Dans notre article précédent, nous présentions les difficultés que nous avons rencontrées dans notre tentative de géocoder (convertir une adresse en coordonnées géographiques, et standardiser cette adresse) avec Nominatim, le géocodeur d’OpenStreetMap. Nous avons aussi évoqué qu’en modifiant légèrement les adresses que Nominatim n’avait par reconnues, elles le devenaient. Nous avons considéré un ensemble de modifications, que nous appelons ci-dessous des “transformers“. Nous présentons ensuite comment des combinaisons de transformers nous ont permis de notablement améliorer le “matching rate”, c’est-à-dire la proportion d’adresses reconnues par Nominatim.
Nous mettons à disposition le code (Python) qui permet d’appliquer la logique présentée ci-dessous, soit en mode “batch”, soit via une API REST :
https://github.com/SmalsResearch/NominatimWrapper.
Une version plus détaillée de ce travail sera disponible sous peu, incluant une comparaison fonctionnelle et de performance, entre la solution que nous proposons, le logiciel Trillium (utilisé chez Smals) et le projet BeStAddress (source authentique d’adresses en Belgique).
Principe de “Transformers”
![]() Le principe général de notre solution est le suivant : avant d’envoyer les adresses à OpenStreetMap, on les fera passer par un séquence (éventuellement vide) d’opérateurs, nommés “transformers” ci-dessous, visant à les nettoyer. Les résultats d’OSM seront ensuite analysés, pour éventuellement rejeter certains résultats (avec la méthode de vérification des résultats présentée dans notre article précédent). Pour toutes les adresses qui n’ont pas donné de résultats (soit parce qu’OSM n’a donné aucun résultat, soit parce que ceux-ci ont été rejetés), nous appliquons une autre séquence de “transformers” avant ré-envoi, et ce jusqu’à ce que soit toutes les adresses ont donné un résultat, soit toutes les séquences de transformers définies ont été épuisées.
Le principe général de notre solution est le suivant : avant d’envoyer les adresses à OpenStreetMap, on les fera passer par un séquence (éventuellement vide) d’opérateurs, nommés “transformers” ci-dessous, visant à les nettoyer. Les résultats d’OSM seront ensuite analysés, pour éventuellement rejeter certains résultats (avec la méthode de vérification des résultats présentée dans notre article précédent). Pour toutes les adresses qui n’ont pas donné de résultats (soit parce qu’OSM n’a donné aucun résultat, soit parce que ceux-ci ont été rejetés), nous appliquons une autre séquence de “transformers” avant ré-envoi, et ce jusqu’à ce que soit toutes les adresses ont donné un résultat, soit toutes les séquences de transformers définies ont été épuisées.
Suppression du numéro
Il est fréquent que Nominatim ne renvoie aucun résultat pour une adresse, mais qu’il en retourne un si l’on supprime le numéro. Ce premier transformer est donc très simple : il supprime simplement toute valeur du champ “house_number”.
Il faut être conscient qu’on baisse la fiabilité, puisqu’il ne sera plus possible d’obtenir un résultat précis au niveau du bâtiment (place rank=30). Mais un résultat, même imprécis, reste meilleur qu’une absence de résultat.
Remplacement par expression régulière
Notre expérience nous a montré qu’il est fréquent de trouver des conventions peu habituelles. Par exemple, dans l’exemple détaillé ci-dessous, de nombreuses adresses sont écrites sous la forme “A FONSNY” ou “R DE LA LOI”. Nous avons aussi rencontré un grand nombre d’adresses du type “Fonsny (Avenue)” ou “Loi (Rue de la)”. Ou encore “Rue de l été”. Voire encore “SN” (sans numéro) dans le champs du numéro.
Ce genre d’adresse peut facilement être corrigée par un replacement par expression régulière. Par exemple, le cas de l’apostrophe manquante peut être corrigé en remplaçant toute occurrence de ” de l ” par ” de l’”. L’ensemble des expressions à considérer sera typiquement dépendant du dataset et des habitudes et convention que l’on y observera.
Libpostal
La librairie libpostal, présentée dans notre article précédent, est un utilitaire permettant de parser un adresse, c’est-à-dire identifier ses différentes composantes. Si on lui soumet par exemple “Smals, Avenue Fonsny 20 bte 5, 1060 Saint-Gilles”, on obtiendra comme résultat :
[('smals', 'house'),
('avenue fonsny', 'road'),
('20', 'house_number'),
('bte 5', 'unit'),
('1060', 'postcode'),
('saint-gilles', 'city')]
Il devient alors facile d’ignorer les éléments qui ne font pas réellement partie de l’adresse (‘smals’, ‘house’) et ce qui décrit la boite ou l’étage (‘bte 5’, ‘unit’), de façon à ne pas les envoyer à OSM.
Photon
Photon est un utilitaire qui combine OpenStreetMap et ElasticSearch, également présenté dans notre article précédent. Il est nettement moins sensible aux fautes de frappe que Nominatim.
Les adresses, non trouvées jusqu’ici par Nominatim, sont envoyée à Photon (une API). On vérifie que le résultat est raisonnablement proche de l’adresse initiale, puis on la renvoie à Nominatim.
Prenons l’exemple de la « Rue de Brabant », à 1030 Schaerbeek, qui serait erronément orthographiée « Rue du Brabant ». Envoyé à Nominatim, nous n’obtenons aucun résultat :
Photon, pour la même rue, va en fait retourner dans son résultat une série de rues avoisinant la rue en question :
http://photon.komoot.de/api/?q=RUE%20DU%20BRABANT,%201030%20SCHAERBEEK
On a dans le résultat, certes la « Rue de Brabant », mais également « Rue du Pavillon », « Rue du Saphir », …. Seul le premier résultat sera gardé et renvoyé à Nominatim, qui proposera cette fois-ci un résultat.
Suppression de la rue
En dernier recours, lorsqu’aucune (séquence de) transformation n’a permis à Nominatim de trouver une adresse, nous supprimons la rue (et le numéro), dans l’espoir qu’au moins la localité soit reconnue. Il va de soi qu’un “match” d’une adresse ayant subi cette modification n’aura pas le même poids qu’un “match” sur une adresse complète.
Expérimentations
Comme pour nos articles précédents, nous avons repris les adresses disponibles en open data, de la Banque Carrefour des Entreprises, en Belgique (https://kbopub.economie.fgov.be/kbo-open-data/login?lang=fr). Cette base de données contient 3,112 millions d’adresses d’entreprises, dont 3,027 millions en Belgique.
Dans un premier temps, nous avons envoyé les adresses telles quelles. 83,3 % (matching rate) des adresses ont donné un résultat accepté par nos règles de vérifications présentées ci-dessus (qui en ont seulement rejeté 0,46 %). Nous avons ensuite appliqué une série de combinaisons de « transformers », présentées dans le tableau et la figures ci-contre. Au final, la séquence de transformers a permis de faire monter le taux de succès de 83,3 à 98,6 %, en 2 petites heures sur un serveur virtuel avec 8 cœurs et 24 GB de mémoire. Nous avons évalué plusieurs séquences de transformers (par exemple, d’abord suppression du numéro, puis libpostal, ou l’inverse), mais l’impact sur le résultat était en général très faible.
Le transformer “orig” ne fait aucune modification. Nous avons dans notre expérimentation utilisé deux variantes du transformer « regex » : un premier (regex[init] ci-dessous) permettait de nettoyer les adresses en entrée, principalement la suppression de tout texte apparaissant entre parenthèse. Le second (regex[lpost]) les adresses traitées par libpostal.
Le tableau ci-dessous indique, pour chaque étape, le nombre d’adresses ayant été envoyées à OSM (Sent), le nombre de résultats acceptés (Match), le ratio des deux (Match rate), le ratio par rapport au nombre d’adresses globales (Glob MR), ainsi que sa valeur cumulée (Cum MR). Cette dernière colonne nous permet de voir comment nous arrivons au « matching rate » de 98,64 % pour le dataset en question (99,97 en incluant « nostreet »).
Nous constatons que le « transformer » ayant eu le plus d’effet est le « regex[init] », essentiellement grâce à la suppression des parenthèses (10,43% d’amélioration), suivi de la combinaison libpostal + photon (2,84 %)
|
Method |
Sent |
Match |
Match rate (%) |
Glob MR |
Cum MR |
|
orig |
3.062.332 |
2.551.079 |
83,31 |
83,31 |
83,31 |
|
regex[init] |
348.011 |
319.321 |
91,76 |
10,43 |
93,73 |
|
nonum |
184.503 |
36.653 |
19,87 |
1,20 |
94,93 |
|
libpostal+regex[lpost] |
69.780 |
16.881 |
24,19 |
0,55 |
95,48 |
|
libpostal+regex[lpost]+nonum |
129.906 |
895 |
0,69 |
0,03 |
95,51 |
|
libpostal+regex[lpost]+photon |
91.867 |
86.853 |
94,54 |
2,84 |
98,35 |
|
libpostal+regex[lpost]+photon |
5.400 |
2.450 |
45,37 |
0,08 |
98,43 |
|
photon |
8.591 |
6.038 |
70,28 |
0,20 |
98,62 |
|
photon+nonum |
2.949 |
454 |
15,40 |
0,01 |
98,64 |
|
nostreet |
41.708 |
40.875 |
98,00 |
1,33 |
99,97 |
Notons que nous avons aussi appliqué notre méthode sur des adresses de moins bonne qualité, typiquement correspondant à des adresses encodées par des agents lors d’inspections. Nous avions alors un taux de succès initial de 65 %, que nos transformers ont pu faire grimper à 93 %.
Adresses non trouvées
Au total, 1,3%, soit de l’ordre de 30.000 adresses, n’ont pas été trouvées, ou seulement après suppression de la rue. Si l’on ignore les numéros de bâtiment, cela représente 6.123 couples rue-ville. Nous avons envoyé ces 6.123 au géocodeur de Here (Nokia). Nous avons trouvé un résultat pour 4.060 adresses. Parmi ces résultats, 580 ont un code postal différent des données, indiquant soit que le résultat est incorrect, soit que le code postal est incorrect dans les données.
Lorsque le code postal est compatible (3.480), 1.960 ont une rue (quasiment) identique à la rue en entrée. Il s’agirait probablement de bons candidats pour enrichir OpenStreetMap. Nombre d’entre elles sont effectivement présentes sur OSM, mais non nommées.
Parmi les 1.540 adresses restantes, nous constatons qu’elles sont fréquemment si mal encodées qu’il est peu probable qu’un processus fiable puisse les traiter sans prendre de grands risques. Il s’agit soit d’adresses très abrégées comme « 20 P.ST.GERY » (pour « Place Saint-Géry », avec un numéro qui devrait se trouver dans un champ adéquat) ou « A 11 NOVEMB. » (pour « Avenue du Onze Novembre »), soit des informations plutôt descriptives (« Maison communale », « Hôtel XXX », « Ferme de XXX », « Café XXX », « Centre commercial XXX »…). Nous remarquons que souvent, la réponse proposée par Here est suspecte, et mériterait des investigations que nous n’avons pas menées dans le cadre de ce travail.
Numérotation
Dans les résultats fournis par OSM, 49,4 % contenant un numéro de bâtiment (avec un place_rank à 30) et 50 % n’en contenait pas (place_rank à 26), alors que seul 1,1 % n’avait pas d’information dans la champ numéro (0,8 % si on considère les numéros présents dans le champ de la rue). Si l’objectif est de géocoder les adresses, c’est-à-dire de les convertir en coordonnées géographiques, nous ne pouvons vraisemblablement pas faire mieux avec OSM, et devons simplement savoir que la moitié des points ont une précision au niveau de la rue.
S’il s’agit par contre de nettoyer les adresses, auxquelles on doit pouvoir envoyer une lettre ou un agent, il va de soi que l’on ne peut pas se contenter d’adresses où la moitié des numéros manque. Par ailleurs, plusieurs transformers ont potentiellement simplifié les numéros (22 bte 5 vers 22). Nous avons donc choisi d’enrichir les données résultat avec un numéro de bâtiment supplémentaire, suivant le principe suivant :
- Si le numéro est présent dans l’adresse en entrée, on le reprend
- Sinon, on applique « libpostal ». Si ce « parsing » donne un numéro, on le garde.
En faisant ceci (on calcule donc le numéro uniquement sur base des données en entrée, et non sur le résultat d’OSM), on a donc un numéro dans 99,2 % des cas (cf les 0,8 % évoqués ci-dessus).
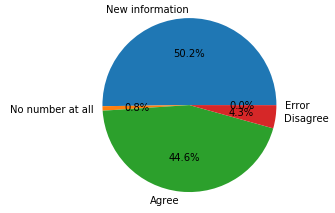 Pour 50,2 % des adresses, il s’agit d’une information que OSM n’avait pas fournie. Dans 44.6 % des cas, elle est identique à celle d’OSM. Dans 4,3% des cas, il y a une différence, essentiellement constituée de différentes façons d’écrire « la même chose » (« 10 » au lieu de « 10-12 », « 10 ;12 » au lieu de « 10-12 ») ou presque (« 10 » au lieu de « 10 a »). Nous avons également identifié quelques très rares cas, où quand on fournissait à Nominatim une adresse sans numéro, il y en avait un dans le résultat.
Pour 50,2 % des adresses, il s’agit d’une information que OSM n’avait pas fournie. Dans 44.6 % des cas, elle est identique à celle d’OSM. Dans 4,3% des cas, il y a une différence, essentiellement constituée de différentes façons d’écrire « la même chose » (« 10 » au lieu de « 10-12 », « 10 ;12 » au lieu de « 10-12 ») ou presque (« 10 » au lieu de « 10 a »). Nous avons également identifié quelques très rares cas, où quand on fournissait à Nominatim une adresse sans numéro, il y en avait un dans le résultat.
Conclusions
Au travers de ce travail, nous avons pu répondre aux principales contraintes que nous rencontrions, à savoir proposer une solution efficace de géocodage (standardisation des adresses, et calcul des coordonnées géographiques), on-premise et open source. Les difficultés étaient nombreuses, mais toutes ont pu être résolues avec des solutions ouvertes et gratuites : OpenStreetMap, Photon et Libpostal.
Notre solution est disponible en open source : https://github.com/SmalsResearch/NominatimWrapper
Il reste certes des pistes d’amélioration, mais le niveau de ce que nous offrons est déjà largement supérieur à ce qu’OpenStreetMap offre de base.
____________
Ce post est une contribution individuelle de Vandy Berten, Data Science Expert chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.