Inleiding
Detectie van anomalieën (ook wel ‘outliers’ of ‘afwijkende waarden’ genoemd) is een veelvoorkomend probleem binnen data science en machine learning. Dit opsporen wordt vaak gezien als een eenvoudige voorbereidende taak, maar kan ook prima het einddoel van de toepassing zijn:
- Als voorbereidende taak vindt de detectie plaats tijdens de verkennende analyse, om problemen met ‘garbage in, garbage out’ te beperken. Het doel is hier dus om deze anomalieën te corrigeren of te verwijderen om te voorkomen dat ze worden gebruikt tijdens de trainingsfase van het voorspellende model, omdat dit de prestaties ervan negatief zou kunnen beïnvloeden.
- Als hoofdtaak kan het opsporen van waarnemingen met afwijkende profielen bijvoorbeeld dienen om frauduleuze activiteiten, fouten of zelfs inbraken op te sporen (IDS: Intrusion Detection System) [1].
Het opsporen van anomalieën is dus een zeer belangrijke taak die in tal van domeinen veel toepassingen kent [1], en tot doel heeft waarnemingen te vinden die niet in overeenstemming zijn met de rest van de gegevens [2].
Deze blogpost gaat in op het probleem van het opsporen van anomalieën in gegevens en heeft tot doel oplossingen te presenteren die gebaseerd zijn op een machine learning-benadering.
Opmerkelijk is ook dat, hoewel deze twee gebieden met elkaar verband houden, anomaliedetectie verschilt van tools voor datakwaliteit (data quality) zoals Trillium en Open Refine. Bij data quality ligt de nadruk op het opsporen van problemen met incomplete/ongeldige gegevens aan de hand van regels, terwijl anomaliedetectie erop gericht is zeldzame/ongebruikelijke patterns te identificeren (die afwijken van de ‘norm’), maar die vanuit het oogpunt van data quality niet per se ongeldig zijn.
Verschillende soorten anomalieën
Voordat we ingaan op de tools voor het opsporen van anomalieën, zullen we eerst de verschillende soorten anomalieën definiëren die kunnen worden gedetecteerd. In de literatuur wordt vaak uitgegaan van drie soorten anomalieën [3] :
- De incidentele anomalie
Dit is de eenvoudigste vorm van anomalieën: een individueel geval dat als afwijkend wordt beschouwd ten opzichte van de rest van de gegevens.
Deze anomalieën worden soms nog onderverdeeld in twee subcategorieën: globale (die significant verschillen van de rest van de gegevens) en lokale anomalieën (die verschillen van de directe omgeving). Illustratief voorbeeld:
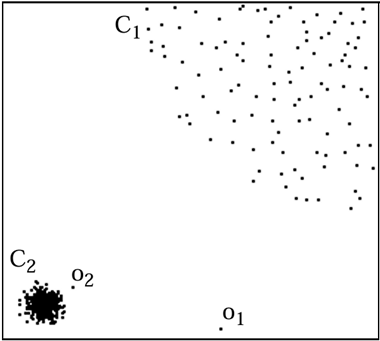
Figuur 1: Voorbeeld van lokale en globale anomalieën (afbeelding uit [4])
In figuur 1 zijn twee anomalieën te zien: o1, een globale anomalie die sterk verschilt van de andere waarnemingen, en o2, een lokale anomalie ten opzichte van de omgeving (de C2-groep).
- De contextuele anomalie
Een anomalie wordt als ‘contextueel’ beschouwd als deze in een andere context als normaal kan worden beschouwd. Neem bijvoorbeeld neerslag: een bepaald neerslagniveau dat op een bepaalde plek abnormaal is, kan op een andere plek heel goed als normaal worden beschouwd. We hebben hier dus twee soorten kenmerken: contextuele kenmerken die de context bepalen (vaak temporele of ruimtelijke kenmerken) en gedragsmatige kenmerken waarin we naar anomalieën zoeken (in ons voorbeeld: de neerslag).
- Collectieve anomalie/groepsanomalie
In deze laatste categorie gaat het niet langer om een individuele anomalie, maar om een reeks anomalieën die een groep vormen met ongebruikelijke kenmerken.
Detectiemethodes
Vaak (en vooral wanneer het gaat om een eenvoudige voorbereidende taak als data cleansing) gebeurt het opsporen van anomalieën in de gegevens eenvoudigweg met behulp van statistische tools (bijvoorbeeld door gebruik te maken van standaardanomalieën, kwantielen of statistische toetsen). In dit artikel gaan we niet in op deze statistische benaderingen, maar richten we ons op machine learning-benaderingen voor het opsporen van anomalieën.
Welk soort learning?
Er zijn hoofdzakelijk twee benaderingen om anomalieën op te sporen: methoden op basis van supervised learning (begeleid leren) en methoden op basis van unsupervised learning (onbegeleid leren). Ter herinnering: bij supervised learning wordt gebruikgemaakt van gelabelde data. Dit vereist dat er, naast de data, ook voorbeelden zijn van eerder geïdentificeerde anomalieën, zodat het detectiemodel kan leren deze te onderscheiden van normale data. Omgekeerd is unsupervised learning volledig gebaseerd op de data en vereist het geen set van vooraf geïdentificeerde anomalieën.
In het kader van dit artikel gaan we de unsupervised benaderingen verkennen. Deze hebben namelijk een interessant kenmerk ten opzichte van de supervised modellen (naast het feit dat ze geen gelabelde gegevens vereisen): het ontdekken van nieuwe vormen van anomalieën.
Een supervised model zal namelijk de neiging hebben om anomalieën te identificeren die kenmerken vertonen die vergelijkbaar zijn met die van de gelabelde anomalieën. Daarom is het, zelfs wanneer er gelabelde gegevens beschikbaar zijn, vaak interessant om een supervised model – getraind om bepaalde vooraf gedefinieerde anomalieprofielen nauwkeuriger te detecteren – te koppelen aan een unsupervised model, dat mogelijk anomalieën met totaal andere profielen kan opsporen.
Enkele klassieke algoritmes voor het opsporen van anomalieën
Voordat we beginnen, zullen we algoritmen voor het opsporen van anomalieën in twee categorieën indelen: detectoren en detectiemodellen. Een detectiemodel bouwt, zoals de naam al aangeeft, een model op dat op zichzelf kan worden gebruikt: als we bijvoorbeeld een nieuwe waarneming hebben, kunnen we die gewoon in het model invoeren om te beoordelen of het om een anomalie gaat. Een detector daarentegen heeft geen getraind model dat later kan worden gebruikt: als er een nieuwe waarneming binnenkomt, moet deze opnieuw in de context worden geplaatst door deze tussen de andere gegevens te plaatsen, of zelfs het detectieproces van anomalieën volledig opnieuw starten.
Detectoren zonder modellen
Een eerste intuïtieve benadering om te bepalen of een waarneming een anomalie is of niet, is gebaseerd op het idee dat een anomalie de neiging heeft om ver van zijn buren te liggen. Door dus de gemiddelde afstand (bijvoorbeeld de Euclidische afstand) te meten tussen een waarneming en zijn k dichtstbijzijnde buren (k-NN), of simpelweg de afstand tussen een waarneming en zijn k-de dichtstbijzijnde buur (kth-NN) [5], kan men het risico inschatten dat een waarneming een anomalie is: als de waarneming ver van de andere ligt, kan men aannemen dat het om een anomalie gaat.
Deze op afstand gebaseerde benadering heeft het voordeel dat ze intuïtief, eenvoudig te implementeren en te interpreteren is, maar ze stuit al snel op haar grenzen. Als we het voorbeeld uit Figuur 1, nog eens bekijken, zien we dat alle waarnemingen van cluster C1 verder van elkaar verwijderd zijn dan o2 van de waarnemingen van C2. Resultaat: een op afstand gebaseerd algoritme zal anomalie o1 gemakkelijk vinden, maar o2 niet. Een zeer bekende alternatieve benadering, de Local Outlier Factor (LOF) [4] is gebaseerd op dichtheid in plaats van op afstand. Hiermee kunnen gevallen worden behandeld waarin de gegevens clusters bevatten (C1 en C2 in Figuur 1) die niet dezelfde dichtheid hebben.
Het idee is als volgt: kijken of de dichtheid rond een waarneming consistent is met de dichtheid van de k dichtstbijzijnde buren. Als we dus een waarneming nemen die deel uitmaakt van groep C1, is de dichtheid rond deze waarneming consistent met de dichtheid rond haar naaste buren, terwijl voor waarneming o2 de dichtheid rond o2 verschilt van de dichtheid rond haar naaste buren binnen C2. Het LOF-algoritme bestaat er dus in anomalieën te detecteren door na te gaan of hun dichtheid consistent is met de dichtheid van hun lokale omgeving.
Een laatste type detector dat we zullen bekijken, is gebaseerd op het clusteren van gegevens (clustering). Het bekende doel van clustering is het opsporen van groepen waarnemingen met vergelijkbare kenmerken. Dit maakt het met name mogelijk om:
- Te zoeken naar een waarneming die ver van het zwaartepunt van haar cluster ligt, of die zich in een microcluster bevindt die slechts één waarneming bevat (een incidentele anomalie).
- Zoeken naar abnormale clusters (collectieve anomalieën).
Jiang et al. [6] stellen bijvoorbeeld voor om de gegevens op te splitsen en vervolgens de ‘outlier factor’ van elke cluster te berekenen (gebaseerd op de afstand tussen die cluster en de andere), om zo clusters van anomalieën te vinden. He et al. [7] stellen het FindCBLOF-algoritme (CBLOF: cluster-based local outlier factor) voor, dat de gegevens opdeelt en vervolgens naar anomalieën zoekt door zowel de grootte van de clusters (te kleine clusters kunnen collectieve anomalieën vertegenwoordigen) als de afstanden tussen de waarnemingen en de zwaartepunten van de clusters te gebruiken.
Detectiemodellen
Nu we modelvrije benaderingen hebben bekeken, gaan we kort verder met modelgebaseerde benaderingen voor het opsporen van anomalieën. Dit hoofdstuk zal vrij kort zijn en slechts twee van de bekendste modellen behandelen: de ‘isolation forest’ en de ‘one-class SVM’.
Isolation forest [8] is gebaseerd op het principe dat een anomalie, omdat deze ongebruikelijke kenmerken vertoont, gemakkelijker te isoleren zou moeten zijn dan een normale waarneming.
Het idee is simpel: we kiezen willekeurig een variabele en een waarde (bijvoorbeeld: leeftijd (variabele) en 21.3 (waarde)), en gebruiken die om de gegevens in twee subgroepen (takken) te verdelen. Elk van deze groepen wordt vervolgens op willekeurige wijze onderverdeeld in subgroepen, die op hun beurt weer worden onderverdeeld, enzovoort, op recursieve wijze, waardoor een willekeurig opgebouwde beslissingsboom (decision tree) ontstaat, die een isolation tree wordt genoemd.
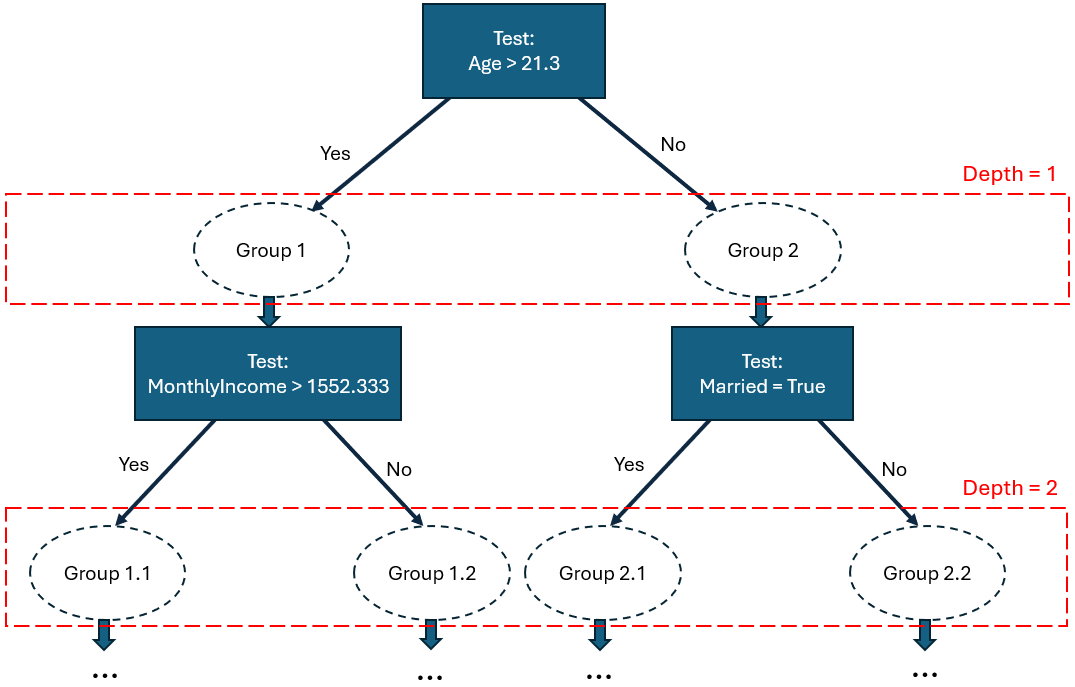
Figuur 2: Illustratief voorbeeld van een isolation tree
Tijdens de ontwikkeling van de boom wordt een groep niet meer in subgroepen opgesplitst zodra deze nog maar één waarneming bevat. Een Isolation Forest bestaat dus uit een groot aantal van deze willekeurige bomen, met het idee dat een normale waarneming moeilijker te isoleren zou moeten zijn (en dus gemiddeld meer willekeurige verdelingen van de ruimte zou vereisen) dan een anomalie (zie Figuur 3).
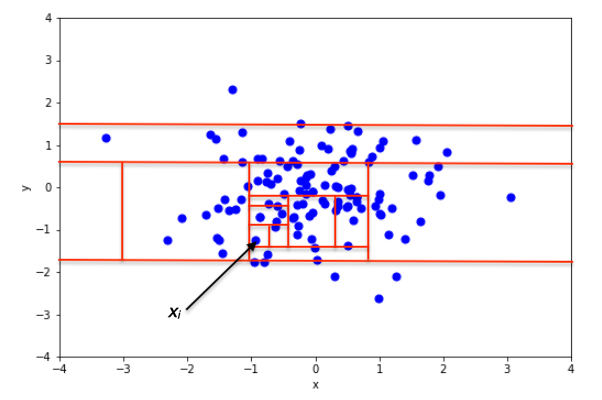
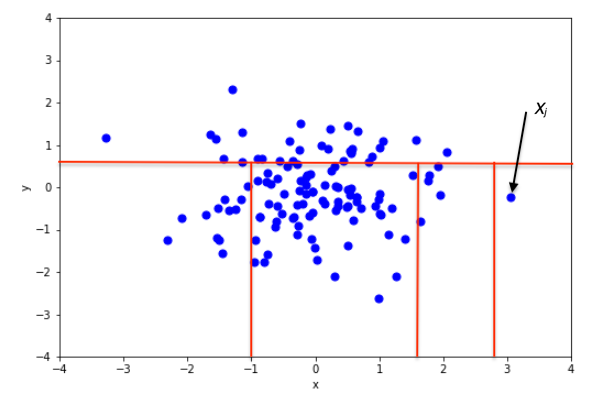
Figuur 3: Voorbeeld van het isoleren van een normale waarneming (xi) en een afwijkende waarneming (xj) (afbeelding uit [9])
Om te bepalen of een waarneming een mogelijke anomalie is, volstaat het om te kijken op welke diepte deze in de verschillende bomen geïsoleerd is. Anomalieën zouden gemiddeld genomen vrij dicht bij de top van de bomen moeten staan, omdat ze makkelijker te isoleren zijn.
De One-Class Support Vector Machine (OCSVM) [10] is het tweede detectiemodel waar we in dit artikel naar gaan kijken. Merk op dat het algoritme dat aan de basis ligt van de OCSVM aanzienlijk minder intuïtief en gemakkelijker uit te leggen is dan isolation forest. We zullen dus niet uitgebreid ingaan op de werking ervan. We zullen het echter toch kort toelichten, omdat het een bekend klassiek model is voor detectie van anomalieën.
OCSVM probeert het gebied te vinden waar de gegevens dicht bij elkaar liggen, en de punten buiten dit gebied als afwijkend te beschouwen. Het doel van OCSVM is om de vorm van de ‘normaliteit’ te leren, om zo een grens te bepalen die de normale waarnemingen van de anomalieën scheidt. Het bijzondere aan het OCSVM-algoritme is dat het, in plaats van direct de kenmerken (features) van de waarnemingen te gebruiken om de grens tussen normale en abnormale waarnemingen te bepalen, de waarnemingen projecteert in een getransformeerde ruimte, waardoor complexe grenzen tussen normale en abnormale gegevens kunnen worden getrokken.
Illustratief voorbeeld
Om de opsporing van anomalieën te illustreren, hebben we artificiële gegevens in twee dimensies gegenereerd, bestaande uit:
- ‘Normale’ gegevens: gegenereerd volgens een normale verdeling.
- Anomalieën: willekeurig gegenereerd volgens een uniforme verdeling.
De normale gegevens en de anomalieën zijn door elkaar gemengd en we hebben daarop drie algoritmen voor het opsporen van anomalieën toegepast (OCSVM, Isolation Forest en LOF). De resultaten zijn te zien in de figuren 4 – 6:
- Figuur 4: Een enkele groep van normale waarnemingen;
- Figuur 5: Twee groepen normale waarnemingen die licht uit elkaar liggen
- Figuur 6: Twee groepen normale waarnemingen die ver uit elkaar liggen
In elk van deze grafieken worden normale waarnemingen in het wit weergegeven en anomalieën in het zwart, zodat ze visueel gemakkelijk van elkaar te onderscheiden zijn. Deze labels (normaal versus anomalie) zijn uiteraard niet aan de algoritmen meegedeeld, aangezien deze unsupervised draaien.
Voor elk van deze drie algoritmen hebben we de grens die het algoritme gebruikt om normale gegevens van anomalieën te onderscheiden, in het rood gemarkeerd. De waarnemingen in de oranje zone (binnen de grens) worden door het algoritme als normaal beschouwd, en de waarnemingen in de blauwe zone worden als anomalieën beschouwd (lichtblauw: licht afwijkend; donkerblauw: sterk afwijkend).
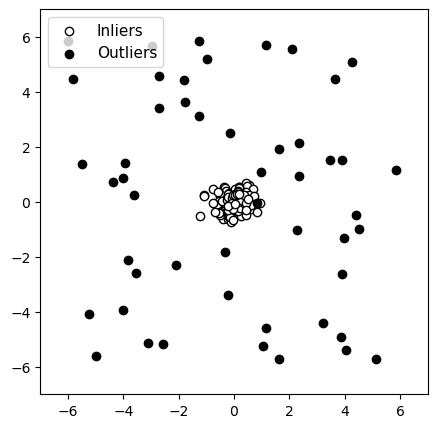
Originele gegevens
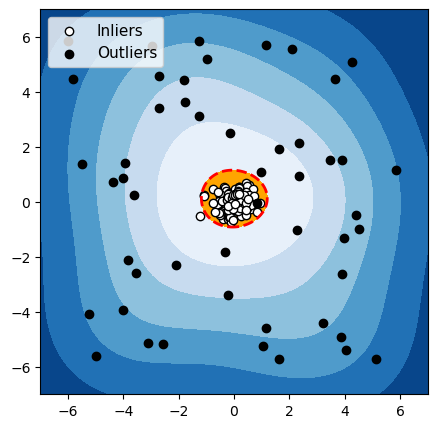
OCSVM
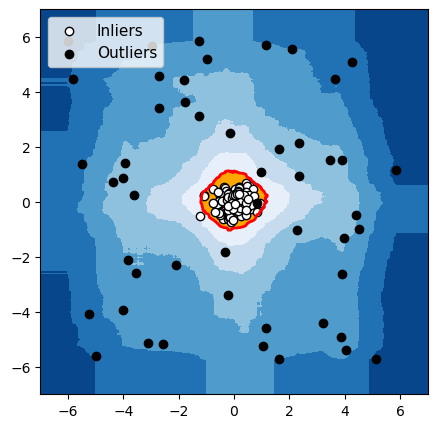
Isolation Forest
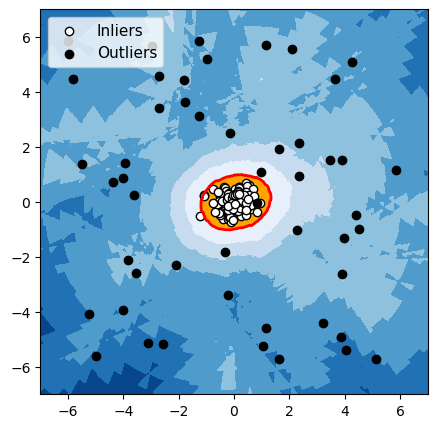
LOF
Figuur 4: Detectie van anomalieën met een groep normale gegevens
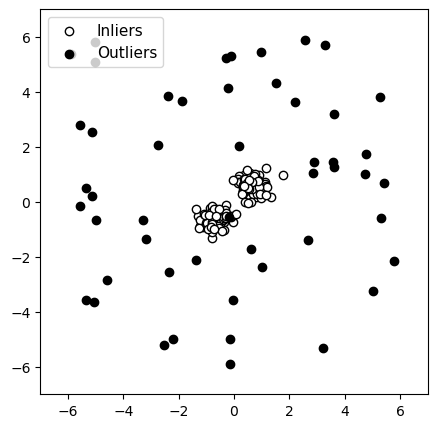
Originele gegevens
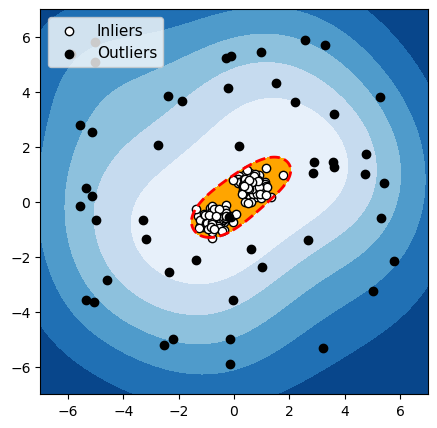
OCSVM
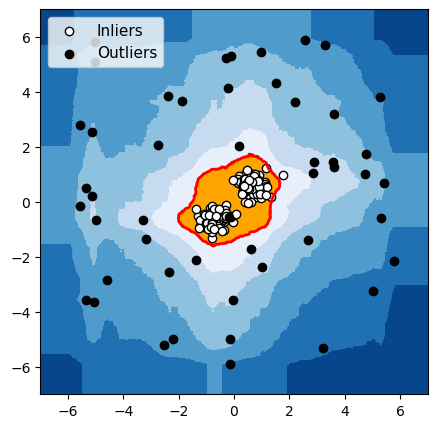
Isolation Forest
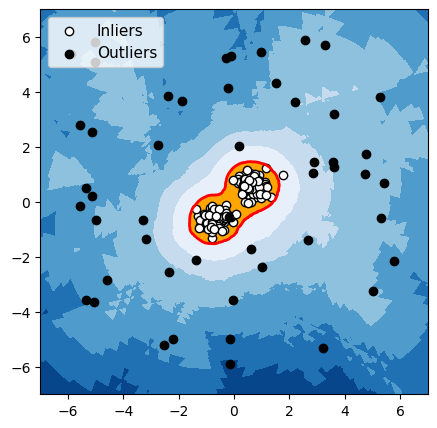
LOF
Figuur 5: Detectie van anomalieën met twee licht van elkaar gescheiden groepen normale gegevens
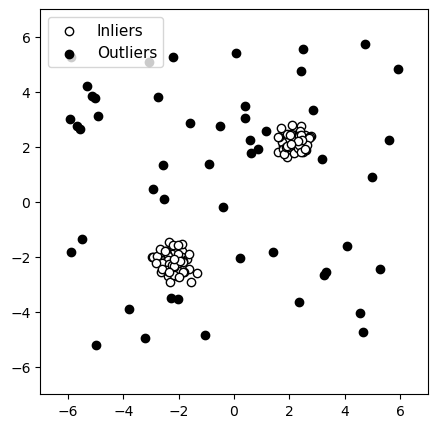
Originele gegevens
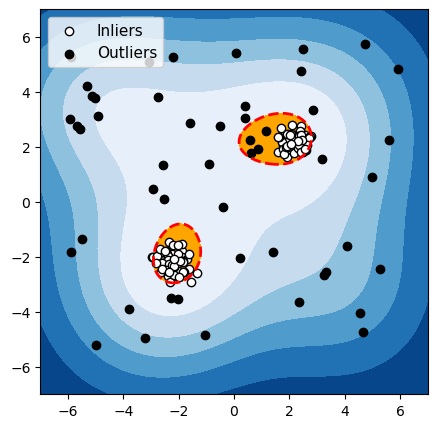
OCSVM
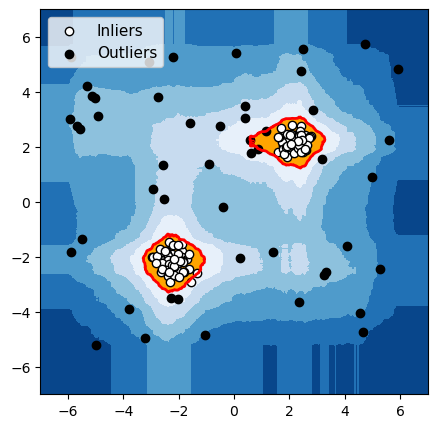
Isolation Forest
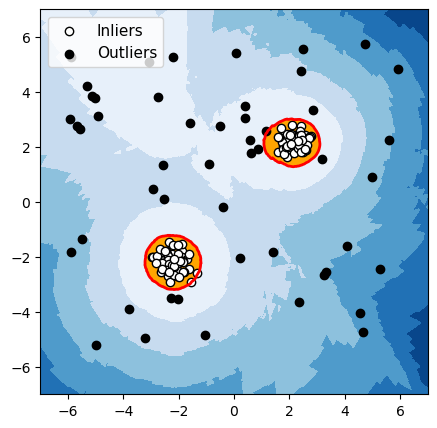
LOF
Figuur 6: Detectie van anomalieën met twee duidelijk gescheiden groepen normale gegevens
Detectie evalueren
Het is geen eenvoudige opgave om de kwaliteit van de opsporing van anomalieën te kwantificeren. Laten we beginnen met het eenvoudigste geval: als we beschikken over vooraf geïdentificeerde anomalieën (labels). In deze gevallen kan een algoritme voor het opsporen van anomalieën worden gevalideerd door te controleren of het erin slaagt de reeds bekende anomalieën terug te vinden, met behulp van klassieke maatstaven (recall, precision, F1-measure, enz.).
Zonder labels wordt het ingewikkelder. In dat geval moeten de door het algoritme geïdentificeerde waarnemingen handmatig worden gecontroleerd om te bevestigen of ze daadwerkelijk afwijkend zijn. Dit vereist niet alleen een goede kennis van het domein waaruit de gegevens afkomstig zijn, maar ook inzicht in waarom de waarneming door het algoritme als anomalie is geïdentificeerd. Aangezien er vaak een groot aantal variabelen in de gegevens zit en de grens (tussen normale en afwijkende gegevens) die door het algoritme wordt gebruikt doorgaans complex is, is het soms moeilijk te begrijpen waarom bepaalde waarnemingen door een algoritme als anomalieën zijn geïdentificeerd. Het kan dan nuttig zijn om verklaarbaarheidstools (bijvoorbeeld: SHAP, LIME) te gebruiken om de beslissingen van het algoritme te begrijpen.
Conclusie
In deze blogpost hebben we ervoor gekozen om een selectie van (unsupervised) algoritmen te presenteren die gebaseerd zijn op verschillende aanpakken (afstand, dichtheid, isolatie, enz.) om zo de grote verscheidenheid aan bestaande algoritmen te illustreren. We willen er echter op wijzen dat we geen aandacht hebben besteed aan de supervised methoden (die vaak nauwkeuriger zijn omdat ze gespecialiseerd zijn in de opsporing van vooraf gedefinieerde patronen) en de statistische benaderingen. Opsporing van anomalieën is dus een uitgebreid domein met talrijke tools. Unsupervised algoritmen bieden een grote flexibiliteit omdat ze geen labels vereisen en nieuwe vormen van anomalieën kunnen opsporen. In de praktijk is het soms handig – aangezien elk detectiealgoritme anders is – om meerdere algoritmen te combineren voor het opsporen van anomalieën om een grotere verscheidenheid aan opgespoorde anomalieën te verkrijgen.
[1] : Chandola, V., Banerjee, A., & Kumar, V. (2009). Anomaly detection: A survey. ACM computing surveys (CSUR), 41(3), 1-58.
[2] : Samariya, D., & Thakkar, A. (2023). A comprehensive survey of anomaly detection algorithms. Annals of Data Science, 10(3), 829-850.
[3] : Nassif, A. B., Talib, M. A., Nasir, Q., & Dakalbab, F. M. (2021). Machine learning for anomaly detection: A systematic review. Ieee Access, 9, 78658-78700.
[4]: Breunig, M. M., Kriegel, H. P., Ng, R. T., & Sander, J. (2000). LOF: identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD international conference on Management of data (pp. 93-104).
[5] : Ramaswamy, S., Rastogi, R., & Shim, K. (2000). Efficient algorithms for mining outliers from large data sets. In Proceedings of the 2000 ACM SIGMOD international conference on Management of data (pp. 427-438).
[6] : Jiang, S. Y., & An, Q. B. (2008). Clustering-based outlier detection method. In 2008 Fifth international conference on fuzzy systems and knowledge discovery (Vol. 2, pp. 429-433). IEEE.
[7] : He, Z., Xu, X., & Deng, S. (2003). Discovering cluster-based local outliers. Pattern recognition letters, 24(9-10), 1641-1650.
[8] : Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008). Isolation forest. In 2008 eighth ieee international conference on data mining (pp. 413-422). IEEE.
[9] : Isolation forest – Wikipedia
[10] : Schölkopf, B., Platt, J. C., Shawe-Taylor, J., Smola, A. J., & Williamson, R. C. (2001). Estimating the support of a high-dimensional distribution. Neural computation, 13(7), 1443-1471.