Cet article est aussi disponible en français.
De recente opkomst van generatieve artificiële intelligentie (GenAI) heeft tal van sectoren op hun kop gezet, waaronder de IT-sector zelf (coding assistants, geautomatiseerd testen, vertaling van programmeertalen…). Het domein van de data-analyse, of data science, vormt hierop geen uitzondering. Vaak wordt gezegd dat 80% van de tijd van een data scientist wordt besteed aan het pre-processing van data (ingestion, transformatie, opschoning, verrijking…), wat vaak arbeidsintensief en repetitief is, en dat slechts 20% een beroep doet op zijn meest geavanceerde vaardigheden. Kan GenAI worden ingezet om deze 80% te versnellen? Aan de hand van dit inleidende artikel zullen we aantonen dat het antwoord grotendeels positief is, maar dat bovendien ook de resterende 20% al in belangrijke mate is aangepakt. We bekijken in hoeverre een tool als ChatGPT kan helpen bij het analyseren van data: begrijpen wat ze bevatten, statistische indicatoren extraheren, afwijkingen identificeren, specifieke fenomenen verklaren….
Om dit te illustreren, baseren we ons op de dataset “urgences data”, beschikbaar op Kaggle.
Het betreft een CSV-bestand van ~430 MB, bestaande uit 336.253 rijen en 39 kolommen, zonder bijbehorende metadata. Elke rij komt overeen met een bezoek van een patiënt aan de spoeddienst van een (niet nader genoemd) ziekenhuis in Noord-Frankrijk, tussen 6 januari 2016 en 6 december 2020. Het bevat een schat aan informatie: datum en tijdstip van aankomst en vertrek, vervoermiddel, oorzaak, leeftijd, een aantal medische parameters, zoals hartslag, bloeddruk, temperatuur, zuurstofsaturatie, evenals booleaanse waarden die lijken aan te geven of aanvullende onderzoeken zijn voorgeschreven (bloedonderzoek, röntgenfoto, echografie, CT-scan, MRI…)
We gaan gebruikmaken van “Data Analyst”, een van de “GPT’s” die in ChatGPT worden aangeboden. Aangezien de gratis versie beperkt is tot een zeer klein aantal vragen, hebben we een betaalde versie (“Personal Plus”) gebruikt. Voor deze oefening hebben we in het Engels gecommuniceerd, maar vergelijkbare resultaten zouden waarschijnlijk ook in het Frans of Nederlands zijn verkregen.
Voorafgaande analyse
Een eerste stap kan bestaan uit het simpelweg indienen van het te analyseren bestand bij “Data Analyst” en hem te vragen wat hij daarin kan vinden. Meer formeel levert een vraag als “What useful insight can you extract from those data?” ons het onderstaande resultaat op.
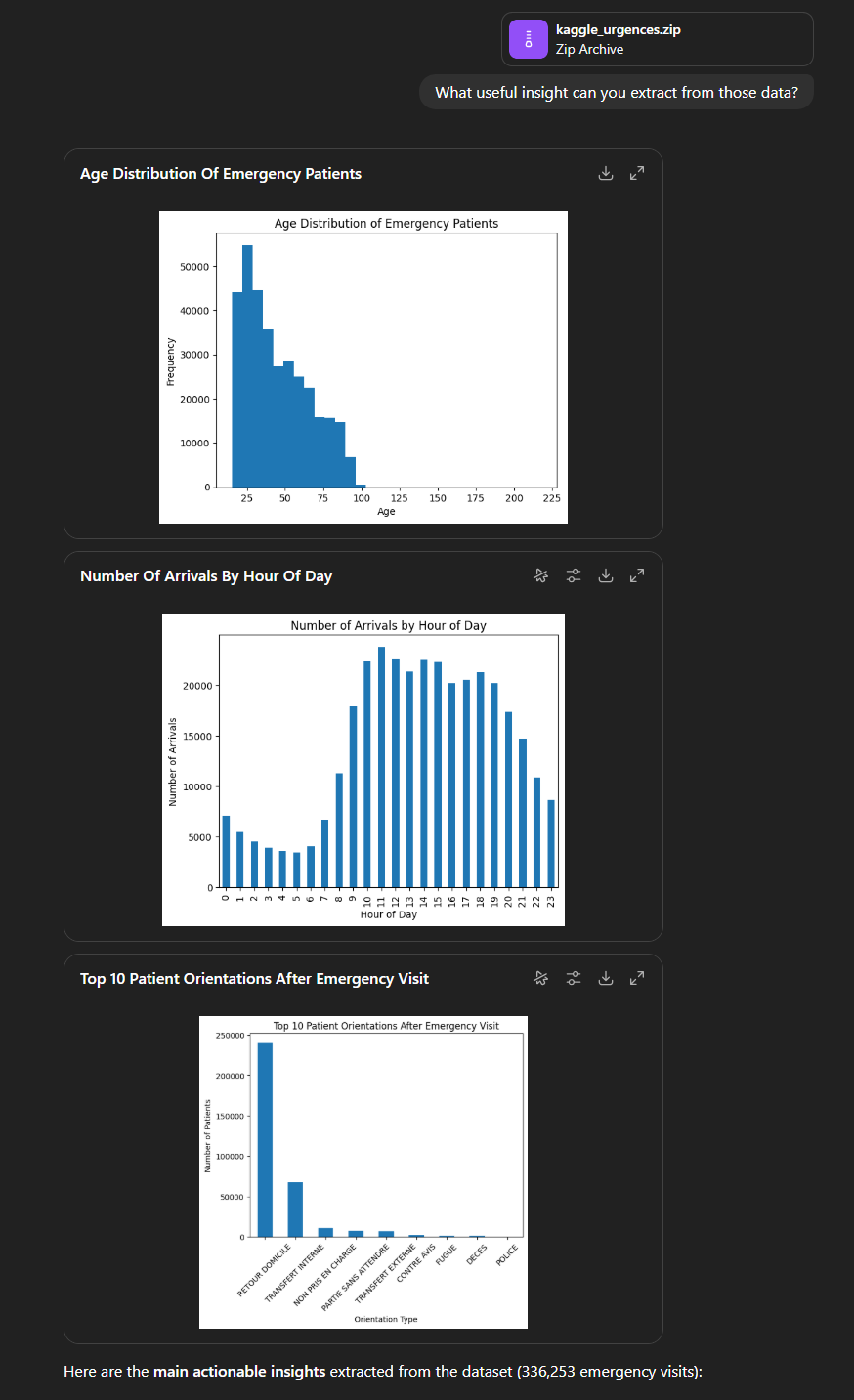
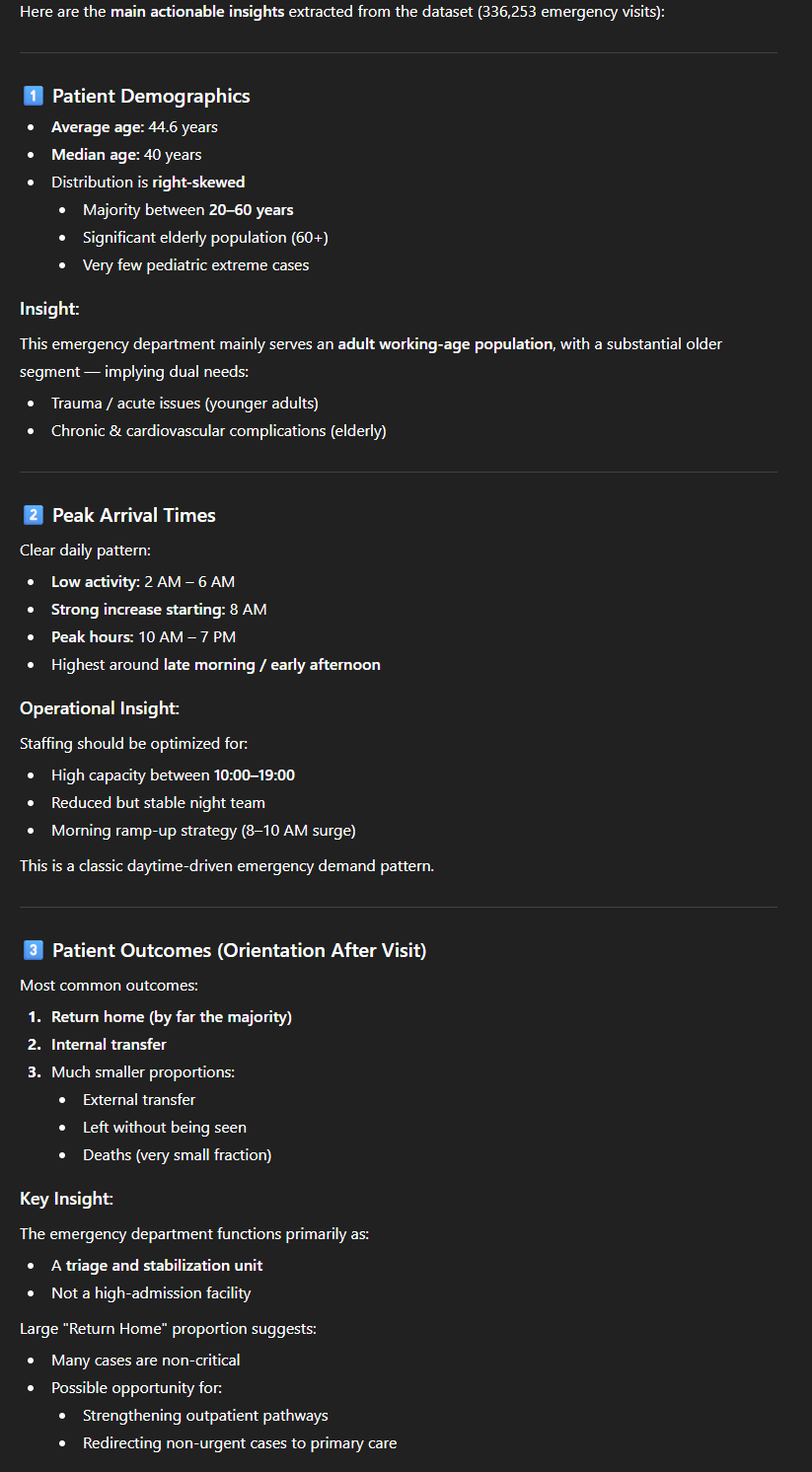
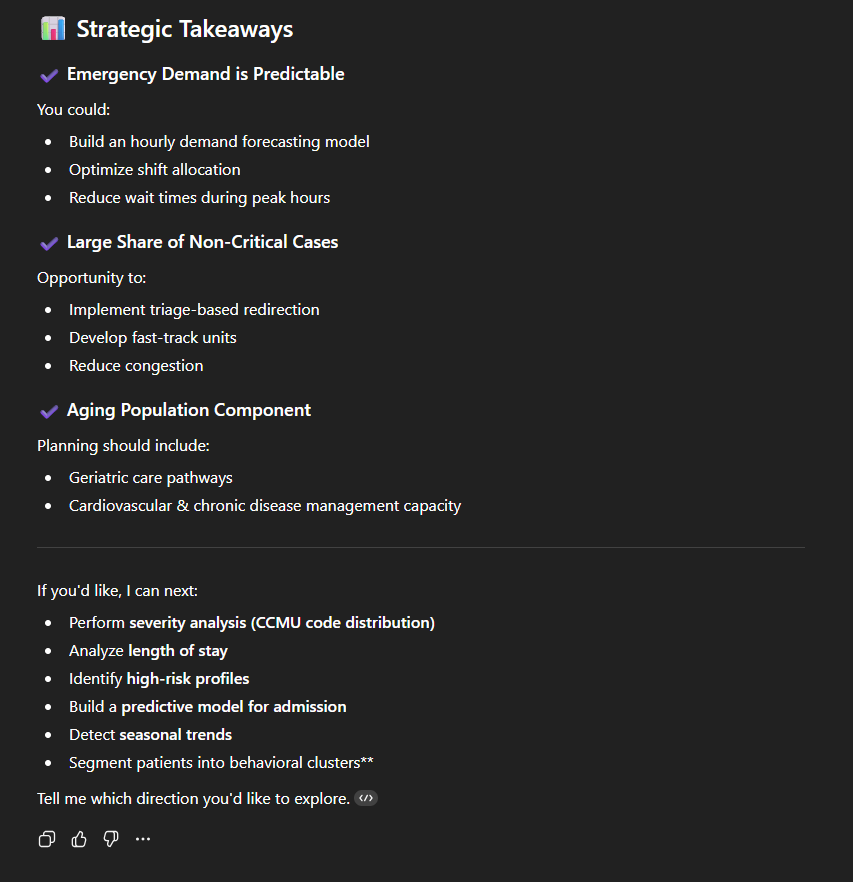
We verkrijgen een resultaat dat een structuur volgt die in bijna alle antwoorden terug te vinden is:
- Een reeks grafieken. Hier zien we een leeftijdsverdeling van de patiënten, de gemiddelde verdeling per tijdstip van de dag, evenals de verdeling van de bestemming (terug naar huis, interne overplaatsing…). Merk op dat ChatGPT, zonder dat wij daar iets over hebben gezegd, begrepen heeft dat het om patiënten van een spoeddienst ging;
- Een gestructureerde tekstanalyse van wat het uit de gegevens heeft kunnen opmaken. De demografische gegevens van de patiënten, de piekuren, waar de patiënten na vertrek naartoe gaan en hoe ze zijn aangekomen;
- Strategische voorstellen;
- Voorstellen voor de volgende stappen. “If you’d like, I can next:”, gevolgd door een reeks relevante prompts om de analyse voort te zetten (die je helaas moet kopiëren en plakken).
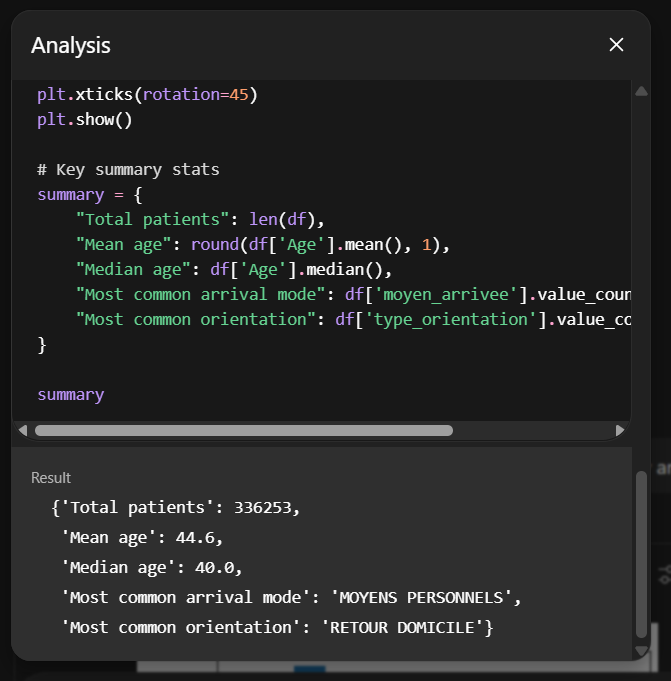
Bovendien eindigt de tekst altijd met een link “</>”, die niet voorkomt in een “standaard” ChatGPT-chat en waarop je kan klikken om de Python-code te verkrijgen waarop deze analyse is gebaseerd. Deze code, die is gemaakt met behulp van de Python-library “Pandas” (een van de meest gebruikte open-source tools voor data-analyse en data science), maakt het mogelijk om de voorgestelde grafieken te genereren, evenals alle cijfers die in de beschrijvingen worden gebruikt. Het is dus volkomen mogelijk om deze code niet alleen direct te gebruiken, maar ook om er zeker van te zijn dat de cijfers niet volledig verzonnen zijn, maar gebaseerd zijn op algemene statistische modellen en zorgvuldig berekend zijn op basis van de verstrekte gegevens.
Zo konden we met één enkele zin en na amper een minuut wachten drie grafieken, Python-code en een beschrijvende tekst verkrijgen, waar een data scientist normaal gesproken meerdere uren over zou hebben gedaan. Dit is natuurlijk een zeer beknopte eerste benadering. Maar we kunnen nog verder gaan.
We kunnen bijvoorbeeld vragen naar een statistische beschrijving voor elke kolom. Het resultaat is hier een lange, zeer gestructureerde beschrijving, per type variabele (numeriek of categorisch), met een reeks indicatoren: gemiddelde, minimum/maximum, aantal ontbrekende waarden… evenals een opmerking (“Not usable for analysis”, “Vital signs moderately complete”, “Excellent for resource utilization analysis”, “Likely categorical indicator”…). De tool biedt ons ook enkele opmerkingen met betrekking tot de kwaliteit van de gegevens (bijvoorbeeld: “Outliers: Age max = 218 (likely error)”).
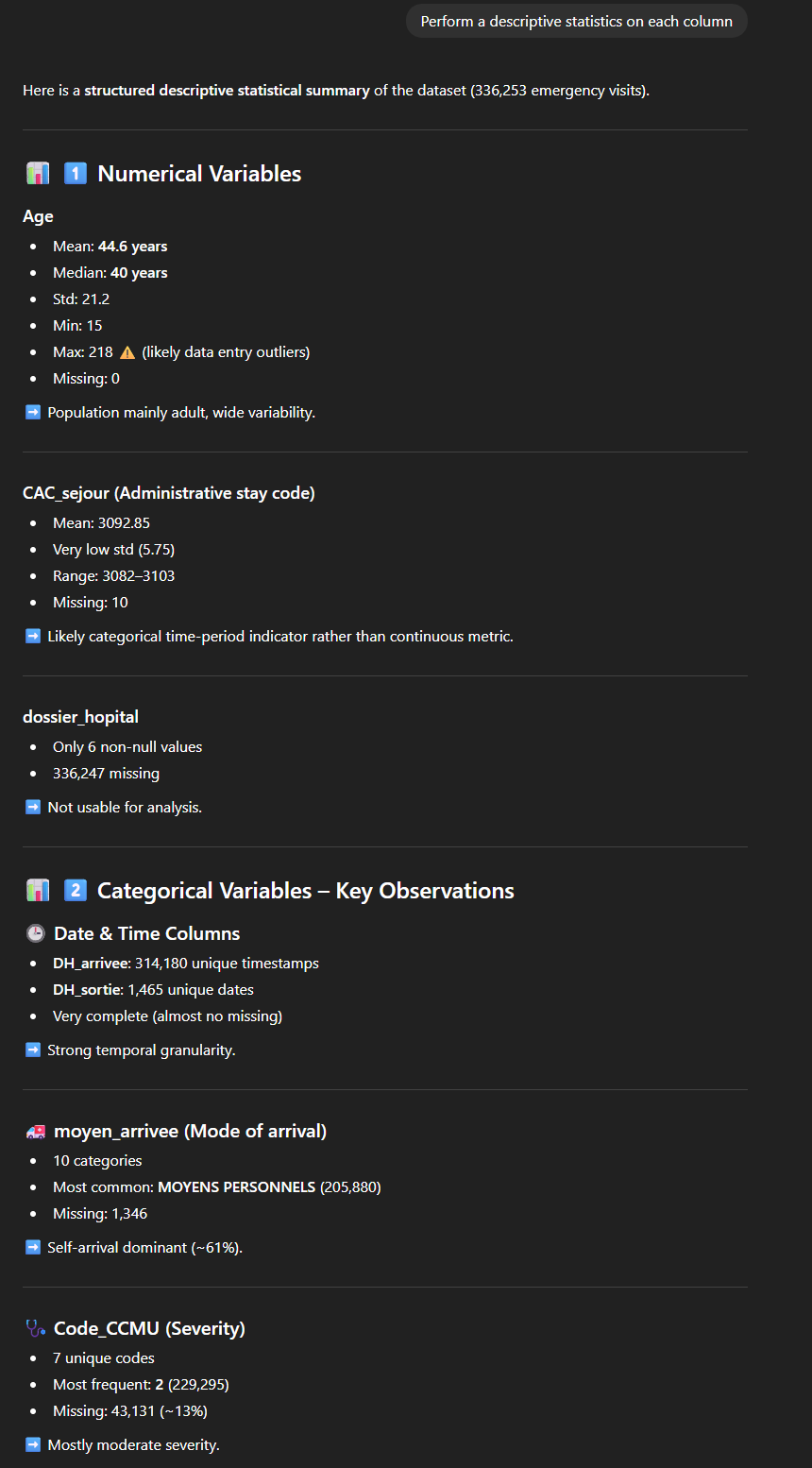
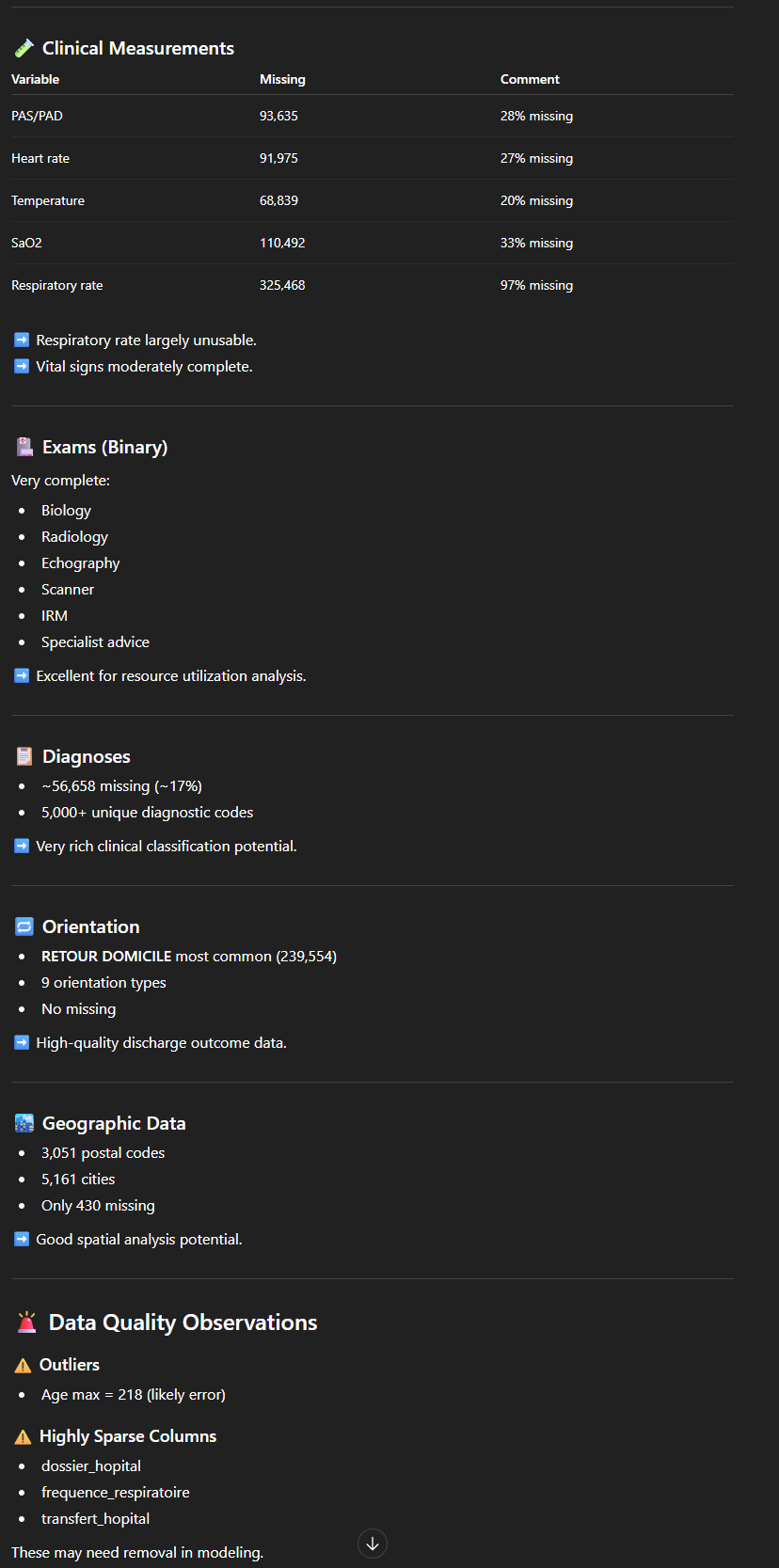
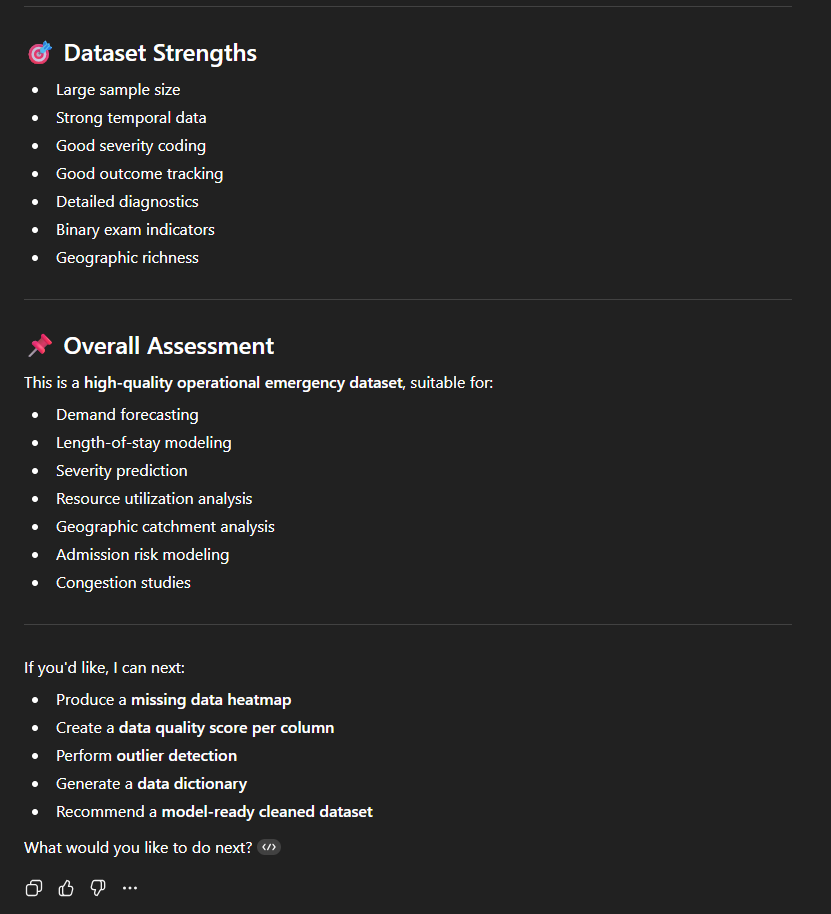
Op dezelfde manier kunnen we een “EDA” (Exploratory Data Analysis) aanvragen, die een vergelijkbare analyse oplevert, die deels overlapt maar ook andere aspecten behandelt.
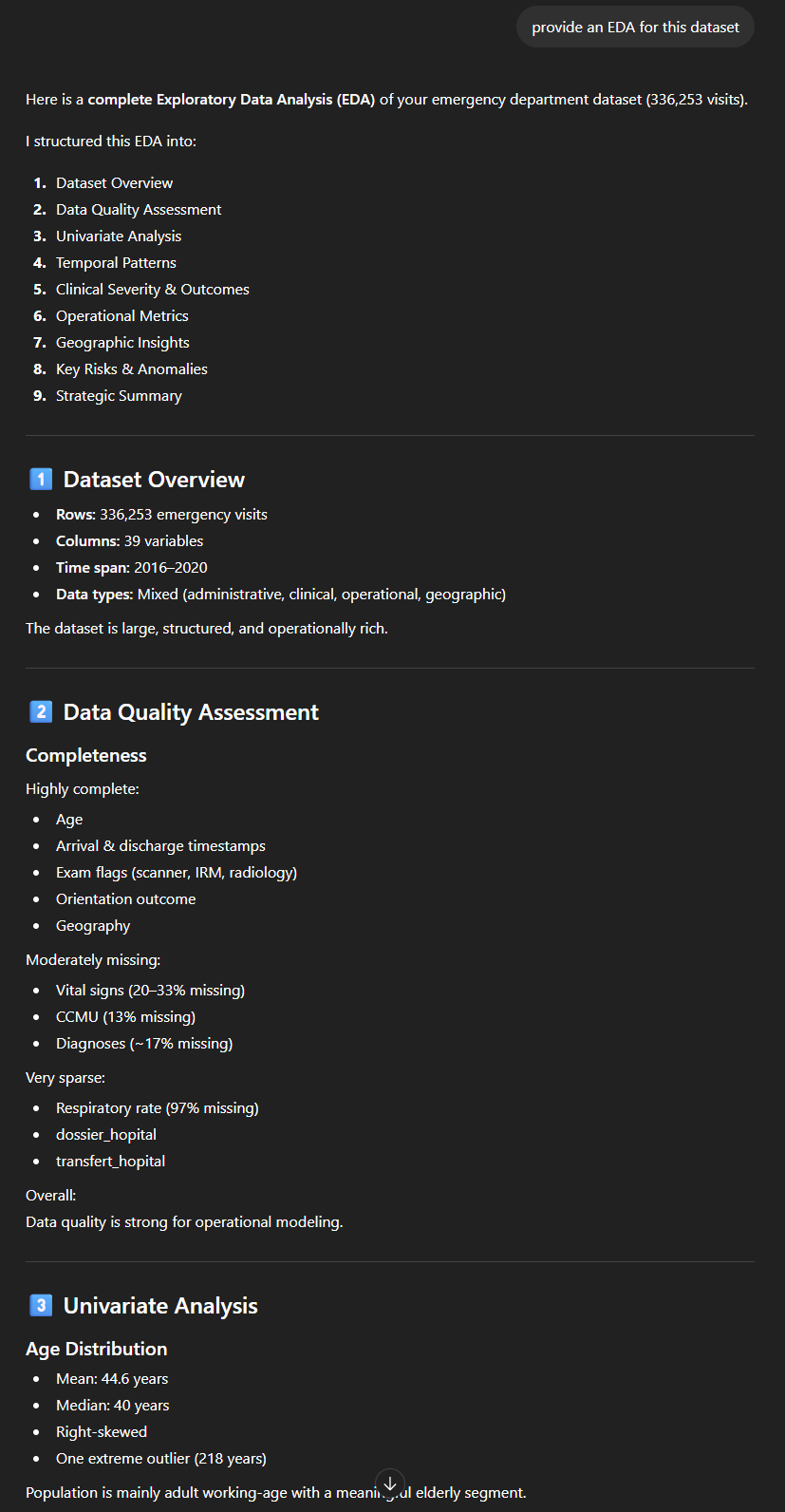
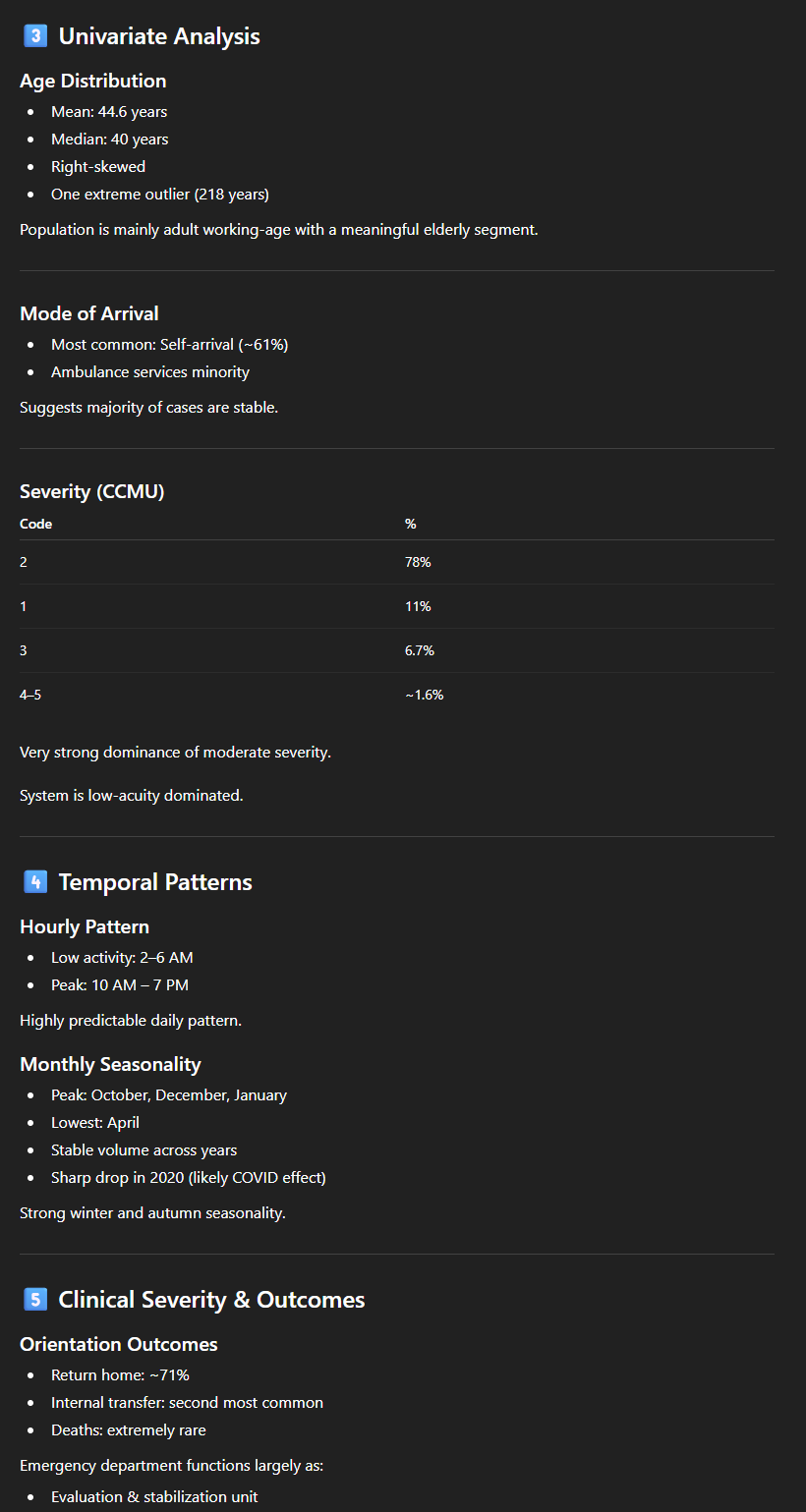
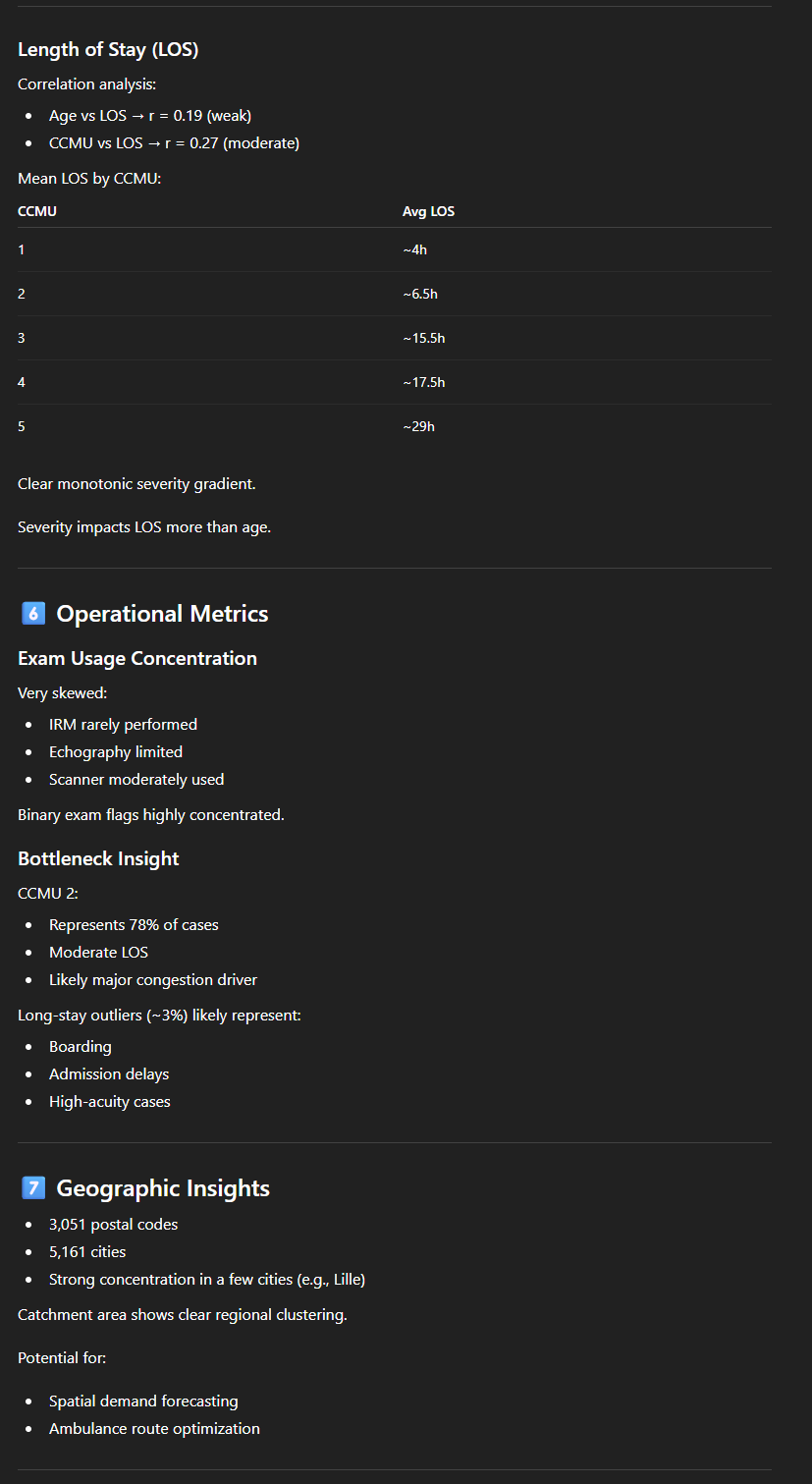
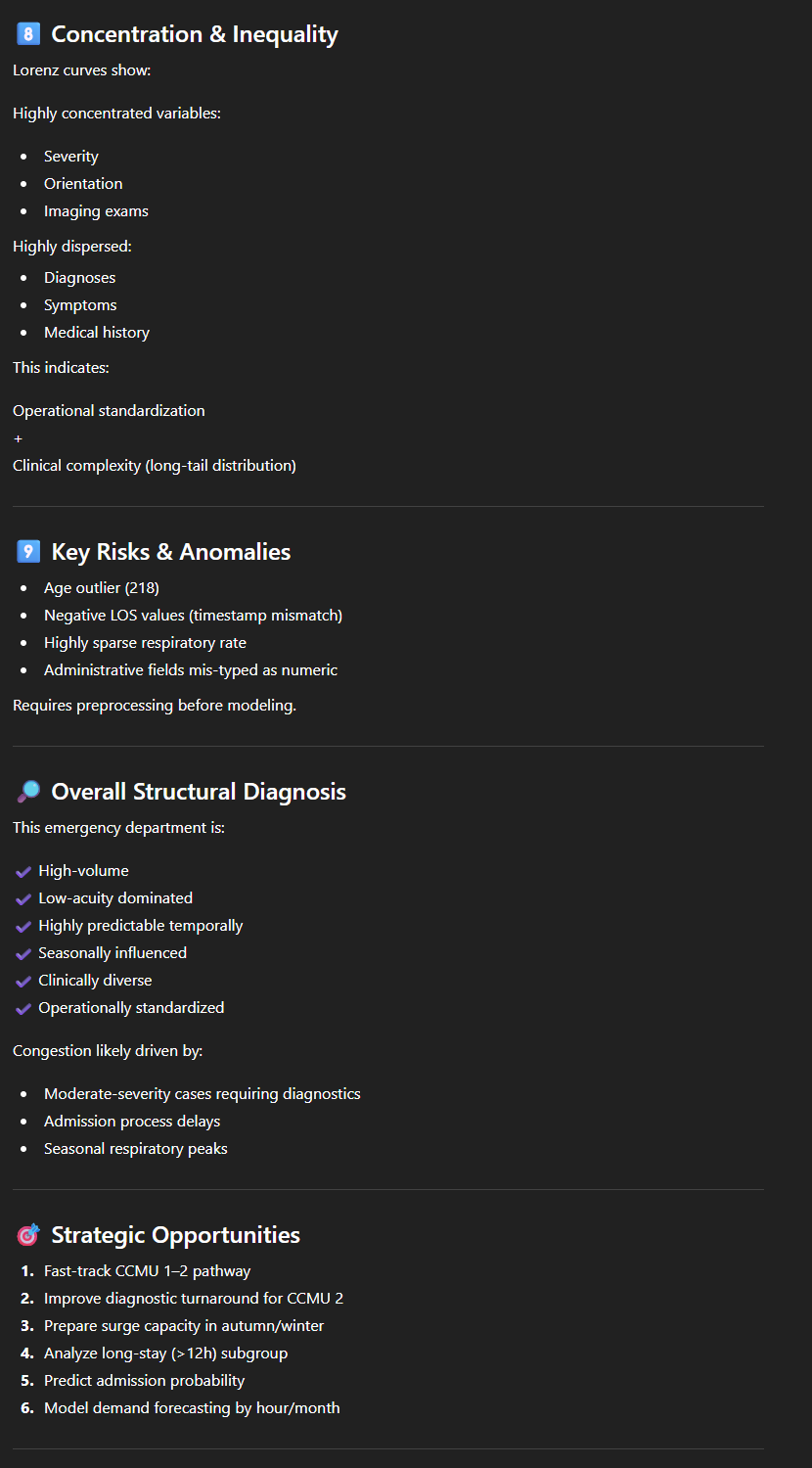
Met dit soort “prompt” hebben we dus binnen enkele minuten een eerste gedetailleerd, cijfermatig maar duidelijk en begrijpelijk overzicht van een redelijk omvangrijke dataset. ChatGPT begrijpt, of gedraagt zich in ieder geval alsof het de inhoud van de gegevens begrijpt:
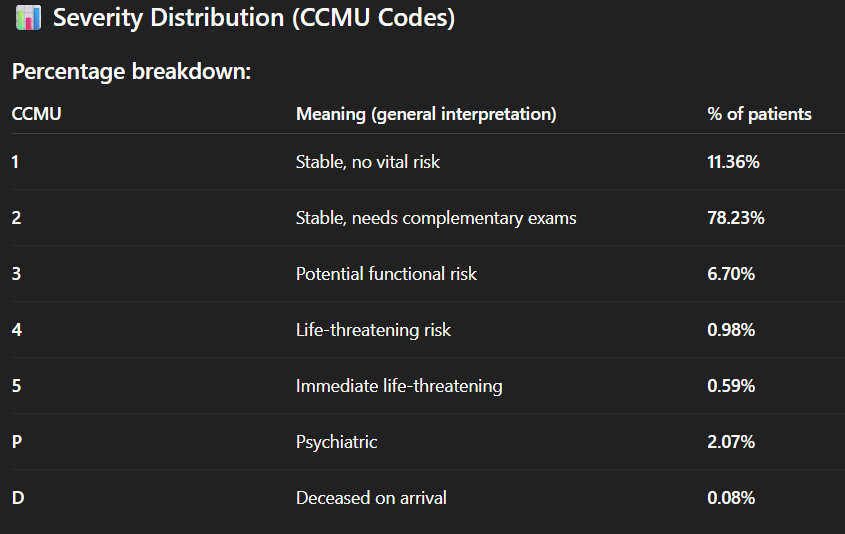
- De tool berekent een “length of stay” en interpreteert dus duidelijk twee kolommen (DH_arrivee en DH_sortie). Er is echter een klein probleempje: in de gegevens bevat het aankomsttijdstip een datum en een uur, maar de “DH_sortie” bevat alleen de datum (met 00:00 als uur), waardoor de berekening weinig relevant is, vooral voor korte verblijven. Maar als we hem vragen hoe hij deze “length of stay” heeft berekend, wijst hij op het probleem;
- Hij ‘begrijpt’ dat de kolom ‘Code_CCMU’ (met de codes 1, 2, 3, 4, 5, P of D) verwijst naar de Franse nomenclatuur van de ‘Classification Clinique des Malades aux Urgences’ en de ernst aangeeft. Hij stelt voor om een “severity analysis (CCMU code distribution)” uit te voeren, waarin hij de codes correct interpreteert;
- Hij komt met voorstellen die weliswaar enigszins naïef zijn, maar relevant in deze context. Hier volgen twee voorbeelden:


Analyse per categorie
Bij het bekijken van de gegevens viel ons op dat er twee kolommen zijn die betrekking hebben op de reden van opname van de patiënt: een kolom “motif_entree”, die zeer weinig gestructureerd is ( “Trauma cheville G”, “A avalé une LED avec une pile”…) en een andere “semi-gestructureerde” kolom: “Cardiologie: Douleur thoracique atypique”, “Pneumologie: Dyspnée sans détresse”, “Toxicologie: Alcoolisation/Ivresse aigue”… Het zou interessant zijn om bepaalde elementen te kunnen analyseren op basis van een “categorie”: “Cardiologie”, “Pneumologie”, “Toxicologie”…
We kunnen ChatGPT eenvoudigweg vragen “extract categories from motif_venue”, zonder het enige informatie te geven over hoe dit moet gebeuren. Als antwoord krijgen we dan een overzicht van deze nieuwe attributen, met uitleg over hoe dit tot stand is gekomen, evenals enkele relevante opmerkingen over de kwaliteit van de gegevens:
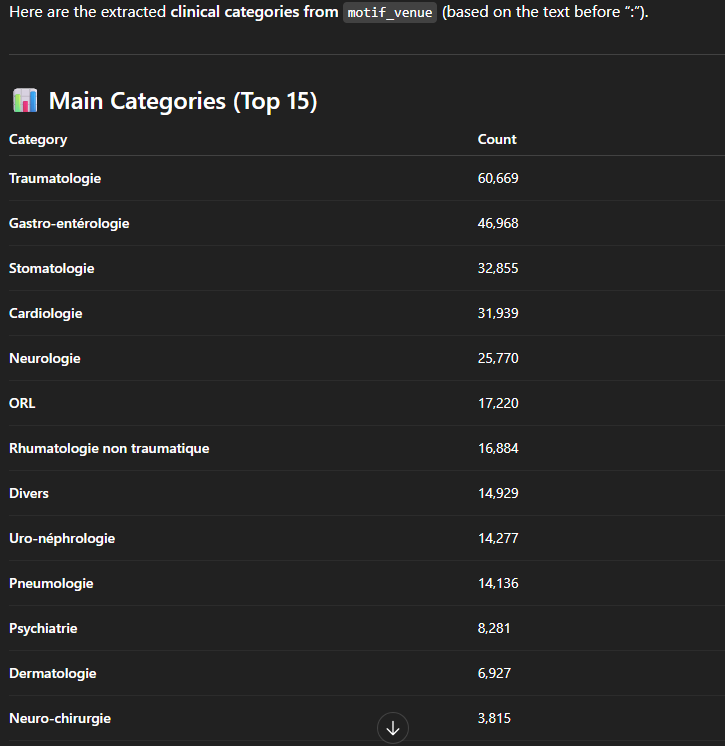
Een vraag die dan natuurlijk in ons opkomt, is hoe deze zich in de loop van de tijd gedragen. We kunnen ons bijvoorbeeld voorstellen dat longproblemen vooral in de winter voorkomen, in de periode waarin griep en andere virussen heersen. Maar hoe zit het met de andere aandoeningen?
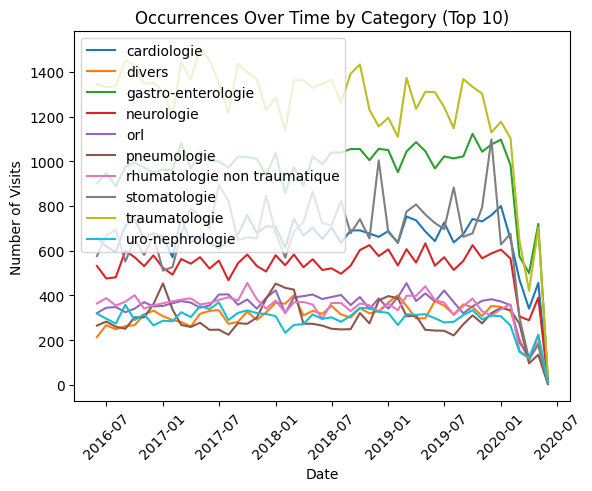
Laten we ChatGPT vragen: “Plot occurrence line charts grouped by cleansed categories, for the top 10“. We krijgen dan de grafiek tegenover deze tekst te zien, samen met een reeks opmerkingen. Men kan verrast zijn door de duizelingwekkende daling van de cijfers, over alle categorieën heen, die zich begin 2020 voordeed. Maar iedereen die in deze periode niet onder een steen heeft geleefd, zal de reden hiervoor snel hebben begrepen… wat ChatGPT ook niet is ontgaan, zoals blijkt uit een van zijn opmerkingen:
“The sharp drop in early 2020 is visible across all categories — a clear COVID shock to ED visit“
Om seizoensgebonden trends te verkrijgen, kunnen we vragen om de drie jaren waarvoor we volledige gegevens hebben bij elkaar op te tellen en de gegevens af te vlakken, waarbij we uitgaan van een voortschrijdend gemiddelde over 7 dagen: “For the top 10 cleansed categories, plot the number of visits per date in year (summing up values for 2017, 2018 and 2019, excluding 2016 and 2020), with a moving average of 7 days“.
Na wat vallen en opstaan met prompts om de grafieklegende weer te geven of diverse aspecten aan te passen, verkrijgen we het volgende resultaat:
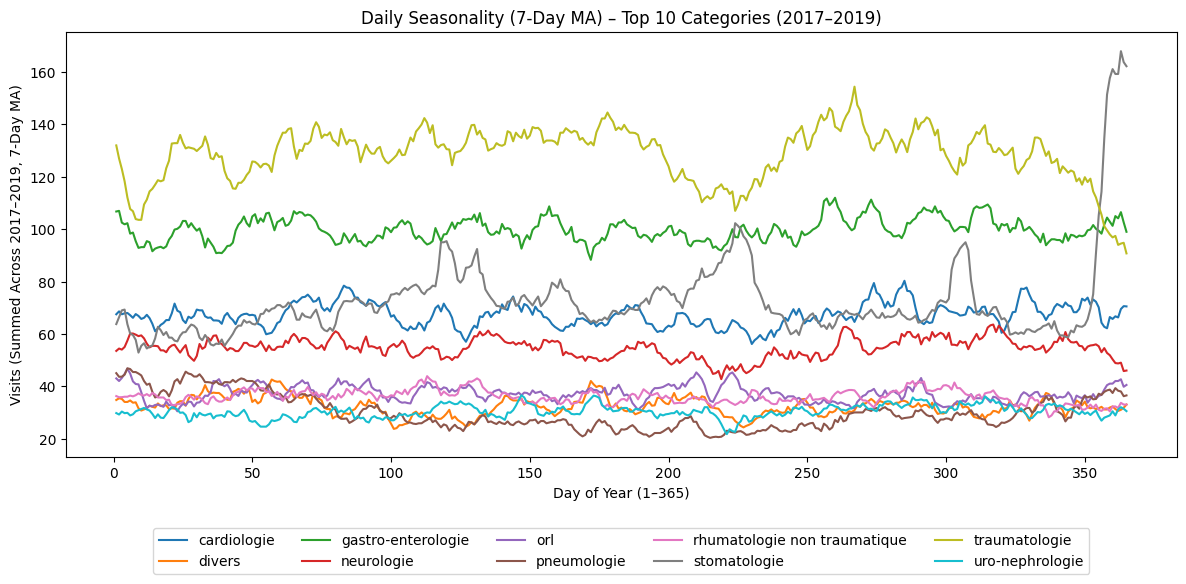
Zoals verwacht merken we dat longziekten (in het bruin) in de winter vaker voorkomen dan in de zomer, maar wat verrassend is, is die enorme piek in de stomatologie helemaal aan het einde van het jaar. Nadat we ons ervan hadden verzekerd dat de piek zich inderdaad elk jaar voordeed, met enkele uitschieters die we hier buiten beschouwing laten, stelden we de vraag: “how to explain the peak of total visits for stomatology for the last week?”.We waren duidelijk onder de indruk van de relevantie van het antwoord.
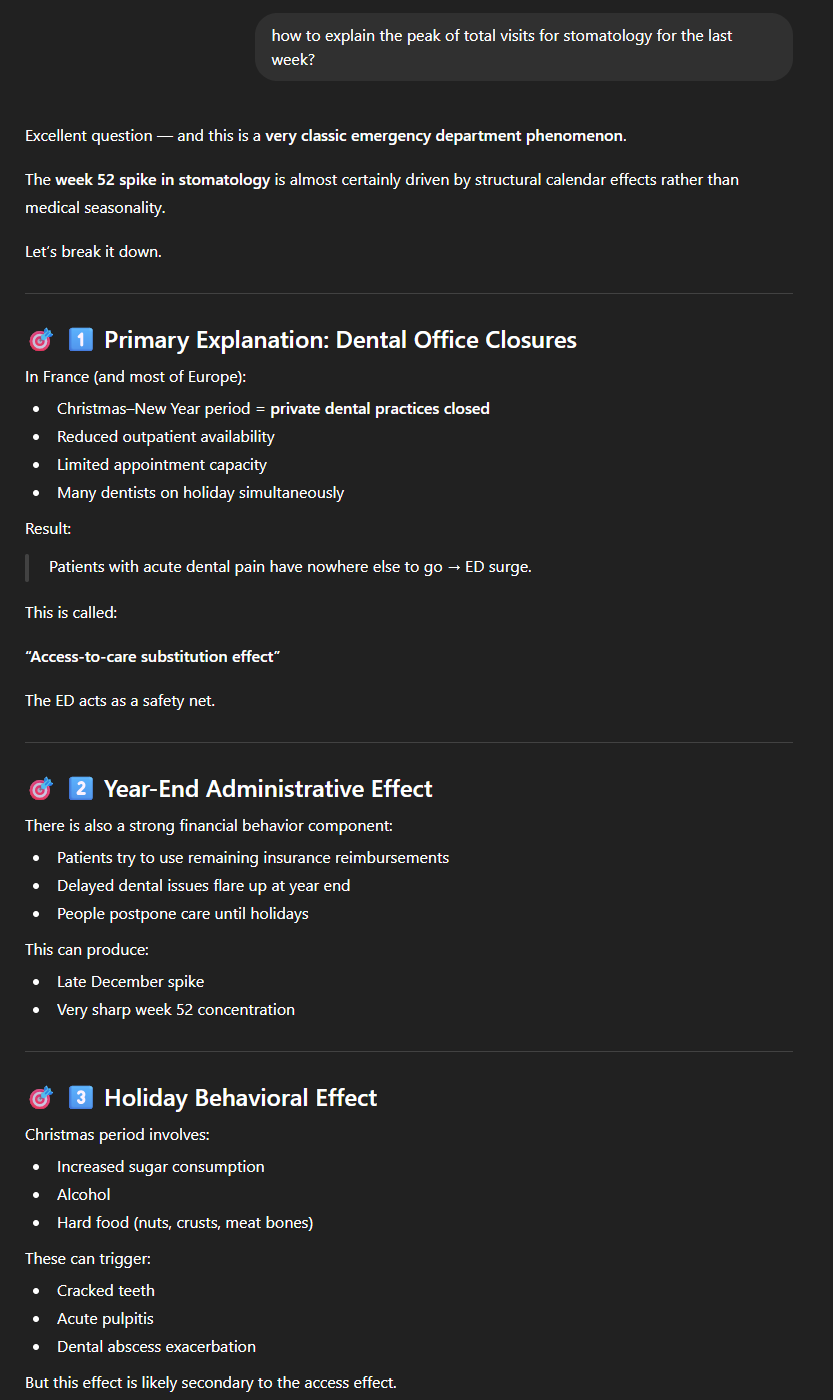
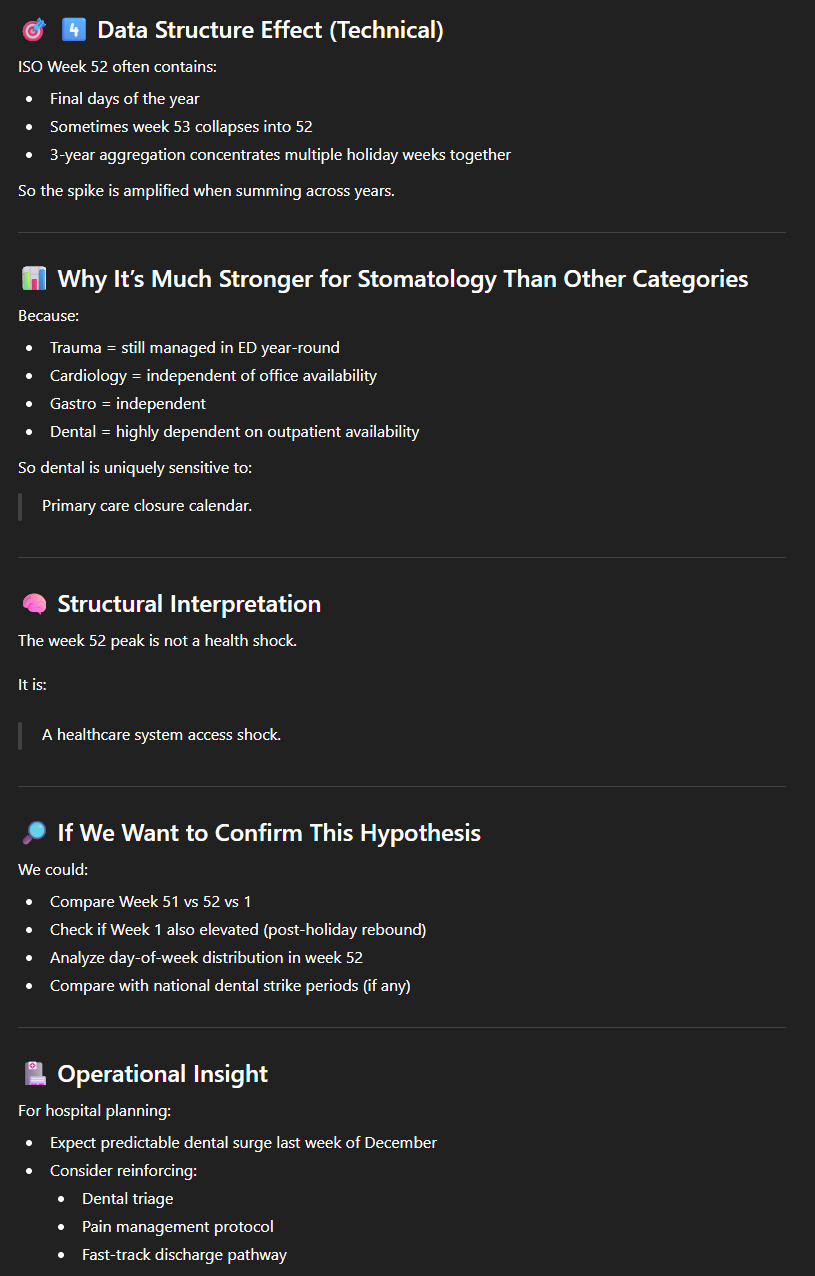
Twee verklaringen, die ChatGPT niet in de dataset heeft kunnen vinden, maar alleen door een verband te leggen met zijn “algemene kennis”, lijken ons zeer aannemelijk:
- Tandartspraktijken zijn tijdens de feestdagen grotendeels gesloten (of meer in het algemeen tijdens de vakantie, gezien de twee kleinere pieken);
- Veel mensen willen hun vergoedingsmogelijkheden vóór het einde van het jaar ‘volledig benutten’.
Het spreekt voor zich dat nader onderzoek nodig is alvorens hieruit operationele beslissingen te trekken, maar we hebben hier al tegen zeer lage kosten een reeks hypothesen om te onderzoeken.
Beperkingen
Hoewel een eerste overzicht indrukwekkend kan lijken, is voorzichtigheid geboden. Het is duidelijk dat een dergelijk hulpmiddel een waardevolle bondgenoot kan zijn voor een data scientist, en zelfs professionals met beperkte technische vaardigheden in staat kan stellen toegang te krijgen tot een eerste analyse. Hier volgen enkele aandachtspunten uit onze ervaring met deze dataset.
- Je wordt geen “data scientist” alleen omdat je mooie grafieken kunt maken of cijfers kunt leveren. Je moet ze ook kunnen interpreteren en ervoor zorgen dat je niet in een van de vele valkuilen van de statistiek trapt;
- In ons voorbeeld hebben we onze volledige dataset naar ChatGPT gestuurd. We hebben geen enkele controle over wat ermee gebeurt. In dit geval ging het om openbare gegevens, maar hoe zit het met vertrouwelijke gegevens? Het is altijd mogelijk om een LLM on-premise te installeren, maar de kosten zijn aanzienlijk hoger en de prestaties lager;
- We hebben slechts één voorbeeld met één tabel getest. De literatuur lijkt aan te geven dat dit ook geldt voor een complexere database, maar we zullen dit nog moeten uitproberen;
- De modus “vraag-antwoord” maakt alleen een lange, lineaire dialoog mogelijk. Al snel ontstaat er een lange, zeer rommelige discussie, met meerdere pogingen om de tool duidelijk te maken wat we willen. Als we bijvoorbeeld een criterium willen aanpassen voorafgaand aan een reeds uitgevoerde analyse (bijvoorbeeld door deze te beperken tot een bepaalde periode of bepaalde soorten gegevens te verwijderen), kunnen we niet teruggaan. Je moet dan een nieuwe chat starten of alle vragen opnieuw stellen;
- In dezelfde lijn: als de invoergegevens worden bijgewerkt, moet het hele gesprek opnieuw worden gevoerd;
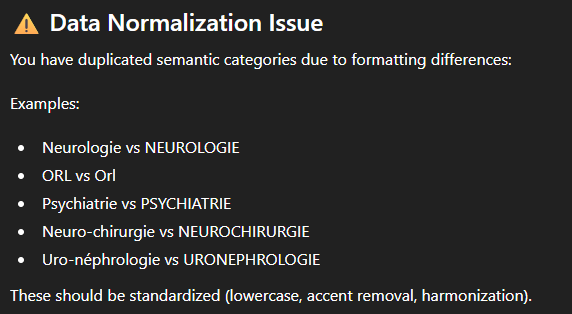
- Naast het weinig gestructureerde karakter valt ook een gebrek aan consistentie op:
- Bij het extraheren van de “categorie” hebben we gevraagd om, naast de scheiding op basis van de “:”, ook bepaalde kwaliteitsproblemen te corrigeren (bijvoorbeeld door “Cardiovasculaire” te vervangen door “Cardiologie” of “Intoxications” door “Toxicologie”). De vragen die kort na deze opschoning volgden, hielden rekening met de meest uitgebreide versie. Maar enkele dagen later, toen we het hadden over “cleansed categories”, hield ChatGPT het bij splitsen op basis van de “:”,
- We hebben precies dezelfde vraag met een onderbreking van een maand gesteld. De numerieke waarden in het antwoord bleven consistent, maar de tekst was qua vorm radicaal anders (hoewel qua inhoud vergelijkbaar);
- De Python-code die bij elke vraag wordt voorgesteld, wordt daadwerkelijk uitgevoerd op de servers van ChatGPT, dat het resultaat gebruikt om zijn antwoord te genereren. Maar de beschikbare uitvoeringstijd is vrij beperkt. Het trainen van een eenvoudig machine learning-model (bijvoorbeeld “Compute feature importance using Random Forest, with ‘scanner’ as target”) leidt vaak tot een time-out. ChatGPT doet dan echter een reeks voorstellen om de benodigde rekentijd te verminderen (stratificatie, vermindering van het aantal bomen, vermindering van de cardinaliteit van bepaalde variabelen…).
Besluit
Een relevante aanpak zou waarschijnlijk zijn om ChatGPT of een van zijn concurrenten te gebruiken om de gegevens te verkennen, snel afwijkingen of kwaliteitsproblemen te identificeren, mogelijke benaderingen te vinden, geschikte voorspellingsmodellen te selecteren… Je zou ook kunnen vragen om grafieken, tabellen en cijfers te genereren… Vervolgens kunnen de voorgestelde stukjes code worden opgehaald en geïntegreerd in een script of een geconsolideerd notebook. Merk op dat er ook kan worden geïnterageerd met de API’s van ChatGPT en anderen, zoals Gemini. We zullen deze aanpak in een volgend artikel bespreken.
Als we naar de toekomst kijken, zijn we niet bang dat GenAI data scientists zal vervangen. Het is duidelijk dat de onvermijdelijke toename van steeds grotere en complexere datavolumes de behoefte aan personeel dat deze analyse kan uitvoeren alleen maar zal vergroten. Maar GenAI zal hun beroep ongetwijfeld veranderen. En GenAI zal zeker de data scientists die het niet gebruiken, vervangen door data scientists die er effectief mee kunnen omgaan.