Het streven van 99% naar 99.9% availability is een veel grotere stap dan de stap van 95% naar 99%. De traditionele manier van werken schiet ruimschoots tekort (ad-hoc processen, de software-architectuur en ontwerp, een deterministische failover, …). Door alles “juist iets beter doen”, zullen we er niet komen. De specifieke elementen van High Availability systemen worden in dit artikel kort besproken.
10 misvattingen bij gedistribueerde systemen
Bij het ontwerpen van systemen in een gedistribueerde context (bv. verschillende webservers moeten toegang krijgen tot dezelfde databank), wordt nog te vaak uitgegaan van veronderstellingen die in praktijk helemaal niet gelden, waardoor systemen falen:
- Het netwerk is betrouwbaar;
- De latency is nul;
- De bandbreedte is oneindig;
- Het netwerk is veilig;
- De topology verandert niet;
- Er is slechts één administrator.
- Transport is gratis;
- Het netwerk is homogeen.
Bij het ontwerpen van gedistribueerde systemen moet er vanuit worden gegaan dat deze elementen zullen falen. Tijdens testing moeten deze situaties dan ook expliciet gevalideerd worden!
Hoge beschikbare systemen
Voor het bouwen van systemen met een hoge beschikbaarheid, zijn volgende punten essentieel:
Governance
Het robuust maken van een systeem vereist dat men het systeem goed beheerst en dat er bijgevolg een hoge voorspelbaarheid heerst. ITIL processen moeten geïnstalleerd worden en zich in een mature fase bevinden. Denken we bijvoorbeeld aan IT Asset Management (welke hardware, welke software, welke applicaties, business processen, netwerkconnecties, … hebben we?), Release Management, Configuration Management (welke configuraties bevinden zich waar & waarom?), …
Duidelijke processen
De hoeveelheid menselijke interventie moet geminimiseerd worden (de meeste fouten gebeuren door mensen) en bijgevolg moeten zoveel mogelijk processen geautomatiseerd worden (hier is goede governance voor nodig uiteraard). Er moet een duidelijk inzicht zijn van de processen, wie waarvoor verantwoordelijk is, een duidelijke documentatie aanwezig zijn en de complexiteit moet verlaagd proberen te worden.
Vanaf het ontwerp
Het ontwerp van systemen met een hoge beschikbaarheid steunt op
- Transparantie: Lange termijn betrouwbaarheid is steeds gebaseerd op een transparante en begrijpelijke documentatie.
- Lage complexiteit: Complexe systemen moeten opgedeeld worden in subsystemen met lagere complexiteit.
- Redundantie: Redundante systemen voorzien een extra instantie voor in het geval een kritische component uitvalt; deze neemt automatisch over in geval van falen (failover) en zet een proces in gang dat de oorspronkelijke component laat heropstarten of vervangen.
- Diversiteit: Diversiteit kan de kans op gezamenlijk falende componenten verminderen. Men kiest componenten & architecturen die fundamenteel andere faalmechanismes vertonen
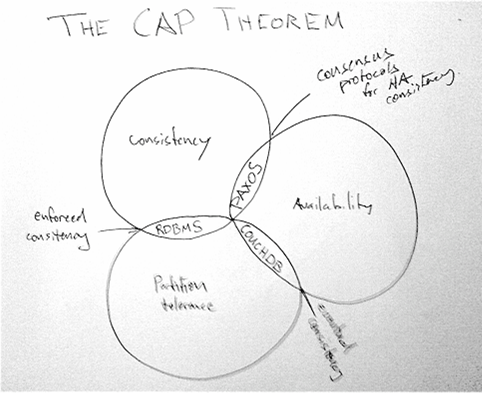
Het CAP theorema
Theorema

{kind=link}
Er bestaat een fundamenteel theorema, bewezen door de MIT, dat stelt dat bij gedistribueerde systemen, van de volgende drie niet-functionele requirements (NFR’s):
- Consistency (elk deelsysteem geeft hetzelfde antwoord)
- Availability (we krijgen steeds antwoord)
- Partition tolerance (verlies van willekeurig aantal netwerkpakketten is toegelaten)
er slechts twéé tegelijk voldaan kunnen zijn.
Grafisch bewijs
Zonder in detail te treden (Er bestaat een bewijs van de MIT), zullen we het theorema grafisch intuïtief illustreren.
Geval 1: Alles verloopt naar wens

- Proces A schrijft een nieuwe waarde V1 weg naar de databank in node N1
- Een message M gaat over het netwerk naar N2
- De nieuwe waarde V1 is beschikbaar in de databank in node N2
- Proces B beschikt over de nieuwe waarde
Geval 2: Het netwerk is onbeschikbaar
In dit geval komt de boodschap M met de change niet toe bij N2. De eerste stappen blijven hetzelfde:

- Proces A in systeem N1 schrijft V1 weg naar V0
- Node N1 stuurt een boodschap M naar node N2
Op dit moment kan systeem N1 niet weten of het systeem N2 dan wel het netwerk down is (het systeem is partition-tolerant). Volgens het CAP theorema zijn nu twee keuzes:
A. Kiezen voor consistency
Omdat proces N1 geen ontvangstbevestiging gekregen heeft van N2, wordt het proces A afgebroken (atomicity) daar de consistency tussen de twee databanken in N1 en N2 niet gegarandeerd kan worden. Het systeem is unavailable.
B. Kiezen voor availability
Hoewel systeem N1 geen ontvangstbevestiging gekregen heeft van N2, wordt de transactie toch afgehandeld (het systeem is dus available). Op dit moment bezitten N1 en N2 verschillende versies van de gegevens. Het systeem is inconsistent.
Geval 3: Kiezen voor partition intolerance
Het geval dat men kiest om partition intolerant te zijn, gaat men er in feite van uit dat het netwerk nooit faalt. Het systeem is dus gevoelig aan het verlies van netwerkpakketten. De deelsystemen gaan er immers vanuit dat elk verzonden pakket ook toekomt. In bovenstaand geval kan het zijn dat node N2 “down” is. In dit geval kan node N1 dit detecteren (niet kunnen communiceren is dan immers equivalent aan “de node is down” omdat we gevoelig zijn aan partities) en hier rekening mee houden. De databank is consistent en available, maar niet partition tolerant.
Conclusies
Het in productiestellen en onderhouden van hoog-beschikbare systemen, vereist een goede controle evenals een goed inzicht. Daarom is het belangrijk
- Een goede governance te hebben (ITIL, …)
- Menselijke interactie te minimiseren in alle processen
- Rekening te houden met High Availability vanaf het begin van het ontwikkelproject
De belangrijkste basistechnieken gebruikt in High Availability architecturen zijn:
- Transparantie (goede documentatie!)
- Verlagen van de complexiteit
- Redundantie
- Diversiteit
Essentieel is echter te beseffen dat Consistentie, Availability en Partition Tolerance niet op hetzelfde moment gegarandeerd kunnen worden maar afgewogen moeten worden!! In praktijk zal men kiezen voor Eventually Consistent systemen die tijdelijke consistentie problemen tgv. de unavailability van een deelsysteem later zullen opvangen en oplossen op business niveau. Hier moet vanaf het begin van het ontwerp rekening mee gehouden worden!