Dans nos blogs précédents (1, 2, 3, 4), nous avons mis en évidence le fait que les structures de graphes étaient très adaptées à la recherche de comportement frauduleux. En étant plongés quotidiennement dans des données issues de diverses bases de données officielles, nous sommes également confrontés en permanence à la présence d’une grande quantité d’information de mauvaise qualité (1, 2). Nous allons voir dans ce blog comment des recherches de fraudes peuvent être réalisées même si les données déclarées sont de mauvaise qualité.
Certaines parties de cet article, plus techniques, seront masquées. Si les détails vous intéressent, il vous suffira de cliquer sur les liens « Cliquer ici pour plus de détails », ou de c
Supposons qu’un organisme public soit responsable de la gestion de la sous-traitance entre entreprises, et que, chaque fois qu’une entreprise fait appel à un sous-traitant, elle doive le déclarer auprès de cet organisme. Les données issues de ces déclarations peuvent alors être vues comme un graphe, dans lequel un nœud représente une entreprise, et une relation entre deux nœuds A et B, le fait que B est un sous-traitant de A. Si A sous-traite auprès de B, et B auprès de C, on notera cela de la façon suivante (en s’inspirant de la notation de Cypher, langage de Neo4j) :
(A)-->(B)-->(C)
Imaginons une loi (un peu simpliste et fantaisiste) disant qu’une entreprise ne peut pas être sa propre sous-traitante, ni directement, ni indirectement. Les structures suivantes seraient donc considérées comme « frauduleuses » :
(A)-->(A) (A)-->(B)-->(C)-->(A)
Du point de vue de la théorie des graphes, on veut en fait s’assurer qu’il n’y a pas de cycle dans le graphe de description des sous-traitances, graphe étant dirigé, puisque les arcs ont une direction. On parle dès lors de « Graphe Dirigé Acyclique » (DAG). Le schéma ci-dessous montre une structure acceptable, dans laquelle aucune entreprise n’est son propre sous-traitant, même indirectement.
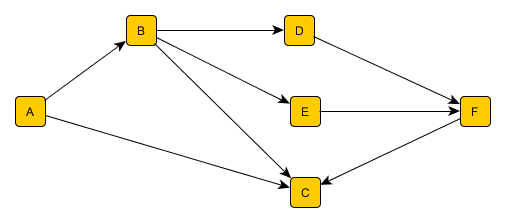
En Cypher (dont la syntaxe a été brièvement présentée dans notre article précédent), en supposant que les entreprises soient de type « Company », et les relations de type « Subcontractor », on pourra écrire la requête suivante, qui retournera une entreprise, et le cycle dont elle fait partie :
(1) MATCH p=(a:Company)-[:Subcontractor*]->(a)
RETURN a, p
Pour des raisons de performances, il sera souvent préférable de limiter la longueur des cycles : (a:Company)-[:Subcontractor*..5]->(a).
Qualité des données
Supposons maintenant que le système de déclaration ne soit pas très contraignant, et que, quand une entreprise déclare une sous-traitance, elle ne soit pas obligée de donner un identifiant officiel de l’entreprise en question (un numéro d’entreprise ou d’employeur attribué par l’état), mais puisse se contenter d’en donner le nom, et éventuellement l’adresse. On peut donc avoir une situation dans laquelle (A) déclare correctement sa sous-traitance vers (B) (c’est-à-dire avec un numéro d’entreprise officiel), idem pour (B) envers (C), mais par contre, (C) déclare sa sous-traitance vers (A) sans en préciser l’identifiant, mais uniquement le nom. On aura dans la base de données associée à la déclaration, deux nœuds, avec les attributs suivants :
- (A) : ID : 12345, Nom : « Mon Entreprise SA »
- (A’) : ID : <vide>, Nom : « Mon Entreprise SA »
L’organisme récoltant les données n’a ici aucun moyen de s’assurer que les entreprises (A) et (A’) sont en fait la même entreprise. Il existe des multitudes de synonymes d’entreprise. On trouve des « Coiffeur Rolland » dans bon nombre de villes, et les boulangeries « La baguette dorée » sont légion.
La cycle ci-dessus devient alors une chaîne (non fermée) : (A)–>(B)–>(C)–>(A’) , et la recherche évoquée plus haut ne permet plus de détecter le comportement frauduleux.
L’approche classique
Une approche classique de ce problème consiste à utiliser des outils de « Data Quality » (comme l’outil open-source OpenRefine, ou le logiciel commercial Trillium aux fonctionnalités beaucoup plus avancées), pour, en fonction de critères définis, fusionner certains enregistrements de la base de données. On peut par exemple décider que si on trouve deux enregistrements avec exactement le même nom d’entreprise, se trouvant dans la même rue, on les fusionne en considérant qu’il s’agit de la même entreprise. On peut par ailleurs décider que si les deux noms sont similaires, mais ont la même adresse, alors on les fusionne également.
Les outils, en particulier les suites professionnelles comme Trillium, permettent de définir finement le degré de proximité que l’on acceptera entre deux dénominations ou adresses (ou, plus généralement, toute information) pour les considérer comme « identiques » (on ne va pas uniquement considérer des chaînes de caractères exactement identiques). Par ailleurs, nous n’évoquons ici que la problématique de la détection de (présomption de) doublons : le domaine de la « Data Quality » s’intéresse à bien d’autres aspects : incohérence de données, comparaison entre différentes sources, profilage des données, standardisation…
Notons qu’on va souvent effectuer cette fusion non pas dans les données de production, mais dans une copie servant à faire des analyses et des recherches de fraude.
Mais cette approche, très efficace dans de nombreuses situations, a principalement deux limites :
- Elle permet de fusionner des informations tabulaires plates (une entreprise avec un nom, une adresse, éventuellement une catégorie d’entreprise, le nom du gérant, voire des dates de création ou autres événements), mais est plus complexe pour des structures plus élaborées. On s’en sort encore sans trop de dommages si on considère que chaque entreprise peut avoir plusieurs adresses (correspondant à plusieurs implantations, ou à l’historique du siège principal), mais si l’on veut considérer, en l’absence d’adresse, les travailleurs communs aux « deux » entreprises, ou les administrateurs (ou autres client, fournisseur…), cette approche relativement statique n’est plus tenable.
- Elle impose de choisir, avant l’analyse des données, les critères de fusion. Or il s’avère parfois utile de faire ce choix plus tard dans l’analyse, soit parce que, en fonction de l’analyse, on veut être plus ou moins stricte sur la façon de faire cette fusion, soit parce que, dans une analyse particulière, on veut identifier un schéma passant par plusieurs « chemin de duplicatas », n’ayant pas tous le même degré de certitude.
Nous proposons dès lors une approche qui combine à la fois les possibilités offertes par les bases de données orientées graphes (« Graph Databases ») et les outils de gestion de qualité de données (« Data Quality tools »).
Une autre approche
L’approche que nous décrivons ici permet de traiter les doublons d’entreprises, mais une approche très similaire pourra être utile pour détecter les doublons de personnes, ou de toute autre entité.
La première étape de notre approche consistera à identifier les entreprises dont le nom est identique, ou similaire (selon un niveau d’exigence que l’on peut définir). Dans cette première étape, on ne considère que le nom de l’entreprise, et pas les autres attributs (adresses, travailleurs…)
Cliquer ici pour plus de détails à propos de cette première étape.
Pour cette étape, l’utilisation d’un outil de « Data Quality » pourra s’avérer être un allié précieux. On peut cependant effectuer avec des outils classiques (R, Python avec Pandas…) de traitement de données une partie (basique) de ces opérations. Supposons deux enregistrements avec pour nom « Ma Société S.A. », et « MA SOCIETE ». Nous effectuons les opérations suivantes sur ces deux chaînes de caractères :
- Mettre tous les noms en majuscules : « MA SOCIÉTÉ S.A. » et « MA SOCIETE »
- Enlever tous les accents et autres signes diacritiques (cédilles, trémas…) : « MA SOCIETE S.A. » et « MA SOCIETE »
- Enlever les symboles non-alpha numériques : « MA SOCIETE SA » et « MA SOCIETE »
- Enlever les formes légales (SA, SARL, SPRL…) : « MA SOCIETE » et « MA SOCIETE »
Notons que pour cette dernière étape, il faudra être prudent : il est fréquent qu’une entreprise, pour diverses raisons, se sépare en plusieurs entités juridiquement distinctes, mais portant le même nom (mise à part éventuellement la forme légale rajoutée en suffixe). Pour certaines analyses, il est important de considérer qu’il s’agit bien de deux entreprises ; pour d’autres, en revanche, on préférera les traiter comme une même entité. Plutôt que de supprimer la forme légale, on peut préférer la déplacer dans un champ distinct.
On peut aller encore un peu plus loin avec des approches plus « fuzzy », permettant d’accepter des fautes de frappe : « Ma Société » et « Ma Socéité » ne donneront pas la même version « nettoyée », mais sont néanmoins très proches. Avec des méthodes telles que les distances de Levenshtein ou de Jaro-Winkler, souvent utilisées avec une méthode de regroupement comme le Metaphone ou le Soundex. Nous ne donnerons pas plus de détails ici, mais un outil comme Trillium permet des stratégies bien plus élaborées que ce que nous décrivons ici.
Après ces étapes de nettoyage, toutes les entreprises (ou plus précisément tous les enregistrements d’entreprise) dont le nom est considéré comme identique ou presque, seront regroupées (mais pas fusionnés). Dans notre base de données, on créera alors un nœud d’un nouveau type (nous avions déjà implicitement un type de nœud « Company »), que nous appellerons « Denomination_group »
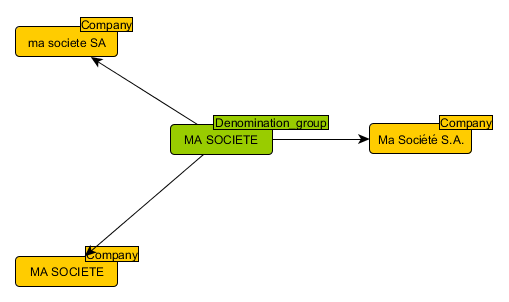
Gestion des adresses
En parallèle avec cette gestion de dénomination, il s’agira également de traiter les adresses dont on dispose pour une entreprise. Il peut s’agir d’une seule adresse, mais également de plusieurs adresses par entreprise, soit parce que celle-ci dispose de plusieurs sites, soit parce que l’on dispose de l’historique des adresses.
Cliquer ici pour plus de détails à propos de la qualité des adresses
Un problème que l’on rencontre presque systématiquement quand des adresses sont collectées, en particulier lorsqu’elles viennent de pays différents, est leur absence de normalisation. Une même adresse pourra être écrite dans un enregistrement « Avenue Fonsny, 20, 1060 Saint-Gilles, Belgique », puis « Av. Fonsny, 20-22, 1060 Bruxelles, Belgique ». Nous avons par ailleurs en Belgique, et en particulier à Bruxelles, la difficulté supplémentaire que les adresses peuvent être écrites dans deux langues : « Fonsnylaan 20, 1060 Brussel ». Pour éviter de passer à côté d’un grand nombre d’erreurs, il est indispensable, pour effectuer ce nettoyage, de passer par un outil adapté (comme par exemple Trillium). Ces outils disposent de bases de connaissance permettant même de corriger des adresses erronément introduites, comme par exemple « Avenue Fonsny 20, 1160 Bruxelles » (au lieu de 1060).
Une fois les adresses normalisées, on va considérer dans notre base de données un nœud par rue, et un lien (avec en attribut le numéro de la boite) entre une entreprise et la rue où celle-ci a un siège.
Nous pourrions éventuellement considérer un nœud par adresse (et non par rue), mais cela fera exploser le nombre de nœuds, et donnera moins de souplesse par la suite, comme nous le verrons plus loin.
Autres liens
On peut imaginer qu’un organisme dispose d’autres informations. Par exemple, un système dans lequel les entreprises doivent déclarer leurs travailleurs, et où le contrôle au niveau de l’entreprise est faible (ce qui est typiquement le cas des travailleurs « détachés », ayant leur employeur dans un pays A, mais travaillant – généralement temporairement – dans un pays B. Ils doivent alors être déclarés dans le pays B, mais qui peut alors difficilement imposer un système d’identification standardisé).
Dans de tels cas, on pourrait utiliser les travailleurs comme entités supplémentaires. On peut aussi se servir des administrateurs ou des gérants si l’on dispose de ce type d’information.
Combiner noms et adresses
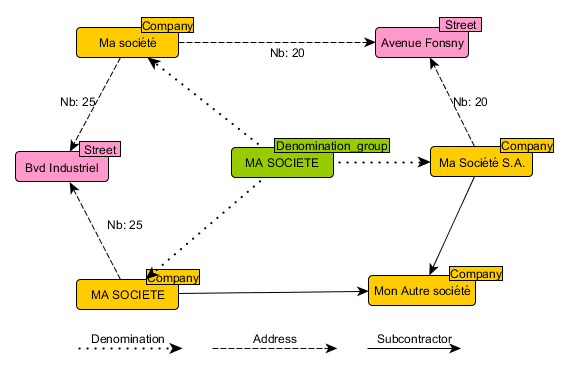
Considérons maintenant plusieurs enregistrements dans notre base de données de sous-traitance. Nous supposons que « Ma Société » a déménagé, on trouve donc des données à deux adresses différentes :
| ID national | Dénomination | Adresse | |
| 1 | Ma société S.A | Avenue Fonsny 20 | |
| 2 | MA SOCIETE | Boulevard Industriel 25 | |
| 3 | 1234 | Ma Société | Avenue Fonsny 20 |
| 4 | 1234 | Ma Société | Boulevard Industriel 25 |
On aura dans notre base de données graphes trois nœuds « Company » : (-, « Ma société S.A »), (-, « MA SOCIETE »), et (1234, « Ma Société »), et deux rues : « Avenue Fonsny » et « Boulevard Industriel » (nous supposons que les adresses ont été normalisées au préalable), comme on peut le voir dans la figure ci-dessus.
Les versions nettoyées des trois sociétés donnent la même chaîne de caractères, et seront regroupées autour d’un nœud « Denomination_group », comme le montre le schéma ci-dessus.
On pourra maintenant rechercher un cycle entre deux compagnies A1 et A2, avec de forts soupçons de doublons.
(2) MATCH
(A1:Company)-[:Subcontractor*]->(A2:Company),
(A1)-->(:Denomination_group)<--(A2),
(A1)-->(:Street)<--(A2)
RETURN …
La première ligne indique donc qu’il y a un chemin de sous-traitance entre A1 et A2 ; la seconde que A1 et A2 portent le même nom (après nettoyage, ou éventuellement après application d’un algorithme tel que la distance de Levenshtein), et la troisième que A1 et A2 sont renseignées dans la même rue.
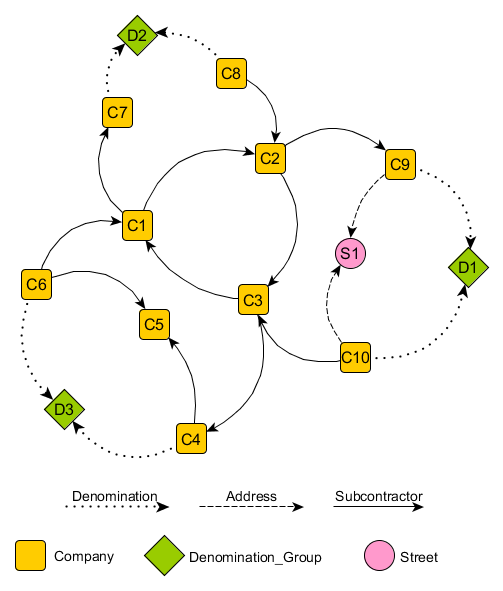
Dans le schéma ci-dessus, la requête (1) plus haut aurait retourné la chaîne
(C1)–>(C2)–>(C3)–>(C1).
La requête (2) retournera quant à elle
(C10)–>(C3)–>(C1)–>(C2)–>(C9),
avec D1 comme nœud « Denomination_group » et S1 comme « Street », A1 et A2 correspondant respectivement à C10 et C9.
Cliquer ici pour plus de détails à propos des adresses identiques
La requête (2) ci-dessus explicite qu’il est suffisant que deux entreprises de même nom (ou presque) partagent la même rue pour être considérées comme des doublons. Si l’on veut être plus sévère, et imposer exactement la même adresse (après standardisation), il suffira de rajouter une contrainte sur les relations entre les nœuds « Company » et les nœuds « Street », imposant le même numéro de maison :
(2bis) MATCH
(A1:Company)-[:Subcontractor*]->(A2:Company),
(A1)-->(:Denomination_group)<--(A2),
(A1)-[str1:Address]->(:Street)<-[str2:Address]-(A2)
WHERE str1.NUMBER = str2.NUMBER
RETURN …
On peut aussi imaginer que l’on va considérer comme fortement suspect deux entreprises de même nom, ayant un même sous-traitant (sans considérer les adresses, qui pourraient être souvent manquantes) :
(3) MATCH
(A1:Company)-[:Subcontractor*]->(A2:Company),
(A1)-->(: Denomination_group)<--(A2),
(A1)- [:Subcontractor]->(B:Company)<- [:Subcontractor]-(A2)
RETURN …
Cette requête retournera alors
(C6)–>(C1)–>(C2)–>(C3)–>(C4),
C5 correspondant à B, et D3 au « Denomination_group ».
Cliquer ici pour voir comme gérer plusieurs duplicatas
Notons que dans les deux requêtes ci-dessus, une seule entreprise de la chaîne peut avoir été mal encodée (une fois en A1, une fois en A2). Il n’est pas très difficile d’imaginer une requête où deux entreprises de la chaîne sont dédoublées. On peut même appliquer une contrainte différente dans les deux doublons :
(4) MATCH
(A1:Company)-[:Subcontractor*]->(B1:Company) -->(:Duplication_group)
<-- (B2:Company)-[:Subcontractor*]->(A2:Company),
(A1)-->(:Duplication_group)<--(A2),
(A1)-->(:Street)<--(A2)
RETURN …
Dans cette requête, on se satisfait du fait que B1 et B2 aient le même nom, par contre on imposera en plus à A1 et A2 d’avoir également la même adresse. Cette requête n’aurait pas été possible si l’on avait dû décider au préalable des règles à appliquer pour déterminer des doublons, et les règles auraient dès lors dues être les mêmes pour A1 vs A2 que pour B1 vs B2. On laisse ensuite à un être humain le soin de déterminer, en fonction de sa connaissance métier et d’information qui ne seraient pas dans la base de données, si B1 et B2 sont effectivement des enregistrements correspondant à la même entreprise.
Dans le schéma ci-dessus, la première ligne correspond au chemin
(C10)–>(C3)–>(C1)–>(C7)–>(D2)<–(C8)–>(C2)–>(C9)
(avec A1 : C10, B1 : C7, B2 : C8 et A2 : C9).
Technique hybrides
Plutôt que de gérer la totalité des doublons dans la base de données graphes, en se servant uniquement des Data Quality tools pour corriger les adresses et détecter les homonymes d’entreprises, on peut aussi considérer une technique hybride. On peut par exemple considérer une première phase, basée sur un Data Quality tool, de fusion de tous les enregistrements qui constituent à coup sûr un doublon (ou avec un niveau de certitude choisi) : par exemple, exactement la même dénomination, exactement la même adresse (les outils avancés permettent bien sûr de faire des choses bien plus complexes que ceci, gérant des dénominations similaires plutôt qu’exactes). Nous avons par exemple dans une base de données que nous exploitons plus de 1000 fois la même entreprise décrite, avec le même nom et la même adresse (mais où le numéro d’entreprise n’a pas été déclaré).
Les données ainsi « compactées » pourront alors être intégrées dans une base de données graphe, dans laquelle on recherchera des structures de doublons plus complexes (en se servant également d’autres informations, comme les travailleurs ou mandataires communs, ou plus généralement le voisinage), ou plus faible.
On pourrait aussi utiliser les techniques décrites ci-dessus pour fusionner, directement dans la base de données graphe, tous les nœuds considérés comme des doublons. Cela permettra de simplifier les requêtes par la suite, tout en permettant de garder une certaine souplesse : on fusionnera uniquement les cas « sûrs » (selon des critères que l’on devra définir), et laissera la possibilité de considérer des doublons moins certains dans les requêtes.
Conclusion
Notre expérience dans la lutte contre la fraude nous a montré ces dernières années qu’il est primordial de tenir compte de la qualité des données sur lesquelles on travaille. Mais elle nous a aussi montré que, dans le cadre d’un travail de « datamining », traiter la totalité de la problématique de qualité en amont, dans une phase de pré-traitement, n’est pas toujours optimal. Le degré de certitude exigé peut varier d’une analyse à l’autre et une certaine souplesse peut être nécessaire dans des phases plus avancées.
Néanmoins, en aucun cas il ne sera envisageable de se passer des outils de Data Quality :
- Nous n’évoquons ici que l’aspect « détection de (présomption de) doublons » ; les outils de Data Quality ont de nombreuses autres fonctionnalités indispensables.
- Notre approche suppose que l’on est capable de déterminer que deux dénominations d’entreprises sont « considérées comme identiques », même s’il y a des différentes orthographiques ou syntaxiques. Si l’on veut pour ce faire utiliser des méthodes plus avancées que des simples distances de Levenshtein, l’utilisation d’outil adapté sera nécessaire.
- Nous supposons également que nous sommes capable d’identifier que deux adresses sont identiques, ce qui est bien plus complexe que de vérifier la similitude entre deux chaînes de caractères. Pour cette tâche, l’utilisation d’outils disposant de base de connaissance sera indispensable.
L’approche que nous proposons ici permet de combiner, pour la problématique du dédoublonnage et dans le cadre d’une analyse effectuée sur une base de données graphe, travail partiel de Data Quality en pré-traitement et analyse métier tenant compte des résultats obtenus. L’idée générale sera d’appliquer le principe de « Keep the power where it belongs » : combiner de façon optimale un outil de Data Quality (pour la comparaison de contenus textuels) et Graph Database (pour l’exploitation des relations).
En appliquant cette méthodologie sur des cas concrets, de multiples cas problématiques (c’est-à-dire des suspicions de fraude) ont pu être trouvés et soumis à divers services d’inspection, que des analyses plus classiques n’avaient jusqu’ici pas permis de déceler.