Heel wat systemen in de publieke sector bewaren – soms erg gevoelige – persoonsgegevens. Het betreft onder meer sociale, fiscale en medische gegevens. We dienen te vermijden dat iemand – van buitenuit of binnenaf – die zich onrechtmatig toegang tot die systemen verschaft die gegevens kan koppelen aan natuurlijke personen. Een waardevolle maatregel daarbij is om de gegevens niet langer onder rijksregisternummers maar onder pseudoniemen te bewaren. Die pseudoniemen zijn unieke codes die enkel met een sleutel terug om te zetten zijn naar het oorspronkelijke rijksregisternummer.
Om de veiligheid en het vertrouwen te maximaliseren is deze sleutel best enkel gekend door een partij die onafhankelijk is van het systeem dat de gepseudonimiseerde persoonsgegevens bewaart. Die partij noemen we de pseudonimiseringsdienst. Een dergelijke aanpak laat meteen ook toe dat heel wat systemen van deze dienst gebruik kunnen maken. We krijgen dus een generieke pseudonimiseringsdienst.
Dit artikel is een introductie tot een dergelijke pseudonimiseringsdienst die uitgedacht werd door Smals Research en een bijzonder hoog niveau van veiligheid verschaft. De dienst gaat in december 2023 live als nieuwe eHealth dienst.
Disclaimer: Omdat rijksregisternummers als term beter gekend zijn dan de ruimere categorie van INSZ-nummers, spreken we in dit artikel uitsluitend over rijksregisternummers, al vormt het type identifier geen enkele beperking.
Rollen en operaties
Zonder pseudonimiseringsdienst zijn er twee rollen: de owner die persoonsgegevens bewaart en de clients die requests naar de owner sturen. We geven drie scenario’s ter illustratie:
- Scenario 1: Een huisarts (client) vraagt aan de voorschriften service (owner) om een elektronisch voorschrift te registreren.
- Scenario 2: Een apotheker (client) vraagt voor een specifieke burger een voorschrift op aan de voorschriften service (owner).
- Scenario 3: Een arts (client) vraagt aan de voorschriften service (owner) om de elektronische voorschriften te bekijken die ze de dag ervoor uitgegeven heeft.
De derde rol is de pseudonimiseringsdienst die instaat voor de vertaling van het rijksregisternummer van de patiënt naar het overeenkomstige pseudoniem (pseudonymize operatie), of omgekeerd, van het pseudoniem naar het rijksregisternummer (identify operatie). Ook het rijksregisternummer of RIZIV-nummer van de arts kan op een gelijkaardige manier gepseudonimiseerd worden.
Systemen (owners) communiceren ook onderling met elkaar. Een dienst op het eHealth platform zou bijvoorbeeld kunnen vragen aan de TherLink service of een patient een therapeutische relatie heeft met een bepaalde arts. Indien TherLink ook met pseudoniemen werkt, zal een pseudoniem van de ene dienst/owner omgezet moeten worden naar het pseudoniem van de andere dienst/owner (convert operatie). Om het identificatierisico zo klein mogelijk te houden is het immers aangewezen om pseudoniemen niet over meerdere diensten te hergebruiken.
De drie operaties die de pseudonimiseringsdienst moet ondersteunen zijn dus pseudonymize, identify en convert. Dit artikel focust op de pseudonymize operatie.
Interacties
Indien gebruik gemaakt wordt van een pseudonimiseringsdienst moet bepaald worden op welke wijze ermee gecommuniceerd wordt. Op hoog niveau is er de keuze tussen de relay modus en de reply modus, die geïllustreerd worden in onderstaande figuur.
- De relay modus is de meest courante. In deze modus fungeert de pseudonimiseringsdienst als doorgeefluik: het ontvangt rijksregisternummers, samen met andere gegevens, van de ene partij, doet er operaties op (bijvoorbeeld pseudonymize) en geeft het resultaat door aan de ontvangende partij. De dienst TTP eHealth is een pseudonimiseringsdienst in deze modus. Healthdata.be – onderdeel van Sciensano – maakt gebruik van deze dienst. Ook het geavanceerde pseudonimiseringssysteem bedacht door de Nederlande professor Verheul hanteert deze modus.
- In de reply modus ontvangt de pseudonimiseringsdienst een request en stuurt het antwoord naar dezelfde partij terug. Deze partij kan bijvoorbeeld vragen om een pseudoniem om te zetten naar een rijksregisternummer (identify). Onder meer de eHealth dienst WS SEALS hanteert deze modus.
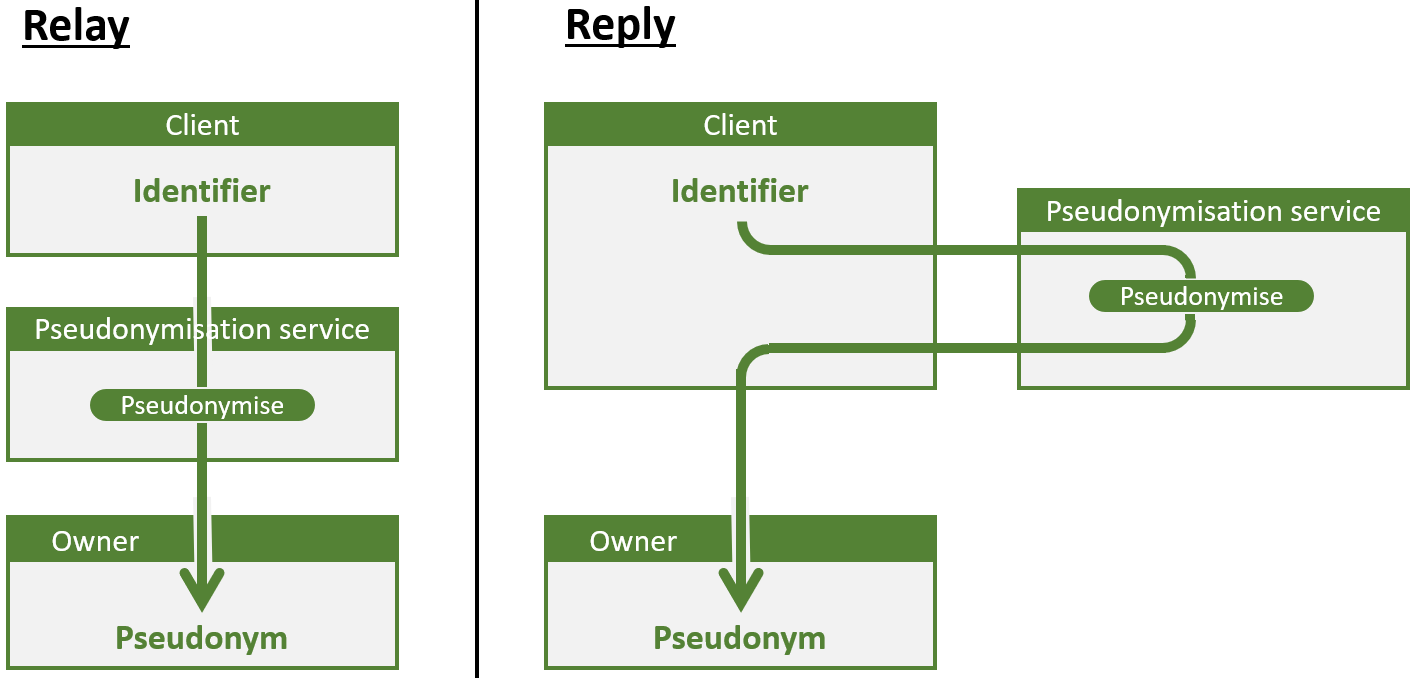
Reply modus en relay modus
Beide aanpakken hebben hun eigen voor- en nadelen. Niettemin komt de reply modus beter tegemoet aan de noden van onze klanten bij de bescherming van operationele medische persoonsgegevens. De reply modus heeft immers een minder intrusieve impact op bestaande interacties; client en owner (of owner en owner bij een convert operatie) communiceren nog steeds rechtstreeks met elkaar en hoeven niet te vertrouwen op een intermediaire partij om de juiste data door te sturen naar de juiste partij over een veilig communicatiekanaal. De low-level interacties liggen dus dichter bij de business interacties.
De basisflow voor scenario 1 van daarnet wordt in de figuur hieronder weergegeven. De basisflows voor de andere twee scenario’s zijn analoog. In tegenstelling tot de dikke pijl bevat de dunne pijl geen rijksregisternummers of pseudoniemen.
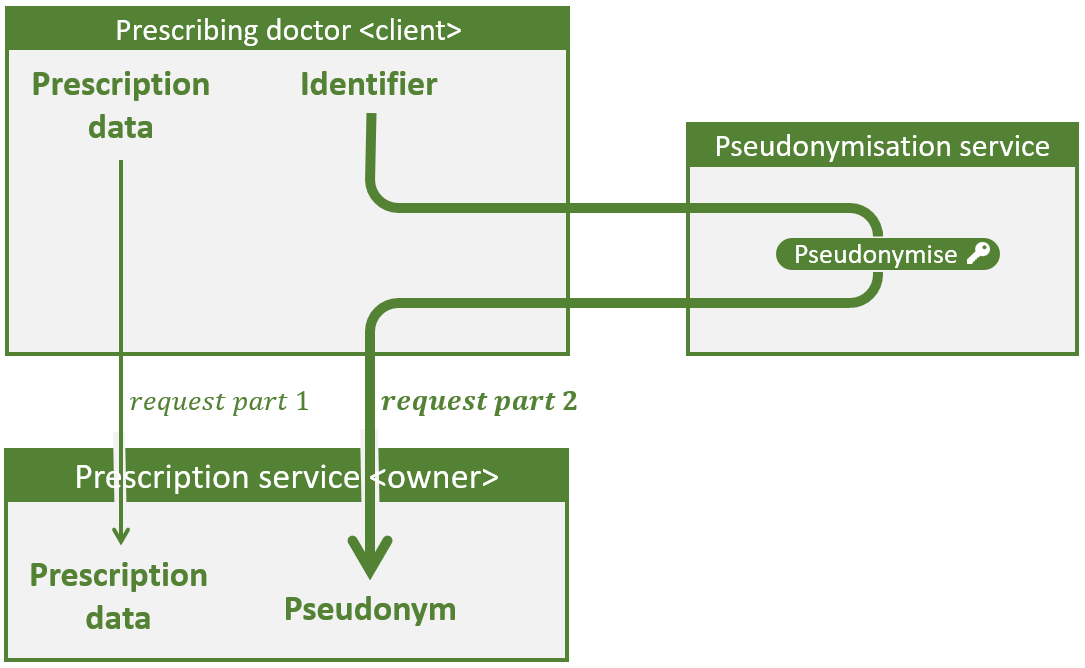
Basisflow voor scenario 1: Een arts (client) vraagt aan de voorschriften-backend (owner) om een elektronisch voorschrift te registreren.
Hoge veiligheidsgaranties
Een privacy risico is dat één van de betrokken partijen, of een hacker, op de één of andere manier ongewenst persoonsgegevens kunnen afleiden en kunnen koppelen aan een geïdentificeerde persoon. Dit risico vermindert aanzienlijk indien elke partij slechts het strikt noodzakelijke te weten komt. In concreto:
- De owner komt enkel de pseudoniemen te weten.
- De client komt enkel de rijksregisternummers te weten.
- De pseudonimiseringsdient komt geen van beiden te weten.
Door het toepassen van enkel de basisflow, die geïllustreerd werd in de vorige figuur, is enkel aan het eerste puntje voldaan. In wat volgt bespreken we een aantal veiligheidsverhogende maatregelen. Indien deze toegepast worden op de basisflow van scenario 1, krijgen we onderstaande figuur. Een sleutel naast een operatie betekent dat een geheime of private sleutel vereist is, een dobbelsteen dat de operatie probabilistisch is; het resultaat is telkens anders, ook bij dezelfde input.
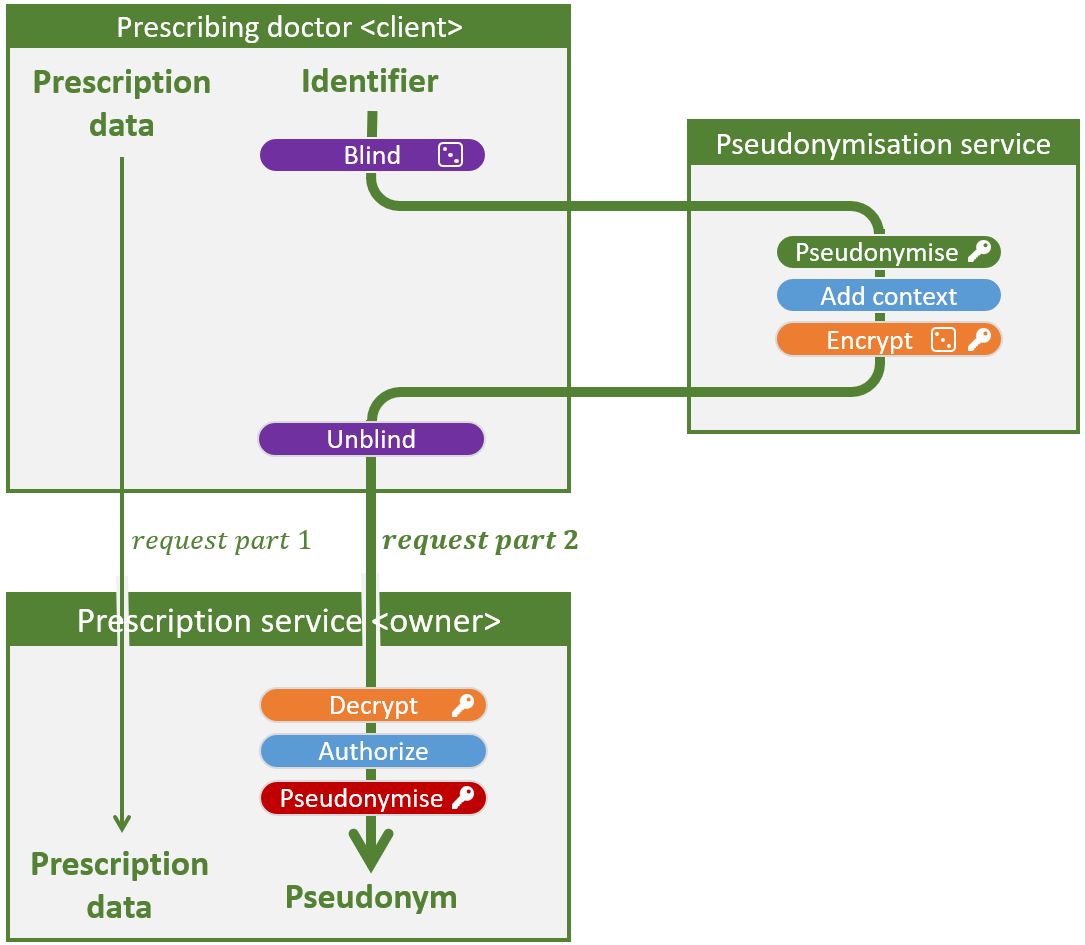
High-security flow voor scenario 1: Een arts (client) vraagt aan de voorschriften-backend (owner) om een elektronisch voorschrift te registreren.
Blinde pseudonimiseringsdienst
Een eerste maatregel is de blinde pseudonimiseringsdienst, die gerealiseerd wordt door de twee paarse operaties (blind en unblind). Het zorgt ervoor dat de pseudonimiseringsdienst niet langer de binnenkomende en uitgaande pseudoniemen en identifiers kan zien, waardoor een nieuwsgierige pseudonimiseringsdienst veel minder informatie kan verzamelen en dus minder vertrouwd hoeft te worden.
Confidentiële pseudoniemen
In een flow met enkel blind en unblind krijgt de arts (client) na de unblind operatie het pseudoniem zelf te zien. De arts – of een hacker – kan dit dus koppelen aan een rijksregisternummer. Dit veiligheidsrisico wordt in de high-security flow gemitigeerd dankzij confidentiële pseudoniemen (oranje), waarbij een extra encryptielaag garandeert dat de client nooit het pseudoniem te weten komt, gezien het de decryptiesleutel niet kent.
Door het toepassen van blinde pseudoniemen en confidentiële pseudoniemen op onze initiële flow realiseren we de volgende eigenschappen:
- De client is verziend; ze ziet enkel globale identifers (rijksregisternummers).
- De owner is bijziend; het ziet enkel de lokale identifiers (pseudoniemen).
- De pseudonimiseringsdienst is blind; het ziet noch identifiers, nog pseudoniemen.
We voeren nog twee extra maatregelen in om de veiligheid verder te verhogen: expliciete authorizatie en de optionele dubbele pseudonimisatie.
Expliciete autorizatie
Uiteraard mag niet iedereen zomaar gebruik kunnen maken van de pseudonimiseringsdienst. Wie welke requests met welk doel naar die dienst mag sturen is dan ook strikt geregeld. Bovendien veranderen die regels constant; er komen nieuwe zorgverstrekkers (clients) en diensten (owners) bij, en oude verdwijnen. Bovendien zijn de clients van de vele tienduizenden zorgverstrekkers in dit land niet steeds even goed beveiligd; gebruik van de pseudonimiseringsdienst door gecompromitteerde clients moet dan ook onder bepaalde omstandigheden ontzegd kunnen worden.
In die optiek is het zinvol om de geldigheidsduur van pseudoniemvercijferingen (die de client in de vorige figuur verkrijgt na de unblind operatie) te beperken. Meer algemeen kan de context waarin een pseudoniemvercijfering gebruikt mag worden beperkt worden. Op die manier wordt onrechtmatig hergebruik van pseudoniemvercijferingen vermeden.
Dit is exact wat expliciete autorizatie verhindert. In bovenstaande figuur wordt dit gerealiseerd met behulp van de blauwe operaties; de pseudonimiseringsdienst hecht autorizatieregels (vb. expiration time) aan het pseudoniem voor het vercijferd wordt. Bij ontvangst verifieert de owner a.d.h.v. contextinformatie (vb. current time) of aan deze regels voldaan is. De bruikbaarheid van een pseudoniemvercijfering kan bijvoorbeeld beperkt worden tot 5 minuten. Geavanceerdere regels zijn uiteraard steeds mogelijk.
Dubbele pseudonimisatie
Ondanks de eerder besproken veiligheidsmaatregelen is het nog steeds mogelijk dat de pseudonimiseringsdienst op zijn eentje de volgende aanval uitvoert:
- Het maakt een lijst van alle strings (opeenvolging van karakters) die de structuur van een rijksregisternummer hebben. Dat zijn er een paar tiental miljoen en kan dus snel gerealizeerd worden.
- Voor elk van die strings doet het een pseudonymize operatie
De pseudonimiseringsdienst heeft nu een tabel bestaande uit een paar tiental miljoen koppels. Ongeveer 12 miljoen van die koppels bevatten een rijksregisternummer dat effectief toegekend is aan een in leven zijnde burger.
Dat die dienst de koppeling kent tussen rijksregisternummer en pseudoniem is een risico; indien een hacker dit kan koppelen aan gepseudonimiseerde gegevens die lekten uit de owner, kan hij eenvoudig reïdentificeren.
Dit risico kan gemitigeerd worden met behulp van dubbele pseudonimisatie (rood). Om een rijksregisternummer om te zetten naar het finale pseudoniem, of, omgekeerd, om een pseudoniem terug om te zetten naar een rijksregisternummer, zijn dan twee sleutels vereist: De ene is enkel gekend door de pseudonimiseringsdienst, de andere enkel door de owner. De keerzijde is dat de owner nu een sleutel moet beveiligen en meer cryptografische operaties moet uitvoeren. Gezien dit niet steeds evident is en gezien het beperkte risico, is deze stap optioneel.
Conclusies
De voorgestelde pseudonimiseringsdienst biedt extreem hoge veiligheidsgaranties, terwijl de complexiteit ervan beheersbaar blijft. In het bijzonder aan de kant van de clients (vb. arts) blijft die zeer beperkt, wat een integratie van de oplossing in de bestaande client software, die door vele tienduizenden zorgverstrekkers in ons land gebruikt wordt, vergemakkelijkt.
De client hoeft inderdaad geen long-term keys te beheren en voert telkens dezelfde operaties uit: een blind en unblind met tussenin een call naar de pseudonimiseringsdienst. De complexiteit aan de kant van de zorgverstrekkers blijft dus beperkt.
Bovendien worden bestaande interacties gerespecteerd, waardoor de re-engineering kost bij bestaande processen beperkt blijft.
De oplossing vermijdt heridentificatie van persoonsgegevens op basis van rijksregisternummers. Bemerk dat heridentificatie ook mogelijk kan zijn op basis van de data zelf, ook al zijn die enkel gekend onder een pseudoniem. In dat geval kunnen bijkomende veiligheidsmaatregelen, zoals encryptie, zich opdringen.
Een initieel voorstel door Smals Research tot generieke pseudonimiseringsdienst werd in nauwe samenwerking met andere diensten binnen Smals verder verfijnd en uitgebreid en is daarmee afgestemd op de business noden. Smals Research ontwikkelde zowel het theoretische concept als de Proof of Concept (PoC) in Java; die laatste werd door eHealth gebruikt als inspiratie voor het bouwen van een eHealth service die in de in december 2023 live gaat.
Ten slotte geven we mee dat Smals Research ook werkt aan een ander type pseudonimisatie, gericht op een andere set van use cases; structuurbehoudende pseudonimisatie heeft het voordeel dat pseudoniemen dezelfde structuur hebben als de identifiers, maar kan helaas niet dezelfde hoge security eigenschappen bieden.
Aarzel niet ons te contacteren bij interesse in deze of één van onze andere oplossingen voor het pseudonimiseren (en kruisen) van van persoonsgegevens.
Dit is een ingezonden bijdrage van Kristof Verslype, cryptograaf bij Smals Research. Het werd geschreven in eigen naam en neemt geen standpunt in namens Smals.
Bron featured image: Youngsang Hwang
Leave a Reply