Het zijn twee korte verhalen die een hele andere kijk geven op hoe technologie de toekomst kan veranderen. De eerste is er op gericht om mensen van een nieuwe techniek te helpen en om nieuwe ideeën te ontwikkelen. De tweede, die wordt gekenmerkt door meer inzicht in wat de toekomstige mogelijkheden zullen zijn en ook wat de nadelen en valkuilen zijn.
Bovenstaand paragraafje werd geschreven door een GPT-2 taalmodel dat in het Nederlands werd getraind door de Gentse startup ML6. Volgens hun taalmodel is dit een plausibele aanvulling op de titel van dit stuk. En het mag gezegd: qua stijl, woordkeuze en coherentie tussen opeenvolgende zinnen is dit zeker niet slecht. Of het ook inhoudelijk consistent en betekenisvol is, is nog iets anders: de aandachtige lezer besluipt toch nog een gevoel van “woordenbrij”, al is het maar omdat een echt correcte tekst zou verwijzen naar de verhalen als “Het eerste” en “Het tweede”.
Dit geeft wel een idee van waar we vandaag staan qua Natural Language Generation (NLG) in het Nederlands. De agile manier waarop ML6 dit heeft uitgewerkt is trouwens een uitstekende illustratie van wat we in een eerdere blogpost al concludeerden: het tweaken van bestaande NLP systemen met je eigen datasets en voor je eigen doeleinden is het afgelopen jaar veel gemakkelijker geworden – al blijft beschikbaarheid van voldoende grote datasets wel een voorwaarde voor degelijke resultaten, en dat is moeilijker voor minder courante talen.
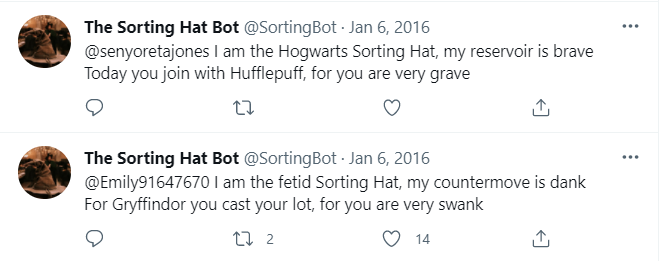
De geschiedenis van tekstgeneratoren gaat een heel eind terug. De Turing Test vereist al dat een computer een realistisch klinkend antwoord op een gestelde vraag moet kunnen samenstellen. De eerste chatbots waren, ondanks hun eenvoud, opvallend goed in staat om een conversatie te simuleren. Recenter zagen verschillende generatoren voor langere teksten gaande van academische papers tot new-age bullshit het licht. Op basis van de laatste evoluties in deep learning voor Natural Language Processing, is het aansturen van je eigen adventure game slechts een van de vele creatieve toepassingen. Met wat goede wil is ook automatische vertaling een vorm van NLG – we genereren immers een equivalent van de oorspronkelijke tekst, maar dan in een andere taal. En als we code ook als tekst beschouwen, valt het generatieve luik van Low Code Application Platforms er ook onder.
Hier kijken we naar twee categorieën van NLG systemen die fundamenteel verschillen van elkaar en op een heel andere manier tot resultaten komen. De eerste categorie moet het hebben van templates en grammaticale regels, en produceert een strikt deterministische output. De tweede categorie is gebaseerd op machine learning met een scheut randomness, en benadert zo meer wat we “creatief schrijven” zouden kunnen noemen. We beperken ons hier louter tot het genereren van tekst, waarbij je al weet wat je zou willen zeggen of welke richting je uit wil. Het begrijpen van vragen of het opzoeken van informatie, zoals bij chatbots en question answering systemen, kan aan het genereren van een tekst voorafgaan, maar zijn afzonderlijke concepten die buiten de scope van dit artikel vallen.

Grammaticale template engines
De “klassieke” manier om teksten te genereren is met templates. De meesten onder ons gebruiken die wel eens in Word en Powerpoint, en wie evenementen organiseert heeft misschien ervaring met MailChimp. Een template is zoals een formulier: een deel is vooraf geschreven en ligt vast, de rest moet je nog aanvullen met eigen gegevens of inhoud. Die inhoud kan je zelf schrijven, of halen uit een database. Maar zo’n rechtstreekse copy-paste uit een database heeft beperkingen: dat wat je invoegt moet immers ook grammaticaal passen in de omliggende vaste tekst. Dat wordt moeilijker als we in detail willen gaan of enigszins willen variëren.
Retailers of grote online handelaars bieden soms duizenden producten aan op hun website, elke dag verschijnen en verdwijnen er dingen uit het assortiment. Voor elk product moet een wervend tekstje op de website komen zodra het aan de database wordt toegevoegd. Om niet telkens dezelfde tekst te doen verschijnen, wil je “met onze blauwe suède schoenen” al eens afwisselen met “Deze schoen is blauw en gemaakt van suède,” en hetzelfde moet ook werken voor “rode lederen laarzen” of “grote Amerikaanse koelkasten“.
Het doel van zulke data-to-text NLG is om op basis van een database met mogelijk gevarieerde inhoud, toch correcte teksten te kunnen genereren. Daarvoor moeten voornaamwoorden, meervouden, verbuigingen en vervoegingen flexibel aangepast kunnen worden al naargelang het beschreven object en haar eigenschappen. In het Frans moet het accord de l’adjectif correct zijn, in het Duits de naamvallen, in het Nederlands de lidwoorden. Idealiter wordt er ook elegant met ontbrekende gegevens omgegaan, kunnen we de zinsvolgorde al eens veranderen, en tegelijk zorgen dat we ook niets onnodig herhalen.

Echte NLG template engines maken gebruik van een woordenboek en een grammaticale rule engine om dat allemaal correct te kunnen genereren. Verschillende bedrijven zijn actief in deze markt, vaak voorzien zij grafische interfaces en integraties die het gebruiksgemak heel wat kunnen verhogen. Er zijn ook open-source oplossingen waaronder SimpleNLG, RiTa en RosaeNLG. Een NLG template in die laatste ziet eruit als volgt:
| #[+subjectVerbAdj('enquête', {verb: 'être', tense: 'PASSE_COMPOSE', aux: 'AVOIR'}, 'ouvert', {det:'INDEFINITE'})]
| concernant
| #[+value('réclamation', {det:'POSSESSIVE', adj: 'contesté', adjPos: 'AFTER', number:'P' })]
Dit genereert: “Une enquête a été ouverte concernant ses réclamations contestées“. De meeste parameters in dit voorbeeld, zoals de woorden ‘enquête‘, ‘ouvert‘, ‘réclamation‘, ‘contesté‘, kunnen vlot vervangen worden door andere woorden (van dezelfde woordsoort) en dan zal deze template een even correcte zin produceren. Parameters zoals werkwoordstijd en type voornaamwoord zijn eveneens gemakkelijk aanpasbaar.
Het gebruik van NLG op basis van grammaticale template engines heeft een paar duidelijke voordelen:
- De hoge parametriseerbaarheid maakt dat je met 1 goed ontwikkelde NLG template teksten kan genereren over relatief heterogene collecties van gegevens.
- Je hebt volledige controle over de output, alle output is gegarandeerd conform het template.
- Slim gebruik van synoniemen, alternatieve beschrijvingen, wisselende zinsvolgorde, gelinkte voornaamwoorden etc. kunnen veel variatie van de output opleveren.
Het belangrijkste nadeel is dat zulke grammaticale templates erg snel erg complex worden. Als ook variatie en synoniemen ingebouwd moeten worden, is zo’n template al snel vele malen langer dan de tekst die ze genereert. NLG templates ontwikkelen die goed geparametriseerd en breed inzetbaar zijn, is tijdrovend secuur werk en vereist bovendien een uitstekende kennis van grammatica. Als een klassieke substitutie-oplossing waarin je slechts hoeft te copy-pasten al tot een voldoende kwalitatief resultaat leidt, dan bieden NLG templating engines weinig meerwaarde.
Creatief schrijven met neurale netwerken
Een volledig andere manier om teksten te genereren werd mogelijk dankzij machine learning en met name deep learning, waarmee op basis van enorme hoeveelheden bestaande tekst (denk ter grootte van een paar keer de volledige wikipedia) een taalmodel getraind kan worden dat “weet” welke woorden in welke context het meest geschikt zijn. Zulke taalmodellen “voorspellen” het meest plausibele volgende, of ontbrekende, woord. Doe dat vele keren na elkaar en je genereert uiteindelijk ook een tekst.
Kleine taalmodelletjes zitten al een tijdje in onze smartphone, waar toetsenbord-apps suggesties geven voor het volgende woord in een tekstbericht. De taalmodellen van vandaag zijn vele malen groter en kunnen veel beter rekening houden met context, zeker sinds de opkomst van de zogenaamde transformer architectuur. Die zit achter verschillende taalmodellen die furore hebben gemaakt in de laatste paar jaren, zoals BERT, T5 en GPT. GPT-3 is dusdanig groot dat eenzelfde model inzetbaar is voor verschillende taken. De geselecteerde derde partijen die van OpenAI aan de slag mochten met het model maakten al indrukwekkende applicaties.
Het kost heel wat geld, hardware en tijd om zelf zulke taalmodellen te trainen. Wie niet zulke financiële resources heeft, moet vertrekken van een bestaand model dat ter beschikking wordt gesteld door de grote spelers, en trachten dat te verfijnen. Daarmee ben je wel afhankelijk van de dataset die gebruikt werd om het originele model te trainen. Met die trainingsdata, die niet altijd openlijk beschikbaar is, zijn verschillende problemen. Ze zijn deels gescraped van allerlei internetfora, wat maakt dat er nogal wat persoonlijke gegevens in terechtkomen die kunnen uitlekken. Het overgenomen discours van minder appetijtelijke fora leidt dan weer tot sterke bias in de gegenereerde teksten.

Mede daarom wordt de toegang tot GPT-3 angstvallig bewaakt door OpenAI. Voorganger GPT-2 is wel vrij beschikbaar en de oefening om dat ook eens te trainen in het Nederlands werd al gedaan door onder andere de Universiteit van Groningen [code] en de Gentse AI-startup ML6 [code en demo]. Beiden maken andere keuzes voor de manier waarop ze trainen, en gebruiken bovendien verschillende datasets: het Groningse GroNLP model is getraind op voornamelijk wikipedia, e-books en nieuwswebsites, terwijl ML6 zich baseert op OSCAR, een subset van de CommonCrawl webscraping dataset. Beide hebben hun eigen voor- en nadelen: tekst gegenereerd door het GroNLP model gaat al snel lijken op een stationsromannetje, terwijl de OSCAR dataset heel wat bankrekeningnummers, bestaande adresgegevens en zelfs erotiek bevat.
GPT taalmodellen werken als volgt: men geeft een aanzet (een prompt) en laat dan het model vrij aanvullen. Dat aanvullen kan je verder vrij weinig sturing geven, je draait bij wijze van spreken gewoon de woordenkraan open. Eventueel kan je een gebruiker laten kiezen uit verschillende mogelijkheden, of de output alsnog filteren (als je bepaald taalgebruik wil weren), maar dat moet je zelf toevoegen.
Een fictieve biografie van ondergetekende uit een parallel universum, gegenereerd door GroNLP, klinkt als volgt (tekst in vet gegeven als aanzet):
Joachim Ganseman is informaticus en heeft gestudeerd aan de Universiteit van Antwerpen. Levensloop. Hij begon zijn opleiding in het Koninklijk Belgisch Staatsinstituut voor Landbouw (KOCO) te Brussel, waar hij ook een landbouwdiploma kreeg. Hij werkte daar onder andere als assistent-accountant bij Yves Van den Bucket uit 1988 tot 1997. In 1996 was hij adjunct-adjunct-directrice met wie hij contact zocht tussen verschillende Europese landen over hun beleid inzake voedselveiligheid.
Dezelfde aanzet bij ML6 genereert de volgende biografie – ik heb duidelijk een carrière in de agro-sector gemist:
Joachim Ganseman is informaticus en heeft gestudeerd aan de Universiteit van Antwerpen. Als onderzoeker werkte hij veel in het bedrijf van de jonge kunstenaar en producent van het meest uiteenlopende werk: de tuin, het terras, de terras- en het terrasrestaurant. Tijdens zijn werkzaamheden werd hij de expert en de eerste specialist in het werk van Ganseman. Hij specialiseerde zich in de tuinontwerp. Zijn onderzoek naar tuinontwerp is gebaseerd op de vele verschillende tuinontwerpen en is te vinden op diverse sites zoals: websites, mobiele applicaties, apps en sites van partijen.
De repetitiviteit blijft moeilijk te controleren. Je wil dat de output bij hetzelfde thema blijft maar dat geeft een risico op in herhaling vallen, terwijl veel vrijheid dan weer riskeert dat de tekst plots een heel andere richting uitgaat. Deze Nederlandstalige GPT-2 modellen zijn ook nog relatief klein, de context van de aanzet is vaak na een drietal zinnen al vergeten en dan zie je soms rare sprongen in de thematiek gebeuren.
Uit de aanzet die je geeft zal het model bepaalde aannames afleiden over de stijl, taalgebruik en inhoud van wat moet volgen. Zo genereer je met hetzelfde model zowel deze serieus klinkende (inhoudelijk absurde) quasi-wettekst, als het daaropvolgende (oneetbare) quasi-recept:
- Artikel 478, eerste lid, Gerechtelijk wetboek bepaalt dat degene die bij of krachtens deze wet wordt vervolgd wegens een strafbaar feit in de eerste aanleg bij de aanvang van de terechtzitting is verschenen, onverwijld zal worden vervangen door een gewezen rechter-commissaris.
- 2 eieren , 500g boter , 500g suiker , 100g bloem , 1 stokje vanille. Recept: Voeg de kaneel, kaneel en vanille toe aan de mix, voeg nog een beetje vanille, voeg 1 theelepel vanille toe. Meng met een lepel de suiker en klop door tot hij zacht genoeg is om dit een eierdooistokje te maken. Voeg vervolgens de melk, kaneel en vanille toe en voeg dit nog een beetje bij het product. Klop alles goed door elkaar en bestrooi de mix erover.
Via een goed doordachte prompt kunnen we het model dus heel verschillende output laten produceren. Voor echt gespecialiseerde taken zoals het genereren van een machinevertaling of programmeercode, zal het finetunen van het model op een speciaal daarvoor gemaakte dataset misschien wel nog robuustere resultaten geven, zoals bij deze omzetting van Engelse tekst naar SQL queries.
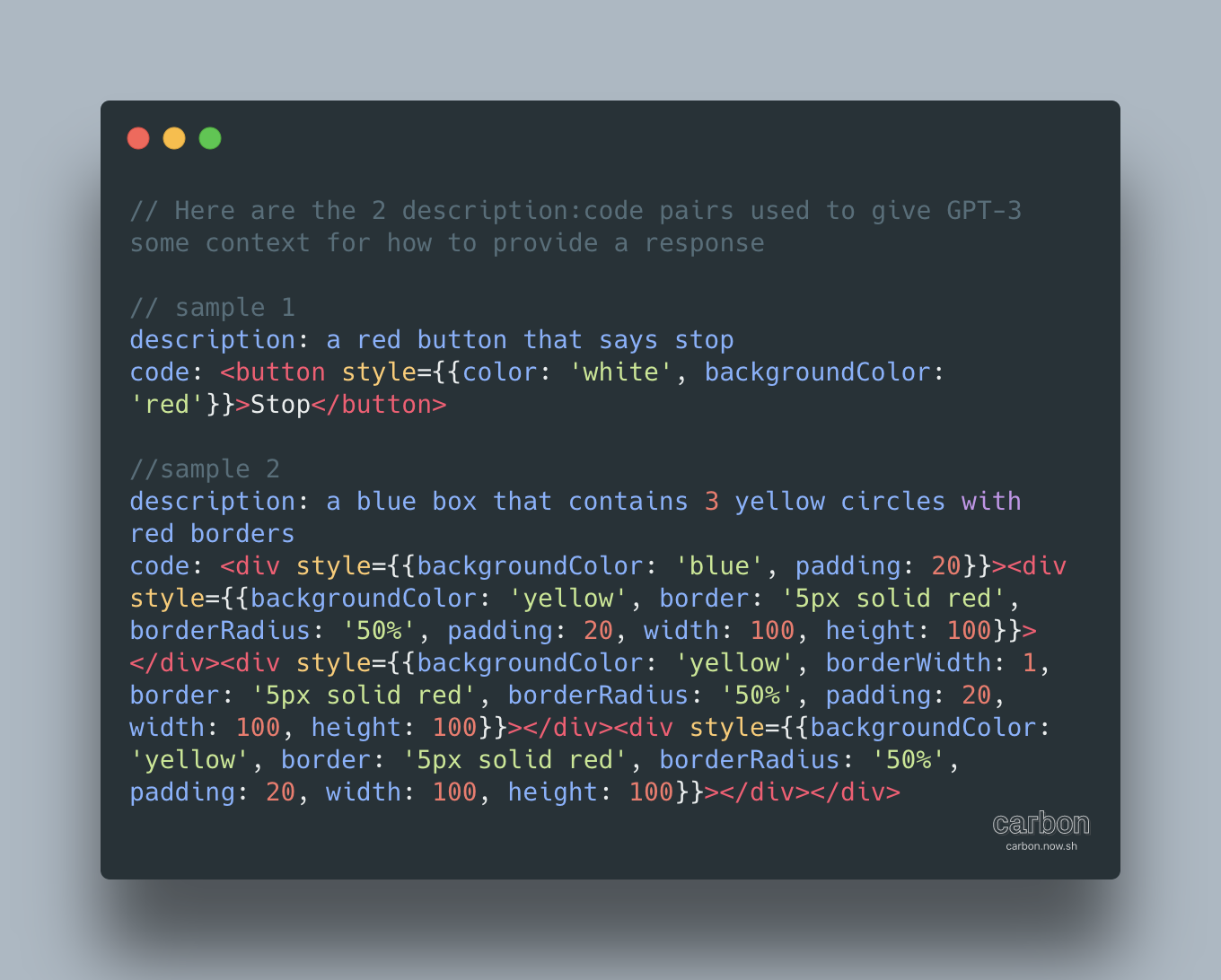
Conclusie
Het gebruik van NLG templating engines is aangewezen wanneer er een duidelijke meerwaarde is ten opzichte van de klassieke substitutie-templates (copy-paste), en wanneer de gegenereerde teksten bedoeld zijn voor de buitenwereld. Toepassingen zijn onder andere:
- Het maken van regelmatige tekstuele rapporten of notificaties over constant binnenstromende gegevens, zoals weerberichten, de financiële markten, de sportuitslagen, maar ook statusrapporten van IT systemen, sensorgegevens van IoT devices, etc.
- Het aanmaken van sterk gepersonaliseerde teksten, over bvb. de inhoud van een winkelmandje, of van een persoonlijk dossier, hetgeen per gebruiker erg kan verschillen.
- Het maken van gevarieerde teksten voor omvangrijke productdatabases bij grote retailers, deelplatformen etc.
Het gebruik van deep learning taalmodellen voor het genereren van tekst is veel riskanter. Zeker als de training van die modellen niet volledig onder eigen controle is gebeurd, is een manuele validatie en correctie van de output altijd aangewezen. Je accepteert immers ook niet blind de suggesties van je smartphonetoetsenbord. Deze aanpak vindt dus vooral intern zijn nut, binnen de organisatie, op plaatsen waar creatief schrijven vandaag veel tijd opeist. We denken onder andere aan:
- Assistentie bij het schrijven of als tool tegen writer’s block, door het suggereren van plausibele aanvullingen.
- Het aanmaken van realistisch ogend maar toch fictief opleidingsmateriaal. Dit is nuttig wanneer het niet wenselijk zou zijn dat personen in opleiding echte dossiers inkijken, bvb. omwille van privacyredenen.
- Het maken van examenvragen.
- Het maken van (tekstuele) synthetische datasets – mits kwaliteitscontrole, filtering en validatie van de output.
- In UX analyse, voor het verzinnen van willekeurige persona’s, fictieve biografieën en gebruiksscenario’s.
De kwaliteit van de vandaag beschikbare Nederlandstalige generatieve modellen, blijft nog wel wat achter bij dat wat de media haalt in het Engels – wat ook De Standaard opmerkte toen zij aan het testen gingen. Om dat ten gronde te verbeteren zal ook werk gemaakt moeten worden van zorgvuldiger samengestelde Nederlandstalige trainingsdatasets.
Voor specifieke toepassingen zoals codegeneratie, verwachten we dat gespecialiseerde modellen relatief snel hun weg zouden kunnen vinden in de bestaande professionele IDEs. Microsoft heeft recent aangekondigd een deel van de functionaliteit van GPT-3 in te bouwen in hun Power Apps low-code platform, en Github lanceert met CoPilot een “AI Pair Programmer” als plugin voor de Visual Studio Code editor. Ongetwijfeld zullen anderen volgen, en zo vinden we suggesties van krachtiger tekstgeneratoren misschien binnenkort al terug als plugin in de gangbare developer tools.
______________________
Dit is een ingezonden bijdrage van Joachim Ganseman, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.
Leave a Reply