(Update 4 juillet 2025)
En 2019, nous annoncions un Proof of Concept relatif à la mise en place ultérieure d’un service générique d’ATMS (Anomalies & Transactions Management System). Nous en rappelons ici les principales motivations en termes de Data Quality et de ROI, illustrées sur la base de use cases ainsi que les spécifications fonctionnelles. Nous en développerons ensuite les avancées sur le plan technique et en évoquerons les perspectives de développement ultérieur.
Une approche “Data Quality” préventive avec un ROI potentiellement important
Comme l’illustre la figure 1 ci-dessous, dans toute approche « data quality », lorsque les problèmes de qualité de données sont déjà présents dans les bases (par exemple, présomptions de doubles à droite de la figure), une approche curative doit être menée via un Data Quality Tool.
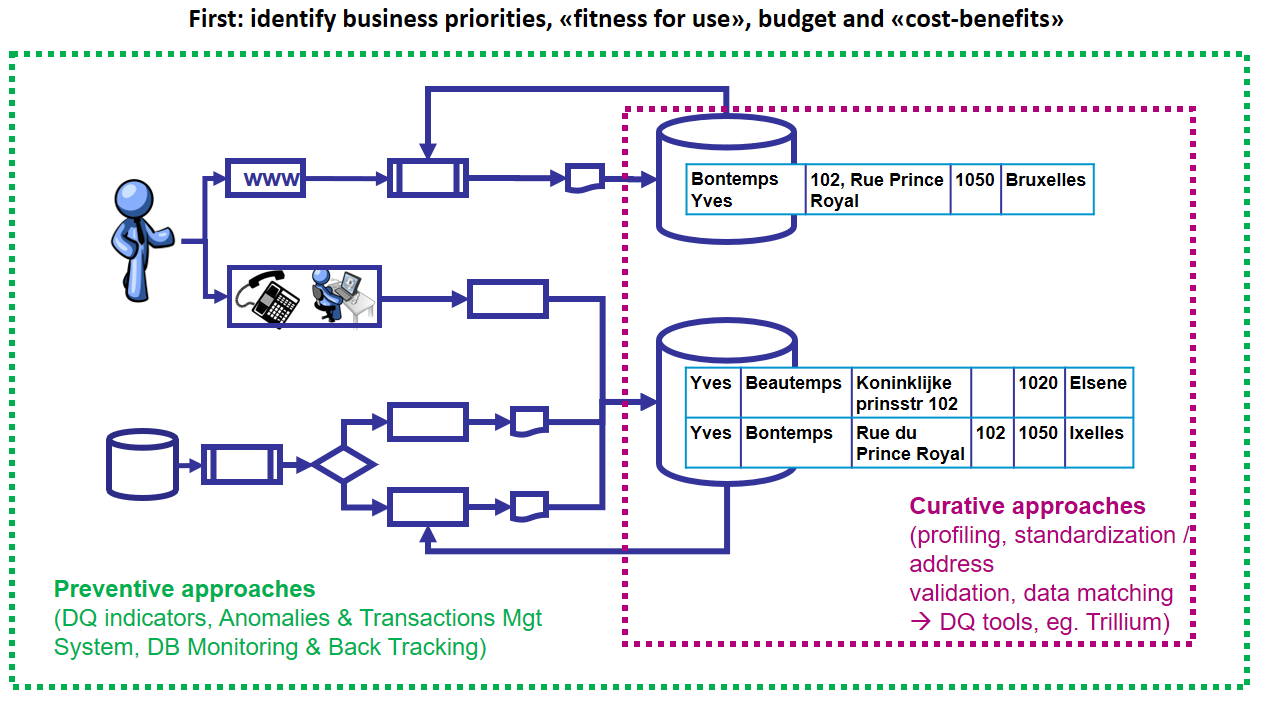
Figure 1. Approches préventives et curatives
Cela dit, si l’on se contente d’agir en aval, les problèmes de qualité vont continuer d’affluer « ad infinitum » comme il proviennent des processus et flux d’information qui alimentent les bases de données ou bien de l’évolution du domaine d’application. Aussi en complément, une approche préventive est-elle indispensable afin de résoudre structurellement à la source les problèmes de qualité.
C’est ce que permet la technique originale du « back tracking » : vu ses bénéfices structurels en terme de diminution de manpower (diminution entre 50% et 80% du manpower dû au traitement des anomalies) et d’amélioration de la qualité des données, celle-ci est passée dans la loi en tant qu’arrêté royal en février 2017 s’agissant des baromètres de qualité appliqués aux secrétariats sociaux agréés belges et de la DmfA.
La base de données LATG (Loon en ArbeidsTijdsGegevensbank) à la fin des années 1990, puis, son héritière modernisée, la DmfA (Déclaration Multifonctionelle – Multifunctionele Aangifte), au début des années 2000 à ce jour, furent les « cas d’étude » privilégiés de l’opération vu leur ampleur stratégique. La DmfA permet en effet actuellement le prélèvement et la redistribution annuels de 65 milliards d’euros de cotisations sociales à l’échelle de la Belgique.
Au sein de celle-ci, le mécanisme d’ATMS est déployé à grande échelle via un DBMS hiérarchique et du code externalisé spécifique associé à un moteur de règles générique. Nous exposons ici une approche en cours de développement sous la forme d’un prototype visant à en élargir le champ d’application à travers la mise en place d’un service d’ATMS générique, applicable à tout DBMS relationnel (RDBMS), tel que PostgreSQL ou Oracle. Celui-ci inclut par ailleurs toute structure de donnée “texte” (JSON, XML, …).
L’ATMS : un socle indispensable pour le “data monitoring” et “le back tracking”
L’opération de « back tracking » évoquée plus haut repose sur un monitoring statistique préalable des anomalies et transactions demandant un ATMS (Anomalies and Transactions Management System). L’ATMS est mis en place après spécification des indicateurs de qualité stratégiques en fonction du domaine d’application. L’opération permet ensuite d’identifier, au sein des processus et flux de données, en partenariat avec le fournisseur de l’information et le gestionnaire de la base, les causes structurelles à l’origine de la production d’un grand nombre d’anomalies systématiques et/ou jugées stratégiques : traitement inapproprié de certaines sources de données, émergence de situations nouvelles, interprétation inadéquate de la législation, erreurs de programmation, etc. Sur cette base, il est possible de poser un diagnostic ainsi que des actions correctrices durables et structurelles (correction de code formel dans les programmes, restructuration de processus, adaptation de l’interprétation d’une loi, clarification de la documentation, …).
Prenons un exemple : avec la mondialisation, de nouveaux cas non prévus initialement dans les tables de références et dans la législation peuvent se présenter à une échelle nationale. Cela peut se produire dans le domaine de l’activité énergétique, à un instant donné, à travers des unités d’exploitation d’entreprises étrangères, comme l’énergie géothermique s’agissant d’énergie renouvelable, … sachant que ce type d’activité est très variable d’un endroit à l’autre du globe (Figure 2).
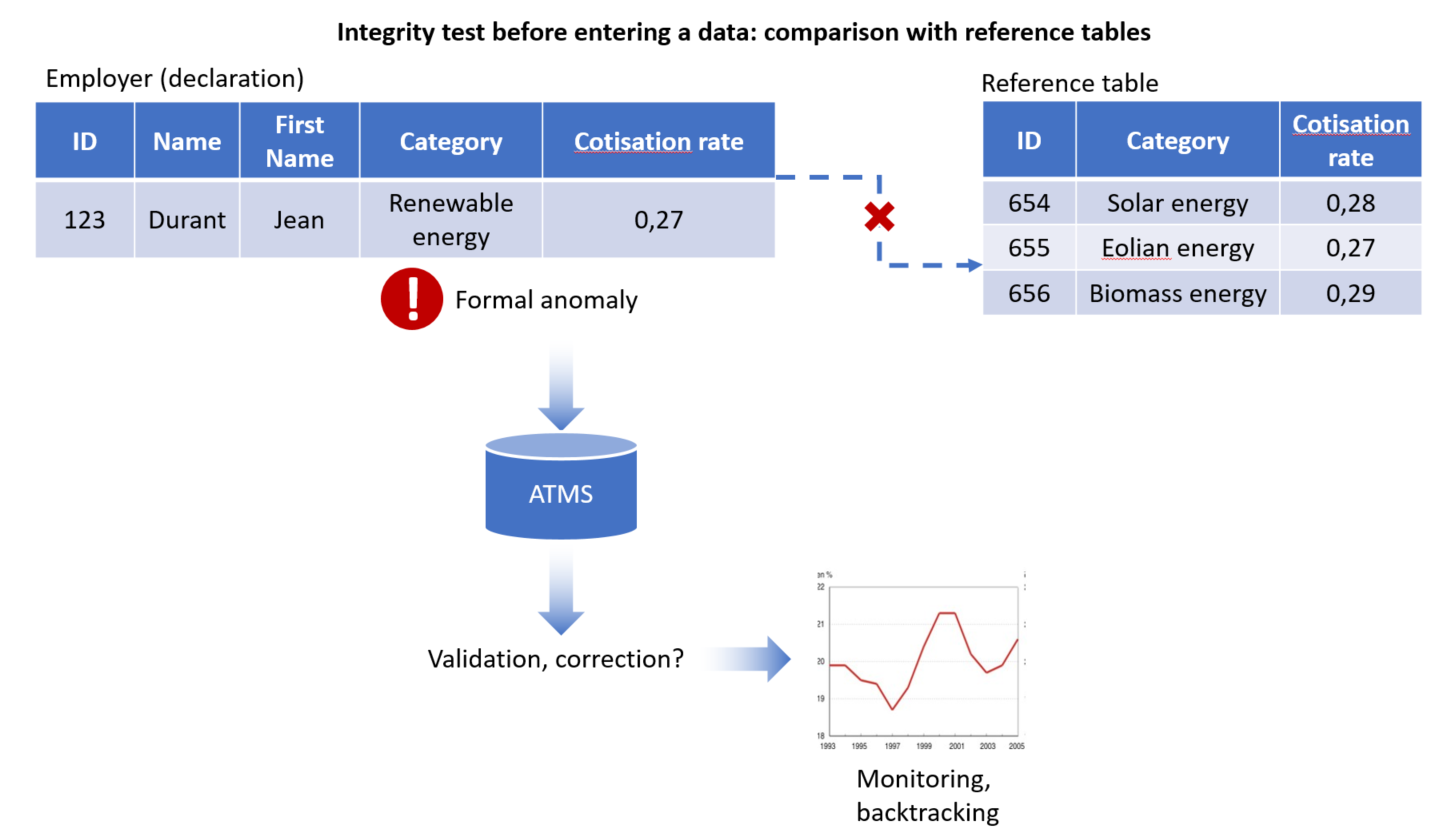
Figure 2. Violation du domaine de définition ou « warning » demandant un monitoring
Dans ce cas, il n’est pas toujours possible de vérifier la correction des valeurs de la base de données de manière automatique. En effet, lorsqu’une incohérence apparaît entre une valeur saisie au sein de la base et les tables de référence permettant d’en tester la validité, il peut s’avérer indispensable, lorsque les enjeux sont stratégiques, de procéder à une vérification intellectuelle, en contactant le citoyen ou l’entreprise concernée, par exemple. C’est là, entre autre, que réside l’intérêt d’un ATMS, en vue d’enregistrer et d’historiser les anomalies et transactions, permettant un monitoring statistique continu de celles-ci et une modification éventuelle du domaine d’application.
L’approche est très efficace car l’expérience montre qu’elle repose sur le principe de Pareto (80/20) : un grand nombre de problèmes peuvent être résolus dès lors qu’on a identifié un petit nombre d’éléments qui en sont la cause.
Les exemples de tels phénomènes abondent dans le secteur administratif. Le 4 mars 2020, la cour de Cassation française a ainsi requalifié en contrat de travail le lien entre Uber et un ancien chauffeur indépendant. Cette décision se propage déjà aux USA en Californie où un procès a eu lieu en août 2020 menaçant directement le géant américain Uber. Sur le plan légal, le régime binaire du travail salarié et indépendant pourrait ainsi être élargi en vue d’assurer la flexibilité mais aussi la protection sociale de ces travailleurs, ce que ne permet pas l’auto-entreprenariat qui exclut le lien de subordination. C’est le cas déjà dans certains pays, commente l’Arrêt, par exemple « … en Italie (contrats de “collaborazione coordinata e continuativa”, “collaborazione a progetto”) ». Outre l’impact législatif, au sein des bases de données administratives, la définition du statut du travailleur risque dès lors d’être peu à peu affectée par ce mouvement, surtout avec la mobilité du travail et la mondialisation. La question est de plus en plus actuelle aux USA et en Europe, dans le cadre du second confinement de fin 2020 où ce secteur est particulièrement mobilisé.
Deux “use cases”
Dans notre approche (le prototype repose sur les « open data » de la KBO), la base de données cliente et l’ATMS sont tous deux accessibles aux agents (techniques et business) qui en ont la charge bien que logiquement séparés (Figure 3).
Le premier use case (Figure 3) montre que, lors d’une saisie par un expéditeur, les données peuvent faire l’objet, selon les choix du business, tant en ce qui concerne les type d’anomalies que les scenarios de détection et de traitement de celles-ci (validation par des « business rules ») :
- D’un rejet ;
- D’un enregistrement dans la base de données cliente ;
- D’un envoi vers l’ATMS, pour correction, et renvoi vers la base de données cliente.
L’ensemble de ces opérations et de leurs caractéristiques sera, nous le verrons plus loin, enregistré et historisé en vue d’un monitoring.

Figure 3. Use Case A. : correction d’une anomalie
Dans le second use case (Figure 4) et dans le même environnement, des enregistrements préalablement validés dans la base de données cliente sont, suite à une interprétation humaine (une inspection, par exemple), jugés inadéquats. Un nouveau cas de figure ayant été découvert, leur traitement demande préalablement une modification de version (passage de la version 1 à la version 2 de l’applicatif et de la base de données) avant qu’ils ne puissent être modifiés via l’ATMS et saisis dans la base cliente.
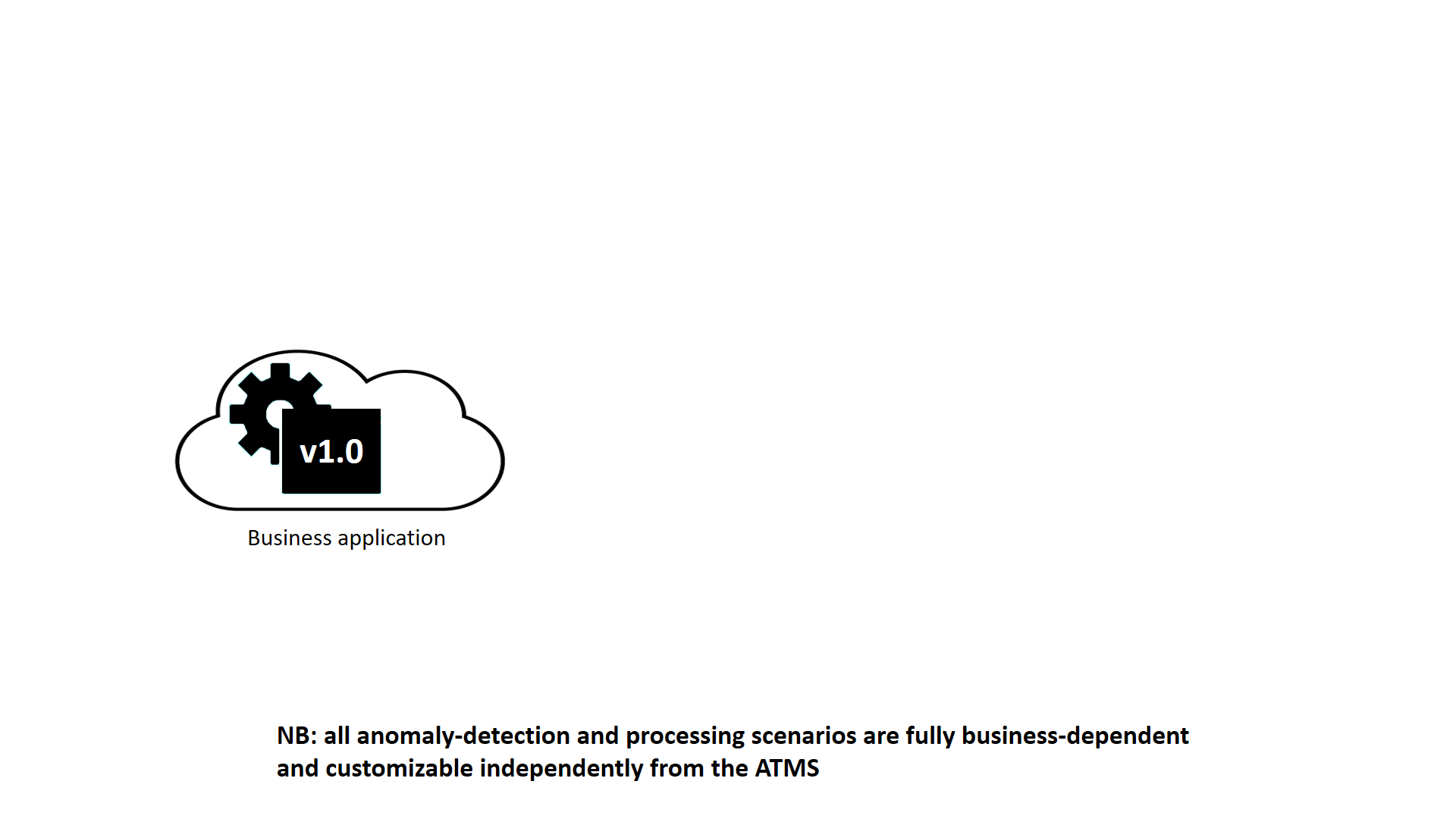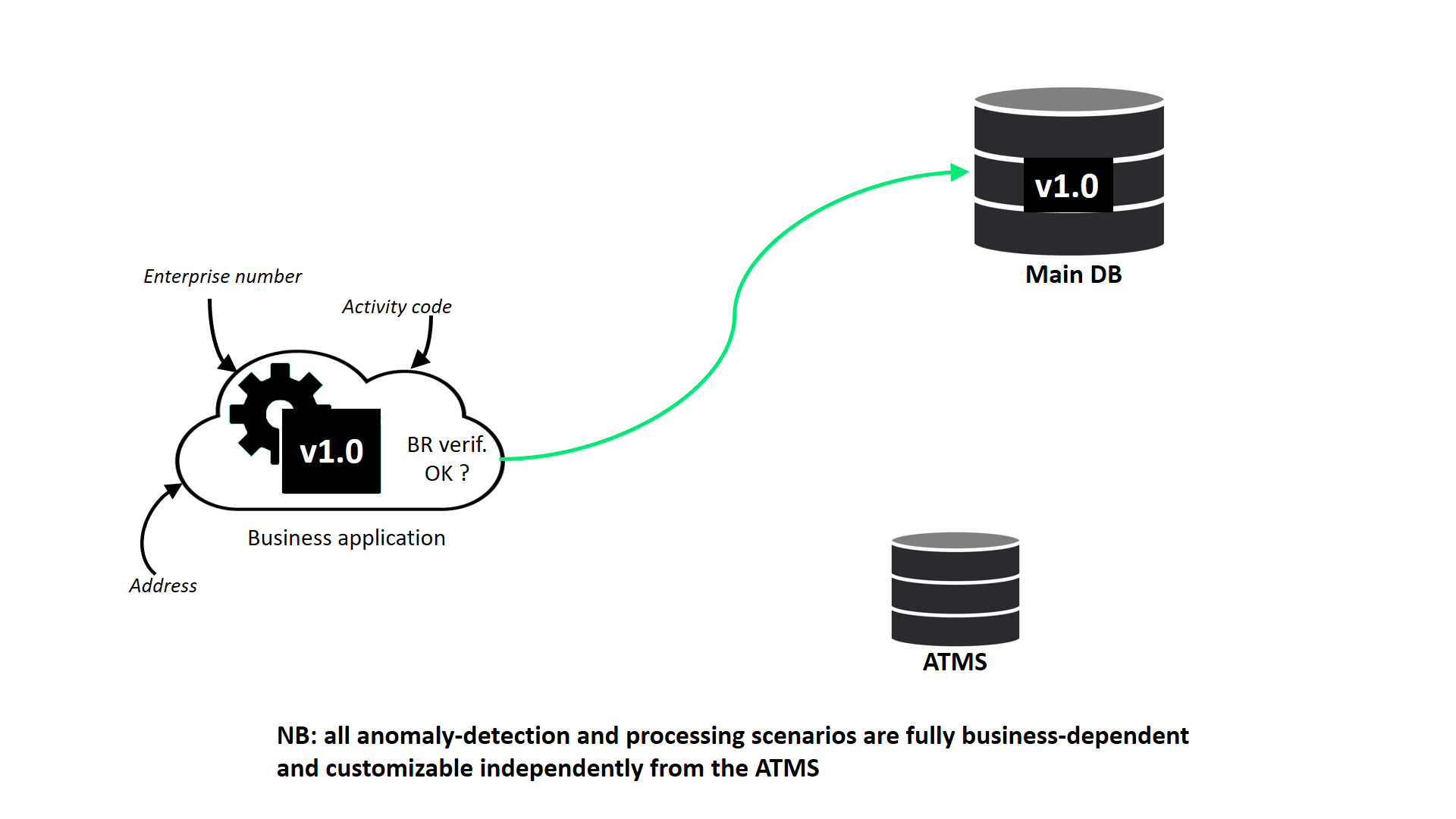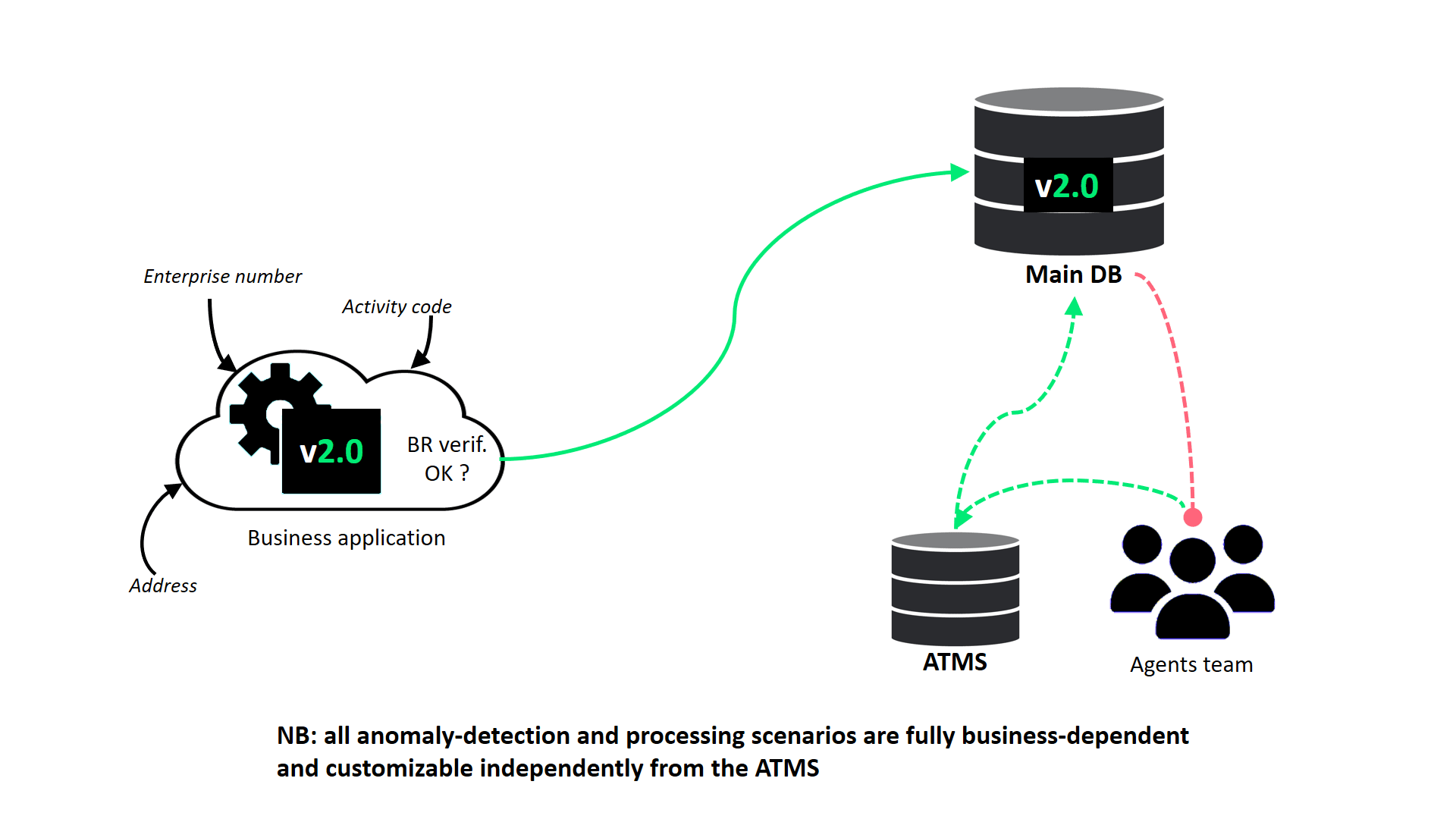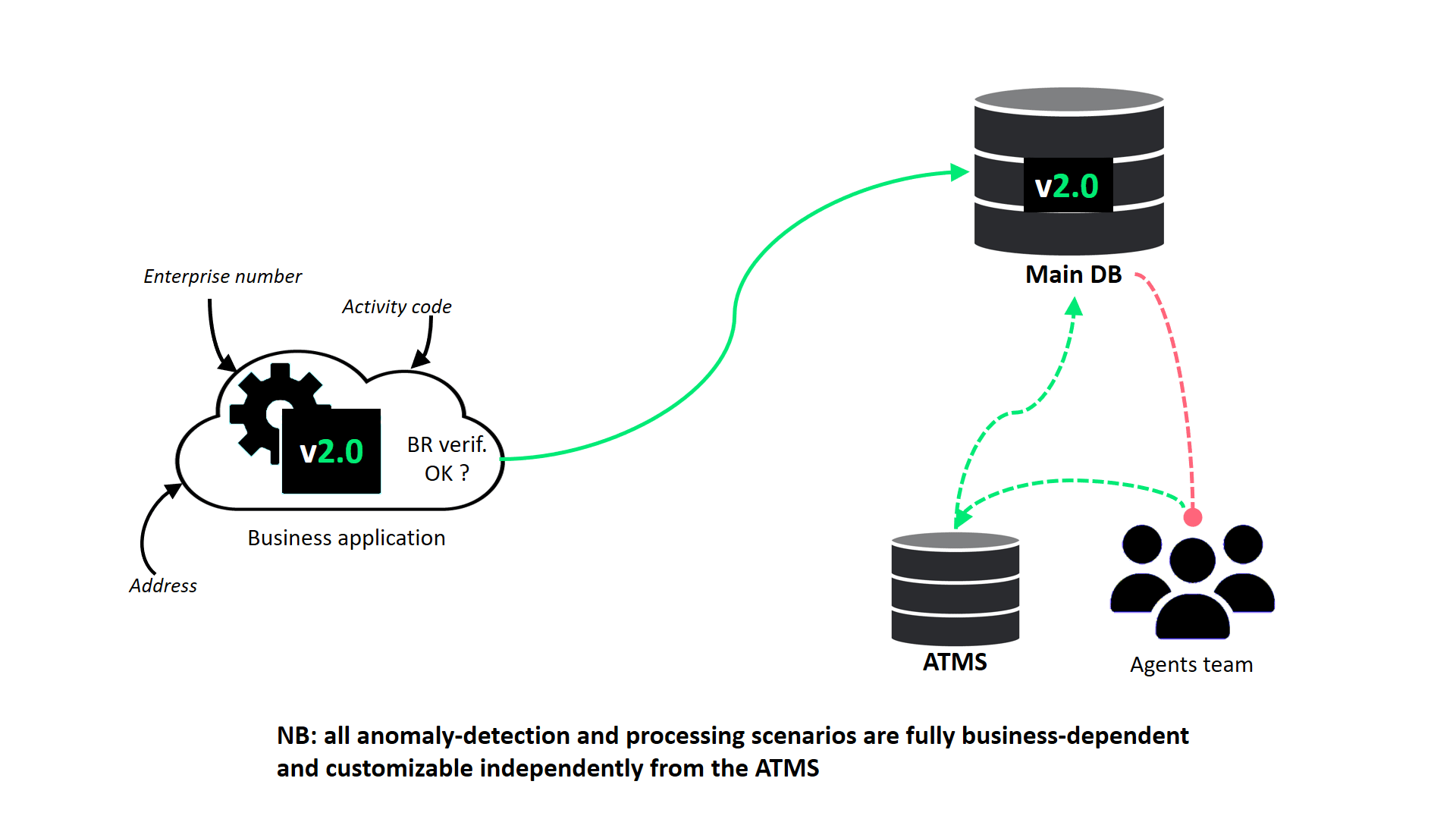
Figure 4. Use Case B. : interprétation et modification d’un record, associés à une nouvelle version du schéma de la base et de l’applicatif (domaine de définition)
L’ATMS est ainsi indispensable en vue de mettre en œuvre la méthode du « back tracking »:
- non seulement pour identifier, via un monitoring continu, les anomalies à prendre en considération (en fonction de leur nombre et des enjeux qu’elles soulèvent) ;
- mais aussi, comme le fondement de solutions structurelles à certains problèmes rencontrés en termes d’interprétation des données (à partir de l’examen des cas de validation correspondants).
L’ATMS permettra également de mettre en place plusieurs mesures continues utiles pour exploiter des sources administratives ou, plus généralement empiriques, à des fins statistiques, par exemple :
- Déterminer le temps de stabilisation de la base de données, au fil du traitement des anomalies spécifiées, en fonction des besoins, et le moment le plus opportun en vue d’en tirer une photographie pour l’exploiter à d’autres fins.
- Identifier les anomalies qui ne seraient jamais traitées (ni corrigées, ni validées).
- Identifier les « pics » d’anomalies et de validations (pouvant potentiellement entraîner quant à elles une restructuration du domaine de définition de la base) ;
- …
Spécifications fonctionnelles
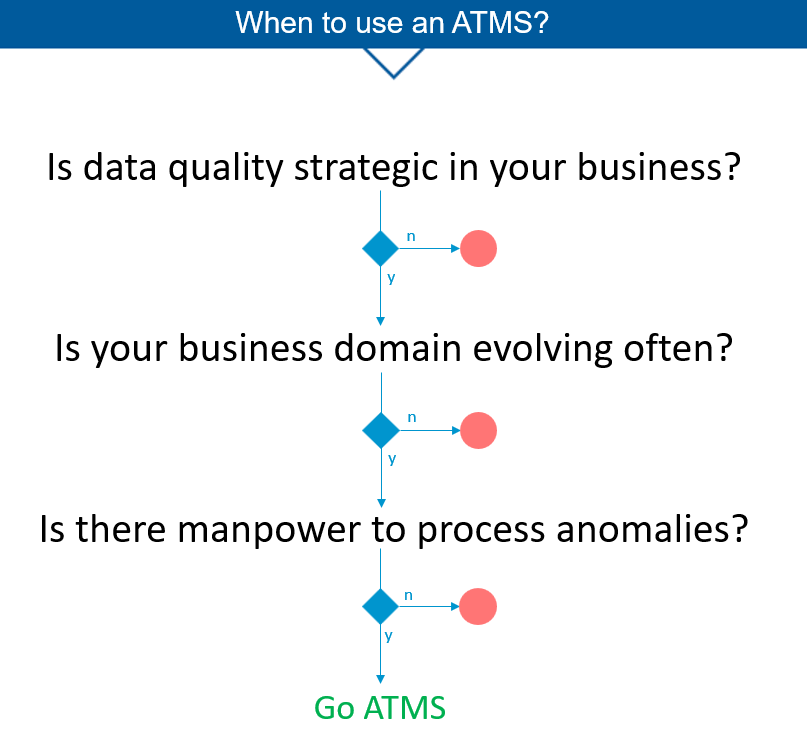
Afin de soutenir cette approche, plusieurs prérequis sont indispensables si les enjeux et les budgets disponibles le justifient (par exemple, il faut disposer de la main d’œuvre intellectuelle requise pour traiter les anomalies), tels que l’identification et la spécification concertées avec les responsables de la base, en vue d’une implémentation ultérieure utile :
- D’anomalies stratégiques: a priori l’approche s’intéresse aux cas systématiques mais elle peut également couvrir un petit nombre de cas « rares » et émergents touchant des types d’anomalies particulièrement sensibles, comme évoqué plus haut.
- De procédures claires et documentées, soutenues par une organisation dédiée incluant les responsables business et IT, quant à leur détection et à leur traitement dans le temps (correction, validation, interprétation d’une valeur en l’absence de toute violation de contrainte d’intégrité, …).
- De procédures claires et documentées de production d’indicateurs de qualité selon une périodicité donnée afin de réaliser un monitoring permettant de supporter la gestion de la base de données face à l’évolution continue des réalités qu’elle traite et de son environnement.
Nous allons maintenant voir comment pratiquement ces éléments peuvent être techniquement traduits sur le plan opérationnel via un prototype d’ATMS.
Les éléments techniques du prototype
L’implémentation du prototype d’ATMS relationnel propose une standardisation de la gestion des anomalies, qui est alors séparée de la base de données cliente (Figure 5).
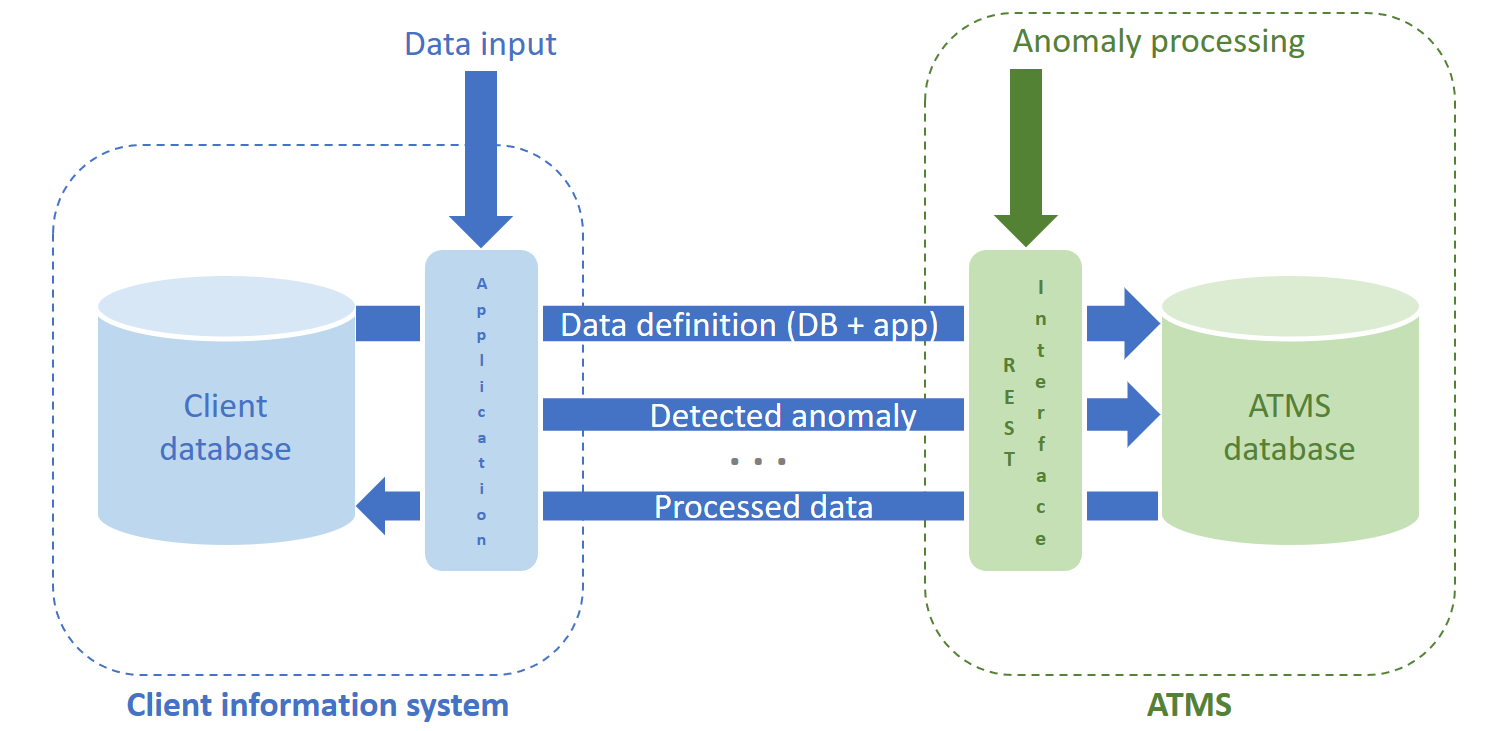
Figure 5. Séparation entre la gestion d’anomalies et la partie cliente (application et base de données métier)
L’application business prend dès lors en charge la détection des anomalies et leur routage vers l’ATMS (Figures 3 et 4) pour traitement. Cette architecture offre une série d’avantages à court et à long terme :
- La modélisation de la base de données cliente se limite à représenter les concepts métier purs, sans l’interférence des anomalies et métadonnées associées.
- Une fois en production, la base de données cliente reste en permanence conforme au domaine de définition et peut évoluer avec lui.
- L’ATMS peut devenir un outil réutilisable auquel la gestion des anomalies et de leurs traitements peut être systématiquement déléguée, réalisant des économies d’échelle et propageant naturellement les bonnes pratiques à travers une organisation.
A cette fin, on trouve au cœur de l’ATMS une DB conçue de manière à s’adapter à n’importe quelle base de données relationnelle cliente ou structure de données en anomalie.
Modéliser l’ATMS
La base de données de l’ATMS est constituée de deux parties essentielles (Figure 6) :
- La description du domaine de définition: cette partie permet de stocker des métadonnées décrivant le domaine de définition, sous la forme du schéma de la base de données cliente (méta-base de données décrivant les tables, colonnes, clés primaires et étrangères, etc. de la base de données cliente) ainsi que de la version de l’application.
- La gestion des anomalies et transactions: c’est ici que sont stockées les anomalies envoyées par l’application, les objets de la base de données auxquels ces anomalies font référence le cas échéant (tables, colonnes concernées), ainsi qu’un grand nombre de métadonnées datées sur le traitement des anomalies (type de traitement tel que correction ou validation, auteur du traitement, résultat, statut de l’anomalie, etc.).
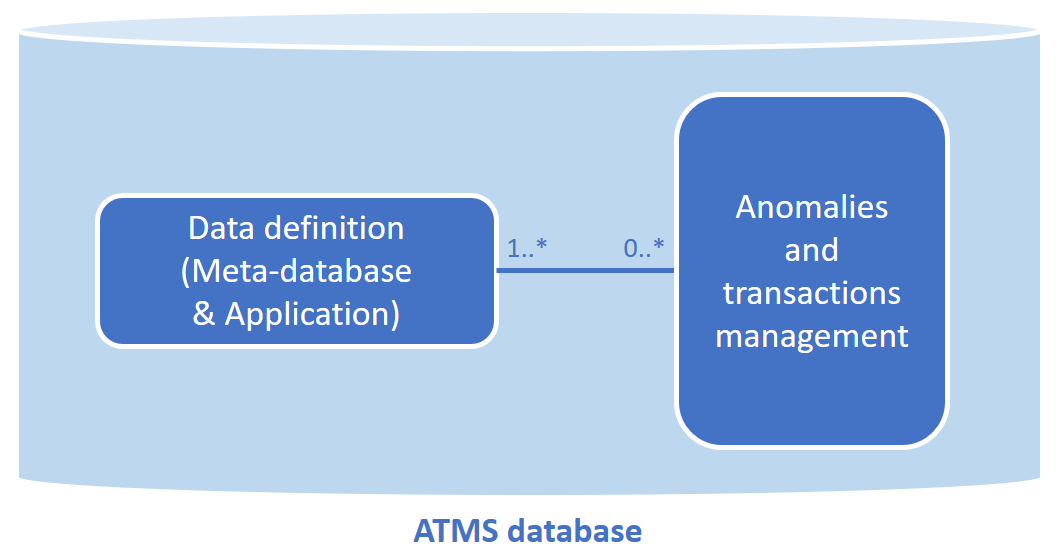
Figure 6. Les deux parties composant la base de données de l’ATMS
Chaque anomalie fait dès lors référence au domaine de définition en vigueur au moment où elle est envoyée dans l’ATMS. Si le domaine de définition est modifié mais que l’anomalie continue d’être en attente de traitement par un agent, elle est automatiquement liée à la nouvelle version du domaine de définition en plus de la précédente.
De ces choix découle un avantage considérable pour la généralisation de l’ATMS : celui-ci peut être intégré à un système d’information sans aucune modification de la base de données cliente à l’exception de l’ajout d’une unique table technique. Celle-ci a pour seul but de permettre à l’application de facilement retrouver l’historique d’un enregistrement de la base cliente à partir de son identifiant business ou de son identifiant d’anomalie.
Devant cette structure interne riche, l’ATMS offre cependant des interfaces techniques simples, permettant par exemple à l’application de faire enregistrer les anomalies arrivant dans le système ainsi que de récupérer le résultat du traitement d’une anomalie par un agent.
Communiquer avec l’ATMS
Dans le cadre du prototype, les interfaces de communication avec l’ATMS ont été implémentées sous la forme de procédures stockées. En pratique, dans un projet grandeur nature, ces procédures prendraient typiquement la forme d’endpoints d’API REST côté ATMS mais également côté client (Figure 7).
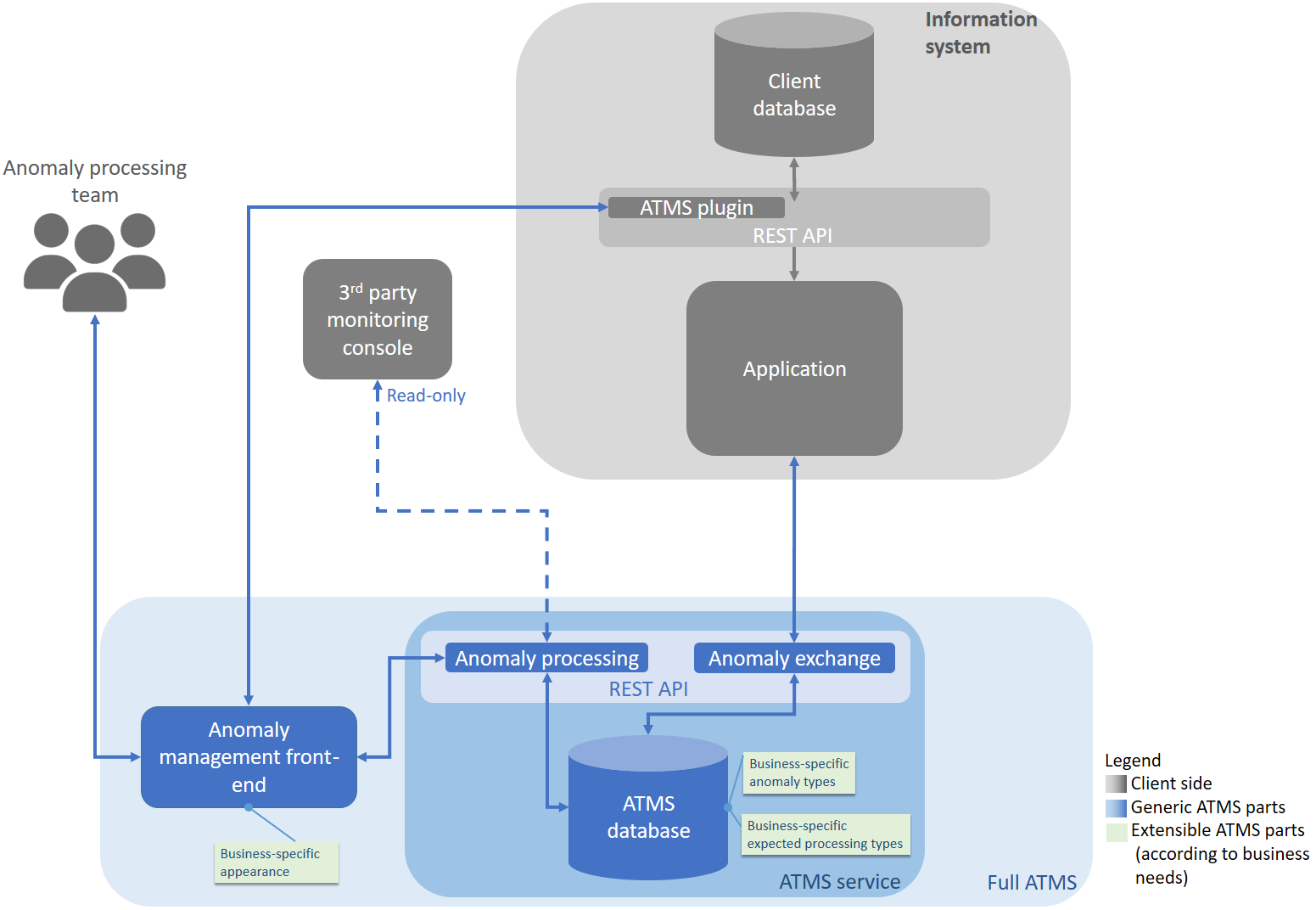
Figure 7. Vue haut niveau de l’architecture d’un système d’information intégrant l’ATMS
Côté client, l’application peut accéder à des fonctionnalités telles que :
- La génération, à partir de la base de données cliente, d’une description de sa structure sous la forme d’un message JSON lisible par l’ATMS.
- Ou encore la création de messages JSON permettant dans un second temps l’enregistrement d’une anomalie avec les données concernées dans l’ATMS.
Côté ATMS, l’interface exerce une double fonction :
- L’échange d’anomalies et de métadonnées : l’interface lit les messages entrants et popule les tables appropriées de l’ATMS, côté domaine de définition ou gestion des anomalies et transactions en fonction des cas. Elle permet également de récupérer le résultat du traitement d’une anomalie par un agent.
- Le traitement des anomalies : l’interface expose des fonctionnalités appelables par un front-end destiné aux agents du business chargés de traiter les anomalies (corriger, valider, …).
Back tracking et ROI
Sur la base du monitoring des anomalies et transactions, il est possible de faire un “back tracking” pour trouver les causes des anomalies prioritaires pour le business et y remédier à la source, de sorte qu’elles ne se reproduisent plus par la suite.
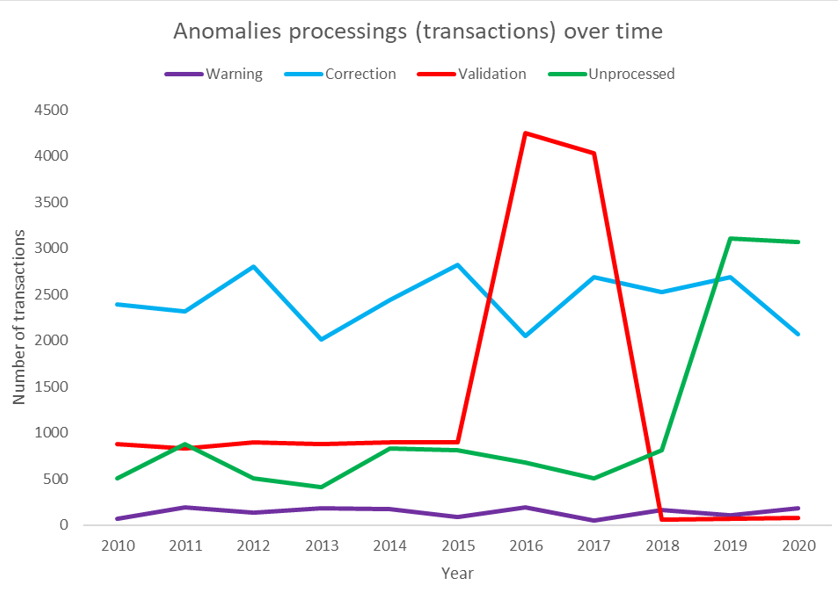
Figure 8. Monitoring du traitement des anomalies
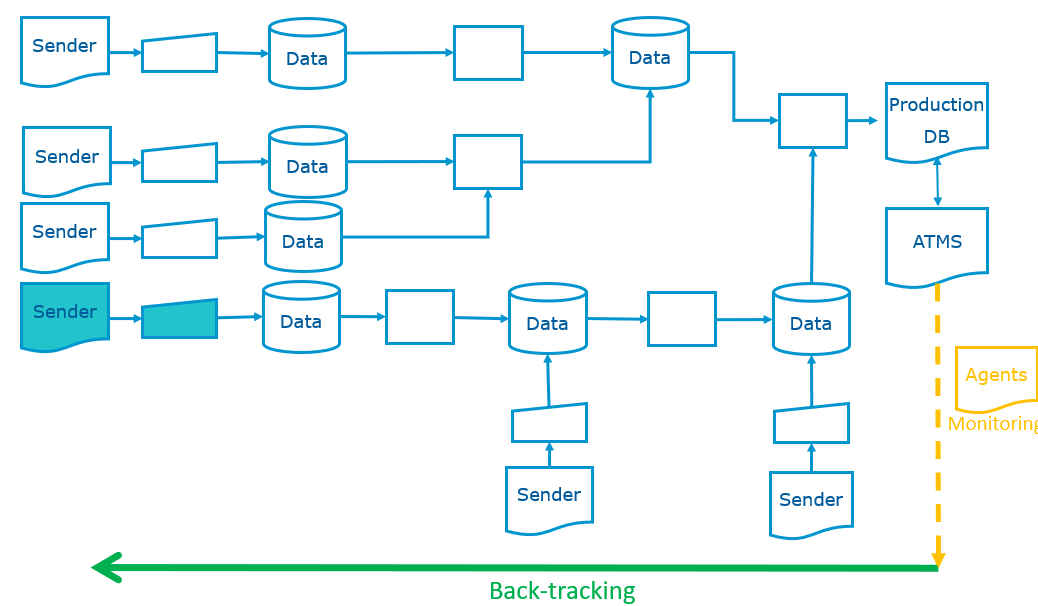
Figure 9. Back tracking sur la base du monitoring : trouver les causes des anomalies les plus importantes dans les processus et les corriger à la source pour que ces anomalies ne se reproduisent plus
Les deux figures suivantes représentent :
- le ROI d’un ATMS couplé à un back tracking qui diminue le nombre d’anomalies et améliore la qualité des données.
- un arbre de décision permettant de savoir si l’on a besoin ou non d’un ATMS pour améliorer la qualité d’un système d’information.
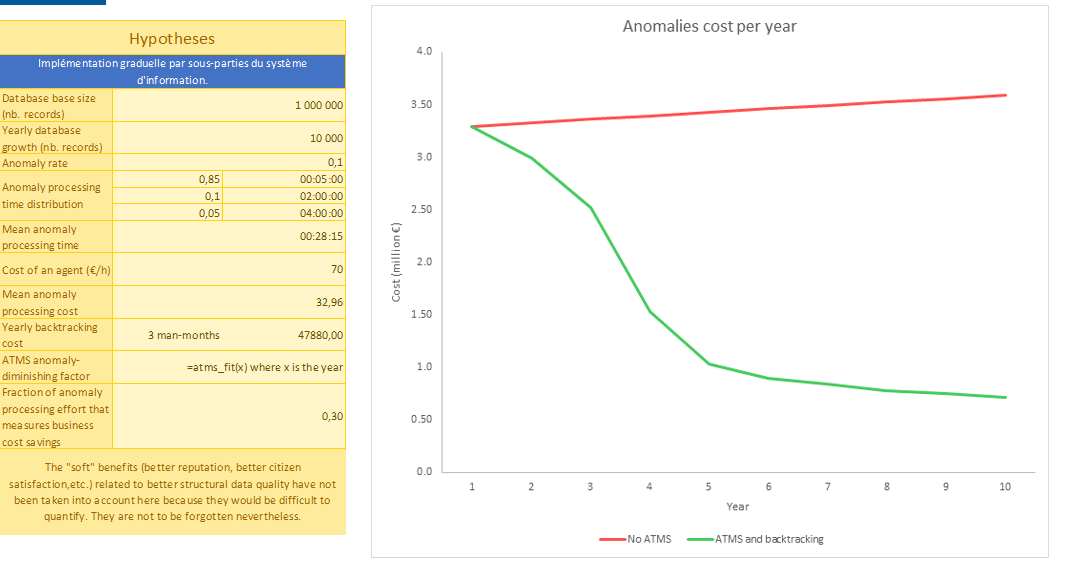
L’ATMS que nous venons de décrire a été implémenté chez Smals par une collaboration entre les équipes de Recherche et Databases. Ce prototype implémente intégralement la base de données de l’ATMS ainsi que les fonctionnalités de génération et consommation de messages JSON au sein de deux bases de données (cliente et ATMS) PostgreSQL. Cependant, n’importe quel RDBMS supportant le traitement de données au format JSON est susceptible de convenir.
Le prototype de l’ATMS a été testé dans le cadre d’un système d’information simulé par une application écrite en Python et une base de données cliente composée de l’intégralité des open data de la KBO. Quatre scénarios d’utilisation réalistes ont été implémentés :
- Correction d’une donnée simple en anomalie.
- Correction d’une anomalie de deux enregistrements incompatibles, l’un déjà présent dans la base de données cliente et l’autre tentant d’entrer dans le système d’information.
- Validation d’anomalies en batch : propagation de la validation d’une anomalie à un lot d’autres, similaires, désignées par un agent.
- Plusieurs vues de monitoring des anomalies et de leur historique, dans le but de guider les back-trackings basés sur un ATMS.
Des liens avec les data quality tools de Smals pourraient également être envisagés. En effet, avec leurs capacités de profiling, standardisation de données (signalétiques notamment, mais pas uniquement) et de matching, ces outils offrent des possibilités techniques pouvant soutenir la gestion humaine des anomalies via un ATMS.
De nombreux contacts ont été pris et sont en cours avec plusieurs équipes-projets qui voient de l’intérêt dans l’utilisation et l’extension progressive de l’ATMS.
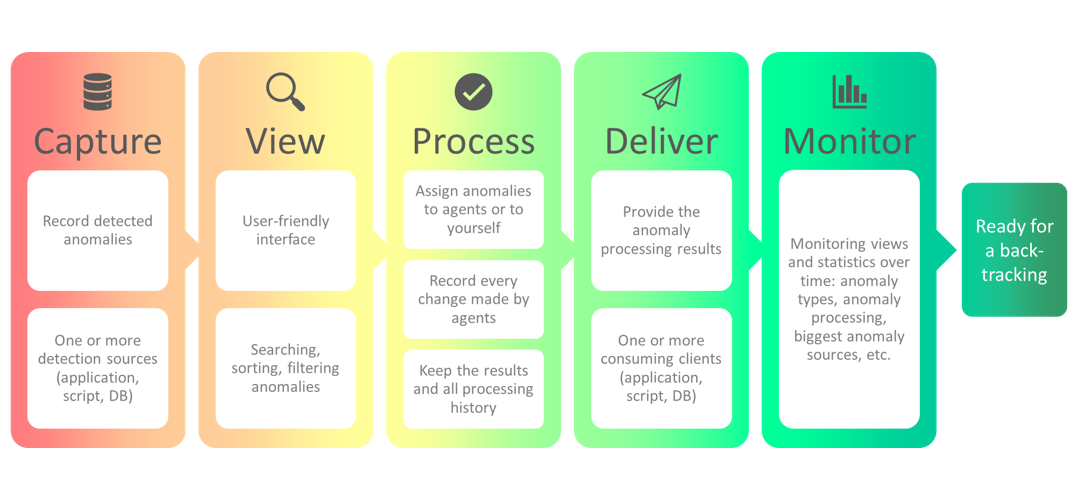
Un développement plus professionnel a suivi (catalogue reuse) et propose les fonctionnalités suivantes :
Ce post est une contribution collective d’Isabelle Boydens, Data Quality Expert chez Smals Research, Gani Hamiti, Data Quality Analyst chez Smals, Databases Team et Rudy Van Eeckhout, Databases R&D chez Smals, Databases Team. Cet article est écrit en leur nom propre et n’impacte en rien le point de vue de Smals.