De fenomenale ontwikkeling van machine learning (ML) technieken en, meer in het algemeen, kunstmatige intelligentie (AI) [1], lijkt de laatste jaren haar hoogtepunt te hebben bereikt met de komst van generatieve AI (“Generative AI (GenAI)”) en het emblematische ChatGPT1. Ondanks de vele beperkingen van deze technologieën en de risico’s die ze met zich meebrengen [2], [3], zijn er op veel gebieden positieve toepassingen (bijv. zoekmachines, automatische vertaling, automatische annotatie van afbeeldingen, enz.). We kunnen ons dan ook afvragen wat deze technologieën kunnen bijdragen aan cybersecurity.
In feite hebben cybersecurity experts niet gewacht op de komst van generatieve AI om AI-technieken te gebruiken. Maar op het gebied van cyberbeveiliging, zoals vaak het geval is met andere technologieën, wordt de toepassing van AI vaak gezien als een tweesnijdend zwaard in die zin dat het kan worden gebruikt voor zowel aanval als verdediging: aan de ene kant maakt AI het mogelijk om steeds geavanceerdere aanvallen te ontwikkelen, en aan de andere kant om effectievere reacties op aanvallen te bieden, zoals verbeterde detectie van bedreigingen en anomalieën en operationele ondersteuning voor beveiligingsanalisten [4].
De invoering van aanvallen met behulp van AI zou zelfs, volgens Renault et al. [5], een nieuw tijdperk openen in de beveiligingsrace met bekende en onbekende transformaties van aanvalsvectoren. Hoewel er geen twijfel over bestaat dat tegenstanders generatieve AI zullen gebruiken of reeds gebruiken om realistischere en effectievere phishingmails te ontwerpen of om zich voor te doen als andere gebruikers, is het helemaal niet duidelijk of ze generatieve AI zullen kunnen gebruiken om geavanceerdere aanvallen uit te voeren of zelfs om nieuwe aanvalsklassen te creëren.
Hoe dan ook, ondanks mogelijke verbeteringen zou de wildgroei aan aankondigingen over AI op het gebied van cyberbeveiliging (Crowdstrike2, Google3, Microsoft4 en SentinelOne5 hebben bijvoorbeeld onlangs het gebruik van generatieve AI in hun beveiligingsproducten aangekondigd) tot grote teleurstellingen kunnen leiden. Deze teleurstellingen kunnen nog worden verergerd door het feit dat de prestaties of nauwkeurigheid van cyberbeveiligingssystemen niet over de hele linie zijn gestandaardiseerd. Hierdoor wordt het moeilijk om verschillende systemen te vergelijken, er rijzen dan ook vragen als: “Wat is de beste manier om verschillende cyberbeveiligingssystemen te evalueren, te configureren of te vergelijken?” of “hebben we een universele methodologie om robuustheid en prestaties in alle of in verschillende scenario’s te beoordelen?” [6] of “Zou een systeem dat goed presteert op de gegevens van de fabrikant ook goed presteren op mijn eigen gegevens?” Meer prozaïsch, “wat zit er echt achter de term kunstmatige intelligentie wanneer deze wordt gebruikt in combinatie met cyberbeveiligingsproducten?”
Het antwoord op deze laatste vraag is verre van voor de hand liggend, gezien het grote aantal zeer verschillende technieken dat bij AI komt kijken. In het vervolg van dit artikel beschrijven we kort wat er achter de term “kunstmatige intelligentie” schuilgaat door een aantal basistechnieken te beschrijven die worden gebruikt in cyberbeveiliging. In volgende artikelen bespreken we het mogelijke gebruik van deze technieken voor zowel aanval als verdediging in de context van cyberbeveiliging.
Belangrijkste technieken voor machinaal leren
In de afgelopen tien jaar heeft machine learning aanzienlijke vooruitgang geboekt op een aantal verschillende gebieden, te beginnen met zogenaamde supervised modellen (de machine krijgt de klasse elementen die hij moet leren, bijvoorbeeld of een bepaalde transactie frauduleus of onschuldig is), dan unsupervised (de machine moet zelf de verschillende klassen ontdekken op basis van de gegevens), dan reinforcement learning (de machine krijgt een vorm van beloning als hij informatie correct classificeert). Figuur 1 toont de belangrijkste algoritmen voor machinaal leren die worden gebruikt in cyberbeveiliging.
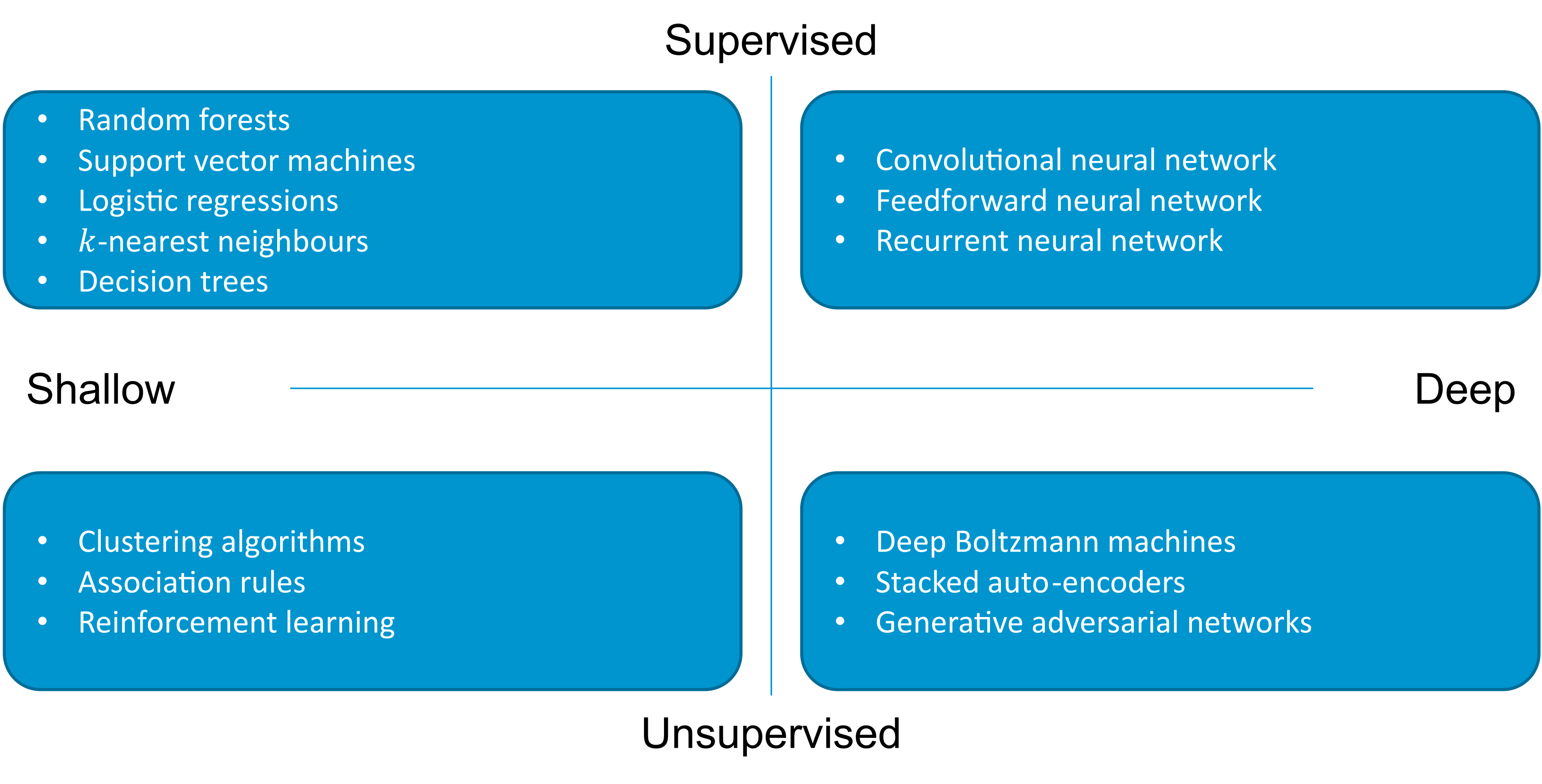
Figuur 1 – De belangrijkste algoritmen voor machinaal leren die worden gebruikt in cyberbeveiliging (volgens [7]).
Supervised learning
Modellen voor supervised learning worden getraind op gelabelde gegevens, d.w.z. voor elk item in de trainingsdataset wordt een categorie opgegeven. Een categorie kan binair zijn (bijv. “aanval” of “onschuldig”) of meervoudig (bijv. type aanval). Dit vereist kostbaar handmatig werk om de gegevens vooraf te categoriseren. Voor een cyberbeveiligingssysteem betekent dit bijvoorbeeld dat analisten elk stuk gegevens categoriseren dat ze hebben geanalyseerd, met de extra moeilijkheid dat er over het algemeen weinig voorbeelden van aanvallen zijn in vergelijking met de andere voorbeelden.
Leren bestaat dan uit het ontdekken, uit de gelabelde gegevens, van de kenmerken die geassocieerd worden met elke categorie en het bouwen van een model dat met een bepaalde waarschijnlijkheid kan vaststellen tot welke categorie een nieuw element behoort dat nog nooit gezien is tijdens het leren.
Deze gesuperviseerde systemen kunnen echter niet worden gebruikt om aanvalstypen te detecteren die hun nog niet bekend zijn. Sterker nog, hoewel supervised learning bijzonder goed werkt voor het herkennen van objecten in afbeeldingen, levert de detectie van cyberbeveiligingsbedreigingen bijzondere problemen op. Inderdaad, zoals opgemerkt door Apruzzese et al. [8], een sample die in de ene context als kwaadaardig wordt bestempeld, kan in een andere context onschuldig zijn, een sample kan speciaal zijn gemaakt om op een onschuldig sample te lijken, of een sample die vandaag als onschuldig wordt bestempeld, kan morgen gevaarlijk blijken te zijn.
Voorbeelden van algoritmen voor supervised learning zijn: decision trees (DT), random forests (RF), naïeve Bayes-classificatie6, neural networks (NN)7, support vector machines (SVM), etc.
Unsupervised learning
Algoritmen voor unsupervised learning leren daarentegen informatie en maken groepen op basis van alle trainingsgegevens, zonder de categorie van elk gegeven te kennen. Het verschil tussen supervised learning en unsupervised learning is dat de laatste geen categorielabels in de trainingsgegevens heeft.
Voorbeelden van algoritmen voor unsupervised learning zijn algoritmen die samples van hetzelfde type proberen te groeperen, zoals k-means partitionering en k-nearest neighbours (k-NN). Naast clusteren is het meer recente gebruik van auto-encoders een vrij populaire techniek voor het detecteren van anomalieën en, in het bijzonder, inbraken (bijv. [9]).
Een auto-encoder bestaat uit een inputlaag (encoder), verschillende verborgen lagen en een outputlaag (decoder). Het doel is om een gecomprimeerde representatie van bepaalde invoergegevens te leren. De encoder wordt gebruikt om de invoergegevens in kaart te brengen in een verborgen representatie, de decoder wordt gebruikt om de invoergegevens te reconstrueren uit een dergelijke representatie. Een encoder kan worden getraind met goedaardige gegevens om een normale voorstelling van het verkeer op een netwerk te leren. Vervolgens wordt tijdens de detectiefase een sample als abnormaal beschouwd als de reconstructiefout na codering groter is dan een bepaald niveau.
Semi-supervised learning
Semi-supervised learning is gebaseerd op zowel gelabelde als ongelabelde gegevens. Het benut efficiënte classificeerders die kleine hoeveelheden gelabelde gegevens nodig hebben door gebruik te maken van informatie verkregen uit grote sets ongelabelde gegevens. Veel onderzoekers hebben geconstateerd dat ongelabelde gegevens, indien gebruikt in combinatie met een kleine hoeveelheid gelabelde gegevens, de leernauwkeurigheid aanzienlijk kunnen verbeteren in vergelijking met unsupervised learning, maar zonder de tijd en kosten die nodig zijn voor supervised learning.
Bij actief leren [10] kan bijvoorbeeld een classificator die aanvankelijk is getraind op een kleine set gelabelde gegevens (bijv. “normal”, “rootkit”, “teardrop”8) worden gebruikt om een grote set ruwe gegevens te analyseren en vervolgens de meest voordelige samples “voor te stellen” om te labelen. Deze samples worden geselecteerd met behulp van een algoritme voor ongesuperviseerde anomaliedetectie. Vervolgens wordt een expert geraadpleegd om de voorgestelde samples te labelen en wordt het model bijgewerkt.
Verschillende auteurs hebben oplossingen met semi-supervised learning voorgesteld in verschillende cyberbeveiligingsdomeinen, of het nu gaat om malwaredetectie (bijv. [12]) of inbraakdetectie (bijv. [13]). Veel methoden zijn geïnspireerd op de populaire co-learning methode [14] die eind jaren 1990 werd voorgesteld.
Reinforcement learning
Reinforcement learning (RL) is gebaseerd op trial and error: een autonome agent leert om beslissingen te nemen in een gegeven omgeving. De omgeving beloont de agent al dan niet voor elke beslissing die hij neemt. De trainingsgegevens in reinforcement learning zijn een mix van gesuperviseerde en niet gesuperviseerde benaderingen: in plaats van gegevens te voorzien van het juiste label, verkent het algoritme acties tot ze juist zijn.
Ondanks het voordeel van reinforcement learning, dat zich kan aanpassen aan veranderingen in de omgeving, is er nog steeds één moeilijkheid die het gebruik ervan in cyberbeveiliging beperkt: het definiëren van de beloningsfunctie, met name op het gebied van inbraakdetectie [15], [16].
Federated machine learning
Geïntroduceerd door McMahan et al. [17], is federated learning een gedistribueerde en collaboratieve manier van machinaal leren. De machines die betrokken zijn bij het leren zijn niet verplicht om hun gegevens te delen en sturen slechts modellen die geleerd zijn van hun gegevens om bij te dragen aan een globaal model dat het resultaat is van het combineren van alle lokale modellen9.
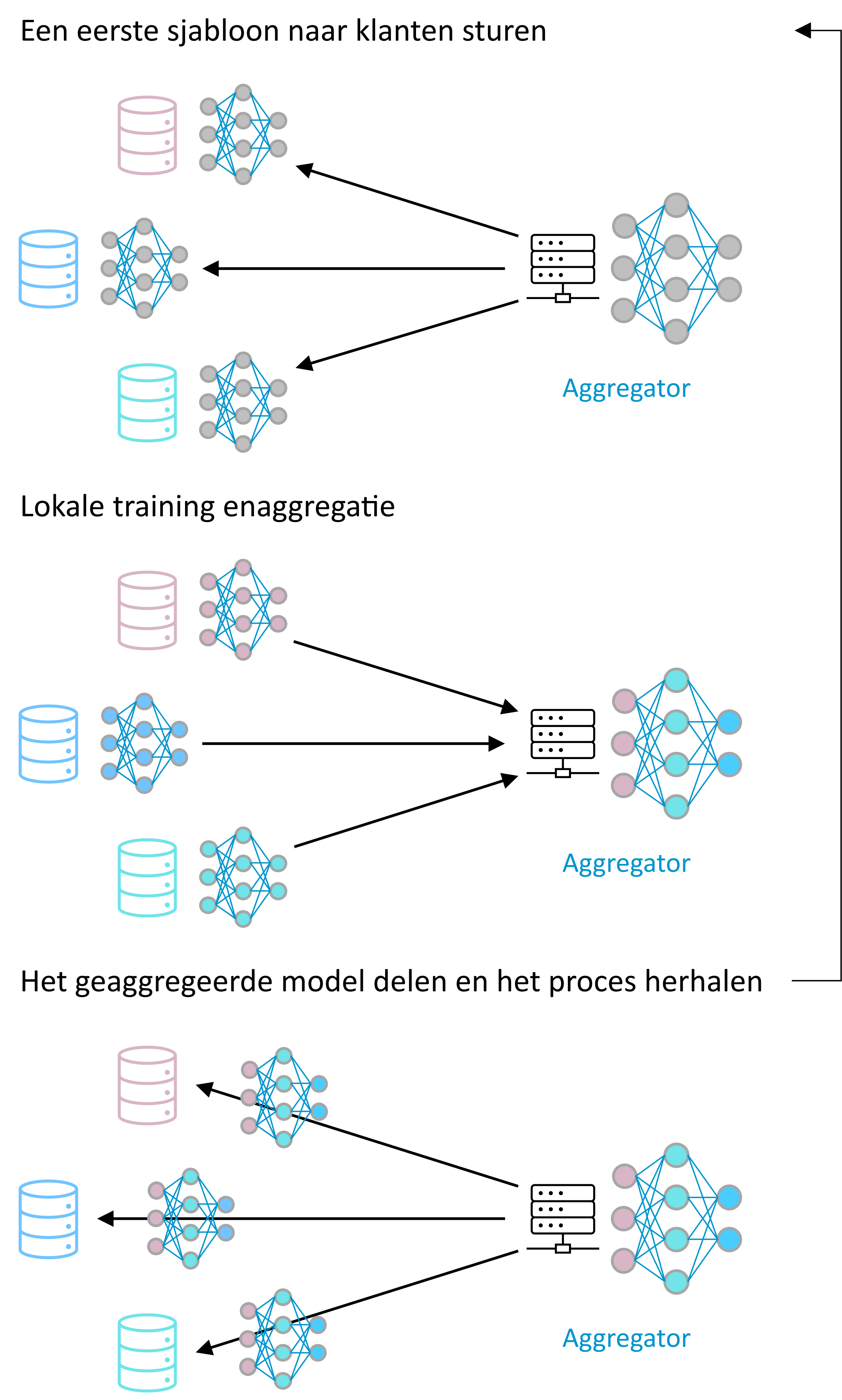
Figuur 2 – Voorbeeld van gecentraliseerd federated learning: een centrale server orkestreert het leren, waardoor een relatief eenvoudig protocol mogelijk is. In het niet-gecentraliseerde geval sturen deelnemers elkaar gedeeltelijke modellen op peer-to-peer basis.
Volgens Hernández-Ramos et al. [18] zou federated learning een belangrijke rol kunnen spelen op het gebied van cyberbeveiliging, omdat het afzonderlijke organisaties in staat zou kunnen stellen informatie over beveiligingsbedreigingen en aanvallen te delen zonder dat ze hun feitelijke en mogelijk gevoelige gegevens hoeven te delen10,11. In hun analyse wijzen de auteurs erop dat het gebruik van federated machine learning op het gebied van inbraakdetectie de afgelopen jaren is toegenomen12. Ondanks hun kosten en beperkingen worden supervised federated methods nog steeds het meest bestudeerd in vergelijking met unsupervised federated methods.
Large Language Models
Grote taalmodellen (Large Language Models, LLM) worden verkregen door unsupervised learning van diepe neurale netwerken13 die getraind zijn op zeer grote hoeveelheden ongelabelde tekst. Deze omvatten generative pre-trained transformers, (GPT) [20], [21], waarvan de belangrijkste functie is om statistisch het volgende woord in een tekstpassage te voorspellen14. Een meer gedetailleerde beschrijving van deze modellen is te vinden in [22].
Toepassingen van deze modellen op cyberbeveiliging zijn nog beperkt, omdat maar weinig toepassingen tekst en gegevens in natuurlijke taal gebruiken. Een intrigerend aspect van deze massale taalmodellen is echter de betwiste aanname dat ze emergente capaciteiten vertonen, die “niet aanwezig zijn in kleinschaligere modellen, maar wel in grootschalige modellen” [23], [24]. Dit roept de vraag op of deze opkomende capaciteiten ook cyberbeveiliging kunnen omvatten.
Eén benadering om LLM-architecturen te benutten is om transformers en andere architecturale aspecten van LLM’s te gebruiken en het model vooraf te trainen op beveiligingsgegevens. Hoewel transformers het meest bekend zijn om hun resultaten in natuurlijke taalverwerking, kunnen ze ook worden overwogen voor inbraakdetectie (bijvoorbeeld [25]).
Gezien de recente ontwikkelingen in generatieve modellen is het zeer waarschijnlijk dat deze in de komende jaren uitgebreid zullen worden bestudeerd voor de ontwikkeling van inbraakdetectie.
Conclusies
De belangstelling voor AI-technieken op het gebied van beveiliging is duidelijk, al is het maar gezien het grote aantal publicaties, literatuurartikelen over het onderwerp en cybersecurityproducten die prat gaan op het gebruik ervan.
Hoewel er geen twijfel over bestaat dat AI nuttig is voor het analyseren van bestaande gegevens, zijn de gegeven resultaten a priori, zoals we hebben gezien, gebaseerd op reeds waargenomen gegevens. Het gevolg is dat, ondanks de indrukwekkende reputatie van AI het doet vermoeden, het nog niet bewezen dat AI creatief vermogen heeft om nieuwe aanvalsvectoren te detecteren, die expertise en menselijke intuïtie vereisen. Bovendien hangt de beoordeling van een risico af van vele factoren die soms moeilijk te kwantificeren zijn, zoals de geopolitieke of sociaaleconomische context.
AI moet daarom worden gezien als een stap in de evolutie van de beveiliging, en niet als een complete revolutie. Zoals we in een toekomstig artikel zullen zien, speelt het een rol bij het verbeteren van de veiligheidspraktijken, maar mag het niet volledig in de plaats komen van menselijke interventie en besluitvorming.
Referenties
[1] N. Fatès, ‘Que faire de l’expression intelligence artificielle ?’, Alliage : Culture-Science-Technique, nov. 2023.
[2] M. Brundage e.a., ‘The malicious use of artificial intelligence: forecasting, prevention and mitigation’, feb. 2018.
[3] C. Villani, ‘Donner un sens à l’intelligence artificielle – Pour une stratégie nationale et européenne’, mrt. 2018. [Online]. Beschikbaar op: https://www.vie-publique.fr/rapport/37225-donner-un-sens-lintelligence-artificielle-pour-une-strategie-nation
[4] M. Taddeo, T. McCutcheon, en L. Floridi, ‘Trusting artificial intelligence in cybersecurity is a double-edged sword’, Nat Mach Intell, vol. 1, nr. 12, pp. 557-560, nov. 2019, doi: 10.1038/s42256-019-0109-1.
[5] K. Renaud, M. Warkentin, en G. Westerman, ‘From ChatGPT to HackGPT: Meeting the cybersecurity threat of generative AI’, MIT Sloan Management Review, 18 april 2023.
[6] D. Dasgupta, Z. Akhtar, en S. Sen, ‘Machine learning in cybersecurity: a comprehensive survey’, Journal of Defense Modeling & Simulation, vol. 19, nr. 1, pp. 57-106, jan. 2022, doi: 10.1177/1548512920951275.
[7] G. Apruzzese e.a., ‘The role of machine learning in cybersecurity’, Digital Threats, vol. 4, nr. 1, pp. 1-38, mrt. 2023, doi: 10.1145/3545574.
[8] G. Apruzzese, P. Laskov, en A. Tastemirova, ‘SoK: The impact of unlabelled data in cyberthreat detection’, in 2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P), jun. 2022, pp. 20-42. doi: 10.1109/EuroSP53844.2022.00010.
[9] Y. Mirsky, T. Doitshman, Y. Elovici, en A. Shabtai, ‘Kitsune: An ensemble of autoencoders for online network intrusion detection’. arXiv, 27 mei 2018. Geraadpleegd: 26 oktober 2023. [Online]. Beschikbaar op: http://arxiv.org/abs/1802.09089
[10] K. Yang, J. Ren, Y. Zhu, en W. Zhang, ‘Active learning for wireless IoT intrusion detection’, IEEE Wireless Commun., vol. 25, nr. 6, pp. 19-25, dec. 2018, doi: 10.1109/MWC.2017.1800079.
[11] ‘KDD Cup 1999 Data’. Geraadpleegd: 8 december 2023. [Online]. Beschikbaar op: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
[12] J. Koza, M. Krčál, en M. Holeňa, ‘Two semi-supervised approaches to malware detection with neural networks’, gepresenteerd bij Information technologies – Applications and theory (ITAT), 2020.
[13] L. Sun, Y. Zhou, Y. Wang, C. Zhu, en W. Zhang, ‘The effective methods for intrusion detection with limited network attack data: multi-task learning and oversampling’, IEEE Access, vol. 8, pp. 185384-185398, 2020, doi: 10.1109/ACCESS.2020.3029100.
[14] A. Blum en T. Mitchell, ‘Combining labeled and unlabeled data with co-training’, in Proceedings of the eleventh annual conference on Computational learning theory, Madison Wisconsin USA: ACM, jul. 1998, pp. 92-100. doi: 10.1145/279943.279962.
[15] E. Bertino, M. Kantarcioglu, C. G. Akcora, S. Samtani, S. Mittal, en M. Gupta, ‘AI for security and security for AI’, in Proceedings of the Eleventh ACM Conference on Data and Application Security and Privacy, Virtual Event USA: ACM, apr. 2021, pp. 333-334. doi: 10.1145/3422337.3450357.
[16] M. Lopez-Martin, B. Carro, en A. Sanchez-Esguevillas, ‘Application of deep reinforcement learning to intrusion detection for supervised problems’, Expert Systems with Applications, vol. 141, p. 112963, mrt. 2020, doi: 10.1016/j.eswa.2019.112963.
[17] H. B. McMahan, E. Moore, D. Ramage, en S. Hampson, ‘Communication-efficient learning of deep networks from decentralized data’, Proceedings of machine learning research, pp. 1273-1282, apr. 2017.
[18] J. L. Hernández-Ramos e.a., ‘Intrusion detection based on federated learning: a systematic review’. arXiv, 18 augustus 2023. Geraadpleegd: 17 oktober 2023. [Online]. Beschikbaar op: http://arxiv.org/abs/2308.09522
[19] E.-M. El-Mhamdi e.a., ‘On the impossible safety of large AI models’. arXiv, 9 mei 2023. Geraadpleegd: 17 oktober 2023. [Online]. Beschikbaar op: http://arxiv.org/abs/2209.15259
[20] A. Vaswani e.a., ‘Attention is all you need’, Advances in neural information processing systems, vol. 30, 2017.
[21] T. Lin, Y. Wang, X. Liu, en X. Qiu, ‘A survey of transformers’, AI Open, vol. 3, pp. 111-132, 2022, doi: 10.1016/j.aiopen.2022.10.001.
[22] B. Vanhalst, ‘Een eigen vraag- en antwoordsysteem op basis van taalmodellen | Smals Research’, Smals Research Blog. Geraadpleegd: 17 oktober 2023. [Online]. Beschikbaar op: https://www.smalsresearch.be/een-eigen-vraag-en-antwoordsysteem-op-basis-van-taalmodellen/
[23] J. Wei e.a., ‘Emergent abilities of large language models’. arXiv, 26 oktober 2022. Geraadpleegd: 9 november 2023. [Online]. Beschikbaar op: http://arxiv.org/abs/2206.07682
[24] R. Schaeffer, B. Miranda, en S. Koyejo, ‘Are Emergent Abilities of Large Language Models a Mirage?’ arXiv, 22 mei 2023. Geraadpleegd: 9 november 2023. [Online]. Beschikbaar op: http://arxiv.org/abs/2304.15004
[25] Z. Wu, H. Zhang, P. Wang, en Z. Sun, ‘RTIDS: A Robust Transformer-Based Approach for Intrusion Detection System’, IEEE Access, vol. 10, pp. 64375-64387, 2022, doi: 10.1109/ACCESS.2022.3182333.
Voetnoten
1 https://www.smalsresearch.be/1-an-chatgpt/
2 https://www.crowdstrike.com/blog/crowdstrike-introduces-charlotte-ai-to-deliver-generative-ai-powered-cybersecurity/
3 https://cloud.google.com/blog/products/identity-security/rsa-introducing-ai-powered-investigation-chronicle-security-operations
4 https://www.microsoft.com/en-us/security/business/ai-machine-learning/microsoft-security-copilot
5 https://www.sentinelone.com/blog/purple-ai-empowering-cybersecurity-analysts-with-ai-driven-threat-hunting-analysis-response/
6 De term naïef is gekoppeld aan het feit dat de methode uitgaat van een hoge mate van onafhankelijkheid van de gebruikte kenmerken.
7 Er zijn vele soorten kunstmatige neurale netwerken, waaronder feedforward neural networks (FFNN) – zoals de beroemde meerlaagse perceptron – convolutional neural networks (CNN), en recurrent neural networks (RNN).
8 Deze en verschillende andere labels worden gebruikt in de populaire KDD-99 dataset [11], die erg populair is in onderzoek naar inbraakdetectie.
9 Hoewel de soorten lokale modellen voor elke deelnemer verschillend kunnen zijn, houden maar weinig werken rekening met deze mogelijkheid. Bovendien gebruiken de meeste werken een gewogen gemiddelde om het centrale model bij te werken en kunnen ze niet goed rekening houden met de heterogeniteit van gegevens en apparaten.
10 Deze stimulans om te delen is in overeenstemming met de Europese regelgeving op het gebied van cyberbeveiliging, die het melden van cyberbeveiligingsincidenten verplicht stelt
11 Toch wordt de veiligheid van deze federated models betwist [19].
12 Het aantal publicaties over dit onderwerp is gestegen van minder dan 5 in 2018 naar meer dan 150 in 2022.
13 Dat wil zeggen, een neuraal netwerk met minstens twee opeenvolgende lagen neuronen.
14 Als het model groot genoeg is, blijkt dat niet alleen de grammatica van de menselijke talen kan worden geleerd, maar ook de betekenis van woorden, gemeenschappelijke kennis en primitieve logica. Als een model bijvoorbeeld het zinsfragment “De kat van mijn buurman is” als input krijgt, zal het veel eerder “grijs” of “mager” voorspellen dan “Franstalig”, ook al zijn alle drie de woorden bijvoeglijke naamwoorden. Op dezelfde manier kunnen we verwachten dat het model een coherente zin voorspelt als we een volledige zin opgeven.
_________________________
Dit is een ingezonden bijdrage van Fabien A. P. Petitcolas, IT-beveiligingsspecialist bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.
Leave a Reply