin), elle reste très limitée, ce qui facilite l’intégration de la solution dans le logiciel client existant utilisé par plusieurs dizaines de milliers de prestataires de soins de santé dans notre pays.
En effet, le client n’a pas besoin de gérer de clé à long terme et effectue les mêmes opérations à chaque fois : un blind et un unblind avec un appel au service de pseudonymisation entre les deux. La complexité pour les prestataires de soins de santé est donc très limitée.
En outre, les interactions existantes sont respectées, ce qui limite les coûts de réorganisation des processus existants.
La solution évite la réidentification des données à caractère personnel sur la base des numéros de registre national. Il convient de noter que la réidentification peut également être possible dans certains cas sur la base des données elles-mêmes, même si elles ne sont connues que sous un pseudonyme. Dans ce cas, des mesures de sécurité supplémentaires, telles que le chiffrement, peuvent s’imposer.
Une proposition initiale de Smals Research pour un service de pseudonymisation générique a été affinée et étendue en étroite collaboration avec d’autres services de Smals, afin de l’adapter aux besoins de l’entreprise. Smals Research a développé à la fois le concept théorique et le PoC (Proof of Concept) en Java ; ce dernier a été utilisé par eHealth comme source d’inspiration pour la construction d’un service de santé en ligne mis en service en décembre 2023.
Enfin, nous mentionnons que Smals Research travaille également sur un autre type de pseudonymisation, visant un ensemble de use cases ; (la pseudonymisation préservant la structure présente l’avantage que les pseudonymes ont la même structure que les identifiants, mais ne peut malheureusement pas offrir les mêmes propriétés de haute sécurité).
Si cette solution ou d’autres solutions de pseudonymisation (et de référencement croisé) des données à caractère personnel vous intéressent, n’hésitez pas à nous contacter.
Cette contribution a été soumise par Kristof Verslype, cryptographe chez Smals Research. Elle a été rédigée en son nom propre et ne prend pas position au nom de Smals.
Source image présentée: Youngsang Hwang