Telle l’abstraction d’un visage en ses traits saillants, l’esquisse épurée d’un mouvement de la main ou d’une silhouette aperçue dans la rue (I), “La loi (doit être) plus ferme dans ses principes et plus modeste dans ses détails” écrivent en juin 2015 Robert Badinter et Antoine Lyon-Caen dans leur dernier ouvrage paru chez Fayard, “Le travail et la loi“. Ces derniers proposent en substance (Revol M., “Code du travail : plaidoyer pour un choc de simplification”. Le point, 17/06/2015) de “désépaissir le Code du travail passé en France de 600 articles à 8 000 depuis 1974, (selon leurs calculs) et surtout, le simplifier.”
 En effet, “l’extrême confusion des règles, loin de protéger les salariés inclus dans le monde du travail, exclut ceux qui voudraient y entrer. Et effraient les petits patrons, obligés de passer des heures à comprendre ce maquis plutôt qu’à dynamiser leur entreprise. Une dernière phrase, extraite là encore du livre : “Le droit du travail (…) joue contre les travailleurs qu’il est censé protéger.”
En effet, “l’extrême confusion des règles, loin de protéger les salariés inclus dans le monde du travail, exclut ceux qui voudraient y entrer. Et effraient les petits patrons, obligés de passer des heures à comprendre ce maquis plutôt qu’à dynamiser leur entreprise. Une dernière phrase, extraite là encore du livre : “Le droit du travail (…) joue contre les travailleurs qu’il est censé protéger.” 
Cette problématique se pose sous des formes diverses dans de nombreux pays, à l’instar d’un “millefeuille administratif“.
Vu les enjeux en termes de coûts-bénéfices soulevés, tant du point de vue des assurés sociaux, entreprises, employeurs et citoyens, que du point de vue de l’administration, nous approfondissons la thématique cette année. Le but de l’étude est de voir comment la question est traitée en Belgique et dans d’autres pays (secteurs publics et privés), d’en dégager une synthèse, des recommandations pratiques et si possible, de confronter certaines de ces propositions au terrain. Deux posts précéderont la publication d’un rapport de recherche plus complet. Dans cette première partie (Part I), nous avons pour objectif de poser le problème en offrant, sur la base d’exemples concrets et actuels, quelques définitions et un cadre d’analyse global. Dans un second post (Part II.) plusieurs pistes opérationnelles, dont certaines sont déjà esquissées ici, seront approfondies.
Rappelons d’emblée les initiatives passées déjà menées en Belgique dès les années 1990 en vue d’harmoniser et de simplifier la législation. Ces travaux de simplification ont donné le jour à la mise en place de la Banque Carrefour de la Sécurité Sociale (BCSS-KSZ) et à la Déclaration Multifonctionnelle (DmfA). Nous renvoyons à cet égard aux publications de Frank Robben et Pierre Vandervorst (et notamment, sa monographie : “Le paysage informatique comme métaphore” (2011, compte-rendu en FR, pp. 787-790, NL, bl. 783-786).
Enfin, de telles entreprises demandant un suivi continu, signalons le système de quantification (des coûts et bénéfices) administratifs Kafka mis en place par l’Agence de la Simplification Administrative (ASA-DAV) ainsi que, sur le site de cette même agence, la loi “Only Once” du 6 mai 2014 demandant une collecte unique et une réutilisation des données issues de sources authentiques identifiées via une clé unique. Parmi les initiatives en cours, citons enfin le projet de la BCSS en vue de faciliter l’octroi des droits liés au statut social, ce qui implique à terme, l’harmonisation de plusieurs concepts importants, comme la composition de ménage. Cette démarche en cours va dans le sens éthique de l’ouvrage de Badinter et al. paru en juin 2015 et cité au seuil de ce post.
1. Définitions et exemples concrets : nature du droit et des données administratives
 En 1915, le philosophe allemand, Heinrich Rickert a très clairement formulé la question du droit en ces termes : “La justice n’existe que pour se réaliser […] Un principe juridique ne peut être appliqué avant que les phénomènes réels ne lui soient soumis. […] Les principes juridiques […] ne sont souvent liés qu’à des phénomènes transitoires, et il peut arriver que les concepts qui y sont employés, autrefois sans équivoque, ne puissent plus, face à une situation qui s’est transformée, être employés avec sûreté, voire ne soient pas même compris.”(II)
En 1915, le philosophe allemand, Heinrich Rickert a très clairement formulé la question du droit en ces termes : “La justice n’existe que pour se réaliser […] Un principe juridique ne peut être appliqué avant que les phénomènes réels ne lui soient soumis. […] Les principes juridiques […] ne sont souvent liés qu’à des phénomènes transitoires, et il peut arriver que les concepts qui y sont employés, autrefois sans équivoque, ne puissent plus, face à une situation qui s’est transformée, être employés avec sûreté, voire ne soient pas même compris.”(II)
Par nature, le droit est donc empirique, sujet à l’interprétation et à l’évolution dans le temps. Ainsi, le droit se révèle au fil de son application et l’interprétation de la norme juridique interagit avec celle des faits (voir : Boydens I., Informatique, normes et temps, … , partie II, chap 6) (III), par exemple : “Une loi contre le racisme, telle que “The Race Relations Act 1976” ne peut énumérer la liste infinie des actes de discrimination raciale : elle ne peut que déterminer les critères de reconnaissance de cette catégorie d’acte. Il revient alors au juge de décider si le fait, par exemple, d’inscrire “Sorry, no travellers” sur la porte d’un pub constitue une infraction à cette loi […] si l’expression “travellers” désigne les membres d’une race ou simplement des personnes sans domicile fixe.” (IV)
Inversément et dans le même temps, l’interprétation des faits interagit avec celle de la norme, dans le cadre d’une dynamique contextuelle, appelée “cercle herméneutique” (I. Boydens, op. cit.). In fine, une prise de décision et un arrêt sont toutefois rendus, lors de l’application du droit dans les enceintes des tribunaux, par exemple. Aux directives d’interprétation s’ajoutent des “règles de blocage” afin de mettre un terme, implicite ou explicite, à ce processus d’interprétation potentiellement infini. Parmi celles-ci, citons par exemple la séparation des pouvoirs, qui suppose que l’on ne discute pas le bien-fondé d’une loi dans les enceintes des tribunaux, l’enfermement des jurés jusqu’à ce qu’ils s’accordent sur une décision ou encore, la prescription qui limite dans le temps la prise en compte légale des cas à traiter (V).
Deux exemples récents illustrent encore cette dynamique :
- L’harmonisation progressive des statuts d’ouvrier et d’employé en Belgique : la loi entrée en vigueur le 1er janvier 2012, fixe de nouveaux délais de préavis afin de rapprocher le régime des ouvriers et des employés, l’illégalité de la différence de régime selon le statut du travailleur ayant été dénoncée par la Cour Constitutionnelle. Comme l’évoque le cabinet juridique Troxquet – Lambert & partenaires, “La distinction historique entre les prestations intellectuelles et manuelles qui a conduit à distinguer deux statuts avec des régimes très distincts entre ouvrier et employé n’est plus d’actualité. Le travail intellectuel d’un opérateur de machine informatisée n’a plus rien de manuel alors que le travail d’un archiviste ou d’un employé subalterne est beaucoup plus manuel qu’intellectuel dans un travail parfois de routine” (voir aussi : Van Kerrebroeck et al., Harmonisation des statuts ouvriers–employés. Larcier, 2014). On observe naturellement un inévitable décalage temporel entre l’évolution de la norme et celle du réel normé comme le synthétisera le cadre d’analyse général du point 2 de ce post.
- La reconnaissance, par la Cour constitutionnelle allemande le 1er novembre 2013, en plus des sexes masculin ou féminin, d’un troisième genre, à savoir du statut “intersexuel” offre un autre exemple d’évolution juridique. Déjà d’application dans d’autres continents, cette mesure qui met un terme au caractère binaire du genre pourrait, si elle s’étend, avoir un impact considérable, en terme de reengineering au sein des bases de données administratives, entre autres, sur tous les identifiants uniques, comme le numéro NISS en Belgique, au sein duquel, on a commis l’imprudence de coder le sexe de manière binaire, toute démarche d’abstraction impliquant une démarche prévisionnelle, l’identifiant unique doit être idéalement dépourvu d’information porteuse de contenu.
Ceci nous amène à la nature des données administratives (et plus largement, empiriques) :
- dont la gestion doit être d’autant plus rigoureuse (nous renvoyons le lecteur à notre post daté du 16 juin 2014 “Dix bonnes pratiques pour améliorer et maintenir la qualité des données“), de manière à éviter, en connaissance de cause, les syndromes de la “ghost factory” ou “death by silos“.
- dont la cohérence requiert une bonne collaboration entre les instances juridiques, administratives et informatiques; idéalement – et certaines administrations, comme l’Office National de Sécurité Sociale, sont dotées d’un service “ad hoc” – avant la parution de chaque nouvelle loi, une analyse des données existantes est réalisée afin de s’assurer de la pertinence d’éventuelles modifications juridiques et ce, en vue de maintenir la pérennité des concepts génériques abstraits.

Naturellement ces questions s’appliquent à tous les concepts empiriques, sujets à l’interprétation humaine : la structure des systèmes d’information les concernant évolue avec l’interprétation des valeurs qu’ils permettent d’appréhender. De la même manière que la notion de genre a évolué dans le temps, avec l’impact juridique et administratif évoqué plus haut, les bases de données médicales, évoluent avec l’interprétation des maladies et des recherches associées… lesquelles permettent d’identifier de nouveaux faits, qui à leur tour, ont un impact sur la théorie médicale … comme en témoigne PubMed, le site de ressources de la “US National Library of Medecine“. Plus en amont, la codification des unités de mesure évolue sur la base des découvertes scientifiques, lesquelles reposent sur ces mêmes standards… évolutifs au fil des découvertes et des conventions ultérieures entre pays (à propos de la métrologie, on consultera avec intérêt les travaux du Bureau International des Poids et Mesures et les multiples évolutions et débats dont ces standards font l’objet : voir par exemple le rapport du 20 mai 2015 rapportant les échanges du “World Metrology Day” dont le thème était cette année : “Measurements and Light“).

2. Modèle global d’analyse : “temporalités étagées” (ou “stratified time”)
 En vue d’une consolidation des données, le rapport “United Nations E-Government Survey 2014” livre deux enseignements qui nous encouragent à considérer l’importance des interactions et d’une collaboration entre la législation, l’appareil de représentation informatique et administratif et, enfin, la population représentée :
En vue d’une consolidation des données, le rapport “United Nations E-Government Survey 2014” livre deux enseignements qui nous encouragent à considérer l’importance des interactions et d’une collaboration entre la législation, l’appareil de représentation informatique et administratif et, enfin, la population représentée :
- “In some countries, there is a tendency to separate information management and issues related to the application of ICTs from the mainstream of public administration transformation, and this can only cause conflict and inefficiencies“. (p. 81)
- “One of the greatest challenges to promoting effective collaborative governance is that too much emphasis has been placed on interoperability as being merely a technical issue. While technology certainly plays an important role, there are other important factors instrumental to effective collaboration and service integration“. (p. 90)
Ces recommandations nous incitent à partir du modèle en temporalités étagées qui a guidé nos précédents travaux et que nous illustrons ici d’exemples récents.
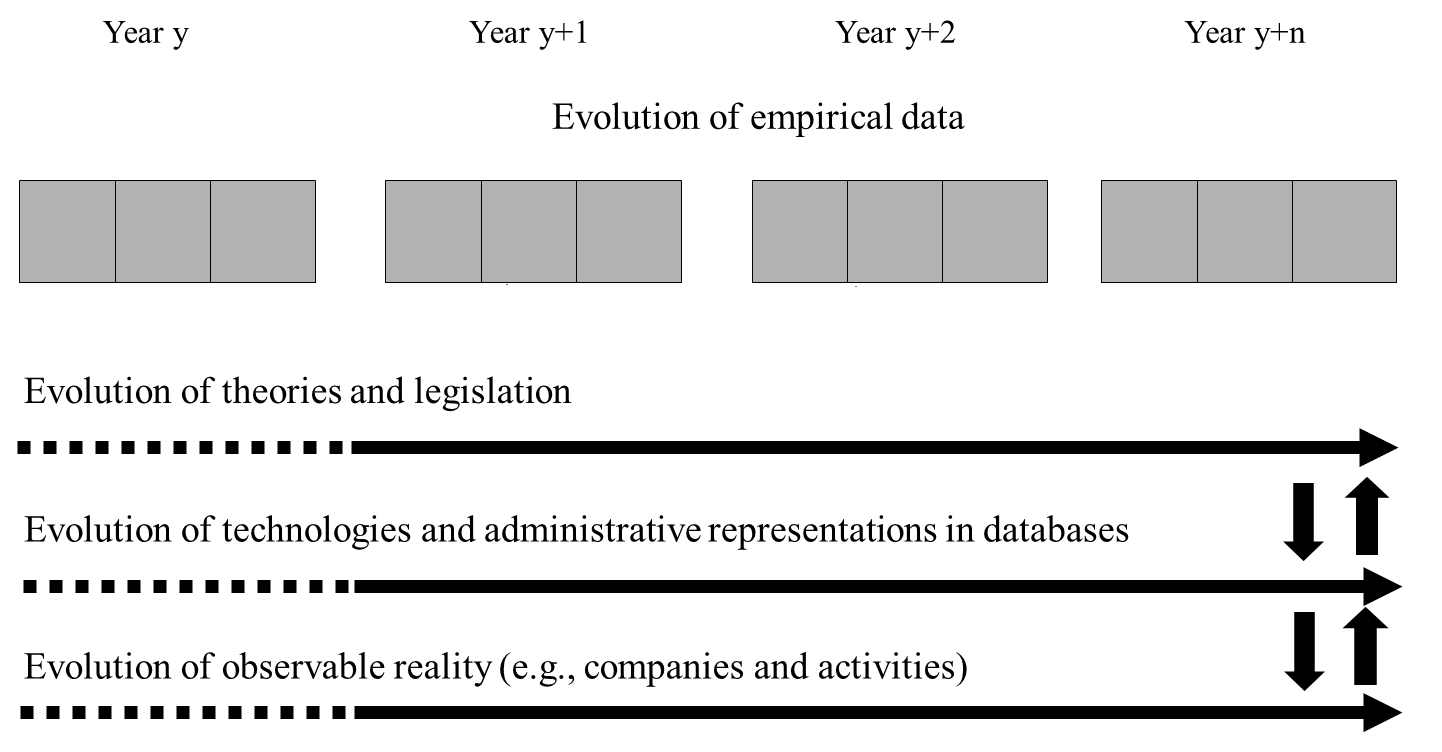
Transformation mechanisms to interpret administrative data (source : I. Boydens, “Strategic Issues Relating to Data Quality for E-government: Learning from an Approach Adopted in Belgium“. In Assar S., Boughazala I. et Boydens I., éds., “Practical Studies in E-Government : Best Practices from Around the World”, New York, Springer, 2011, p. 120.)
Ce modèle, que nous avons proposé pour la première fois dans (Boydens I., “Informatique, normes et temps, … voir III) est cité et développé par David Bade, de l’Université de Chicago, dans sa recension parue en 2011 (VI) et fut récemment appliqué à grande échelle et cité lors de la “Metadata and Semantics Research – 8th Research Conference, MTSR 2014“, qui s’est tenue à Karlsruhe (VII). Nous en rappelons les principales articulations.
Les faits empiriques (sujets à interprétation humaine) doivent être évalués par rapport à un principe unificateur, un horizon de similitude de sens. L’approche herméneutique consiste en une mise en relation sans cesse renouvelée entre les observations et le contexte dans lequel celles-ci s’insèrent. La question du temps est donc centrale. Nous recourrons à deux modèles temporels que nous offre l’herméneutique, la temporalité étagée de Fernand Braudel (VIII) et le continuum évolutif de Norbert Elias (IX).
Le concept de temporalités étagées est une construction permettant d’identifier au sein d’un objet d’étude une hiérarchie entre plusieurs séquences de transformation coexistant. Dans le modèle de Braudel, les séquences relativement les plus rapides (les évolutions politiques, par exemple) sont conditionnées par des séquences relativement plus lentes (comme les évolutions de la géographie et celles du climat). Appliqué à un système d’information empirique, nous avons montré que ce concept clarifiait le processus de construction de l’information : il permet d’identifier plusieurs échelles de transformation inter-agissantes, dont l’évolution est solidaire, mais asynchrone. Par exemple, dans un système d’information administratif, nous pouvons distinguer le temps long de la législation (qui est une théorie normée), évoluant d’un trimestre ou d’une année à l’autre (en témoignent les modifications trimestrielles de la DmfA ou encore, l’harmonisation progressive citée plus haut entre les statuts d’ouvrier et d’employé), le temps intermédiaire de l’appareil de représentation administratif et informatique, dont les transformations s’opèrent d’une semaine ou d’un mois à l’autre (pensons, en 2015, à la mise en place du GCloud et des synergies IT au sein de l’administration fédérale belge) et, enfin, le temps court, celui du réel observable faisant l’objet de la norme et de la représentation informatique et dont l’évolution est quotidienne. Régulièrement, en effet, des entreprises fusionnent ou, au contraire se scindent, d’autres disparaissent, alors que de nouvelles professions ou de nouvelles catégories d’activité non prises en compte par les nomenclatures officielles voient peu à peu le jour, avec, par exemple, la diversification des métiers de l’informatique.
D’un point de vue dynamique, une base de données idéale devrait donc calquer le rythme de ses mises à jour sur la répartition – imprévisible – en temporalités étagées des évolutions de la réalité qu’elle appréhende. À ce qui ressemble à une gageure s’ajoute la nécessité, toujours révélée a posteriori, d’intégrer des observations imprévues a priori interdites par l’hypothèse d’un monde clos (selon laquelle toute valeur violant une contrainte d’intégrité formelle est considérée comme fausse).
Mais la construction temporelle braudélienne doit se traduire par une stratification relative du temps au sein de laquelle les interactions entre séquences de transformation ne sont pas unidirectionnelles. Il arrive en effet que des séquences relativement plus rapides aient un impact sur des séquences de transformation relativement plus lentes, c’est-à-dire que les faits observés aient une incidence sur les théories qui en ont guidé l’observation (nous avons cité, à cet égard, pour le cas de l’Allemagne, sous la pression des groupes concernés (issu du temps court du “réel observé”), la prise en compte d’un troisième genre par la Cour constitutionnelle allemande depuis 2013, ce qui pourrait avoir un impact important pour l’identification des citoyens). Le modèle de Braudel peut alors être complété par le concept du continuum évolutif de Norbert Elias. Celui-ci montre que le temps est une construction résultant de la mise en relation de deux ou de plusieurs séquences de transformations (chaque séquence s’apparentant à un continuum évolutif) dont l’une est normalisée en vue de servir d’étalon pour mesurer les autres. Ce processus de construction lui-même évolutif est intimement lié à l’état du fonds de savoirs dont dispose la société dans lequel il s’insère. En d’autres termes, plusieurs continuums évolutifs coexistent, chacun d’entre eux étant à la fois objet normé et référentiel normatif
Ainsi, par exemple, dans le domaine des bases de données de la sécurité sociale, l’identification de la catégorie d’activité des employeurs est déterminante pour le calcul du taux de cotisations sociales qu’ils doivent payer à l’Etat. En Belgique, comme nous l’avons déjà mentionné, ces cotisations s’élèvent annuellement à 45 milliards d’euros environ. Les enjeux sociaux et financiers sont donc colossaux. Pour catégoriser les employeurs, la législation administrative utilise une nomenclature des activités européennes mise à jour selon une périodicité pluriannuelle. Mais entre chacune de ces mises à jour, la réalité économique ne cesse d’évoluer de manière quasi continue (pensons, par exemple à l’évolution des types d’énergie renouvelable et à la législation les concernant, variable d’un pays à l’autre).
On observe de nos jours le même phénomène de stratification temporelle dans les exemples évoqués au seuil de ce post (médecine et métrologie). En soi, les itérations de la norme aux faits et des faits à la norme sont infinies. Dans notre approche, des critères d’arrêts sont guidés par un principe d’ordre pratique tenant compte des contraintes de budgets : il s’agit d’analyser la nature des arbitrages auxquels sont confrontés les gestionnaires d’un système d’information en vue d’harmoniser la loi (par les instances qui en ont le pouvoir), les normes administratives ou encore d’améliorer le processus de gestion des bases de données en tenant compte des enjeux. A cette fin, nous avons proposé un modèle conceptuel d’identification et de suivi de l’historique des anomalies (violations fictives de contraintes d’intégrité) en vue du déploiement de stratégies de gestion de la base. Il est par exemple possible d’évaluer la rapidité de traitement des anomalies afin de déterminer quel est le moment le plus opportun pour exploiter la base de données ou de détecter non seulement les augmentations anormales du nombre d’anomalies (en fonction d’un seuil donné), mais aussi les augmentations des validations d’anomalies lors de la phase de traitement des données. Une opération de validation signifie qu’après examen, un agent a estimé que l’anomalie, qui est une présomption d’erreur, correspondait à une valeur pertinente. L’opérateur de saisie peut en effet « forcer » le système à accepter ladite valeur. Si le taux de telles validations d’anomalies est élevé et récurrent, la probabilité est grande que la structure de la base elle-même ne soit plus pertinente pour certaines données. Un algorithme émet alors un signal à destination du gestionnaire de la base afin que celui-ci examine si une modification structurelle de son schéma est requise. Lorsque les cas de validations d’erreurs sont importants, il est intéressant d’approfondir le phénomène : comme nous l’avons vu, un cas de figure inédit est peut-être apparu, ce qui requiert une adaptation de la structure de la base. Pour la Sécurité sociale belge, la mise en œuvre de cette méthode a permis d’améliorer la précision et la rapidité du traitement des cotisations sociales en réduisant potentiellement de 50 % le volume des anomalies formelles (qui représentaient jusqu’alors chaque trimestre de 100 000 à 300 000 occurrences nécessitant une gestion manuelle). Nous avons publié, prototype à l’appui, toutes les modalités conceptuelles et logiques d’un tel système dans notre rapport relatif à la gestion intégrée des anomalies de mars 2011.
Dans la suite de cette étude relative à la simplification des données (et notamment dans le post suivant, Part II), nous nous inspirerons encore de la structure en temporalités étagées présentée ci-dessus en vue de situer les interactions entre les différentes solutions opérationnelles.
3. Quelles pistes opérationnelles ? Synergies et collaborations…

Les pistes de solutions en vue de simplifier les données et leur gestion reposent naturellement sur les acquis déjà cités dans les parties qui précèdent. Nous verrons qu’elles peuvent varier selon que l’on se situe au niveau national ou international, dans les secteurs public ou privés :
- au sein du secteur privé, les opérations de simplification peuvent, dans le meilleur des cas, bénéficier d’un management potentiellement plus fort et d’une meilleure gouvernance, le champ d’action étant plus clair et ciblé. Nous avons cité et exposé dans une note de recherche de 2012 (Data Tracking : le “Return On Investment” de l’analyse des flux d’information) :
- les méthodes de “data tracking” appliquées chez AT&T Laboratories aux USA ainsi que le ROI du “reengineering” qui en a découlé (les gains financiers de l’opération furent évalués aux deux tiers du montant antérieurement consacré au traitement de l’information : gain en temps de traitement, en manpower et en montant facturé). Naturellement, la firme AT&T disposait en terme de management d’un pouvoir important pour contraindre tous ses partenaires à un reengineering et à une harmonisation complète de leurs bases de données.
- Nous avons appliqué à méthode à une base de l’ONSS en l’adaptant (voir rapport supra) et le ROI qui en a résulté est important également : diminution des anomalies et du manpower en terme de temps de correction au sein des institutions et chez les expéditeurs de l’information (de 50 % à un facteur 20 dans des opérations stratégiques et ciblées), sans compter les gains qualitatifs en terme de crédibilité, de qualité et de justice sociale. Toutefois, dans le secteur public, il est plus complexe, voire impossible, d’avoir une approche holistique, pour des raisons de management et aussi d’échelle (une application à l’échelle nationale est impensable, à ce stade).
- Dans le même ordre d’idée, lors d’un séminaire IT Works (Integratie-Oplossingen in de Praktijk:Vandaag en Morgen, 21 Mei 2015), Colruyt Group (qui inclut en Belgique non seulement Colruyt mais aussi Laagste Prijs, Spar, Dreamland, Dreambaby, Bio-Planet, …) faisait état d’une gestion très contrôlée en terme de gouvernance, de Product Information Management (PIM) et de charge back vis à vis du business, tout en devant faire face aux évolutions légales et au risque de “death by silos“, en cas de défaut de gouvernance. Il sera utile de s’inspirer d’initiatives de ce type, comme nous l’avons fait pour le “data tracking”.
- dans le secteur public, au plan national :
- nous avons cité pour la Belgique (voir supra) plusieurs grandes initiatives d’harmonisation réalisées par le passé ainsi que les projets en cours en 2015.
- le plus souvent, à côté de ces vastes initiatives, (comme dans le cas de l’harmonisation des régimes ouvriers et employés), on parle plus couramment de “consolidation“, c’est-à-dire qu’on harmonise ponctuellement à l’occasion d’une refonte législative ou d’une obligation légale.
- par ailleurs, nous avons évoqué l’importance du partenariat entre le niveau législatif et le niveau administratif et IT (les deux premières séquences de la temporalité étagée) :
- en donnant l’exemple d’une cellule, au sein de l’ONSS en contact permanent avec les développeurs afin de maintenir la cohérence de l’évolution des concepts administratifs.
- il serait souhaitable qu’une collaboration plus étroite existe, dans l’autre sens, entre les initiatives de synergie IT (Gcloud, mutualisations technologiques) et les projets d’harmonisation administratifs comme la loi “Only Once” de 2014 et d’autres projets de consolidation législative.
- la cohérence des données (ou même leur simplification) peuvent être facilitées également par un système de Master Data Management, analogue aux glossaires de la sécurité sociale (avec workflow de validation, historique, gestion des version, …), cette documentation étant par ailleurs diffusée aux citoyens concernés (troisième strate temporelle du modèle temporel).
- enfin, nous avons rappelé (post cité au point 2 supra) les grands principes en vue d’améliorer et maintenir la qualité des données, dont le recours aux Data Quality Tools, s’inscrivant dans un service plus large dont Smals dispose.

- dans le secteur public, au plan international et européen :
- pour certains postes, l’harmonisation est devenue une obligation sur de nombreux plans, au niveau monétaire, par exemple. L’actualité nous montre toutefois régulièrement combien cette harmonisation est complexe : en témoignent les vifs débats autour de la législation bancaire ou de l’espace Schengen.
- il existe de nombreuses recommandations en vue de proposer une meilleure interopérabilité (plateformes, standards génériques de type “linked data“, …) : ainsi lors de l’UE Semantic interoperability conference qui s’est tenue à Riga ce 5 mai 2015, dans le cadre du programme européen ISA (interoperability solutions for European public administrations, businesses and citizens). Toutefois, les efforts pour les appliquer réellement dans chaque contexte national ne sont pas négligeables et demandent souvent une adaptation “sur mesure”.
- Il sera utile de voir dans quelle mesure un partenariat “public – privé” peut s’avérer réaliste, sur la base des précédents en la matière. Ainsi, lors de la conférence de Riga, un représentant de Gartner a donné une conférence faisant état de nombreux points communs entre les systèmes d’information des différents secteurs, insistant notamment sur :
- l’importance du “knowledge management” : “If only HP knew what HP knows, we would be three times more productive“;
- la nécessité de commencer par des “quick wins” et de s’adapter aux moyens disponibles : “Follow the money : do what you can and not what you want”…
L’ensemble de ces pistes seront approfondies et exemplifiées dans un prochain post. En conclusion, retenons à ce stade, dans une perspective de “data simplification“, que ces solutions devront reposer sur une méthode d’abstraction et de gestion des données poursuivant un double objectif :
- prendre au mieux en compte les évolutions pertinentes issues des interactions entre les différents niveaux de la dynamique en temporalité étagée (nouveaux phénomènes issus du réel observable, obsolescence de certaines lois au regard de l’état du réel observable à un instant t, notamment à travers une gestion adéquate de l’historique des anomalies (voir points 1 et 2, supra);
- exploiter cette même dynamique pour renforcer les synergies et éviter l’émergence inutile de définitions hétérogènes pour un même concept tant au niveau législatif qu’au niveau “data”, sur les plans administratifs et IT.
***
Références complémentaires aux liens figurant dans ce post
(I) Croquis réalisés par Clara Leclercq, 2014.
(II) Rickert H., Théorie de la définition. Paris : Gallimard, 1997, pp. 238-239 (édition originale : “Zur Lehre von den Definition”, 1915).
(III) Boydens I., Informatique, normes et temps. Bruxelles : Bruylant, 1999, 570 p. (Cet ouvrage s’est vu décerner le prix de la Fondation L. Davin, conféré par l’Académie Royale des sciences, des lettres et des beaux-arts de Belgique, 1999).
(IV) McEvoy S., La question de l’arrêt : le cas de l’argumentation dans le droit. In Bourcier D. et Mackay P., éds, Lire le droit. Langue, texte, cognition. Paris : Librairie Générale de Droit et de Jurisprudence, 1992, p. 185.
(V) Huet J., Droit, informatique et rationalité. In Droit et informatique. L’hermine et la puce, Collection F. R. BULL. Paris : Masson, 1992, p. 83.
(VI) Bade, D.: It’s about Time!: Temporal Aspects of Metadata Management in the Work of Isabelle Boydens”. Cataloging & Classification Quarterly 49(4), 2011, pp. 328–338.
(VII) Radio E., “Information Continuity: A Temporal Approach to Assessing Metadata and Organizational Quality in an Institutional Repository“. In Closs S. et al., éds, Metadata and Semantics Research – 8th Research Conference, MTSR 2014, Karlsruhe, Germany, November 27-29, 2014. Proceedings, Springer, pp. 226-237.
(VIII) Braudel, F., La Méditerranée et le monde méditerranéen à l’époque de Philippe II, Paris, Armand Colin, 1949.
(IX) Elias N., Du temps, Paris, Fayard, 1996.
Leave a Reply