Cette contribution se situe dans une série d’articles sur les graphes de connaissances (les « knowledge graphs » en anglais). Nous vous présentons le Smals KG Checklist, un outil qui vous aide à déterminer si un graphe de connaissances serait utile, voire indispensable, pour résoudre un problème dans votre organisation. Le Smals KG Checklist a été présenté au sein du SEMANTiCS 2021, un congrès scientifique et industriel autour des graphes de connaissances.
La différence entre les graphes et les graphes de connaissances
Nous avons déjà traité les graphes de connaissances et les (bases de données) graphes. Mais quelle est la différence entre les deux? Dans les grandes lignes, les bases de données graphes nous permettent de stocker des données représentées en graphe et les graphes de connaissances sont un type de graphe spécifique qu’on stocke dans des bases de données graphes. Autrement dit, tous les graphes de connaissances sont des graphes mais l’inverse n’est pas vrai.
Quelles sont donc les caractéristiques qui séparent les graphes de connaissances des autres graphes? C’est une question qu’on se pose souvent dans l’industrie et la recherche. En 2020, Hogan et al. ont publié un rapport plutôt académique qui traite le sujet des graphes de connaissances. Ils présentent plusieurs définitions de ce concept, ce qui ajoute à la confusion. Par contre, toutes ces définitions nous permettent de synthétiser les caractéristiques d’un graphe de connaissances. C’est un graphe qui représente des entités (sous forme de nœuds) et leurs relations (sous forme de d’arêtes), et qui adhère à trois conditions :
- Le graphe intègre des informations de différentes sources hétérogènes : bases de données, documents, connaissances reprises dans les têtes des experts, …
- Un schéma qui décrit les types et relations utilisés dans le graphe de connaissances. Ce schéma, également nommé ontologie, fait partie du graphe de connaissances.
- Le graphe est utilisé pour déduire des informations implicites à travers les informations explicites. C’est-à-dire, d’utiliser le graphe de connaissances pour découvrir des nouvelles relations, types, etc. en utilisant des algorithmes ou des applications.
La première condition est évidente. La traduction d’une base de données relationnelle vers une base de données graphe peut être utile pour optimaliser les requêtes, mais le résultat n’est pas un graphe de connaissances ; le résultat non seulement ne combine pas d’autres informations, mais il manque aussi au résultat une description détaillée des concepts et relations et enfin, le résultat n’est utilisé que pour optimaliser un processus existant. Ce sont les deux autres conditions qui sont plus complexes et nuancées.
Le Schéma (ou ontologie) d’un graphe de connaissances
La définition d’un schéma (ontologie) d’un graphe de connaissances est : « une spécification formelle et explicite d’une conceptualisation partagée ». Cette définition semble compliquée, mais il suffit de comprendre chaque partie de cette définition.
Nous prenons par exemple l’ONSS et la Banque-Carrefour des Entreprises (BCE). L’ONSS et la BCE ont des informations sur des entreprises, mais de points de vue différents. Si l’ONSS et la BCE décident de partager des informations sur des entreprises, ils auront besoin d’une ontologie pour éviter des malentendus. La conceptualisation partagée inclut donc le concept « entreprise » et ses relations, définitions, règles, etc. Les représentants des deux parties se mettent d’accord sur cette conceptualisation partagée en discutant et en réutilisant des informations existantes (législations, glossaires, etc.). Cette conceptualisation partagée reste « dans la tête » des représentants, donc il faut mettre ces accords quelque part : on parle alors de la spécification. La spécification contient les descriptions et définitions de la conceptualisation. Mais la spécification doit être explicite, c’est-à-dire enregistrée quelque part (p. ex., un fichier) et cette spécification doit être formelle (logique ou mathématique) pour que des logiciels puissent l’utiliser.
Il existe des normes pour créer ces schémas ; RDFS et OWL sont deux exemples. RDFS nous permet de créer des hiérarchies de concepts et de relations. OWL est beaucoup plus expressif et nous permet de créer des règles pour valider un graphe de connaissances. Les use cases d’une organisation nous informent quelle langue est préférable. Ces langues nous permettent de décrire que :
- Chaque entreprise est un agent ;
- Chaque personne est un agent ;
- Une entité ne peut pas être à la fois une personne et une entreprise (possible avec OWL) ;
- Si une entité a un numéro BCE, cette entité est une entreprise ;
- …
En ajoutant des descriptions en langage naturel, ce schéma rend les données sémantiques pour les logiciels et les utilisateurs. En donnant la requête « donne-moi une liste des agents », un logiciel est capable d’interpréter le schéma et d’inclure les personnes et les entreprises.
Les bases de données graphes comme Neo4j ont souvent une notion de types de nœuds, mais ne soutiennent pas les relations entre ces types, par exemple. La réalisation d’un knowledge graph non seulement nécessite la construction du schéma, mais aussi l’utilisation de ce schéma en utilisant :
- une extension d’une base de données graphe ou d’une application sur cette base de données graphe capable d’interpréter un schéma. Un exemple est le RDF & Semantics Plugin de Neo4j ; ou
- des bases de données graphes conçues pour les graphes de connaissances comme Stardog et Apache Jena.
Le schéma est donc un graphe qu’on ajoute au graphe de données et qui est interprété d’une manière spécifique.
Déduire des informations implicites
La troisième condition est que le graphe de connaissances soit utilisé pour déduire des informations implicites ou « cachées » dans le graphe, en utilisant :
- L’intelligence artificielle symbolique (exploitant le schéma) ;
- L’intelligence artificielle statistique (machine ou deep learning) ;
- Des applications qui « comprennent » les graphes grâce au schéma.
Nous avons déjà évoqué l’IA symbolique dans la section précédente. En effet, le langage de schéma permet aux logiciels de déduire des informations. Si l’entité représentant Christophe est du type Personne, cet entité est aussi du type Agent. Ce genre d’IA utilise des logiques formelles pour arriver à ces déductions. L’usage de l’IA symbolique nécessite un schéma.
L’IA statistique, appliquée au graphes, nous permet de prédire des liens entre des entités ou même de prédire les catégories d’une nouvelle entité. L’usage d’un schéma nous permet de fournir des graphes plus riches, en déduisant un maximum d’informations, à ces algorithmes.
Et puis nous avons les applications « intelligentes » qui « comprennent » les graphes de connaissances. Ces applications exploitent le schéma et/ou le langage de schéma pour faciliter les tâches. Pour la recherche facettée, que nous connaissons tous des ventes en ligne, les types et les valeurs des relations sont interprétées pour créer des critères de recherche. Des outils comme Ontodia, traités dans un product review, nous permettent d’explorer et d’analyser les contenus d’un graphe de connaissances d’une manière visuelle. Ontodia non seulement interprète le schéma pour guider les fouilles, mais l’outil interprète aussi les contenus du graphe pour choisir les visualisations. Ces outils permettent donc aux usagers de découvrir eux-mêmes des nouvelles informations dans le graphe de connaissances.
Le Smals KG Checklist
Reconnaitre la différence entre les graphes et les graphes de connaissances n’est pas évident, non seulement pour des informaticiens non-spécialistes mais aussi, et surtout, pour les organisations. Au sein de Smals et ses membres, par exemple, l’usage et les possibilités des bases de données graphes sont reconnus ; pour faciliter, entre autres, les analyses de réseau. Mais quand est-ce qu’un projet nécessite un graphe de connaissances ? Pour répondre à cette question, Smals Research a développé le Smals KG Checklist. A partir d’une problématique concrète, le but du Smals KG Checklist est de déterminer si une solution à cette problématique requiert les trois conditions remplies et le développement d’un graphe de connaissances est une piste valable.
La checklist, disponible en PDF sous licence Creative Commons, se compose de deux parties. Dans la première partie, nous allons d’abord : 1) décrire la problématique, 2) identifier les parties prenantes, et 3) identifier les concepts clefs (partagés par les parties prenantes). Les réponses à ces trois questions nous donnent un cadre pour les discussions suivantes.
La quatrième question se compose de trois blocs, une pour chaque condition, et chaque bloc à sa propre couleur. Ces trois blocs requièrent l’usage de la deuxième partie de la checklist et nous y retrouvons les mêmes couleurs.
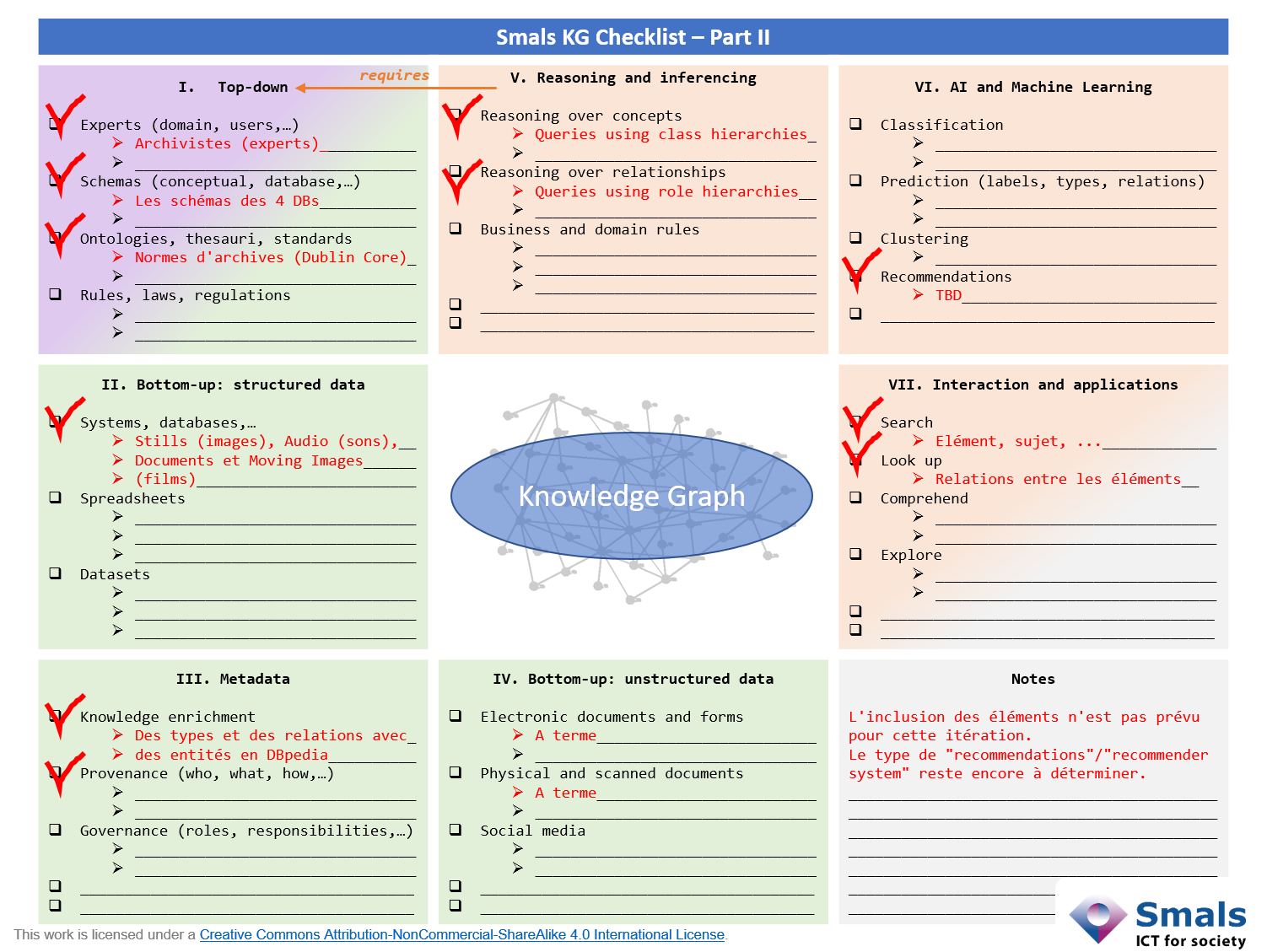
Le violet correspond au schéma du graphe de connaissances. Nous retrouvons, dans la Section I, la connaissance des experts, la réutilisation des ontologies, la formalisation des législations, … et même la réutilisation des schémas existants. Les schémas des bases de données (relationnelles) contiennent souvent une représentation de nos concepts et relations que nous pouvons « réutiliser ». Si une des cases de la Section I est remplie (ou, voir plus tard, une des cases de la Section V), cette condition est remplie.
Le vert correspond à l’intégration des informations et données. Dès que plusieurs cases dans ces sections sont cochées, cette condition est remplie. Mais d’où viennent ces informations et ces données ?
- Section II se focalise sur l’intégration des données structurées (bases de données, fichiers Excel, …)
- Section IV se focalise sur l’intégration des données non-structurées (documents, Tweets, …)
- Section III, au milieu des sections II et IV, se focalise sur les métadonnées (d’où viennent les informations, leurs dates de créations, …)
Remarquez que la Section I a deux couleurs. La connaissance des experts peut contribuer au schéma et au graphe, par exemple. Dès que nous intégrons des bases de données existantes, nous allons (souvent) utiliser les schémas de ces bases de données pour le schéma du graphe de connaissances (surtout quand nous devons créer le schéma nous-même).
L’orange correspond à la découverte des informations implicites. Les Section V, VI, et VII correspondent respectivement avec l’IA symbolique, l’IA statistique, et les applications. Remarquez que la Section V nécessite un schéma et que la section VII est à moitié remplie en orange. Nous pouvons argumenter que la consultation des entités sous forme de page Web (comme, par exemple la page de Bruxelles de la graphe de connaissances DBpedia) est utile pour les utilisateurs, mais pas vraiment une application intelligente. Nous essayons de capter les applications intelligentes : c’est à dire celles qui interprètent le graphe de connaissances. Si une des cases dans les Section V et VI est remplie et/ou des applications intelligentes sont identifiées, la condition est remplie.

Une fois que les trois blocs de la première partie sont complétés, nous sommes capables de répondre à la cinquième question : est-ce que les trois conditions sont remplies ? Si oui, il est probable qu’un graphe de connaissances soit une solution (élégante) à cette problématique. La sixième question, en gris, nous permet d’enregistrer des pistes pour élargir le graphe de connaissances.
Une démonstration
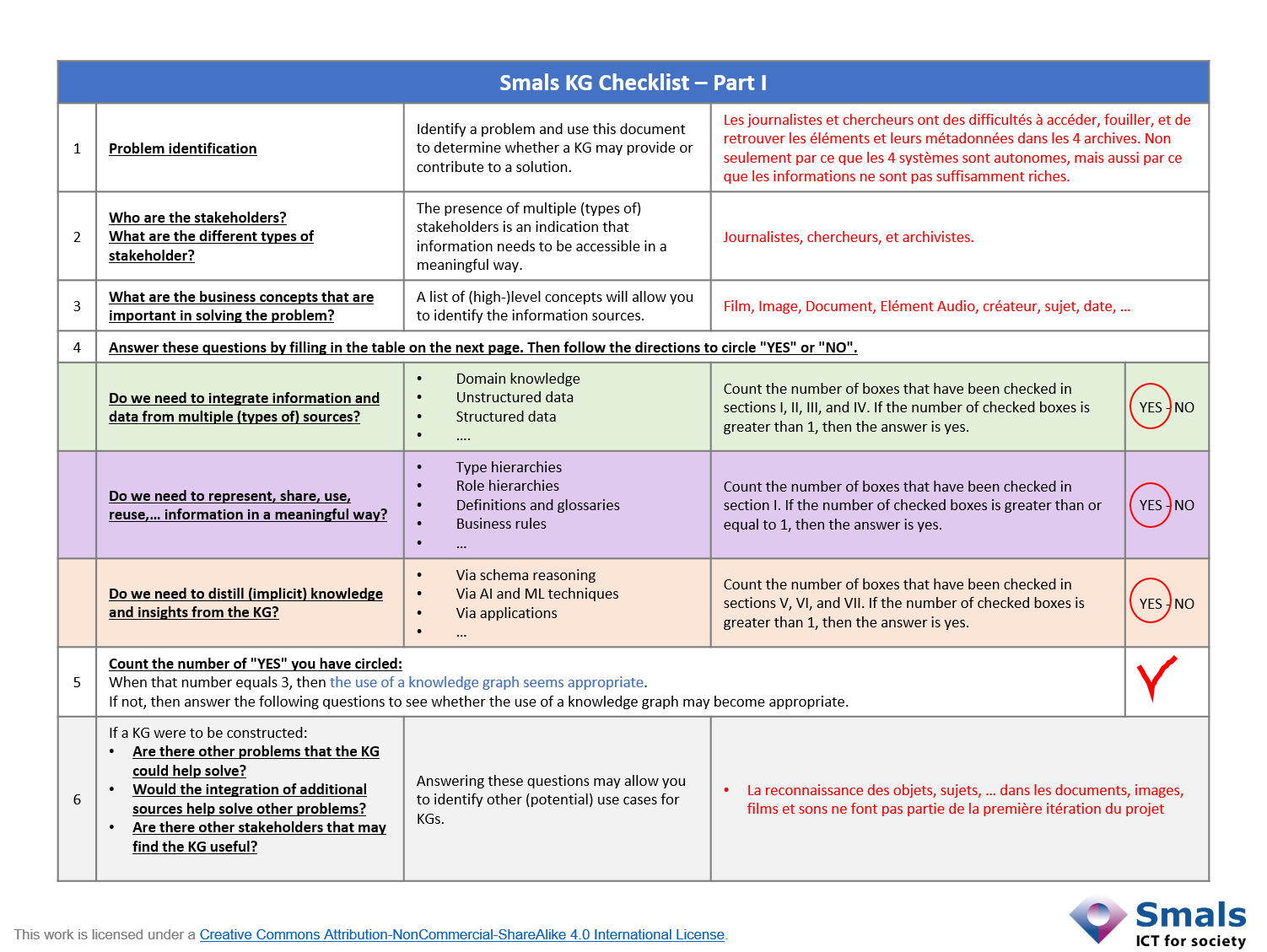
Nous illustrons le Smals KG Checklist avec la problématique de RTÉ, la chaine nationale de l’Irlande.
Le RTÉ gère quatre systèmes d’archives : un pour des photos, un pour des films, un pour des documents, et un pour des sons. Chaque système était autonome ; il était conçu avec d’autres procédures pour gérer les métadonnées et pour permettre de retrouver les éléments. Au fil du temps, chaque équipe a même développé ses propres coutumes.
Si un journaliste ou un chercheur devaient faire des recherches sur un sujet, par exemple un politicien irlandais, ces personnes devaient non seulement consulter les 4 systèmes, mais aussi être au courant de comment les informations étaient encodées dans chaque système. Les informations disponibles n’étaient pas riches non plus ; une photo pouvait avoir comme sujet « Dublin », mais le système ne contenait pas l’information « Dublin est la capitale de l’Irlande ».
Le RTÉ, en partenariat avec une université irlandaise, avait lancé un projet de graphe de connaissances. L’auteur de cet article était impliqué dans ce projet. Le but du projet était de développer un graphe de connaissances (proof-of-concept) pour faciliter la découverte et l’analyse des données contenues dans ces archives et de promouvoir les métadonnées à des entités. Par exemple, le sujet d’une photo qui n’était auparavant qu’une simple valeur littérale comme « Bruxelles » est transformée en entité d’une ville qui porte le nom de « Bruxelles » en français. En conséquence, il peut être ajouté à cette entité d’autres relations comme le nom en néerlandais et « est la capitale de » avec une entité qui représente la Belgique. Le résultat est une conceptualisation plus détaillée, ce qui nous permet de formuler des requêtes comme : « donne-moi une liste de tous les documents de la capitale de la Belgique» sans connaître le nom de cette ville.
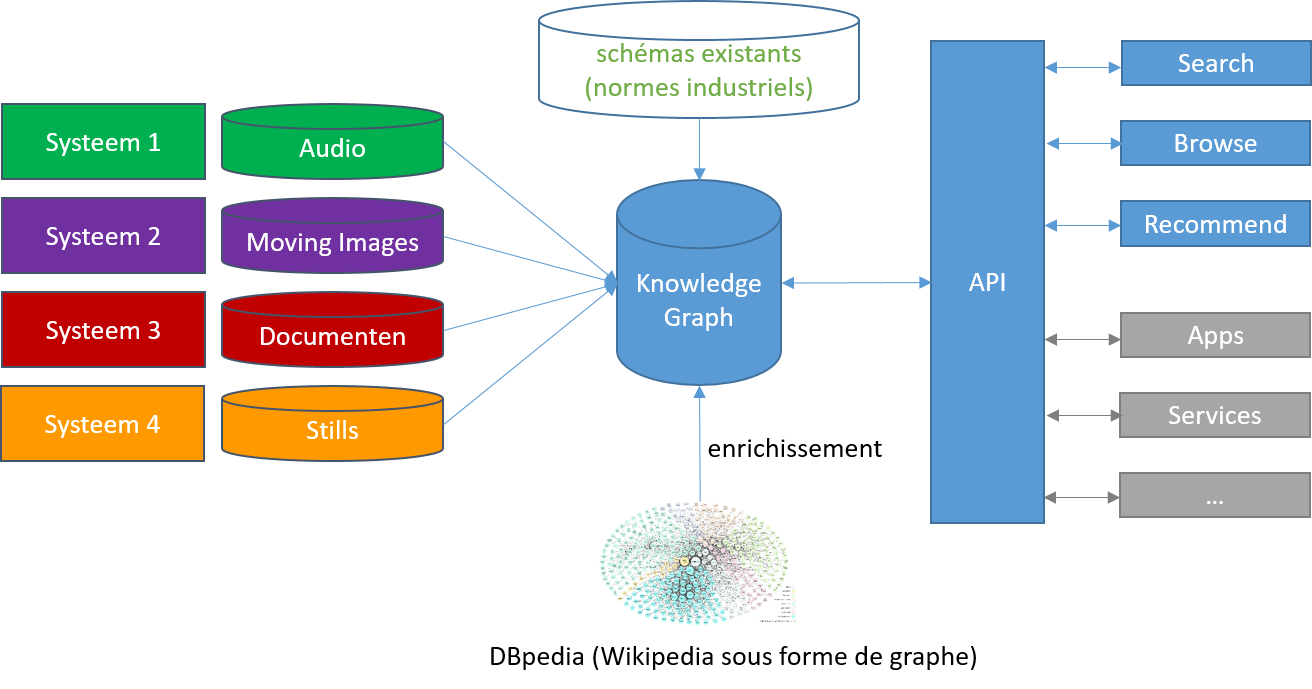
Ce projet, lancé en 2013, rempli les trois conditions d’un knowledge graph. Mais pour illustrer le Smals KG Checklist, nous avons fait, ci-dessous, l’exercice pour déterminer si un graphe de connaissances était nécessaire. Il s’avère qu’une solution pour RTÉ nécessitait : un schéma pour réaliser l’analyse et la découverte des données; RTÉ était capable de réutiliser des normes existantes; l’intégration de quatre bases de données et des informations externes (enrichissement) ; et le développement des outils qui exploitaient le graphe et le schéma pour soutenir les activités des journalistes et des chercheurs.
En conclusion
Le Smals KG Checklist est conçu pour être utilisé dans un contexte collaboratif, par exemple un workshop. Il est nécessaire qu’il y ait au moins une personne (p. ex., le modérateur) qui maitrise le sujet des graphes de connaissances et que cette personne remplisse le Smals KG Checklist pendant les discussions.
Une fois complété (voir affiné au fil du temps) et les trois conditions remplies, le Smals KG Checklist contient une description d’un projet de graphe de connaissances à haut niveau (avec le scope, les attentes, les applications, …). Cette checklist devient donc un document précieux pour les décisions GO/NO-GO, par exemple dans les phases de début des méthodologies Prince2.
Cet article de blog est une contribution individuelle de Christophe Debruyne, spécialisé en knowledge graph chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.