« Data is the New Gold » : voici une citation que l’on a maintes fois vue et entendue quand il s’agit de parler de science des données ou d’intelligence artificielle. Ce blog se concentre sur les données non structurées et textuelles et une des nouvelles techniques qui permettent d’extraire « l’or » contenu dans celles-ci.
Les entreprises et organisations disposent en effet d’une grande quantité de données structurées et non structurées, souvent sous forme de textes. Pour exploiter au mieux l’information contenue dans ses données, elles utilisent des systèmes de recherche (Enterprise Search) pour retrouver rapidement l’information utile et pertinente. L’enterprise search désigne un système similaire au web search visant à faciliter la recherche d’information. Les données provenant de sources telles que les emails, l’intranet, les systèmes de gestion documentaires et les bases de données sont rassemblées et indexées tel qu’il soit aisé de naviguer et de retrouver du contenu. Ce système permet aussi de gérer la sécurité et les accès à l’information. Compte tenu du volume et de la complexité des données générées, il est parfois difficile et long d’accéder à l’information pertinente. En effet selon la façon dont la requête est effectuée, les moteurs de recherche retournent une liste plus ou moins longue de résultats que l’utilisateur doit passer en revue un par un pour retrouver l’information désirée.
La solution décrite ici se focalise sur l’implémentation d’un outil de recherche rapide type « web » et n’inclut pas la construction de thésaurus; les thésaurus apportent précision et spécificité mais ils requièrent des moyens et un effort manuel considérables.
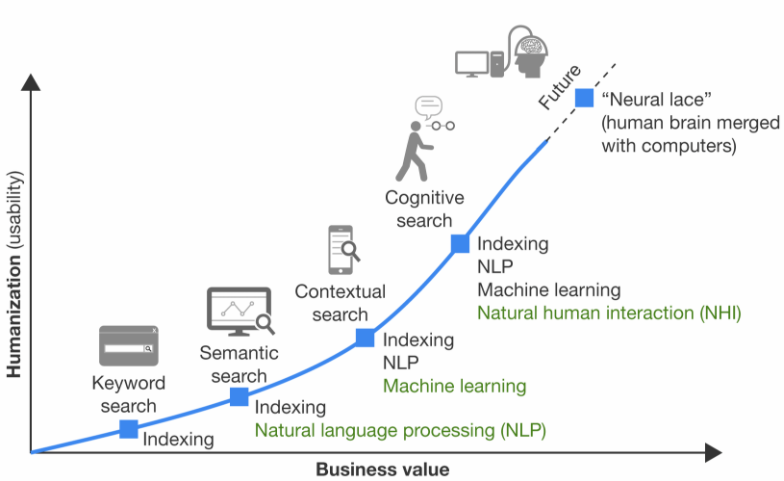
Une nouvelle approche du enterprise search dite cognitive search, a été développée dans l’optique d’exploiter au mieux les données contenues dans les documents de l’entreprise et de proposer des résultats plus ciblés ; le cognitive search permet d’aller plus loin en intégrant le traitement automatique du langage naturel (NLP) et l’intelligence artificielle. Ces techniques sont utilisées pour enrichir l’information, elles permettent au système d’interpréter la requête et de proposer un résultat ciblé et pertinent. Cette approche est dite cognitive car elle tient compte du contexte et des préférences de l’utilisateur pour la recherche et s’améliore avec l’utilisation. On peut la caractériser par les points suivants :
- Capacité d’intégrer les données ayant différents formats et provenant d’une multitude de sources externes et internes telles que les bases de données RDBMS/NO SQL, Sharepoint, les emails, …
- Possibilité d’enrichir les données grâce à l’utilisation du NLP et de l’apprentissage automatique. En appliquant des techniques telles que l’extraction d’entités et de concepts, la classification, l’extraction des relations entre entités et la détection de thèmes (topic detection),
- Personnalisation et contextualisation de l’information en combinant entre autre le moteur de recherche à une base de connaissance graphe (Knowledge Graph),
- Adaptabilité à l’utilisateur en utilisant par exemple les systèmes de recommandations qui proposent des résultats basés sur les précédentes requêtes d’utilisateurs,
- Capacité de s’améliorer au cours du temps c.-à-d. améliorer la pertinence des résultats.

Cette technologie présente un avantage particulier pour le secteur public qui génère une énorme masse de documents, répartis dans plusieurs bases de données sous différents formats. Les utilisateurs doivent pouvoir analyser et traiter des documents de manière rapide et efficace, en tenant compte des règles d’application dans leur domaine. Ces règles sont stockées dans des bases de connaissances mais changent régulièrement en fonction des politiques gouvernementales. Il est donc important pour assurer le traitement correct et équitable des dossiers que ces bases de données soient à jour et faciles à consulter. L’autre avantage qu’apporterait un système de recherche dit cognitif est qu’il tient compte du contexte et donne un résultat ciblé, on pourrait donc changer de paradigme ; l’utilisateur ne doit plus chercher activement un document dans la base de données mais en fonction du contexte et du processus (business process) dans lequel il évolue, les documents/ l’information lui sont suggérés. En outre un système, rapide et spécifique, pourrait facilement s’intégrer avec des applications qui exécutent des requêtes tels que les chatbots, voire des applications mobiles. Une base de connaissance graphe (knowledge graph) associée au cognitive search permettrait aussi de mettre en évidence la connaissance « cachée » c.-à-d. découvrir des liens entre entités, des régularités ou des anomalies. Le cognitive search ne serait donc pas seulement utilisé pour rechercher du contenu mais il permettrait aussi de découvrir de la connaissance (knowledge discovery). Ceci est notamment appliqué dans l’industrie des sciences du vivant pour accélérer le développement de nouveaux traitements. Dans ce contexte, la technologie est utilisée pour extraire la connaissance générée par les équipes de recherche et contenue dans les LIMS (laboratory information management system), ELN (electronic lab notebook) , base de données scientifiques, etc (solution développée par ATTIVIO).
En résumé, le cognitive search offre beaucoup de possibilités et de facilités en termes de recherche d’information. Cette technologie permet à l’utilisateur de retrouver rapidement du contenu pertinent et contextualisé. Néanmoins son implémentation est complexe et à ses limites. Il faut ingérer l’information provenant de sources diverses sous différents formats et en extraire des textes qui seront indexés. Les algorithmes utilisés par exemple pour les systèmes de recommandations et d’extraction d’entités nécessitent d’être entrainés avec des données de qualité. Très souvent, ces modèles générés par apprentissage automatique ont une marge d’erreur non négligeable et il est alors nécessaire de les combiner avec des modèles basés sur des règles bien définies (rule-based). Il n’est pas non plus facile de mettre en place des solutions qui supportent plusieurs langues, étant assez générales pour inclure plusieurs domaines business tout en gardant la capacité de fournir des résultats de recherche pertinents. Et enfin, l’amélioration des performances du système de recherche ne se fait pas de façon totalement automatique. Par exemple, pour ce qui est de la solution développée par IBM (Watson Discovery), l’utilisateur doit fournir au système des exemples de requêtes types et classer les résultats retournés par celui-ci.
Etant donné ces difficultés, il est important de bien mesurer les avantages et inconvénients d’un tel système avant d’envisager de l’implémenter. Cependant, les fonctionnalités de recherche avancée qu’apporte le Cognitive Search restent impressionnantes si l’on accepte une certaine marge d’erreur.
Références
The Forrester Wave™: Cognitive Search And Knowledge Discovery Solutions, Q2 2017
5-Minute Guide to Cognitive Search for the Life Sciences (ATTIVIO)
https://azure.microsoft.com/en-in/blog/global-scale-ai-with-azure-cognitive-services
ttps://www.ibm.com/cloud/garage/architectures/cognitiveDiscoveryDomain/