Systemen die gebaseerd zijn op retrieval augmented generation (RAG) zijn een van de populairste toepassingen van grote taalmodellen (LLM’s). Deze systemen verbeteren LLM’s door hun antwoorden te verankeren in gecontroleerde databronnen. Ze vertonen echter enkele beperkingen, met name wat betreft het onder controle houden van hallucinaties. Onlangs is er een nieuw paradigma ontstaan dat deze beperkingen omzeilt: GraphRAG. GraphRAG is een variant van RAG die de kracht van LLM’s en knowledge graphs combineert, wat leidt tot nauwkeurigere en betrouwbaardere antwoorden.
Dit artikel gaat dieper in op het concept van GraphRAG en behandelt de architectuur, de voordelen en de implementatie ervan.
Basisbegrippen
Om GraphRAG te begrijpen, moeten eerst enkele basisbegrippen worden geïntroduceerd.
Graphs en knowledge graphs
Een graph is een gestructureerde manier om gegevens te organiseren in nodes en hun relaties. Een knowledge graph (KG) geeft betekenis aan data door middel van een ontologie en maakt redeneren over de graph mogelijk. Bovendien maken knowledge graphs het mogelijk om verschillende databronnen te combineren. Een gedetailleerde beschrijving van het concept van knowledge graphs vind je hier: Graphtechnologieën, de toepassingen ervan en tools: een overzicht (deel 2) | Smals Research.
Retrieval-augmented generation (RAG)
LLM’s worden verbeterd door informatie uit een externe knowledge base (bijvoorbeeld pdf’s, webpagina’s) te gebruiken om een antwoord op een vraag van een gebruiker te genereren. Doorgaans haalt RAG informatie uit ongestructureerde documenten die in kleine stukjes tekst (chunks) worden opgedeeld en in een vector database worden geïndexeerd in de vorm van embeddings. De stukjes die relevant zijn voor de query worden uit de vector database opgehaald door middel van semantische similariteitsberekening (zie Een eigen vraag- en antwoordsysteem op basis van taalmodellen.
Hoewel traditionele RAG-systemen de kwaliteit van de antwoorden van LLM’s verbeteren, vertonen ze een aantal problemen:
- Ze slagen er niet in om complexe query’s te beantwoorden die meerstapsredenering vereisen en ze missen een “overzicht” van de informatie door het ontbreken van een gestructureerde context. Traditionele RAG-systemen werken namelijk door korte tekstfragmenten uit een database op te halen en deze aan een LLM te voeren om een vraag te beantwoorden. De fragmenten worden afzonderlijk verwerkt en de relaties tussen hen worden genegeerd. Deze techniek werkt goed voor gerichte query’s die lokale antwoorden vereisen, maar schiet tekort voor brede query’s die inzicht vereisen in patronen en relaties op hoog niveau die verspreid zijn over documenten – LLM’s hebben moeite om betekenis te geven aan gefragmenteerde gegevens.
- De context die bij de prompt wordt geleverd, bevat ruis. Retrieval op basis van semantische gelijkenis levert vaak buitensporige en redundante stukken tekst op, waardoor het voor LLM’s moeilijk is om relevante details in de context te vatten, wat leidt tot een verminderde nauwkeurigheid van het gegenereerde antwoord. Bovendien, als de retrieval-fase er niet in slaagt relevante chunks te extraheren, krijgt de LLM onvolledige informatie, wat kan leiden tot hallucinaties.
Wat is GraphRAG?
GraphRAG staat voor Graph-Aided Retrieval-Augmented Generation en is een RAG-configuratie die gebruikmaakt van de interne verbondenheid van knowledge graphs.
KG’s zijn om de volgende redenen een logische keuze om RAG te verbeteren:
- Graph-structuren, waarin kennis wordt weergegeven in de vorm van entiteiten en relaties, maken diepgaander redeneren mogelijk. Een graph vangt conceptuele verbanden beter op die het redeneren sturen.
- Ze bieden een gestructureerde kennisbron die LLM helpt om antwoorden te verankeren in verifieerbare feiten.
Door een graph te gebruiken om de relaties tussen stukjes informatie te modelleren, stelt GraphRAG het model in staat om de context beter te begrijpen. Het gaat hier niet om een enkel algoritme, maar om een reeks architecturale patronen die graphs gebruiken om de relevantie, consistentie en traceerbaarheid van antwoorden te verbeteren. Afhankelijk van het probleem dat moet worden opgelost, bestaan er verschillende manieren om GraphRAG te implementeren. Deze kunnen worden onderverdeeld in drie grote categorieën, op basis van de vorm die de graph aanneemt:
- Indexgebaseerde GraphRAG: graphs worden gebruikt als index om de ruwe teksten van een corpus te ordenen. De tekstfragmenten worden georganiseerd in een graphstructuur waarin de relaties tussen deze chunks worden benut om de tekst efficiënt en semantisch bewust op te halen. Deze relaties worden gedefinieerd door de semantische gelijkenis tussen chunks en/of gedeelde entiteiten. De onderliggende graph is een lexicale graph. Deze architectuur wordt doorgaans gebruikt voor RAG op lange documenten, de graph maakt het dan mogelijk om de structuur van het document te behouden door de volgorde van de chunks (“is het vervolg van”-relatie) of de hiërarchie van het document (“is een subsectie van”-relatie) te volgen.
- Kennisgebaseerde graphRAG: de (knowledge) graphs zijn gebruikt als belangrijkste vectoren van kennis waar de nodes concepten zijn en de edges hun semantische relaties weergeven. De knowledge graph geeft doorgaans de kennis van het vakgebied weer. Volgens deze configuratie kan een niet-gestructureerde tekst worden omgezet in expliciete, gestructureerde gegevens in de knowledge graph. Hierdoor kan direct op de graph worden geredeneerd.
- Hybride GraphRAG: deze aanpak combineert vectorgebaseerd ophalen en graphgebaseerd zoeken voor betere resultaten.
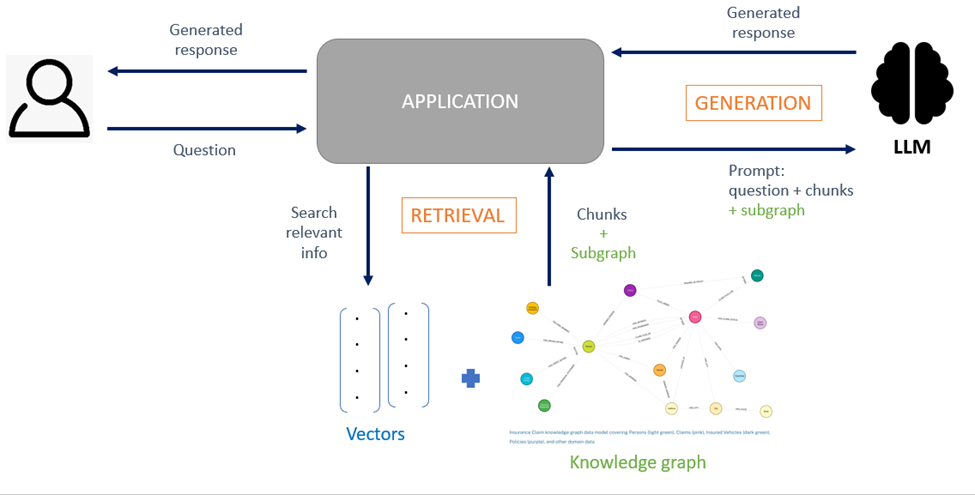
Voordelen van GraphRAG
Beter contextueel begrip
Knowledge graphs geven kennis beter weer: ze bieden een rijke context van relaties die het begrip van de LLM verbeteren. Retrieval uit een graph legt complexe afhankelijkheden tussen stukken informatie bloot die met traditionele RAG mogelijk niet worden opgemerkt.
Minder hallucinaties
De informatie die in een KG wordt opgeslagen is gestructureerd en bevat geen ruis. Bovendien integreren geavanceerde graphs ontologieën die formele definities geven voor de concepten. Dit alles draagt bij tot het verankeren van de LLM’s in feiten en het verminderen van hallucinaties.
Verklaarbaarheid
Het redeneringspad door de KG kan gemakkelijk worden getraceerd en gevisualiseerd door gebruikers. In combinatie met de uitleg van de LLM zorgt dit voor een transparanter RAG-systeem.
Implementatie van GraphRAG in de praktijk
Opbouw van de graph
a) Data ingestion
De meeste stappen in het data ingestion proces zijn vergelijkbaar met die in traditionele RAG: verzamelen, opschonen en opdelen van het corpus in kleinere eenheden, enz.
b) Entiteiten en relaties extraheren
LLM’s of regelgebaseerde systemen worden gebruikt om entiteiten en relaties in de tekst te identificeren.
c) Registratie van entiteiten, relaties en/of chunks in de graph
Vaak wordt de graph verrijkt met samenvattingen van gemeenschap van noden voor een globale context. Groeperingsalgoritmen zoals Louvain of Leiden worden vervolgens gebruikt om hiërarchische gemeenschappen binnen de graph te creëren en voor elke community vat een LLM vervolgens de informatie van de community samen.
d) Creatie van embeddings voor nodes, relaties en samenvattingen van gemeenschappen
Merk op dat de kosten om een knowledge graph op te bouwen op basis van ongestructureerde gegevens snel kunnen oplopen door de vele query’s die naar de LLM’s worden gestuurd.
Knowledge retrieval
De methodes om kennis op te halen zijn talrijk, deze sectie beschrijft enkel de meest voorkomende.
De eerste stap voor knowledge retrieval bestaat uit het vinden van de toegangspunten in de graph. Dit gebeurt door middel van een semantische zoekopdracht op de vectorrepresentatie van een chunk of een node, of door een declaratieve query te genereren in de taal van de graph (Cypher voor Neo4j) op basis van de in natuurlijke taal geformuleerde gebruikersquery. De informatie die door de zoekopdracht wordt teruggestuurd, wordt vervolgens naar de LLM gestuurd om het definitieve antwoord te genereren.
Er bestaan twee strategieën om een graph query van het type Cypher te genereren. De eerste is gebaseerd op vooraf gedefinieerde querymodellen, die tijdens de uitvoering worden aangevuld door de LLM, die automatisch de nodige parameters uit de oorspronkelijke query van de gebruiker haalt. Deze basisconfiguratie heeft het voordeel dat zij eenvoudig en correct geformatteerd is, maar mist flexibiliteit omdat het aantal query’s dat op de graph kan worden uitgevoerd beperkt is. De tweede bestaat uit het dynamisch laten construeren van de query op de graph door een LLM. De LLM genereert vervolgens de complete graph query gebaseerd op de aard van de vraag van de gebruiker en het opgegeven graphschema. Deze methode is flexibeler maar minder betrouwbaar. Het is daarom aan te raden om een paar voorbeelden toe te voegen aan de prompt en om syntaxiscontrolemechanismen te implementeren.
Een andere veelgebruikte methode voor het ophalen van informatie is een vectorzoekopdracht op de chunks, gevolgd door het doorlopen van de graph om aanvullende informatie over de relaties tussen de chunks en de entiteiten te verzamelen. Zoals hierboven vermeld, hangt de manier waarop informatie wordt opgehaald af van het doel dat men wil bereiken.
Andere technieken voor het ophalen van informatie:
Bron: A Survey of Graph Retrieval-Augmented Generation for Customized Large Language Models, Zhang et al.
- Hierarchical retrieval. De graph is georganiseerd in een hiërarchische structuur waarin de hoogste niveaus algemene informatie bevatten voor een breed contextueel begrip (bijv. samenvattingen van community’s), terwijl het laagste niveau meer specifieke informatie bevat. In het kader van onze experimenten hebben we een eenvoudige versie van deze methode toegepast op een chatbot (RAPTOR), wat de kwaliteit van de antwoorden heeft verbeterd.
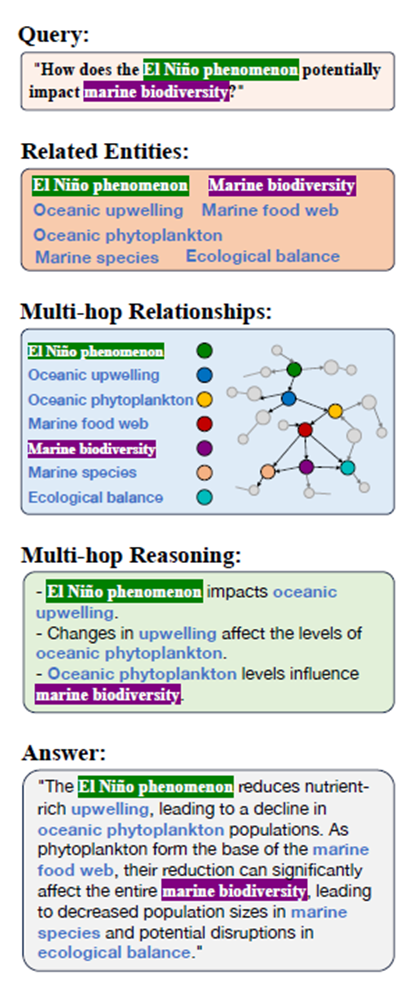
- Multi-hop retrieval. Voor het redeneren wordt de informatie meerdere stappen verwijderd van de oorspronkelijke vraag opgehaald via een extra doorloop, eventueel gestuurd door een ontologie. De geëxtraheerde paden worden vervolgens gelineariseerd in tekstformaat om de LLM te voeden (zie Fig. 2).
- Multi-turn retrieval. Het antwoord wordt iteratief verfijnd via een feedbackloop tussen de graph en de LLM, waarbij de LLM aanvullende query’s formuleert als de informatie die uit de graph wordt opgehaald niet volledig is.
Strategieën voor verbetering van de retrieval
Knowledge retrieval gaat vaak gepaard met verwerkingsoperaties vóór of na de uitvoering van de query:
- Query decomposition: als de query complex is, wordt deze vóór de retrieval-fase verder verwerkt. De query wordt met behulp van een LLM opgesplitst in eenvoudige subquery’s, die vervolgens worden vertaald naar graph-taal. De resultaten van de subquery’s worden gegroepeerd om een antwoord te genereren.
- Query expansion: de oorspronkelijke query wordt verrijkt met extra context. De knowledge graph wordt vervolgens gebruikt om het toepassingsgebied van de query uit te breiden door nieuwe entiteiten of relaties toe te voegen aan de query.
- Pruning (het verwijderen van nutteloze informatie) en herschikken van queryresultaten.
Uitdagingen bij de implementatie
Hoewel GraphRAG veel verbeteringen biedt aan traditionele RAG, brengt het ook enkele uitdagingen met zich mee:
- De juiste balans vinden voor een kwalitatief goede graph: een te dichte graph gaat ten koste van de prestaties, maar een te dunne graph gaat ten koste van de nauwkeurigheid.
- Graph/tekst-alignment: gangbare LLM’s zijn niet ontworpen om native graph-structuren te verwerken.
- Schaalbaarheid: omvangrijke graphs vereisen efficiënte algoritmen voor het identificeren van relevante subgraphs.
- Ondubbelzinnigheid: entiteiten moeten correct worden geïdentificeerd om contextfouten te voorkomen.
Conclusie
GraphRAG is een concept om in de gaten te houden. Afhankelijk van de toepassing kan het de prestaties van taalmodellen aanzienlijk verbeteren in vergelijking met traditionele RAG-systemen. Dankzij de gestructureerde weergave van informatie in knowledge graphs, vergroot GraphRAG het redeneervermogen van LLM’s en kan het zijn antwoorden motiveren, waardoor een transparanter systeem kan worden opgebouwd en hallucinaties aanzienlijk worden verminderd. Deze verandering is met name van cruciaal belang voor sectoren zoals de gezondheidszorg of de publieke sector, waar nauwkeurigheid en interpreteerbaarheid vereist zijn.