Ce blog introduit les modèles de langage statistiques qui sont nécessaires à la résolution de nombreux problèmes liés au traitement automatique du langage naturel ou NLP (Natural Language Processing). Parmi ces problèmes, on peut citer la traduction automatique, la reconnaissance vocale, les systèmes de questions-réponses, l’optical character recognition (OCR) et les problèmes de génération de langage naturel en général.
Qu’est-ce qu’un modèle de langage ?
Construire un modèle de langue statistique consiste à estimer une distribution de probabilité sur des séquences de mots[1] dans une langue particulière. Il permet ainsi d’assigner une probabilité à une séquence de mots.
Par exemple, dans un modèle de langage en français, la probabilité de la séquence « tous les matins je bois du café » sera supérieure à la probabilité de la séquence « du café je tous les matins bois ».
Ces modèles de langage sont statistiques c.-à-d. qu’ils ne sont pas définis par des règles formelles mais sont appris sur base d’un grand nombre de textes appelés aussi corpus.
Dans ce blog, nous aborderons les modèles dit n-grammes ainsi que les modèles neuronaux issus des avancées récentes du deep learning, ces derniers supplantant les modèles n-grammes en termes de performance.
Les modèles n-grammes
Ce sont les premiers modèles de langue, ils sont basés sur les chaînes de Markov. La probabilité d’une séquence de mots étant le produit des probabilités de chaque mot sachant les mots précédents, on introduit une simplification en prenant uniquement en compte les n mots précédents. Autrement dit, le modèle permet de prédire les mots suivants étant donné les n mots précédents.
Considérons la séquence de mots « m1 m2 m3 m4 », la probabilité d’obtenir cette séquence dans un modèle bigramme sera calculée de la façon suivante :
P(m1, m2, m3, m4) = P(m1)P(m2|m1)P(m3|m2)P(m4|m3)
Tandis que la probabilité d’obtenir cette séquence dans un modèle trigramme sera calculée de la façon suivante :
P(m1, m2, m3, m4) = P(m1)P(m2|m1)P(m3|m2,m1)P(m4|m3,m2)
Comment sont calculées ces probabilités ?
On part d’un très large corpus et on calcule la fréquence pour chaque mot et séquence de mots et on calcule la probabilité de chaque n-gramme.
Exemple de calcul de la probabilité du bigramme <m1 m2>:
P(m2|m1) = N(m1,m2) / N(m1)
Limitations du modèle n-gramme:
- Le modèle n-gramme, du à la simplication qui est faite, ne permet pas de capter les dépendances entre les mots qui sont éloignés dans la séquence.
- Lors du traitement d’un texte, un n-gramme qui ne se trouve pas dans le modèle peut apparaître, la probabilité de ce n-gramme est alors de 0. Cependant, il existe des méthodes telles que la méthode de lissage Good-Turing pour corriger ce problème.
Les modèles de langage basés sur les réseaux de neurones
Bien que les modèles n-grammes soient relativement simples et performants, ils sont de plus en plus délaissés au profit de modèles basés sur les réseaux de neurones. Comme pour les modèles n-grammes le but du modèle de réseaux de neurones est d’estimer la probabilité d’une séquence de mots.
Ils sont construits sur base des réseaux de neurones récurrents (RNN) et plus particulièrement les RNN à mémoire court terme étendue (LSTM). Ces réseaux sont spécialement utilisés pour le traitement de séquences car ils gardent la mémoire du traitement des mots vus précédemment, on intègre de cette façon le mot à prédire dans son contexte. Dans l’exemple ci-dessous, le module LSTM garde la mémoire du mot “chanter“ rencontré précédemment dans la séquence et prédira donc le mot “voix” .
Exemple de prédiction d’un mot dans le cas d’homophones en reconnaissance vocale.
Elle adore chanter mais elle perd sa __ [voie, voix]
Elle adore chanter mais elle perd sa voix
Vecteur de mots
Avec ces modèles, on introduit aussi le concept de similarité c.-à-d. que des mots similaires apparaissent dans des contextes similaires et seront donc représentés de façon similaire. Ce qui permet d’avoir une représentation plus compacte que les modèles n-grammes.
Dans un réseau de neurones, les séquences de mots sont représentées/traduites en vecteurs de mots denses avant d’être injectées en entrée du réseau (word vectors)[2]. Chaque mot est ainsi projeté dans un espace de dimension d (word embedding) dans lequel il est représenté par un vecteur tel que deux mots au concept similaire seront représentés par des vecteurs proches l’un de l’autre dans cet espace. Ces représentations vectorielles peuvent être apprises par le modèle en même temps que la fonction de probabilité ; ils constituent alors des paramètres additionnels du modèle.
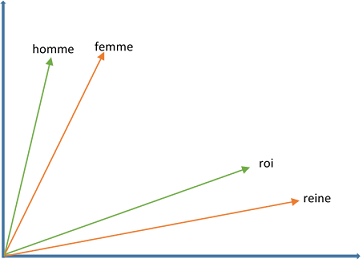
Les principaux modèles permettant de générer des vecteurs de mots sont word2vec et GloVe. Néanmoins si cette représentation de texte permet de capturer le « sens » d’un mot, elle ne permet pas toujours de capturer le sens d’un mot quand il est employé dans des contextes différents. Par exemple, dans les phrases « je place la souris à droite du clavier» et « je place la souris dans sa cage », le mot « souris » n’a pas la même signification mais il sera représenté par le même vecteur.
La représentation compacte et l’intégration du concept de similarité introduites avec les vecteurs de mots favorisent la généralisation du modèle c.-à-d. la capacité du modèle à faire une prédiction correcte pour un cas qu’il a peu ou pas rencontré lors de l’entraînement.
Les modèles basés sur les réseaux de neurones type LSTM ont cependant quelques limitations. La première est qu’ils requièrent un très large corpus ou ensemble de textes-exemples pour être entraîné. La deuxième est le temps de traitement très long. Les informations étant traitées de manière séquentielle dans le réseau, les calculs ne peuvent être parallélisés. En outre, à cause de ce traitement séquentiel des mots, l’algorithme a plus d’information sur le contexte en fin de séquence car ayant vu plus de mots, qu’en début de séquence. Et enfin, « l’historique » (information sur le traitement des mots précédents dans la séquence) proche a plus de poids dans le traitement d’un mot que « l’historique » lointain.
Pour corriger ces limitations, Google a notamment introduit un nouveau modèle, BERT (Bidirectional Encoder Representations from Transformers)
The state-of-the-art : BERT
BERT est une architecture à réseaux de neurones avec un mécanisme dit d’attention basé sur le principe des transformateurs bidirectionnels (Transformer).
Modèle basé sur le mécanisme d’auto-attention
Le mécanisme d’auto-attention permet de déterminer quel mot ou suite de mots dans la totalité de la séquence donne des éléments de contexte lors du traitement d’un mot. Il permet ainsi de capter les relations entre les mots, même si ceux-ci sont éloignés l’un de l’autre dans la séquence.
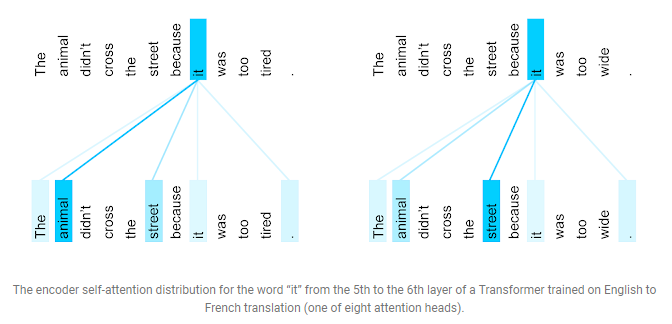
Source : https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html (Transformer: A Novel Neural Network architecture for Language Understanding)
Modèle basé sur les transformateurs
Un transformateur consiste en deux parties, un encodeur et un décodeur. L’encodeur est un réseau de neurones utilisé pour transformer la séquence d’entrée en une représentation vectorielle de la séquence. Le mécanisme d’attention (head of attention) capture ensuite pour chaque mot, les éléments de contexte qui lui sont pertinents et l’intègre dans le vecteur généré par l’encodeur. Cette étape est répétée plusieurs fois simultanément pour tous les mots, ce qui permet de paralléliser le processus. La représentation vectorielle finale ainsi générée par l’encodeur sert ensuite d’entrée à un deuxième réseau, le décodeur, qui est utilisé pour générer des mots de façon séquentielle.
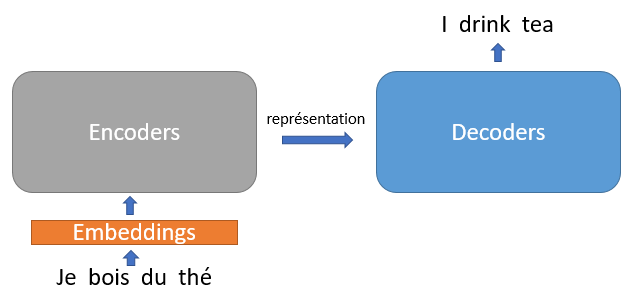
Dans le cas particulier de la traduction automatique, l’encodeur transforme le texte source en vecteur qui est ensuite donné en entrée au décodeur. Ce dernier génère alors la séquence correspondante dans la langue cible.
Dans l’architecture BERT seule la partie encodeur des transformateurs est utilisée, c’est un modèle de représentation de la langage.
Modèle bidirectionnel
Pendant l’entraînement d’un modèle bidirectionnel l’algorithme utilise lors du traitement d’un mot le contexte, qui n’est pas seulement déterminé par l’historique (mots précédents à gauche de la séquence) mais aussi par les mots suivants à droite dans la séquence.
Dans l’exemple ci-dessous, un modèle bidirectionnel capturerait le contexte du mot « caduque » dans les deux phrases tandis qu’un modèle unidirectionnel ne pourrait saisir le contexte dans l’une des deux phrases.
- ces arbres sont à feuilles caduques (le contexte est donné par les mots à gauche de « caduques »)
- ceci rend caduque le contrat que nous avons signé (le contexte est donné par les mots à droite de « caduque »)
Apprentissage du modèle BERT
BERT est un modèle générique dont l’apprentissage se fait de façon non supervisée sur un très large corpus tel que Wikipédia. L’apprentissage se fait en deux parties :
- Apprentissage de la relation entre les mots. Cela consiste à prédire un mot masqué dans une séquence.
Ex : ceci rend <MASK> le contrat que nous avons signé
- Apprentissage de la relation entre les séquences. Etant donné deux séquences A et B, est-ce que la séquence B suit la séquence A (NotNext/IsNext)?
Ex : L’automne est bien là/Les feuilles des arbres tombent [IsNext], les feuilles des arbres tombent/Cette machine doit être réparée [NotNext]
Le modèle BERT est le modèle par excellence pour traiter de nombreux problèmes de NLP tels que :
- la traduction
- la génération de texte
- la classification
- le question-réponse
- l’analyse syntaxique (tagging, parsing)
Pour accomplir une tâche particulière de NLP, on utilise comme base le modèle pré-entraîné BERT et on l’affine en ajoutant une couche supplémentaire; le modèle peut alors être entraîné sur un set de données labélisées et dédiées à la tâche NLP que l’on veut exécuter. C’est le principe même du transfer learning. Il est important de noter que BERT est un modèle très large avec 12 couches, 12 têtes d’attention et 110 millions de paramètres (BERT base).
En conclusion, pour beaucoup de problèmes de NLP, un modèle statistique de langage est requis. Les modèles basés sur les réseaux de neurones offrent les meilleurs résultats grâce notamment à leur capacité de généralisation. Quant aux modèles de type transformateurs apparus récemment, il permettent d’atteindre de très bonnes performances sur certaines tâches de NLP avec des données limitées. Beaucoup de recherches sont faites sur les modèles de représentation de langue basés sur les transformateurs. On peut citer entre autre les modèles RoBERTa, XLNet et GPT-2 qui sont des variantes de BERT.
[1] Il existe aussi des modèles opérant sur des caractères, des syllabes, …
[2] Pour qu’un texte puisse être traité par des algorithmes d’apprentissage machine il doit être représenté sous forme numérique
____________
Ce post est une contribution individuelle de Katy Fokou, spécialisée en intelligence artificielle chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.
Merci beaucoup pour votre exposé. Enfin, une explication claire avec des exemples pertinents, ce qui prouve que vous maitrisez le sujet. En un mot, bravo !
Merci pour cette superbe explication. Je voudrais travailler sur un un tranformer qui permettrait de détecter des techniques de propagande avec des articles de presse…ce serait très instructif et un honneur d’echanger avec vous sur ce sujet.
razzaqkabore97@gmail.com