Data Quality Tools
-
“Data Observability”, een nieuwe topic in het “Data Quality” landschap?
In de afgelopen twee jaar zijn er steeds meer tools voor “data observability” verschenen: voegen ze waarde toe aan het landschap van gegevenskwaliteit? Wat zijn hun potentiële functies met betrekking tot preventieve en curatieve benaderingen van gegevenskwaliteit? Hoe volwassen zijn deze tools op dit moment?
-

OpenRefine – Outils d’analyse et de raffinement de données
(FR) OpenRefine est une très bonne alternative gratuite aux outils professionnels d’analyse de qualité de données, souvent hors de prix pour des petites organisations. Il est par ailleurs beaucoup plus simple à utiliser, et permet une prise en main rapide, même sans connaissances poussées en informatique. (NL) OpenRefine is een zeer goed gratis alternatief voor de professionele tools voor kwaliteitsanalyse…
-

Typologie van de anomalieën, een kader voor actie: de case van machine learning
De kwaliteit van een gegeven is de geschiktheid ervan voor gebruik en voor de beoogde doelstellingen (‘fitness for use’) (Boydens, 1999, Boydens 2014). In dit artikel gaan we bekijken hoe een rigoureuze typologie van de anomalieën een kader biedt voor de verbetering van de kwaliteit van de gegevens, in verschillende domeinen, waaronder machine learning.
-
Typologie des anomalies, un cadre pour l’action : le cas du machine learning
La qualité d’une donnée désigne son adéquation aux usages et objectifs visés (« fitness for use ») (Boydens, 1999, Boydens 2014). Dans cet article nous allons voir comment une typologie rigoureuse des anomalies offre un cadre pour l’amélioration de la qualité des données, dans de nombreux domaines, dont le machine learning.
-
Data Quality Tools : retours d’expérience et nouveautés
Isabelle Boydens(*), Isabelle Corbesier(**) et Gani Hamiti(**) (*) Data Quality Expert, Research Team (**) Data Quality Analyst, Databases Team La problématique de la qualité des données (ou “fitness for use“, adéquation aux usages) est maintenant reconnue au plan international comme étant un facteur de succès à prendre en compte dans tout projet impliquant des bases de données. En 2016, T.…
-

Cours-conférence “Data Quality Tools”, ULB, 13 mars 2019, par Gani Hamiti, Smals
Gani Hamiti donnera un cours-conférence à l’ULB le 13 mars 2019 de 18 heures à 20 heures, suivi d’une réception. Dans le cadre du cours STIC-B-510 « Qualité de l’information et des documents numériques » de la filière STIC de l’Université libre de Bruxelles, Gani Hamiti, Data Quality Analyst chez Smals, donnera un cours-conférence intitulé « Data Quality Tools : concepts and practical lessons from a vast operational…
-
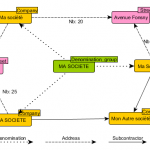
Gérer les doublons dans une Graph Database
Dans nos blogs précédents (1, 2, 3, 4), nous avons mis en évidence le fait que les structures de graphes étaient très adaptées à la recherche de comportement frauduleux. En étant plongés quotidiennement dans des données issues de diverses bases de données officielles, nous sommes également confrontés en permanence à la présence d’une grande quantité d’information de mauvaise qualité (1,…
-

Data simplification and abstraction (Part II) : pistes opérationnelles & ROI
Dans son rapport publié le 27 août 2015, l’ASA (Agence pour la Simplification Administrative) – DAV (Dienst Administratieve Vereenvouding) indique que les “les charges administratives ont connu une diminution globale en 2014 d’environ 400 millions d’euros” en Belgique, notamment via l’adoption de nouvelles réglementations et l’utilisation croissante de la facturation électronique. Nous proposons d’aborder ici un ensemble de “bonnes pratiques” concrètes…
-
Dix bonnes pratiques pour améliorer et maintenir la qualité des données
(dernière mise à jour : décembre 2021) Les bases de données se prêtent aux métaphores financières. Ne les désigne-t-on pas souvent par le terme « banques de données » ? Elles évoqueraient ainsi un capital d’information sur lequel on peut faire des retraits à la demande. A condition que le compte soit correctement approvisionné…(*) Vu l’actualité des enjeux soulevés, dès lors que l’information est un…
-
“Mapping the World of Data Problems” : la qualité des données vue par la communauté IT
En novembre 2012, O’Reilly Media a édité un “livre-événement” en matière de “data quality” : Q. E. McCallum, Bad Data Handbook, Mapping the World of Data Problems, O’Reilly Media, 2012, 246 p. Cet ouvrage collectif sur la qualité des données est inédit car il émane exclusivement de la communauté des web software developpers (Python, Perl script, Parallel R, NLP, cloud computing, …),…
Keywords:
analytics Artificial intelligence big data blockchain BPM chatbot cloud computing cost cutting cryptography data center data quality development EDA egov Event GIS Information management Machine Learning Managing IT costs methodology Mobile Natural Language Processing Open Source Privacy Productivity Security social software design software engineering standards