Les systèmes basés sur la génération augmentée par récupération (RAG) sont l’une des applications les plus populaires des grands modèles de langage (LLM). Ces systèmes augmentent les LLM en ancrant leurs réponses dans des sources de données contrôlées. Ils ont néanmoins, fait preuve de certaines limites notamment dans le contrôle des hallucinations. Un nouveau paradigme a récemment émergé qui permet de dépasser ces limites: GraphRAG. GraphRAG est une variation du RAG qui combine la puissance des LLM et des graphes de connaissances, ce qui conduit à des réponses plus précises et plus fiables.
Cet article explore le concept de GraphRAG ; il couvrira son architecture, ses avantages et son implémentation.
Concepts de base
Pour comprendre le GraphRAG, il faut d’abord introduire quelques concepts de base.
Les graphes et graphes de connaissances
Un graphe est une manière structurée d’organiser des données en nœuds et leurs relations. Un graphe de connaissances (KG) ajoute du sens aux données grâce à une ontologie et permet le raisonnement sur le graphe. En outre, les graphes de connaissances permettent de combiner différentes sources de données. Une description détaillée du concept de graphe de connaissances peut être trouvée ici : Les technologies graphes, leurs applications et leurs outils: un tour d’horizon (Partie 2) | Smals Research.
Génération augmentée par récupération (RAG)
Le RAG améliore les LLM en exploitant des informations provenant d’une base de connaissances externe (par exemple, des PDF, des pages web) afin de générer une réponse à la question d’un utilisateur. Typiquement, le RAG récupère des informations à partir de documents non structurés qui sont divisés en petits morceaux de texte (chunks) et indexés dans une base de données vectorielle sous forme d’embeddings. Les morceaux pertinents pour la requête sont récupérés de la base vectorielle par calcul de similarité sémantique (voir Un propre système de questions/réponses basé sur des modèles de langue | Smals Research).
Bien qu’améliorant la qualité des réponses des LLM, les systèmes RAG traditionnels présentent certains problèmes:
- Ils ne parviennent pas à répondre aux requêtes complexes qui nécessitent un raisonnement en plusieurs étapes et ils manquent de « vue d’ensemble » sur l’information en raison de l’absence de contexte structuré. En effet, les systèmes RAG traditionnels fonctionnent en récupérant de courts extraits de texte dans une base de données et en les fournissant à un LLM pour répondre à une question. Les morceaux sont traités isolément et les relations entre eux sont ignorées. Cette technique fonctionne bien pour des requêtes ciblées nécessitant des réponses localisées, mais elle est insuffisante pour des requêtes larges qui nécessitent la compréhension de motifs et de relations de haut niveau dispersés dans les documents – les LLM ont du mal à donner du sens aux données fragmentées.
- Le contexte fourni au prompt contient du bruit. La récupération basée sur la similarité sémantique renvoit souvent des morceaux de texte excessifs et redondants, rendant difficile pour les LLM de capturer les détails pertinents dans le contexte ce qui entraîne une diminution de la précision de la réponse générée. De plus, si la phase de récupération échoue à extraire des chunks pertinents, le LLM recevra des informations incomplètes, ce qui peut entraîner des hallucinations.
Qu’est-ce que le GraphRAG ?
GraphRAG signifie génération augmentée par récupération basée sur les graphes, c’est une configuration RAG qui tire parti de la nature interconnectée des graphes de connaissances.
Les KG sont un choix naturel pour améliorer le RAG pour les raisons suivantes :
- Les structures de graphe, où la connaissance est représentée sous la forme d’entités et de relations, permettent un raisonnement plus approfondi ; un graphe capture mieux les connexions conceptuelles qui guideront le raisonnement.
- Ils fournissent une source de connaissances structurée aidant le LLM à ancrer les réponses dans des faits vérifiables.
En utilisant un graphe pour modéliser les relations entre les chunks d’information, le GraphRAG permet au modèle de mieux comprendre le contexte. Il ne s’agit pas d’un algorithme unique, mais d’un ensemble de motifs d’architecture exploitant les graphes pour améliorer la pertinence, la cohérence et la traçabilité des réponses. Il existe différentes façons d’implémenter le GraphRAG en fonction du problème à résoudre. On peut les classer en trois grandes catégories en fonction de la forme que prendra le graphe :
- GraphRAG basé sur l’indexation : les graphes sont utilisés comme index pour organiser les textes bruts d’un corpus. Les morceaux de texte sont organisés dans une structure graphe où l’exploitation des relations entre ces chunks facilite une récupération de texte efficace et sémantiquement consciente. Ces relations sont définies par la similarité sémantique entre les chunks et/ou les entités partagées. Le graphe sous-jacent est un graphe lexical. Cette architecture est typiquement utilisée pour le RAG sur des documents longs ; le graphe permet alors de préserver la structure du document en suivant l’ordre des chunks (relation « est le morceau suivant de ») ou la hiérarchie du document (relation « est une sous-section de »).
- GraphRAG basé sur les connaissances : les graphes (de connaissances) sont utilisés comme principaux vecteurs de connaissance où les nœuds sont des concepts et les arcs représentent leurs relations sémantiques. Typiquement, le graphe de connaissances représente la connaissance du domaine métier. Selon cette configuration, un texte non structuré peut être transformé en données explicites et structurées dans le graphe de connaissances. Cela permet un raisonnement direct sur le graphe.
- GraphRAG hybride : cette approche combine la récupération basée sur les vecteurs et l’exploration basée sur les graphes pour obtenir de meilleurs résultats.
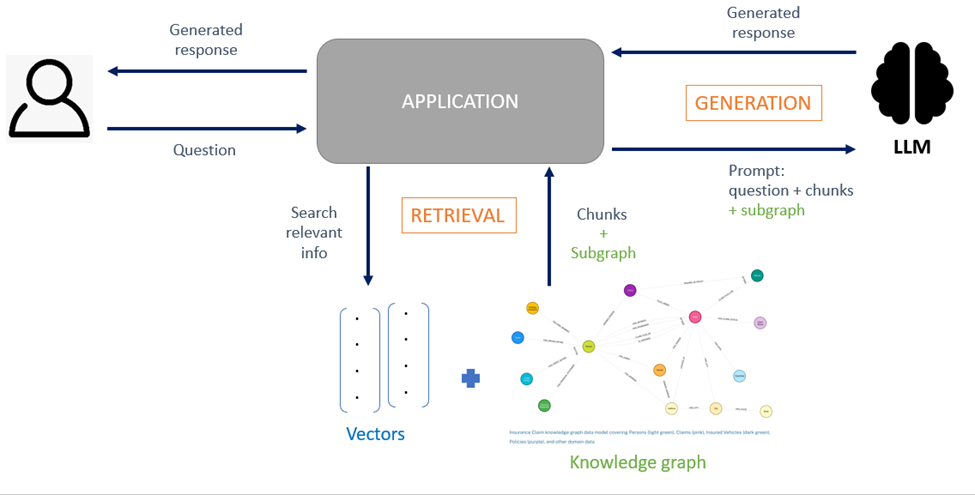
Les avantages du GraphRAG
Meilleure compréhension contextuelle
Les graphes de connaissances ont une meilleure représentation des connaissances ; ils fournissent un contexte riche en relations qui améliore la compréhension du LLM. La récupération à partir d’un graphe révèle des dépendances complexes entre les éléments d’information qui pourraient ne pas être capturées avec le RAG traditionnel.
Réduction des hallucinations
Les informations stockées dans un KG sont structurées et ne contiennent pas de bruit. De plus, les graphes avancés intègrent des ontologies qui fournissent des définitions formelles pour les concepts. Tout cela contribue à ancrer les LLM dans les faits et à réduire les hallucinations.
Explicabilité
Le chemin de raisonnement à travers le KG peut être facilement tracé et visualisé par les utilisateurs. Associé aux explications données par le LLM, il fournit un système RAG plus transparent.
Implémentation GraphRAG en pratique
Construction du graphe
a) Ingestion des données
La plupart des étapes du processus d’ingestion des données sont similaires à celles du RAG traditionnel : collecte, nettoyage et division du corpus en plus petites unités, …
b) Extraction des entités et des relations
Des LLM ou des systèmes basés sur des règles sont utilisés afin d’identifier les entités et les relations à partir du texte.
c) Enregistrement des entités, relations et/ou chunks dans le graphe.
Très souvent, on enrichit le graphe avec des résumés de communautés de nœuds pour un contexte global. Des algorithmes de regroupement tels que Louvain ou Leiden sont alors utilisés pour créer des communautés hiérarchiques au sein du graphe et pour chaque communauté, un LLM résume ensuite les informations de la communauté.
d) Création d’embeddings pour les nœuds, les relations et les résumés communautaires.
Notons que le coût de construction d’un graphe de connaissances à partir de données non structurées peut rapidement grimper dû aux nombreuses requêtes envoyées aux LLM.
Récupération des connaissances
Les méthodes de récupération des connaissances sont nombreuses, seules les plus communes sont décrites dans cette section.
La première étape de l’opération de récupération consiste à trouver les points d’entrée dans le graphe. Soit une recherche par similarité sémantique est effectuée sur la représentation vectorielle d’un chunk ou d’un nœud, soit une requête déclarative est générée dans le langage du graphe (Cypher pour Neo4j) à partir de la requête utilisateur formulée en langage naturel. Les informations retournées par la recherche sont alors envoyées au LLM pour générer la réponse finale.
Il existe deux stratégies pour générer une requête graphe du type Cypher. La première repose sur des modèles de requêtes prédéfinis, complétés au moment de l’exécution par le LLM qui extrait automatiquement les paramètres nécessaires de la requête initiale de l’utilisateur. Cette configuration de base a l’avantage d’être simple et correctement formattée mais manque de flexibilité car le nombre de requêtes qui peuvent être effectuées sur le graphe est limité. La deuxième consiste à faire construire dynamiquement la requête sur le graphe par un LLM. Le LLM génère alors la requête graphe complète en se basant sur la nature de la question de l’utilisateur et le schéma du graphe qui lui aura été fourni. Cette méthode est plus flexible mais moins fiable. Il est donc conseillé d’ajouter quelques exemples au prompt et d’implémenter des mécanismes de vérifications de syntaxe.
Une autre méthode de récupération très répandue consiste à faire une recherche vectorielle sur les chunks, suivie de traversées effectuées dans le graphe pour collecter des informations supplémentaires sur les relations entre les chunks et les entités. Comme mentionné ci-dessus, la manière de récupérer de l’information dépend de l’objectif que l’on veut atteindre.
On peut citer d’autres techniques de récupération telles que :
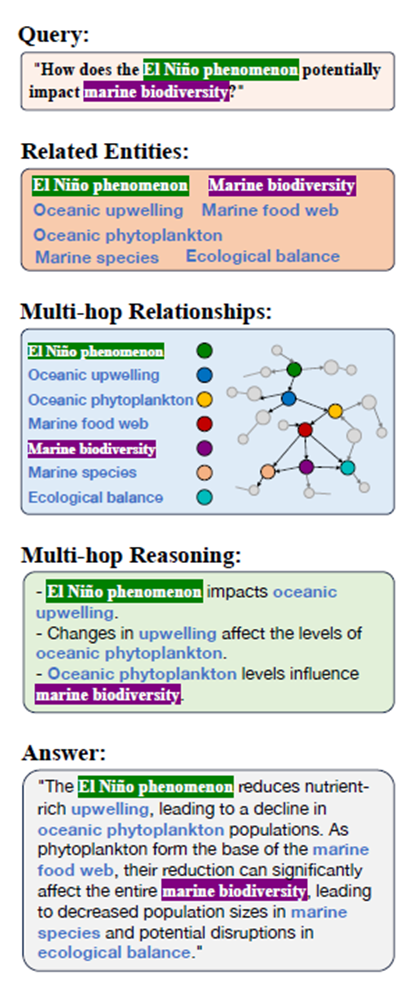
Source: A Survey of Graph Retrieval-Augmented Generation for Customized Large Language Models, Zhang et al.
- La récupération hiérarchique. Le graphe est organisé en une structure hiérarchique où les niveaux les plus élevés contiennent des informations globales pour une compréhension contextuelle large (ex : résumés de communautés) tandis que le niveau le plus bas contient des informations plus spécifiques. Dans le cadre de nos expériences, nous avons appliqué une version simple de cette méthode à un chatbot, (RAPTOR), ce qui a eu pour effet d’augmenter la qualité des réponses.
- La récupération multi-sauts (multi-hop retrieval). Pour le raisonnement, les informations sont récupérées à plusieurs sauts de la requête initiale par l’intermédiaire d’une traversée supplémentaire éventuellement dirigée par une ontologie. Les chemins extraits sont ensuite linéarisés au format texte pour alimenter le LLM (voir Fig. 2).
- La récupération multi-tours (multi-turn retrieval). La réponse est affinée de manière itérative par l’intermédiaire d’une boucle de rétroaction entre le graphe et le LLM où le LLM formule des requêtes supplémentaires si les informations récupérées dans le graphe ne sont pas complètes.
Stratégies d’amélioration de la récupération
La récupération des connaissances s’accompagne souvent d’opérations de traitement avant ou après l’exécution de la requête :
- Décomposition de la requête (query decomposition) : si la requête est complexe, un traitement supplémentaire lui est appliquée avant l’étape de récupération. La requête est décomposée à l’aide d’un LLM en sous-requêtes simples, chacune de ces sous-requêtes étant ensuite traduite en langage graphe. Les résultats retournés par les sous-requêtes sont regroupés pour générer une réponse.
- Extension de la requête (query expansion): la requête initiale est enrichie en ajoutant du contexte supplémentaire. Le graphe de connaissances est alors utilisé pour élargir le champ d’application de la requête en fournissant de nouvelles entités ou relations qui sont ajoutées à la requête.
- Élagage (pruning) et réordonnancement des résultats de la requête.
Défis d’implémentation
Bien que le GraphRAG apporte de nombreuses améliorations au RAG traditionnel, il présente certains défis :
- Trouver le bon équilibre pour un graphe de qualité: un graphe trop dense nuit à la performance, cependant un graphe trop pauvre nuit à la précision.
- L’alignement graphe/texte : Les LLM courants ne sont pas conçus pour traiter nativement des structures graphe.
- L’extensibilité : les graphes massifs nécessitent des algorithmes efficaces pour l’identification de sous-graphes pertinents.
- La désambiguïsation : les entités doivent être correctement résolues pour éviter les erreurs de contexte.
Conclusion
GraphRAG est un concept à suivre de près. Suivant l’application, il peut considérablement améliorer les performances des modèles de langage par rapport aux systèmes RAG traditionnels. Grâce à la représentation structurée de l’information dans les graphes de connaissance, le GraphRAG augmente les capacités de raisonnement des LLM et est capable de justifier ses réponses ce qui permet de construire un système plus transparent tout en réduisant de manière significative les hallucinations. Ce changement est particulièrement critique pour des secteurs comme la santé ou le secteur publique où la précision et l’interprétabilité sont nécessaires.
Références
https://neo4j.com/blog/genai/graphrag-manifesto
https://microsoft.github.io/graphrag/
Graph Retrieval-Augmented Generation: A Survey, Peng et al.
A Survey of Graph Retrieval-Augmented Generation for Customized Large Language Models, Zhang et al.
_________________________
Ce post est une contribution individuelle de Katy Fokou, spécialisée en intelligence artificielle chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.
Leave a Reply