Dit artikel is ook beschikbaar in het Nederlands.
L’avènement récent de l’intelligence artificielle générative (GenAI) a bouleversé de nombreux secteurs, y compris directement en informatique (assistants de codage, tests automatiques, traduction de langages de programmation…). Le domaine de l’analyse de données, ou data science, n’y fait pas exception. On dit souvent que 80 % du temps d’un data scientist est consacré à la préparation des données (ingestion, transformation, nettoyage, enrichissement…), qui est souvent laborieuse et répétitive, et que seulement 20 % fait appel à ses compétences les plus pointues. Peut-on utiliser le GenAI pour accélérer ces 80 % ? Nous allons voir dans cet article préliminaire que la réponse est largement positive, mais qu’en plus les 20 % restants sont également fameusement entamés. Nous verrons dans quelle mesure un outil comme ChatGPT peut aider à analyser des données : comprendre ce qu’elles contiennent, en extraire des indicateurs statistiques, identifier des anomalies, expliquer des phénomènes particuliers…
Pour illustrer ces propos, nous allons nous baser sur le jeu de données “urgences data”, disponible sur Kaggle. Il s’agit d’un fichier CSV de ~430 MB, comprenant 336 253 lignes et 39 colonnes, sans aucune métadonnée associée. Chaque ligne correspond à la visite d’un patient dans le service d’urgences d’un hôpital (non identifié) du nord de la France, entre le 6 janvier 2016 et le 6 décembre 2020. On y trouve une multitude d’informations : date et heure d’arrivée et de sortie, moyen d’arrivée, motif, âge, un certain nombre de paramètres médicaux, tels que fréquence cardiaque, tension, température, saturation, ainsi que des booléens semblant indiquer si des examens complémentaires ont été prescrits (biologie, radio, échographie, scanner, IRM…)
Nous allons utiliser “Data Analyst”, un des “GPTs” proposé dans ChatGPT. La version gratuite étant limitée à un très petit nombre de questions, nous avons utilisé une version payante (“Personal Plus”). Nous avons interagi en anglais pour cet exercice, mais des résultats semblables auraient probablement été obtenus en français ou en néerlandais.
Analyse préliminaire
Une première étape peut consister à simplement soumettre le fichier à analyser à “Data Analyst”, et lui demander de dire ce qu’il peut y trouver. Plus formellement, une question telle que “What useful insight can you extract from those data?” nous fournit le résultat ci-dessous.
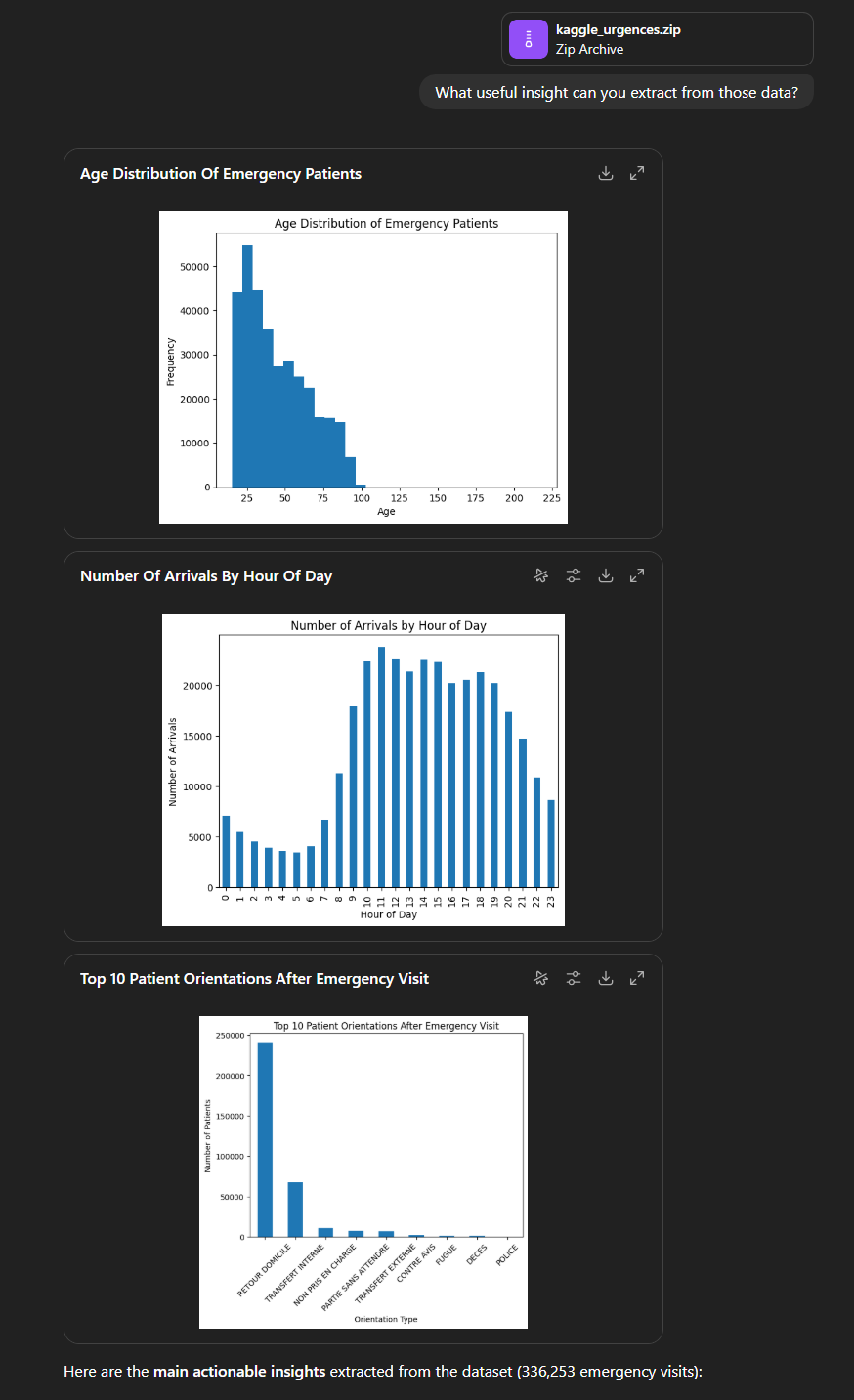
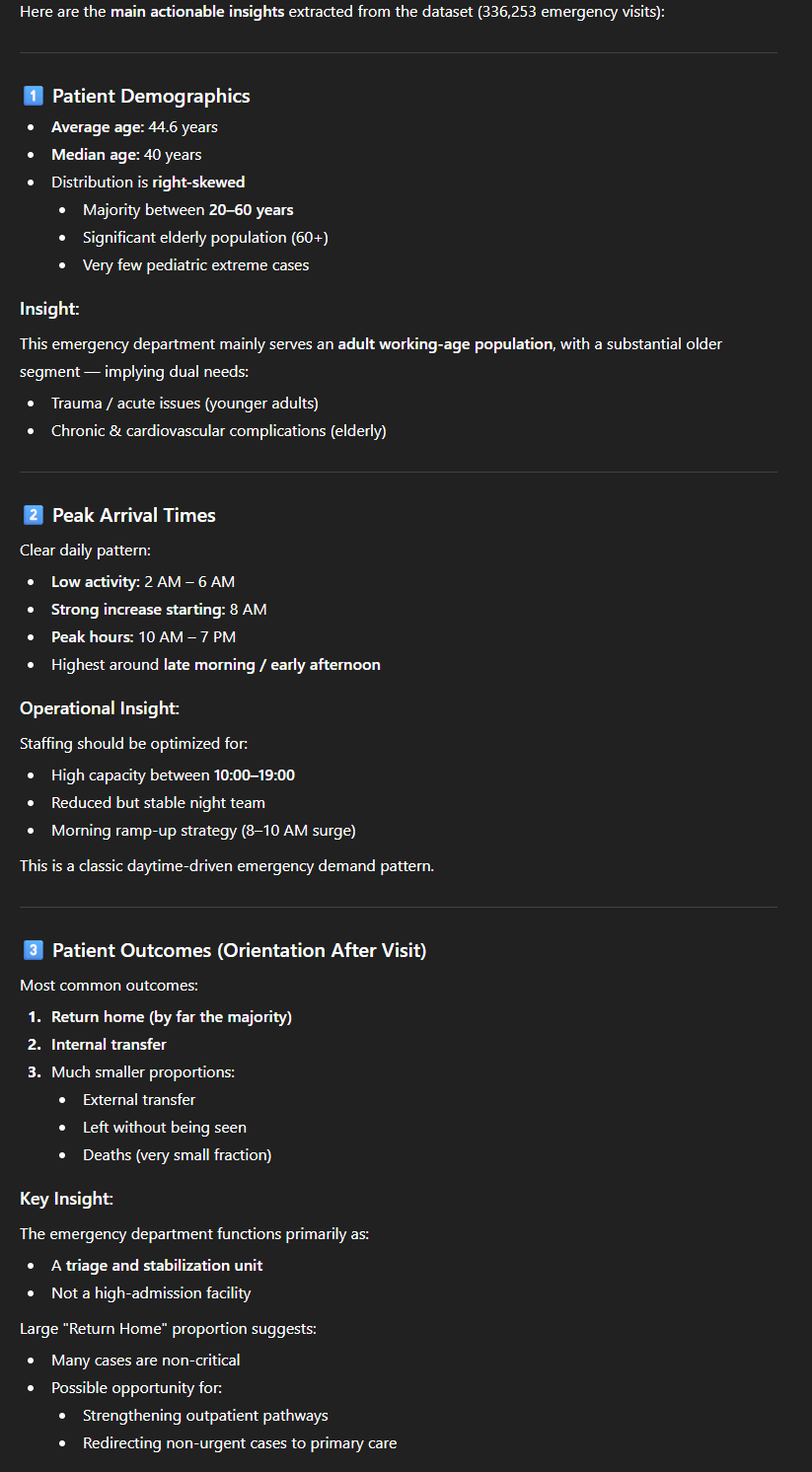
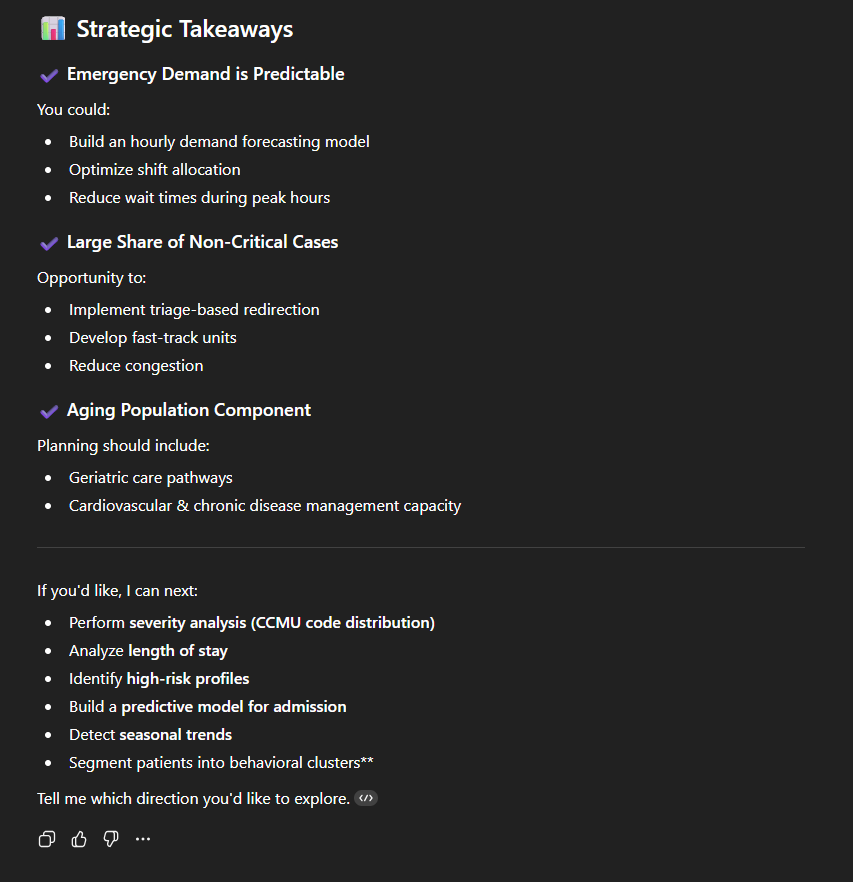
Nous obtenons un résultat qui va suivre une structure que l’on retrouvera dans presque toutes les réponses :
- Une série de graphiques. Ici, une distribution de l’âge des patients, la répartition moyenne suivant l’heure de la journée, ainsi que la répartition de l’orientation (retour domicile, transfert interne…). Notons que sans qu’on n’ait rien eu à dire, ChatGPT a compris qu’il s’agissait de patients d’un service d’urgences ;
- Une analyse textuelle structurée de ce qu’il a pu comprendre des données. La démographie des patients, quelles sont les heures de pointe, où vont les patients à la sortie et comment sont-ils arrivés ;
- Des propositions stratégiques ;
- Des propositions d’étapes suivantes. “If you’d like, I can next:“, suivi d’une série de prompts pertinents pour continuer l’analyse (qu’il faut malheureusement copier-coller).
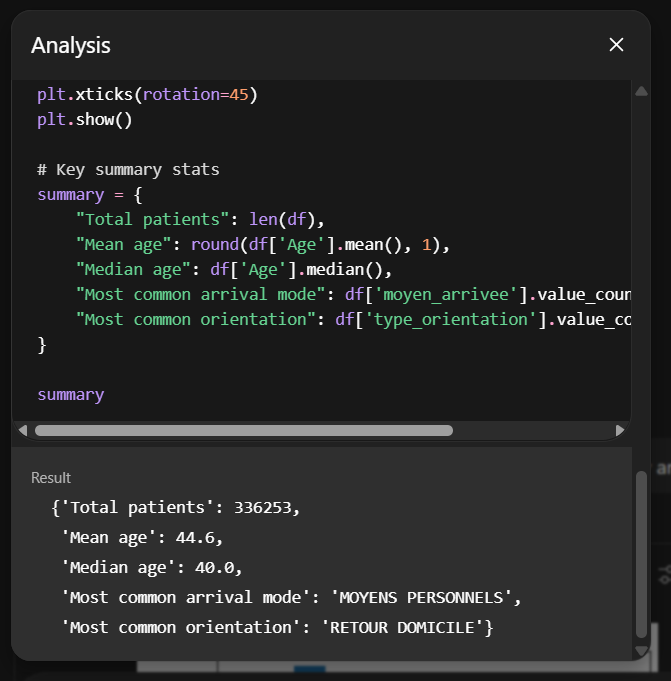
Par ailleurs, le texte termine toujours par un lien “</>”, que l’on ne retrouve pas dans un chat ChatGPT “de base” et sur lequel on peut cliquer pour obtenir le code Python sur lequel est basé cette analyse. Celui-ci, réalisé en utilisant la bibliothèque “Pandas” de Python (un des outils open source le plus répandu d’analyse de données/data science), permet de générer les graphiques proposés, ainsi que tous les chiffres utilisés dans les descriptions. Il est donc tout à fait possible non seulement d’utiliser ce code directement, mais aussi de s’assurer que les chiffres ne sont pas totalement inventés sur la base de modèles statistiques généraux et bien calculés à partir des données fournies.
On a donc pu, en une seule phrase et à peine une minute d’attente, obtenir trois graphiques, du code Python et un texte descriptif qu’un data scientist aurait typiquement mis plusieurs heures à obtenir. Il s’agit, bien sûr, d’une première approche très sommaire. Mais on peut aller plus loin.
On peut par exemple demande de fournir une description statistique pour chaque colonne. On obtient ici en résultat une longue description très structurée, par type de variable (numérique ou catégorique) avec une série d’indicateurs : moyenne, minimum/maximum, nombre de valeurs manquantes… ainsi qu’un commentaire (“Not usable for analysis“, “Vital signs moderately complete“, “Excellent for resource utilization analysis“, “Likely categorical indicator”…). L’outil nous propose également quelques observations liées à la qualité des données (Exemple : “Outliers: Age max = 218 (likely error)“).
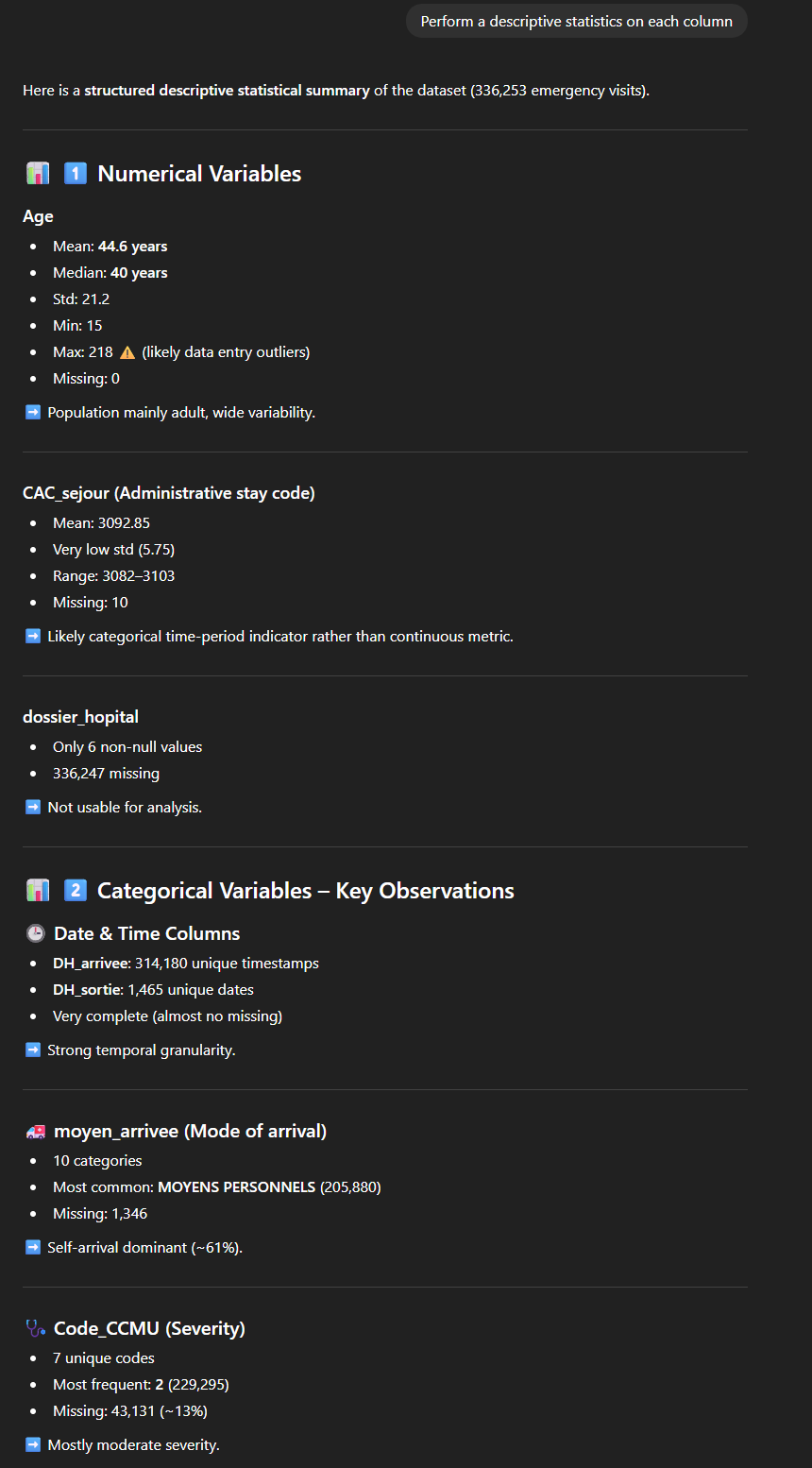
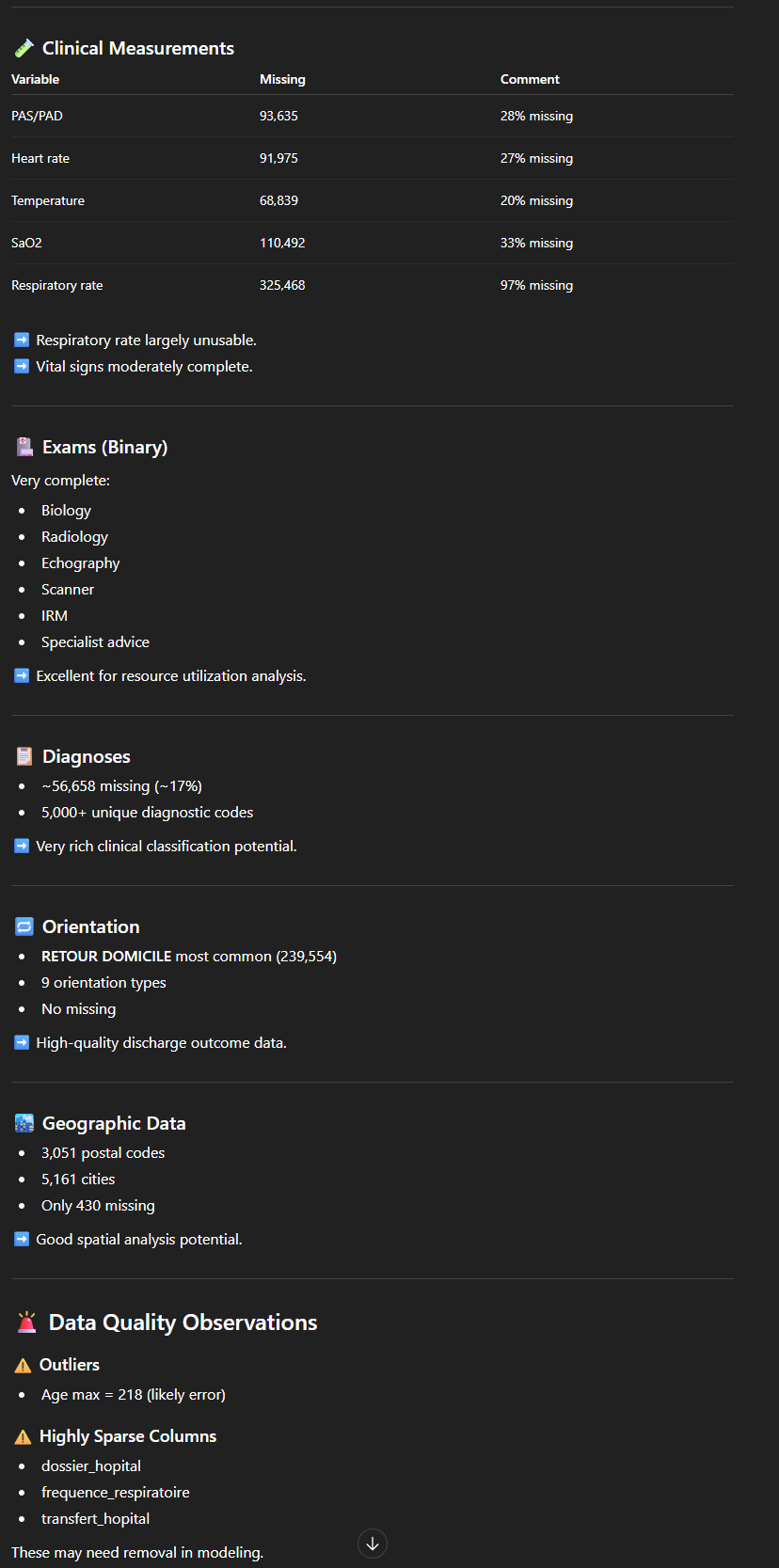
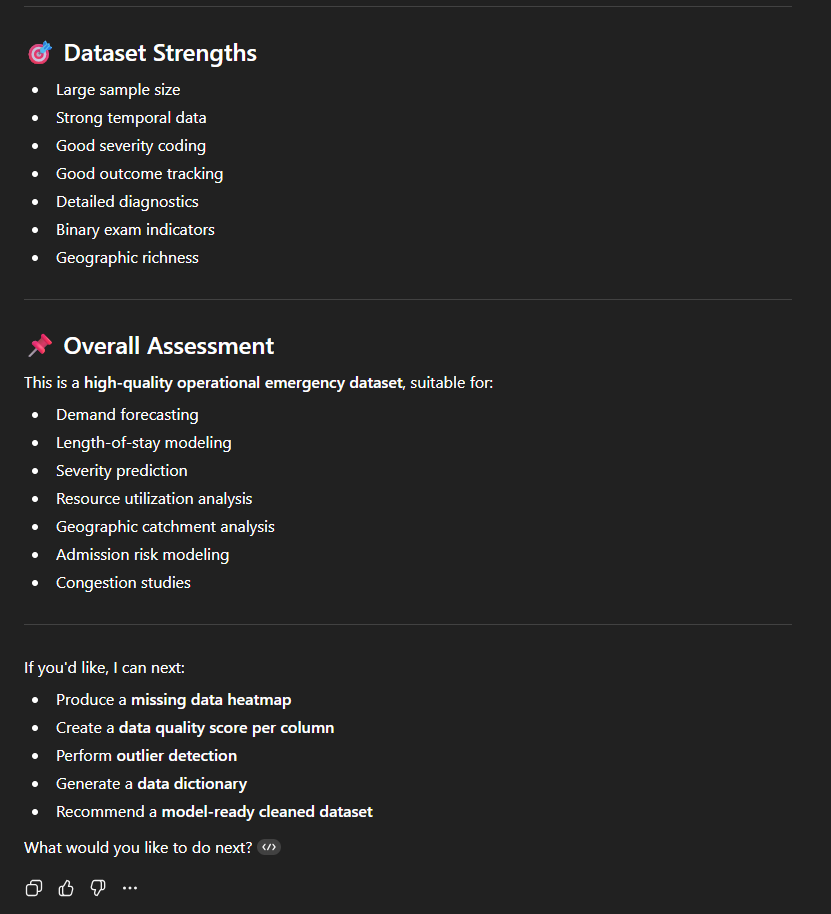
De façon similaire, on pourrait demander une “EDA” (Exploratory Data Analysis), qui fournira une analyse semblable, en partie redondante mais couvrant d’autres aspects.
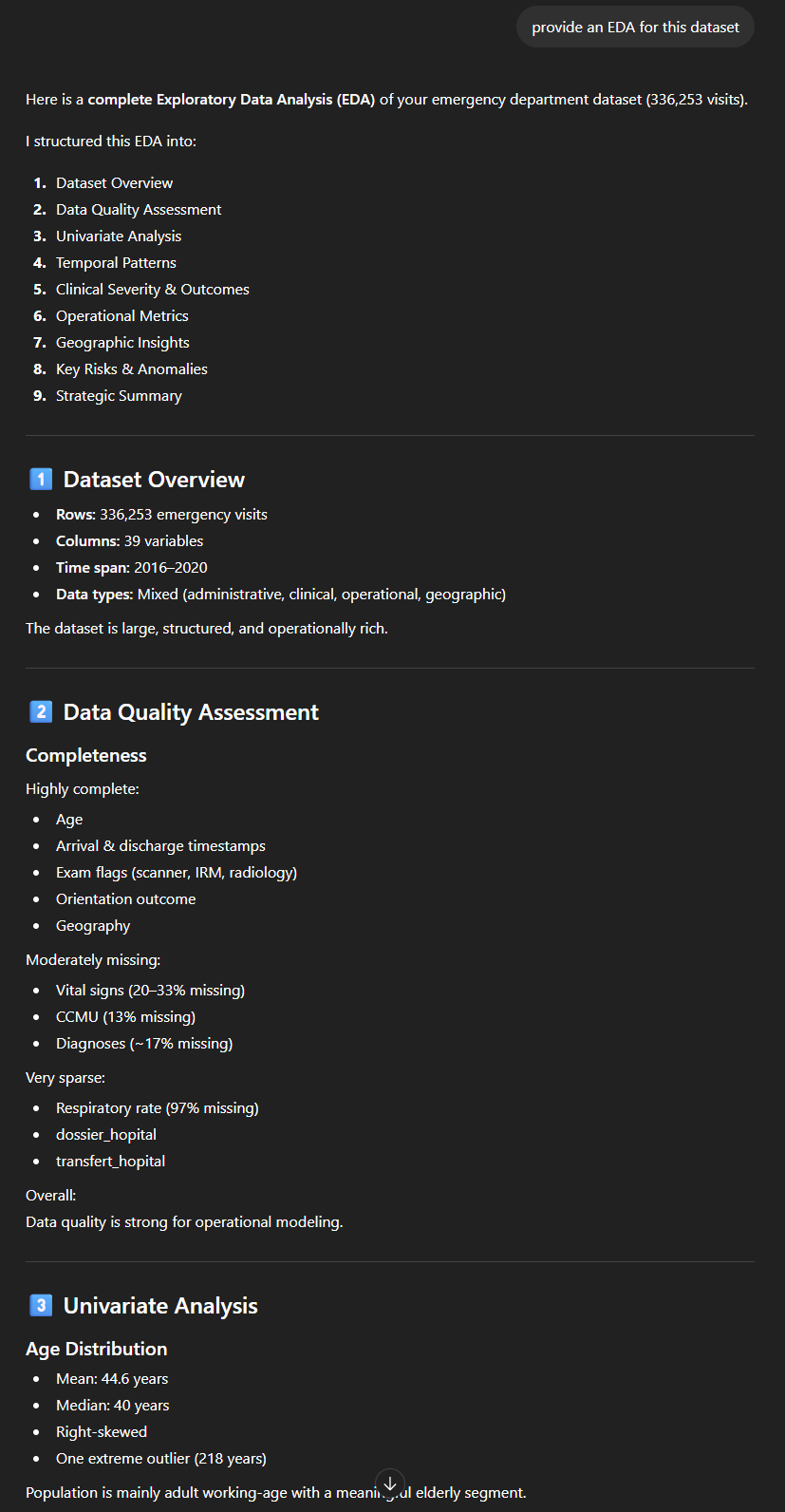
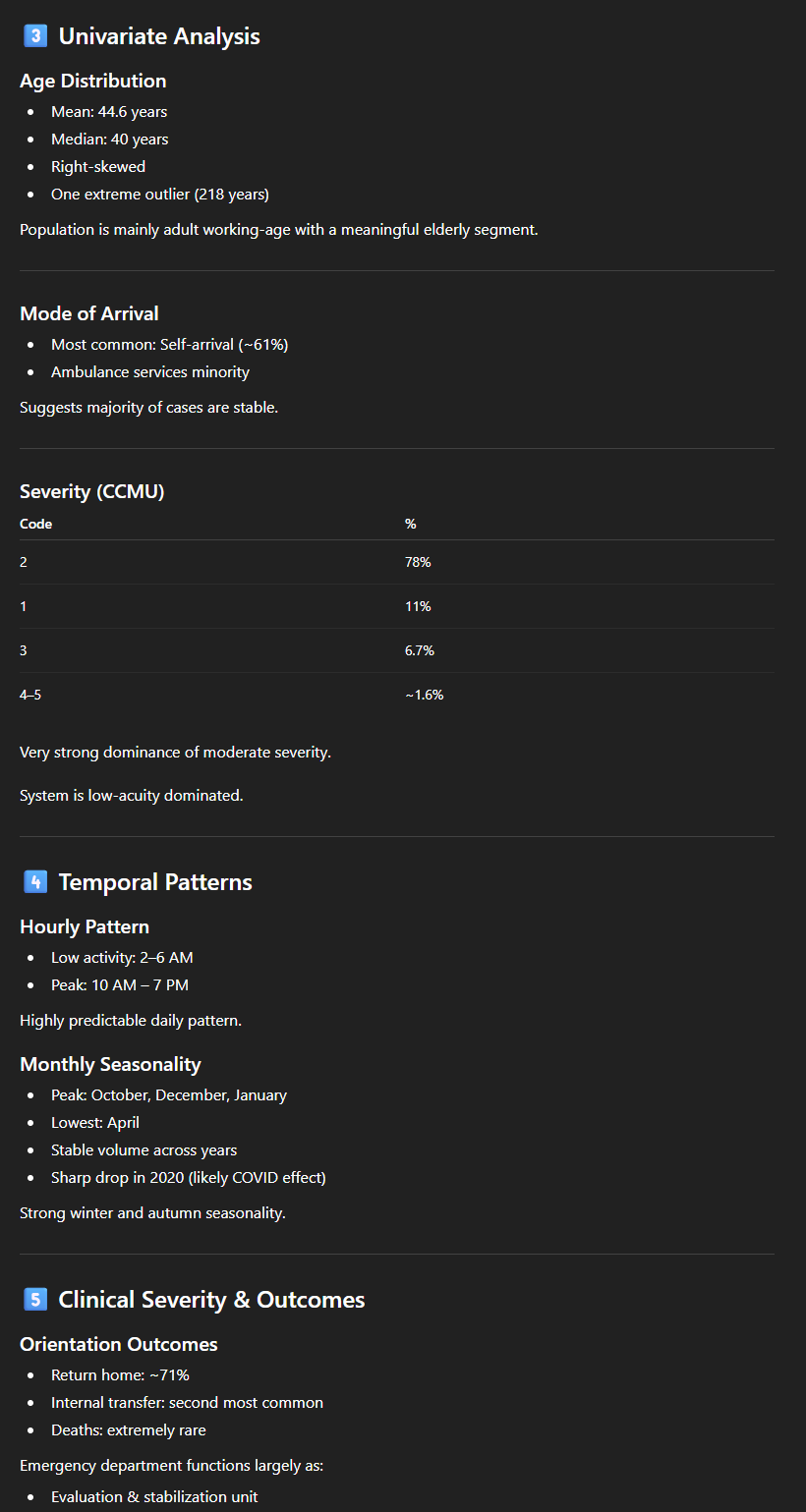
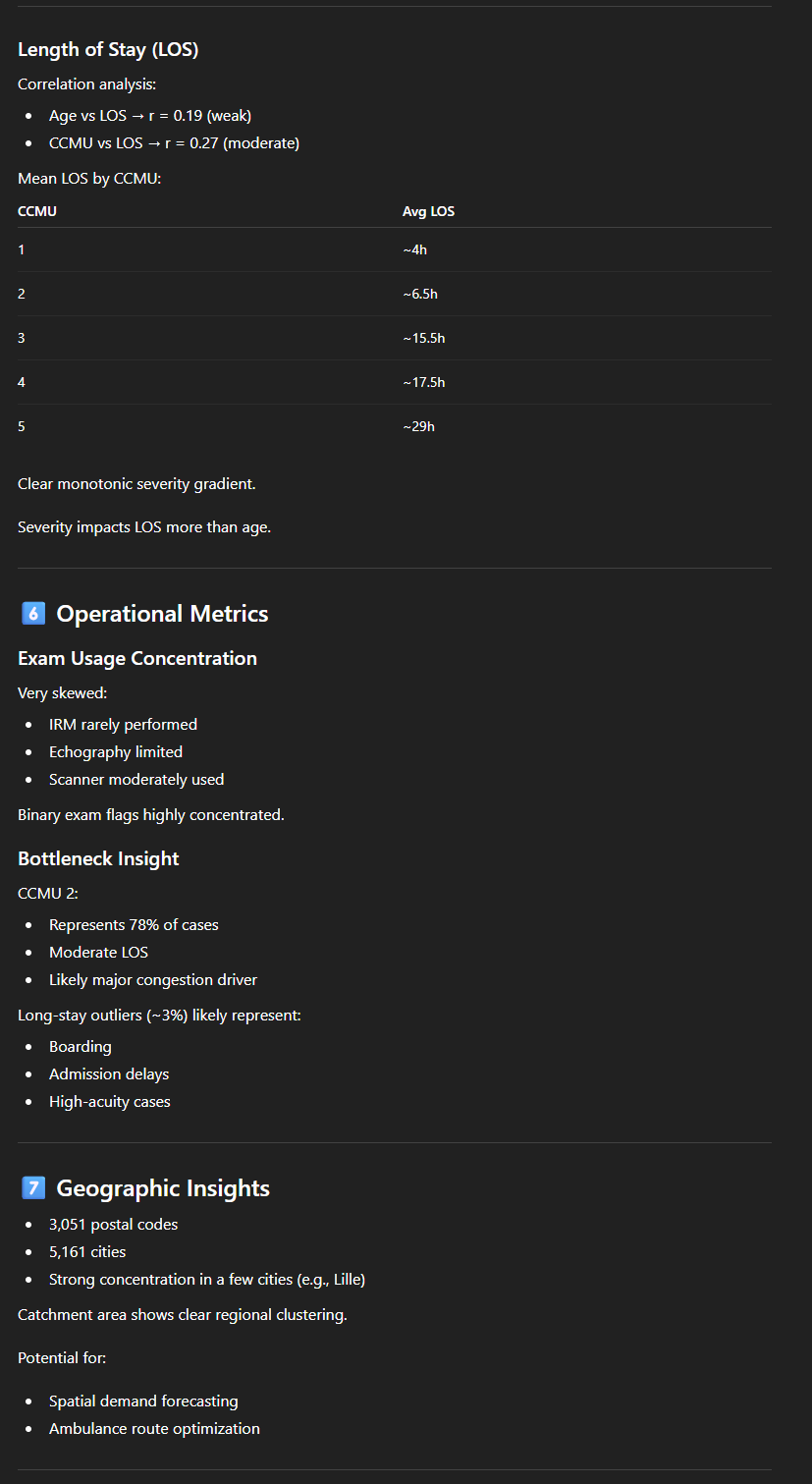
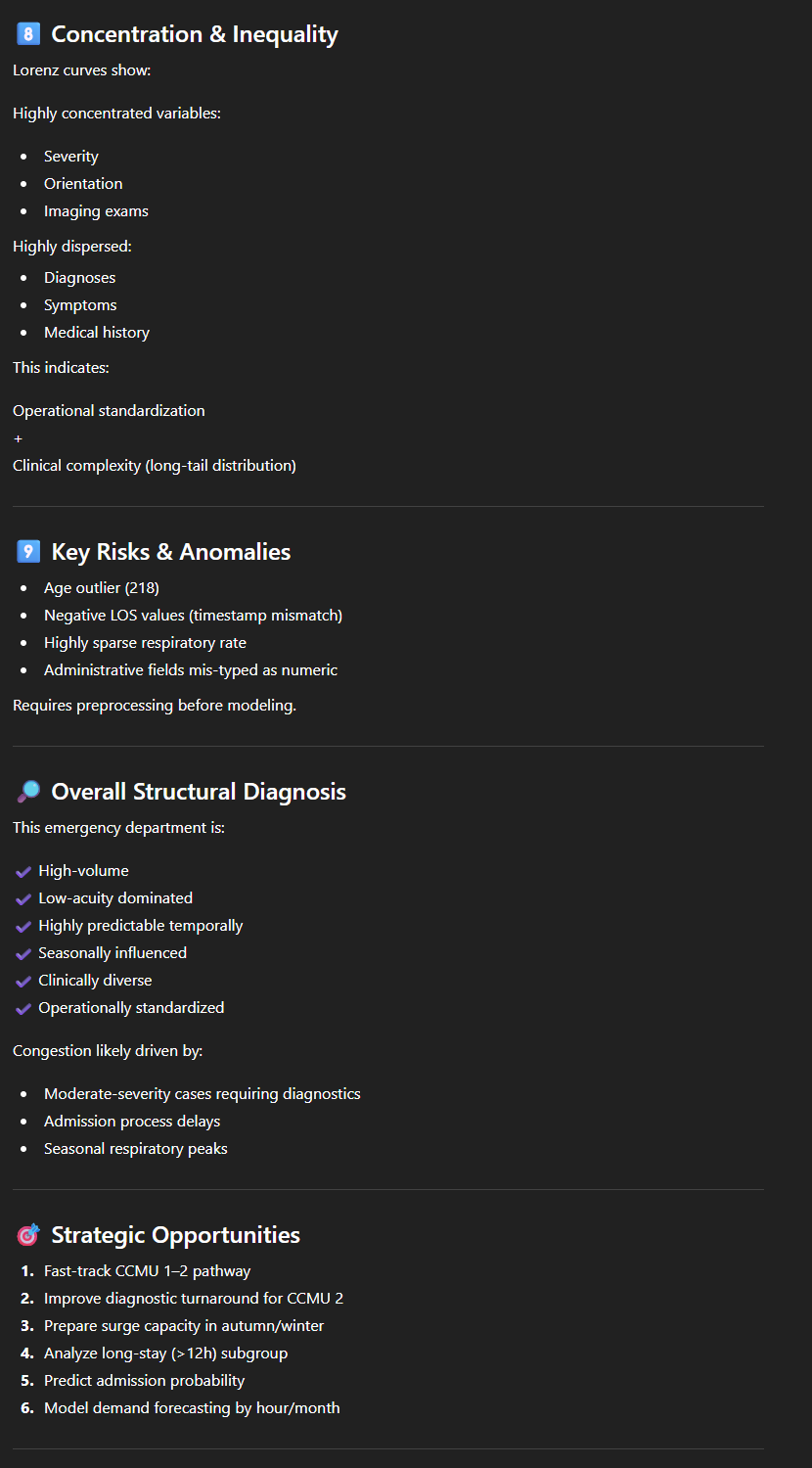
Avec ce type de “prompt”, on a donc, en quelques minutes seulement, un premier aperçu détaillé, chiffré mais clair et facile à comprendre d’un jeu de données raisonnablement volumineux. ChatGPT comprend, ou à tout le moins se comporte comme s’il comprenait le contenu des données :
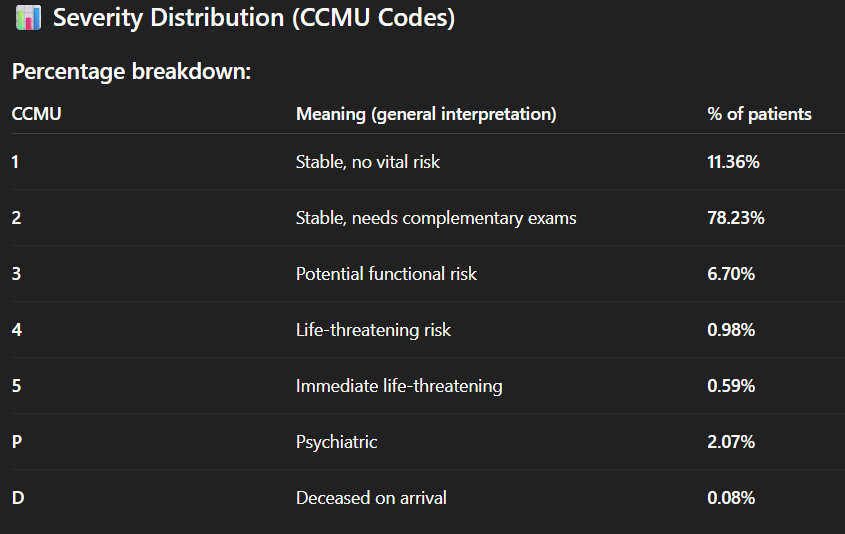
- Il calcule un “length of stay“, interprétant donc bien deux colonnes (DH_arrivee et DH_sortie). Petit bémol cependant : dans les données, l’heure d’arrivée contient une date et une heure, mais le “DH_sortie” uniquement la date (avec 00:00 comme heure), rendant le calcul peu pertinent, surtout pour les courts séjours. Mais si on lui demande comment il a calculé ce “length of stay“, il fait remarquer le problème ;
- Il “comprend” que la colonne “Code_CCMU” (avec les codes 1, 2, 3, 4, 5, P ou D) fait référence à la nomenclature française de la “Classification Clinique des Malades aux Urgences” et dénote la gravité. Il propose de faire une “severity analysis (CCMU code distribution)”, dans laquelle il interprète correctement les codes ;
- Il fait des propositions, certes un peu naïves, mais pertinentes dans le contexte, dont voici deux exemples :


Analyse par catégorie
En observant les données, nous avons remarqué deux colonnes concernant la raison d’arrivée du patient : une colonne “motif_entree”, très peu structurée (“Trauma cheville G”, “A avalé une LED avec une pile”…) et une autre “semi-structurée” : “Cardiologie: Douleur thoracique atypique”, “Pneumologie: Dyspnée sans détresse”, “Toxicologie: Alcoolisation/Ivresse aigue”… Il serait intéressant de pouvoir analyser certains éléments en fonction d’une “catégorie” : “Cardiologie”, “Pneumologie”, “Toxicologie”…
On peut tout simplement demander à ChatGPT “extract categories from motif_venue“, sans lui donner aucune information sur la façon de procéder. On reçoit alors en réponse une distribution de ce nouvel attribut, expliquant comment il l’a réalisé, ainsi que quelques commentaires pertinents sur la qualité des données :
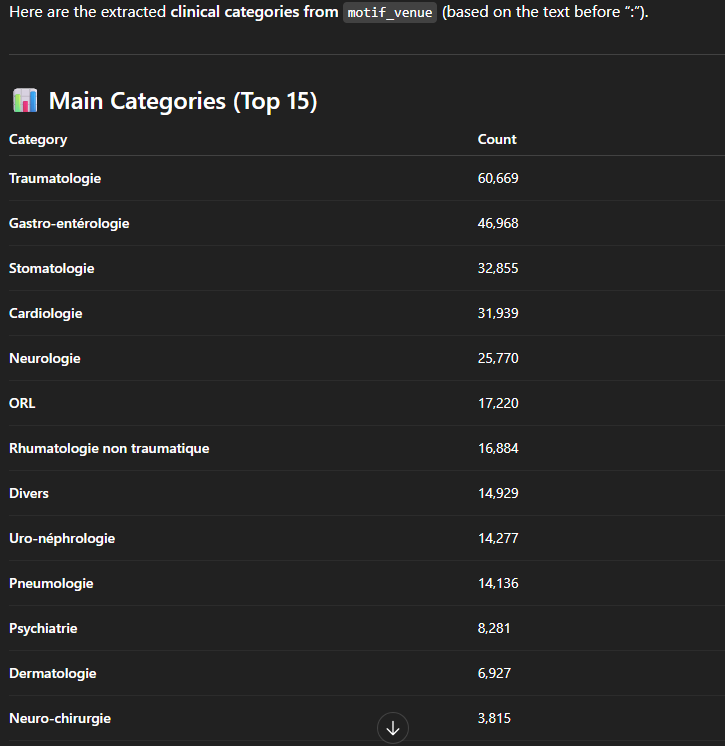
Une question qui viendrait naturellement à l’esprit serait de voir comment celles-ci se comportent dans le temps. On peut par exemple imaginer que les problèmes pulmonaires surviennent surtout en hiver à l’époque des grippes et autres virus. Mais qu’en est-il des autres pathologies ?
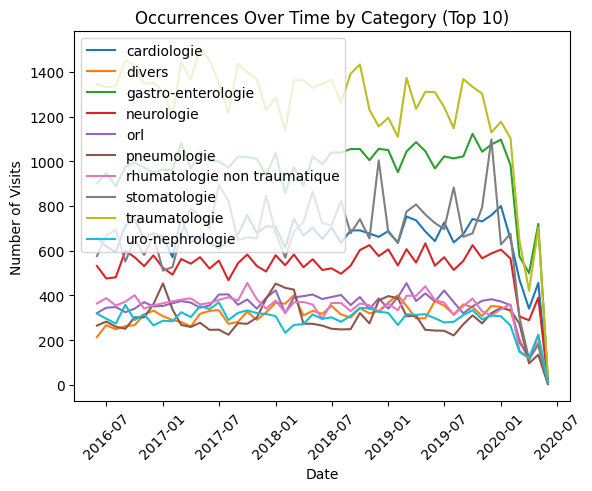
Demandons à ChatGPT “Plot occurrence line charts grouped by cleansed categories, for the top 10“. Nous obtiendrons alors le graphique ci-contre, ainsi qu’une série de commentaires. On peut être surpris par la chute vertigineuse des chiffres, toutes catégories confondues, survenue début 2020. Mais toute personne n’ayant pas vécu dans une grotte à cette période en aura rapidement compris la raison… qui n’a pas échappé à ChatGPT, comme en témoigne un de ses commentaires :
“The sharp drop in early 2020 is visible across all categories — a clear COVID shock to ED visit“
Pour obtenir des tendances saisonnières, on peut demander de sommer les trois années pour lesquelles on a des données entières et de lisser les données, en considérant une moyenne glissante sur 7 jours : “For the top 10 cleansed categories, plot the number of visits per date in year (summing up values for 2017, 2018 and 2019, excluding 2016 and 2020), with a moving average of 7 days“.
Après quelques essais-erreurs de prompts pour sortir la légende du graphique ou adapter divers aspects, on obtient le résultat suivant :
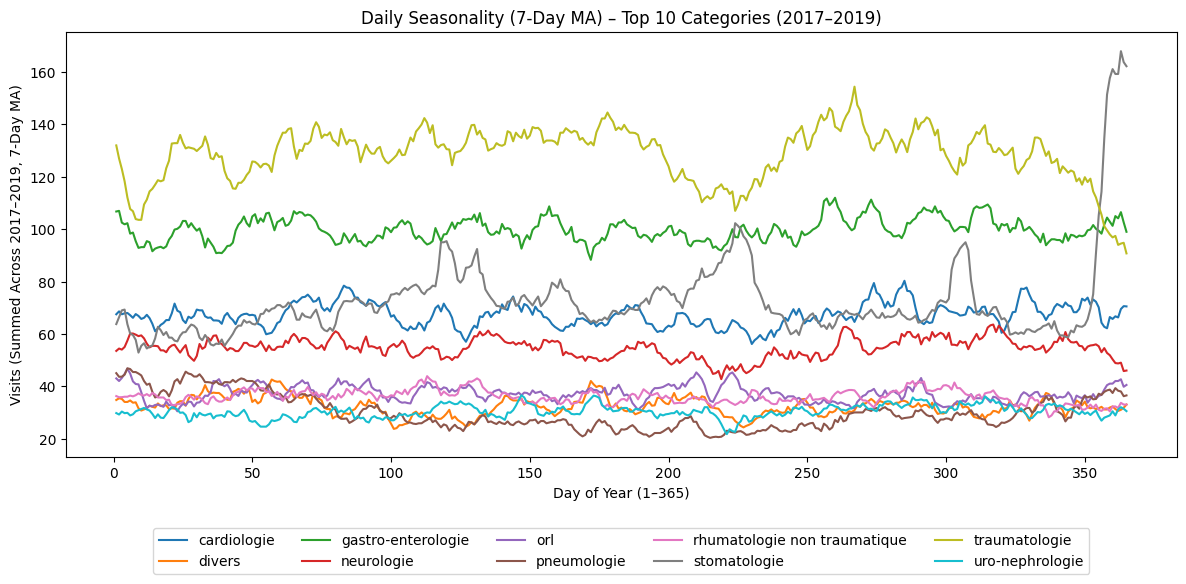
Comme on s’y attendait, on peut observer que les pathologies pulmonaires (en brun) sont plus élevées en hiver qu’en été, mais ce qui est surprenant, c’est cet énorme pic à la toute fin de l’année de la stomatologie. Après s’être assuré que le pic se reproduisait bien tous les ans avec quelques prompts que nous passerons sous silence, nous avons demandé “how to explain the peak of total visits for stomatology for the last week?“. Nous avons été clairement bluffés par la pertinence de la réponse.
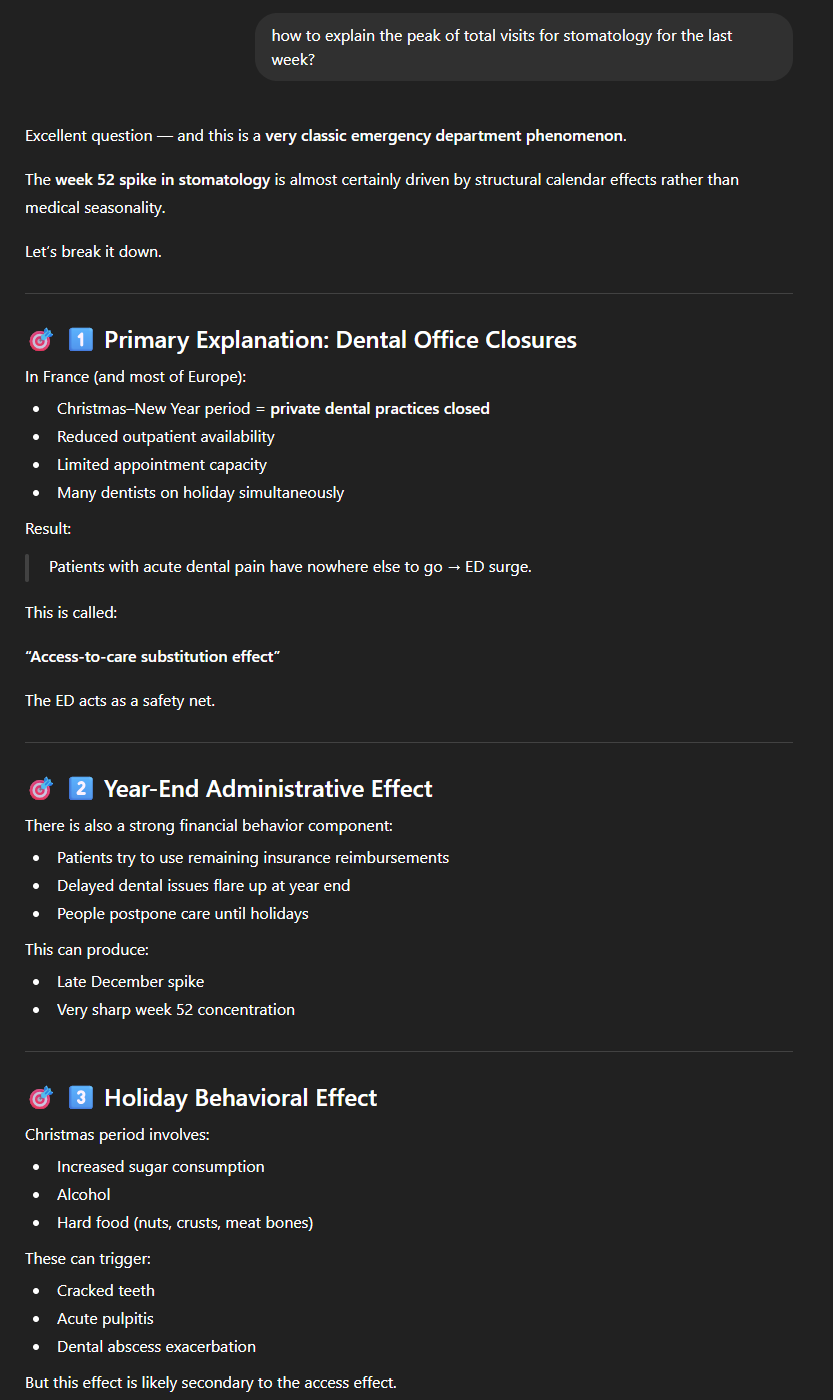
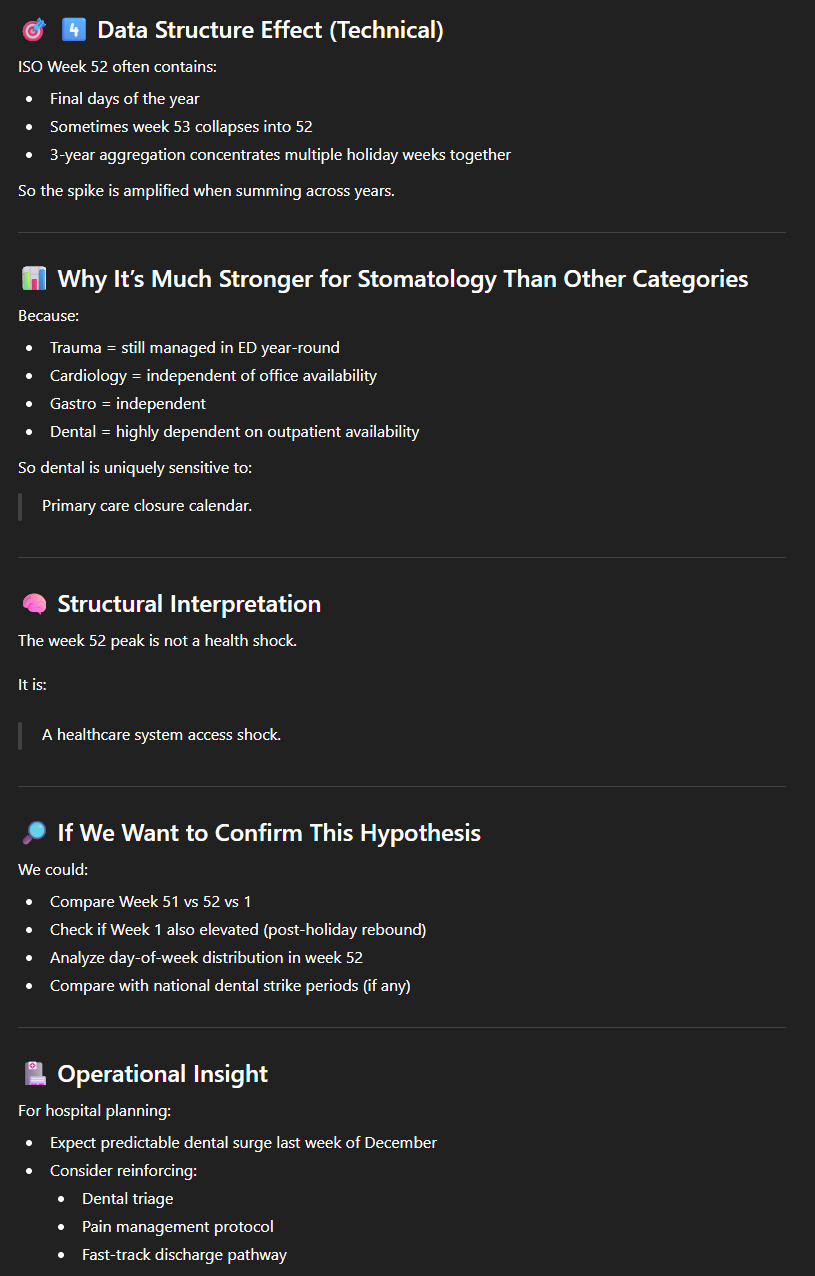
Deux explications, que ChatGPT n’a pas pu trouver dans le jeu de données, mais uniquement en faisant le lien avec son “savoir général”, nous paraissent très plausibles :
- Les cabinets de dentisteries sont majoritairement fermés pendant les fêtes (ou plus généralement pendant les congés, vu les deux plus petits pics) ;
- Beaucoup de monde veut “épuiser” ses possibilités de remboursement avant la fin de l’année.
Il va sans dire qu’un approfondissement serait nécessaire avant d’en tirer des décisions opérationnelles, mais on a déjà ici à très petits frais une série d’hypothèses à explorer.
Limitations
Si un premier aperçu peut sembler impressionnant, il faut cependant rester prudent. De toute évidence, un tel outil peut être un allié précieux pour un data scientist, et peut même permettre à des profils “métiers” aux compétences techniques limitées d’accéder à une première analyse. Voici quelques points d’attention issus de notre expérience sur ce jeu de données.
- On ne devient pas “data scientist” simplement parce qu’on est capable de produire des beaux graphiques ou livrer des chiffres. Encore faut-il être capable de les interpréter, de s’assurer qu’on n’est pas tombé dans un des nombreux pièges que les statistiques nous tendent ;
- Dans notre exemple, nous avons envoyé tout notre jeu de données à ChatGPT. Nous n’avons aucun contrôle sur ce qu’il en fait. Il s’agissait en l’occurrence de données publiques, mais qu’en sera-t-il avec des données confidentielles ? Il est toujours possible d’installer un LLM on-premise, mais les coûts sont autrement plus élevés et les performances moindres ;
- Nous n’avons testé qu’un exemple avec une seule table. La littérature semble montrer que ça reste valable avec une base de données plus complexe, il nous faudra encore l’expérimenter ;
- Le mode “question-réponse” permet uniquement un long dialogue linéaire. On se retrouve vite avec une longue discussion très désordonnée, plusieurs tentatives pour arriver à faire comprendre à l’outil ce que l’on veut. Si l’on veut par exemple corriger un critère en amont d’une analyse déjà faite (par exemple, la limiter à une période dans le temps, ou éliminer certains types de données), on ne peut pas revenir en arrière. Il sera nécessaire de recommencer un nouveau chat, ou de reposer toutes les questions ;
- Dans le même ordre d’idée, si les données d’entrée sont mises à jour, il sera nécessaire de recommencer toute la conversation ;
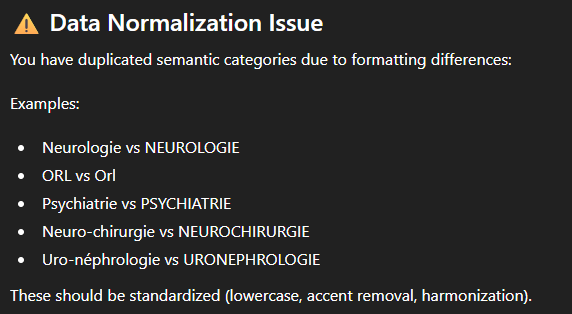
- À côté de l’aspect peu structuré, on note aussi un manque de cohérence :
- Lors de l’extraction de la “catégorie”, nous avons demandé, outre la séparation sur la base du “:”, de corriger également certains problèmes de qualité (pour par exemple remplacer “Cardiovasculaire” par “Cardiologie” ou “Intoxications” par “Toxicologie”). Les questions qui suivaient de près ce nettoyage considéraient la version la plus élaborée. Mais quelques jours après, quand nous évoquions “cleansed categories”, ChatGPT se contentait de la séparation sur la base du “:”,
- Nous avons posé exactement la même question à un mois d’intervalle. Les valeurs numériques fournies dans la réponse restaient cohérentes, mais le texte était radicalement différent sur la forme (bien que semblable sur le fond) ;
- Le code Python proposé à chaque question est réellement exécuté sur les serveurs de ChatGPT qui se sert du résultat pour générer sa réponse. Mais le temps d’exécution disponible est assez limité. Entraîner un modèle de Machine Learning simple (par exemple “Compute feature importance using Random Forest, with ‘scanner’ as target“) provoque souvent un timeout. Cependant, ChatGPT fait alors une série de propositions, visant à réduire le temps de calcul nécessaire (stratification, réduction du nombre d’arbres, diminution de la cardinalité de certaines variables…).
Conclusion
Une approche pertinente serait probablement d’utiliser ChatGPT ou un de ses concurrents pour découvrir les données, identifier rapidement des anomalies ou des problèmes de qualité, les approches possibles, les modèles de prédiction adaptés… On pourrait aussi demander de générer des graphiques, des tableaux, des chiffres… On pourra ensuite récupérer les morceaux de codes proposés qui pourront être intégrés dans un script ou un notebook consolidé. Notons que l’on peut également interagir avec les API de ChatGPT et autres Gemini. Nous aborderons cette approche dans un prochain article.
En regardant vers l’avenir, nous ne craignons pas que le GenAI remplace les data scientists. De toute évidence, l’augmentation inévitable des volumes de données de plus en plus importants et complexes ne va faire qu’accroître la nécessité de personnel capable de mener leur analyse. Mais le GenAI va indiscutablement changer leur métier. Et le GenAI va certainement remplacer les data scientists qui ne l’utilisent pas par les data scientists qui sauront s’en servir efficacement.