Dit artikel is het vervolg op een eerste deel dat zich toespitste op de veiligheid van code die gegenereerd werd door generatieve AI-tools (GenAI). In het tweede deel nemen we de taak onder de loep om kwetsbaarheden in bestaande code op te sporen en zien we hoe GenAI daarbij zou kunnen helpen.
Kwetsbaarheden in code zijn een terugkerend probleem dat de meeste software treft en een impact heeft op integriteit, vertrouwelijkheid en beschikbaarheid. Er wordt aangeraden om bepaalde programmeertalen te gebruiken waarvan bekend is dat ze minder gevoelig zijn voor klassieke problemen dan andere (bijv. Rust in plaats van C). Code review door andere expertprogrammeurs is ook een veelgebruikte methode. Maar zou GenAI de taak kunnen vergemakkelijken?
Zoeken naar kwetsbaarheden
Er zijn verschillende manieren om kwetsbaarheden in code of binaire bestanden op te sporen, zowel automatisch als handmatig, statisch of dynamisch, en systematisch of verkennend. In 2022 hebben Elder et al. [1] in een zeer gedetailleerde studie verschillende van deze methoden vergeleken op een grootschalige toepassing in de medische sector: OpenMRS. Deze bevat bijna 4 miljoen regels Java- en JavaScript-code. De auteurs doen verschillende aanbevelingen op basis van de beoogde doelstellingen en de beschikbare middelen (expertise, tijd, apparatuur) en bevestigen een eerdere studie: elke methode voor het opsporen van kwetsbaarheden vindt kwetsbaarheden die met andere methoden niet zijn gevonden. In hun experiment bleek echter de handmatige verkennende methode met penetratietests de gevaarlijkste kwetsbaarheden op te sporen.
GenAI en statische analyse
Tabel 1 vergelijkt twee benaderingen van code-analyse: statische (klassieke) en een analyse die GenAI gebruikt. Volgens bepaalde studies zou GenAI enkele voordelen beginnen te vertonen ten opzichte van klassieke statische analysetools.
Tabel 1 – Overzicht van de belangrijkste verschillen en overeenkomsten tussen twee benaderingen van codeanalyse: statische analyse en analyse met GenAI (naar [2]).
| Criterium | Statische analyse | Analyse met GenAI |
|---|---|---|
| Doel en ontwerp | Bekende beveiligingskwetsbaarheden in de code identificeren | Menselijke tekst begrijpen en genereren, inclusief computercode |
| Weergave van code | Abstracte syntactische bomen of controlestroomgrafen | Code als reeksen tokens |
| Leren en aanpassen | Vooraf gedefinieerde regels en handtekeningen gebruiken; geen traditioneel ‘leren’ | Continu ‘leren’ op basis van trainingsgegevens; aanpassing op basis van waargenomen patronen |
| Generalisatie | Nauwkeurig en specifiek; gebaseerd op bekende patronen/signaturen | Kan verschillende patronen/stijlen van codering generaliseren |
| Feedback en iteratie | Deterministische feedback op basis van overeenstemming met regels | Contextuele en beschrijvende feedback |
| Dekking van kwetsbaarheden | Beperkt tot een reeks vooraf gedefinieerde regels/handtekeningen | Potentieel breder vanwege algemene training, maar kan onnauwkeurig zijn |
| Werkingsbasis | Regels | Patroonherkenning op basis van trainingsgegevens |
| Aanpasbaarheid | Vast, tenzij de regels worden bijgewerkt | Flexibel dankzij patroonherkenningsmogelijkheden |
Noever [2] heeft bijvoorbeeld de prestaties van bepaalde GenAI onderzocht om kwetsbaarheden in software te identificeren en te verhelpen. Zijn onderzoek had betrekking op verschillende GitHub-repository’s en vergeleek GenAI met statische analysetools. De auteur gebruikte de volgende prompt:
“Act as the world’s greatest static code analyzer for all major programming languages. I will give you a code snippet, and you will analyze the code and rewrite it, removing any identified vulnerabilities. Do not explain, just return the corrected code and format alone.”
De tests van de auteur gebruiken de volgende cyclus voor een bepaalde codebase:
- Gebruik een statische analysetool om het aantal en de ernst van de kwetsbaarheden te beoordelen;
- Vraag GenAI om de kwetsbaarheden te identificeren;
- Vraag GenAI om de gevonden kwetsbaarheden te corrigeren;
- Gebruik de statische analysetool op de gecorrigeerde code en vergelijk het aantal en de ernst van de gevonden kwetsbaarheden.
De resultaten van de auteur zijn vrij positief op basis van de gekozen codebase: GenAI heeft het aantal zeer ernstige kwetsbaarheden aanzienlijk verminderd.
Performantie van GenAI
Maar zelfs de beste tools die AI gebruiken voor foutdetectie hebben volgens CodeXGLUE een nauwkeurigheid van minder dan 70%. Een studie van Steenhoek [3] meldt dat de meest geavanceerde modellen slechts een gemiddelde nauwkeurigheid van 54,5%1 behaalden bij het opsporen van kwetsbaarheden, zelfs voor modellen die vooraf waren getraind op grote hoeveelheden broncode. Met andere woorden: “alle modellen en alle prompts leverden resultaten op die dicht in de buurt kwamen van willekeurige antwoorden op raadsels”. De auteurs verklaren dit door de moeilijkheid die GenAI heeft om te redeneren over de semantiek van code. Deze moeilijkheid om te redeneren beperkt zich overigens niet tot code [3].
We hadden al iets soortgelijks opgemerkt tijdens onze eigen tests op een codebase met bekende CWE-kwetsbaarheden: het aantal valse positieven2 was vaak even groot als het aantal echte positieven3 toen we verschillende modellen verzochten (gpt-40-mini, gpt-4o, mistral-large-2411, Llama-4-Scout, DeepSeek-V3, Qwen2.5) om aan te geven of een codebestand potentiële kwetsbaarheden bevatte. Zelfs toen we een volledige codebase verstuurden, waren onze resultaten niet overtuigender. Llama biedt namelijk een zeer grote context (10 miljoen symbolen) en nadat we het de volledige WebGoat – een speciaal geschreven softwareprogramma met kwetsbaarheden – hadden aangeleverd, werd er geen enkele significante kwetsbaarheid geïdentificeerd!
In een recentere en systematischere studie tonen Ullah et al. [4] aan – aan de hand van 8 modellen en 17 promptmethoden op 228 codevoorbeelden – dat GenAI niet-deterministische antwoorden en onjuiste en onbetrouwbare redeneringen geeft en slecht presteert in ‘realistische’ scenario’s. Erger nog, het onderzoek bevestigt ook een gebrek aan robuustheid bij het opsporen van potentiële kwetsbaarheden. Talrijke studies hadden al aangetoond dat machine learning-technieken niet robuust genoeg zijn tegen semantiekbehoudende codetransformaties, zoals het hernoemen van identifiers, het invoegen van niet-uitgevoerde declaraties of het vervangen van code door gelijkwaardige code [5]. Het is dan ook niet verwonderlijk dat amplificatiemethoden waarmee een model dit soort transformaties kan leren, alleen de robuustheid verhogen voor de specifieke transformaties waarop het model is getraind [5].
In een ander, meer anekdotisch voorbeeld bespreekt Heelan [6] het vermogen van ChatGPT-o3 om de kwetsbaarheid CVE-2025-37778 in de Linux-kernel te vinden. Afgezien van het feit dat de prompt die de auteur naar GenAI stuurde zeer nauwkeurig was (zorgvuldig geselecteerde codefragmenten, gedetailleerde instructies), vond GenAI de kwetsbaarheid slechts 8 van de 100 keer (dezelfde prompt werd 100 keer verzonden en slechts 8 keer vond GenAI de kwetsbaarheid). In een ander voorbeeld beschrijft de auteur hoe hij door toeval met behulp van GenAI een nieuwe kwetsbaarheid ontdekte; ook hier stuurde hij zijn verzoek honderd keer naar ChatGPT en vond hij in één antwoord een aanwijzing die hem op het spoor zette. Daarbij komen nog de milieukosten en financiële kosten van deze operatie en vooral het feit dat de nieuwe kwetsbaarheid semantisch verband houdt met de vorige.
Het is dan ook niet verwonderlijk dat de ervaring met verschillende vrije softwareprojecten aantoont dat bugs die met behulp van GenAI worden ontdekt, in werkelijkheid weinig waarde hebben [7], [8].
Integratie van GenAI in statische analyse
Om de detectie van kwetsbaarheden door GenAI in een codefragment te verbeteren, stellen Yue Li et al. [9] voor om zoveel mogelijk contextuele informatie te verzamelen (bijv. lijst van afhankelijkheden en specifieke informatie over een bepaald type kwetsbaarheid). Dit wordt in de praktijk gebracht in de IRIS-tool van Ziyang Li et al. [10].
IRIS combineert GenAI met statische analyse om beveiligingskwetsbaarheden in software op te sporen en tegelijkertijd het aantal valse positieven te verminderen. Deze tool volgt een systematisch proces voor het opsporen van beveiligingslekken:
- Extractie van potentiële kandidaten voor besmette bronnen of ontvangers in externe en interne programmeerinterfaces met behulp van een statische analysetool.
- Vragen aan een GenAI om de kandidaat-interfaces te labelen als bron of put (“sink”, kwetsbare functie) die specifiek is voor een bepaalde klasse van kwetsbaarheden4.
- De gelabelde bronnen en putten worden omgezet in specificaties die in CodeQL kunnen worden ingevoerd om een analyse uit te voeren van smears (variabelen die door gebruikersinvoer zijn besmet en een put kunnen bereiken) die specifiek zijn voor een klasse van kwetsbaarheden. Deze stap genereert een reeks kwetsbare codepaden (of waarschuwingen) in het project.
- Ten slotte wordt GenAI gebruikt om het aantal valse positieven dat door de statische analyse van CodeQL wordt gemeld te verminderen en tegelijkertijd een verklaring te geven.
Onze tests van de IRIS-v1-tool5, op basis van WebGoat-code met de modellen Codegen25-7b-instruct, qwen2.5-coder-7b en GPT-4, hebben een vermindering aangetoond van ongeveer 18% van het aantal gedetecteerde potentiële kwetsbaarheden, maar dit ging ten koste van een groot aantal oproepen aan het GenAI-model (1130 oproepen per getest CWE-type, voor een basis van 259 Java-bestanden).
Deze nog experimentele tool toont niettemin een meer algemene trend aan om GenAI te integreren in bestaande detectietools. Dit is bijvoorbeeld het geval bij DeepCode van ETH Zürich, dat onlangs is geïntegreerd in de Snyk-software. Het is bedoeld om programmeurs in staat te stellen snel kwetsbaarheden in hun code op te sporen. Maar de convergentie van GenAI -tools die code onderzoeken die door andere GenAI-tools is gegenereerd, creëert feedbackloops die gevaarlijk kunnen zijn[11].
Conclusie en aanbevelingen
Hoewel enkele studies hebben aangetoond dat GenAI eenvoudige problemen met kwetsbaarheden (bijvoorbeeld geheugenlekken) kan oplossen, blijkt dat het systeem moeite heeft met complexe fouten. De meeste studies die we hebben gevonden, tonen ook inconsistente prestaties en een algemene neiging tot hoge percentages valse positieven bij het opsporen van beveiligingslekken, wat door onze eigen tests bevestigd wordt. De beste detectieprestaties lijken te worden bereikt voor kwetsbaarheden waarvoor GenAI is getraind. Deze bevindingen worden bevestigd door een systematische en uitgebreide studie van Basic en Giaretta [12].
Voordat GenAI kan worden gebruikt voor het opsporen van kwetsbaarheden in code, moet er dus nog aanzienlijke vooruitgang worden geboekt. Voorlopig moeten we ons bewust zijn van de huidige beperkingen van deze tools. Naast de eerder genoemde beperkingen kan het, ongeacht de gekozen methode, erg duur zijn om GenAI veelvuldig te gebruiken (of erg traag als het lokaal wordt uitgevoerd zonder de juiste apparatuur). Bovendien ontbreekt het nog aan een solide wetenschappelijke methodologie om verschillende analysetools effectief te vergelijken en de objectieve bijdrage van GenAI te meten.
Bij SMALS is bijvoorbeeld een initiatief ontstaan uit een samenwerking (werkgroep “SAST”6) tussen het team voor toepassings- en projectontwikkeling en het onderzoeksteam. Er wordt gewerkt aan de prestaties van statische analysetools en de mogelijke bijdrage van GenAI.
Ten slotte merken we op dat CodeQL in veel studies wordt genoemd als referentiepunt voor het vergelijken van de doeltreffendheid van GenAI-modellen bij het opsporen van kwetsbaarheden. Dat is niet verwonderlijk, aangezien tools zoals deze hun nut hebben bewezen. Voordat we ons halsoverkop op GenAI storten om de codeveiligheid te verbeteren, is het waarschijnlijk verstandiger om statische of dynamische analysetools geleidelijk te integreren in de gebruikelijke essentiële codebeoordelingen. Ongetwijfeld zal GenAI op een gepast moment in deze tools worden geïntegreerd.
Referenties
[1] S. Elder et al., « Do I really need all this work to find vulnerabilities? An empirical case study comparing vulnerability detection techniques on a Java application », 2 août 2022, arXiv: arXiv:2208.01595. doi: 10.48550/arXiv.2208.01595.
[2] D. Noever, « Can large language models find and fix vulnerable software? », août 2023, [En ligne]. Disponible sur: https://arxiv.org/abs/2308.10345
[3] P. Shojaee, I. Mirzadeh, K. Alizadeh, M. Horton, S. Bengio, et M. Farajtabar, « The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity », [En ligne]. Disponible sur: https://arxiv.org/abs/2506.06941
[4] S. Ullah, M. Han, S. Pujar, H. Pearce, A. Coskun, et G. Stringhini, « LLMs cannot reliably identify and reason about security vulnerabilities (yet?): A comprehensive evaluation, framework, and benchmarks », 24 juillet 2024, arXiv: arXiv:2312.12575. doi: 10.48550/arXiv.2312.12575.
[5] N. Risse et M. Böhme, « Uncovering the limits of machine learning for automatic vulnerability detection », 6 juin 2024, arXiv: arXiv:2306.17193. doi: 10.48550/arXiv.2306.17193.
[6] S. Heelan, « How I used o3 to find CVE-2025-37899, a remote zeroday vulnerability in the Linux kernel’s SMB implementation », Sean Heelan’s Blog. Consulté le: 12 juin 2025. [En ligne]. Disponible sur: https://sean.heelan.io/2025/05/22/how-i-used-o3-to-find-cve-2025-37899-a-remote-zeroday-vulnerability-in-the-linux-kernels-smb-implementation/
[7] T. Claburn, « AI-assisted bug reports make developers bear cost of cleanup », The Register. Consulté le: 14 mai 2025. [En ligne]. Disponible sur: https://www.theregister.com/2024/01/04/aiassisted_bug_reports_make_developers/
[8] C. Jones, « Curl takes action against time-wasting AI bug reports », The Register. Consulté le: 14 mai 2025. [En ligne]. Disponible sur: https://www.theregister.com/2025/05/07/curl_ai_bug_reports/
[9] Y. Li et al., « Everything you wanted to know about LLM-based vulnerability detection but were afraid to ask », 18 avril 2025, arXiv: arXiv:2504.13474. doi: 10.48550/arXiv.2504.13474.
[10] Z. Li, S. Dutta, et M. Naik, « IRIS: LLM-assisted static analysis for detecting security vulnerabilities », 6 avril 2025, arXiv: arXiv:2405.17238. doi: 10.48550/arXiv.2405.17238.
[11] S. Varma, A. Batchu, et N. Tyagi, « Innovation insight: AI code review tools », Gartner, G00834019, juill. 2025.
[12] E. Basic et A. Giaretta, « Large language models and code security: A systematic literature review », 19 décembre 2024, arXiv: arXiv:2412.15004. doi: 10.48550/arXiv.2412.15004.
1 De auteurs geven de voorkeur aan de ‘balanced accuracy’-score boven de klassieke F1-score om beter te kunnen waken over mogelijke vertekeningen in het geëvalueerde model. Deze wordt als volgt gedefinieerd:
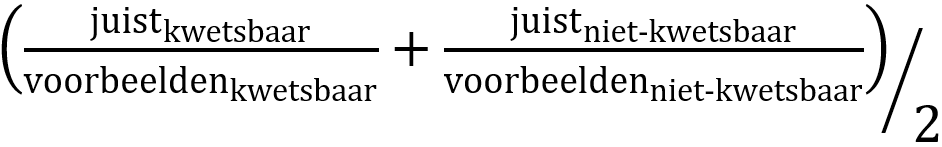
2 Code die als kwetsbaar wordt aangemerkt, terwijl dat niet het geval is.
3 Code die correct als kwetsbaar wordt aangemerkt.
4 Momenteel ondersteunt IRIS alleen de volgende CWE‘s: CWE-022 (path traversal), CWE-078 (injectie van besturingssysteemopdrachten), CWE-079 (cross-site scripting) en CWE-094 (code-injectie).
5 Versie 2 werd gepubliceerd na het schrijven van dit artikel.
6 “Static application security testing”