Dans cet article, nous allons explorer un concept fondamental de l’analytique géographique (GIS Analytics) : la jointure spatiale. Cet article est accompagné d’un notebook Python (lien git – lien nbviewer), permettant à chacun d’approfondir la question et de manipuler les différents exemples. La jointure spatiale est l’équivalent géographique de la jointure classique, ou attributaire, que l’on réalise avec un JOIN dans une requête SQL. Nous allons parcourir quelques exemples, où nous l’appliquerons sur des données géographiques disponibles en open data sur la découpe administrative de la Belgique.
Sans données géographiques
Imaginons d’abord un organisme qui possède une liste d’observations (incident détecté, contrôle à effectuer…) dont il connait l’emplacement géographique (latitude et longitude). 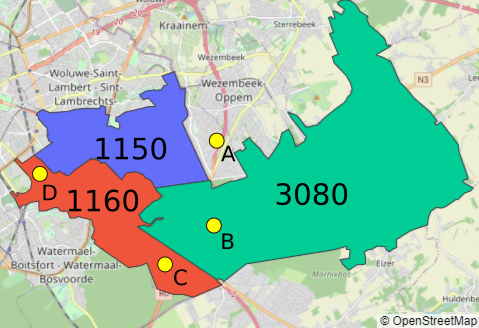 Si l’on veut enrichir cette liste avec, par exemple, la province de l’observation (pour sélectionner l’antenne provinciale qui en sera chargée), il sera classiquement nécessaire de connaitre le code postal de chaque observation, ainsi qu’une table qui indiquera, pour chaque code postal du pays, la province correspondante. Considérons l’exemple ci-contre : les observations (points jaunes) seront reprises dans une table “observations”, et les codes postaux (zones de couleur) dans une table “zipcodes”.
Si l’on veut enrichir cette liste avec, par exemple, la province de l’observation (pour sélectionner l’antenne provinciale qui en sera chargée), il sera classiquement nécessaire de connaitre le code postal de chaque observation, ainsi qu’une table qui indiquera, pour chaque code postal du pays, la province correspondante. Considérons l’exemple ci-contre : les observations (points jaunes) seront reprises dans une table “observations”, et les codes postaux (zones de couleur) dans une table “zipcodes”.
observations
| ID | zipcode |
|---|---|
| A | |
| B | 3080 |
| C | 1160 |
| D | 1160 |
| … | … |
zipcodes
| zipcode | province |
|---|---|
| 1150 | Bruxelles-Capitale |
| 1160 | Bruxelles-Capitale |
| 3080 | Brabant Flamand |
| … | … |
Sur base de ces deux tables, on peut effectuer un simple “(LEFT) JOIN” en SQL (ou un “merge” de dataframe Python Pandas) :
SELECT o.ID, o.zipcode, z.province FROM observations o LEFT JOIN zipcodes z ON o.zipcode = z.zipcode
On obtiendra la table enrichie suivante :
observations_prov
| ID | zipcode | province |
|---|---|---|
| A | ||
| B | 3080 | Brabant Flamand |
| C | 1160 | Bruxelles-Capitale |
| D | 1160 | Bruxelles-Capitale |
| … |
Avec des données géographiques
Cette approche, qui nécessite de connaitre le code postal, peut s’avérer problématique. Il peut être mal aisé pour un agent de connaitre le code postal de l’endroit où il se trouve ou veut aller (le long d’une autoroute, dans un bois, …). Une simple localisation GPS ou un clic sur une carte rendrait les choses plus faciles.
Dans les bases de données géographiques (type PostGIS, extension géographique de PostgreSQL), ou la librairie GeoPandas en Python, qui étend Pandas avec des données géographiques (voire même dans les logiciels comme QGIS), il existe un type de données “géométriques”. Il peut typiquement s’agir d’un point (représenté par deux coordonnées), ou d’un polygone (une séquence de points).
Dans l’exemple ci-dessus, la table ‘observations’ pourra simplement contenir la position de l’observation (en plus d’un ID), et il nous suffira d’une table “provinces” à deux colonnes : le nom de chaque province, et le polygone représentant ses frontières.
| ID | geom |
|---|---|
| A | point(xa, ya) |
| B | point(xb, yb) |
| C | point(xc, yc) |
| D | point(xd, yd) |
| province | geom |
|---|---|
| Bruxelles-Capitale | polygon(pt1, pt2, pt3,…) |
| Brabant Flamand | polygon(…) |
| Braband Wallon | polygon(…) |
Ces systèmes permettent alors une jointure spatiale (spatial join) : au lieu de nécessiter une clé commune entre deux tables (comme c’est le cas dans la jointure “classique”, ou attributaire ; le code postal dans l’exemple ci-dessus), on associera deux enregistrements si leurs objets géométriques respectifs ont une relation définie (inclusion, chevauchement, égalité…). En PostGIS, on aura alors la requête suivante :
SELECT o.ID, p.province FROM observations o LEFT JOIN provinces p ON ST_Contains (p.geom, o.geom)
En pratique
Pour rendre les choses concrètes, nous allons considérer une série de datasets accessibles en Open Data, concernant la géographique belge. Il existe, en Belgique, deux modes de numérotation du territoire. Un premier, basé sur les codes postaux, manquant de cohérence, mais largement utilisé pour les adresses postales. Un second, basé sur les codes INS (géré par l’ancien Institut National de la Statistique), plus cohérent et structuré, inconnu du grand public, mais largement utilisé par les administrations.
Que ça soit dans la découpe postale ou statistique, la Belgique est découpée en 3 régions (Flandre, Wallonie et Bruxelles-Capitale). Les deux premières sont ensuite découpées en provinces, elles-mêmes découpées en arrondissements (Bruxelles-Capitale étant à la fois une région, une province et un arrondissement). Les arrondissements sont ensuite découpés en communes (581 à l’heure d’écrire ces lignes, mais des réorganisations sont fréquentes).
Dans la découpe postale, ces communes sont parfois découpées en sous-communes, ou localités (dont souvent, pour 521 communes, une qui porte le même nom que la commune principale). “Parfois”, parce que si la province d’Anvers contient 33 communes sans localité (ou plutôt, avec une seule localité), aucune commune n’a moins de 4 localités en province de Namur. Ce qui n’empêche pas Anvers d’avoir un commune composée de 17 localités. Au niveau national, 98 communes n’ont qu’une seule localité postale.
Un code postal est attribué soit à une commune (même si elle contient plusieurs sous-communes), soit à une sous-commune (ou localité). Plusieurs situations peuvent se présenter :
- Toutes les entités partagent le même code postal. C’est le cas de 261 communes, comme par exemple Jemeppe-sur-Sambre, province de Namur, dont les 8 entités (Balâtre, Ham-Sur-Sambre, Jemeppe-Sur-Sambre, Mornimont, Moustier-Sur-Sambre, Onoz, Saint-Martin et Spy) partagent le code postal “5190” ;
- Toutes les entités ont un code postal distinct. C’est le cas de 53 communes ;
- Il y a moins de codes postaux que d’entités (169 communes). En province de Namur, la commune d’Assesse a trois entités sur le code postal 5330 (Assesse, Maillen et Sart-Bernard) et un code postal différent pour chacun des autres (5332 Crupet, 5333 Sorinne-La-Longue, 5334 Florée et 5336 Courrière). La commune d’Anvers (Antwerpen), dans la province d’Anvers a 17 entités, dont 4 qui partagent le code postal 2040, et 7 qui se nomment … Anvers (2000, 2018, 2020, 2030, 2040, 2050, 2060) !
La découpe statistique est plus consistante : chaque commune possède un code INS de 5 chiffres. Chacune de ces communes est ensuite divisée en sections de commune, ayant un code “INS 6” de 5 chiffres suivi d’une lettre, les 5 premiers correspondant à la commune. Une centaine de communes n’ont qu’une seule section, et, souvent, les sections correspondent aux localités définies par la découpe postale, mais… pas toujours ! La commune d’Ostende a par exemple 3 localités postales, mais 7 sections statistiques. La commune de Bruxelles-Ville (une des 19 communes de la région-province de Bruxelles-Capitale) a 4 localités postales (Bruxelles, Laeken, Neder-Over-Hembeek et Haren), alors que dans la découpe statistique, la localité de Bruxelles est divisée en 4 quartiers. A contrario, si Oudenaarde a 14 localités postales, elle n’a que 6 secteurs statistiques.
Jointure point – polygone (inclusion)
Dans ce premier exemple, nous avons comparé deux datasets concernant les codes postaux. Un premier dataset, fourni par bpost (la poste belge) qui reprend les frontières de chaque code postal, et un autre, fourni par l’Agence du Numérique qui reprend le centre de chacune des combinaisons code postal – localité. Dans le premier, si un code postal est partagé par plusieurs localités, nous n’aurons qu’un polygone pour ce code postal. Alors que dans le second, nous aurons le centre de chaque localité, chacune d’elle devant se trouver, en théorie, au sein du polygone correspondant.
Nous avons réalisé une jointure spatiale de ces deux datasets, et avons regardé si, pour chaque combinaison retournée, le code postal de gauche correspondait au code postal de droite. Comme on peut constater dans le notebook fourni en annexe, nous avons pu identifier une cinquantaine de différences. Chacune des différences que nous avons approfondies ont mis en évidence une erreur manifeste dans le dataset de l’Agence du numérique. Par exemple, il existe trois “Haren” en Belgique. Dans ce dataset, “3700 Haren” a été placé au centre de “1130 Haren”. Ou encore, la commune de “3400 Laar” a été position à “Laar” (nom de la rue), à 2180 Ekeren. Ces anomalies nous ont permis de voir qu’un certain nombre de points ont été placés au même endroit : par exemple, toutes les entités “Anvers” de la commune d’Anvers ont été localisées au même endroit, bien qu’elles aient chacune un code postal différent.
On peut supposer que ce dataset a été construit en envoyant la liste des communes belges à un géocodeur, sans trop analyser le résultat. Il aurait été très difficile d’identifier ces erreurs avec des techniques classiques.
Jointure polygone – polygone (chevauchement)
Avec la jointure spatiale, nous allons pouvoir, sur base d’un dataset contenant les frontières des communes postales et un autre contenant les frontières des communes statistiques, réaliser 3 opérations :
- Vérifier la consistance, et identifier des territoires qui ne seraient pas dans la même commune en fonction du dataset
- Faire le “mapping” entre la dénomination connue dans un dataset et celle connue dans l’autre
- Faire le “mapping” entre un code postal et un code INS.
Détaillons maintenant la première opération (le deux suivantes sont visibles dans le notebook joint). Nous faisons donc une jointure spatiale entre deux tables de 581 polygones. Première surprise : on obtient… 3 802 résultats ! Ceci est dû au fait que les deux datasets n’ont pas le même degré de précision, et on obtient très fréquemment un chevauchement de quelques (kilo)mètres carrés entre deux communes voisines. Mais en examinant la superficie de l’intersection par rapport à la superficie des communes concernées, il est facile (les détails sont donnés dans le notebook joint) d’isoler les correspondances légitimes de celles dues à des imprécisions de tracés. La même analyse nous a aussi permis de mettre en évidence des différences entre des tracés qui allaient bien au-delà d’erreurs de précision. Ci-dessous, nous avons isolé les couples de polygones dont la superficie commune est comprise entre 2 % et 98 % du plus grand des deux polygones.
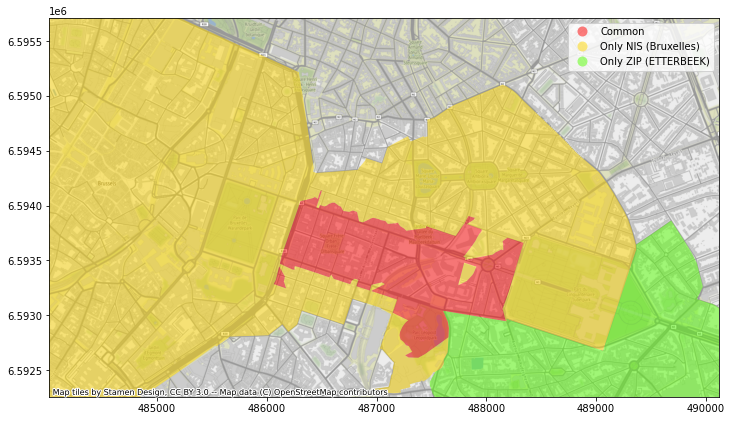
Par exemple, à Bruxelles, tout le quartier autour de “Schuman” et “Maelbeek” fait partie de la commune d’Etterbeek selon les données postales, alors qu’il fait partie de la commune de Bruxelles-ville selon les données statistiques. Google maps et OpenStreetMap sont du même avis que les données statistiques, alors que Here et Bing se rangent du côté des données postales ! Dans la pratique, les plaques de rue visibles sur StreetView semblent contredire les données postales.
Une situation similaire se présente toute autour de l’avenue Louise, où un ensemble de rues fait partie, selon le dataset, de la commune d’Ixelles ou de la commune de Bruxelles. De façon comparable, un petit bout de territoire est “disputé” entre Ottignies-Louvain-La-Neuve et Mont-Saint-Guibert, ainsi qu’entre Drogenbos et Sint-Pieters-Leeuw, entre Charleroi et Ham-Sur-Heure…
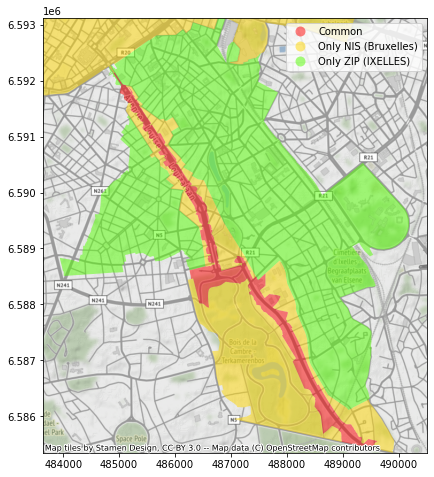
Ixelles 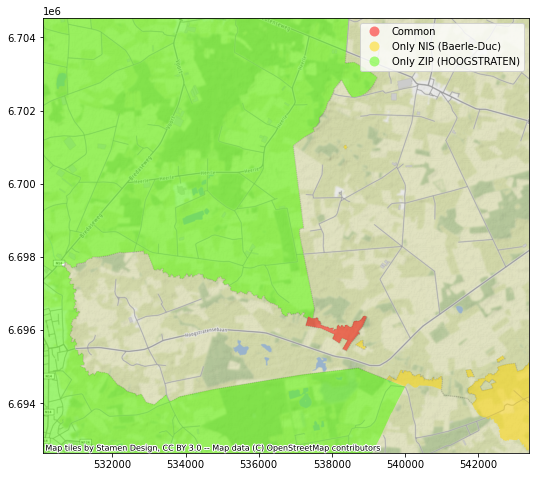
Baerle-Duc 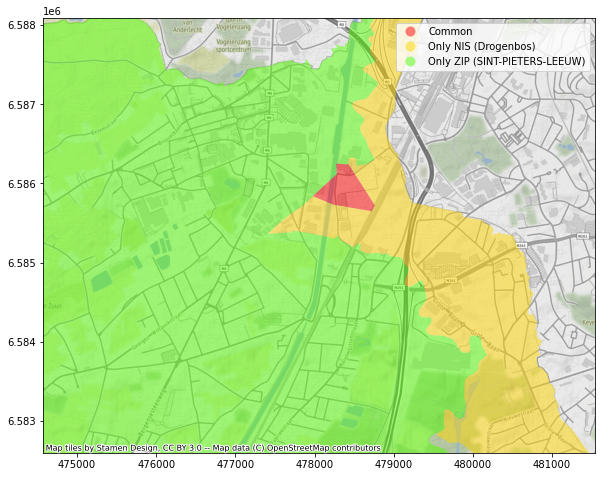
Drogenbos 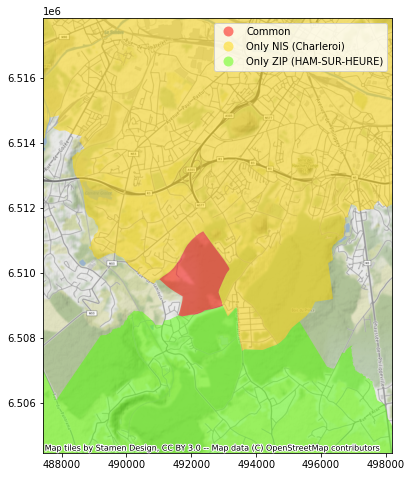
Ham-Sur-Heure 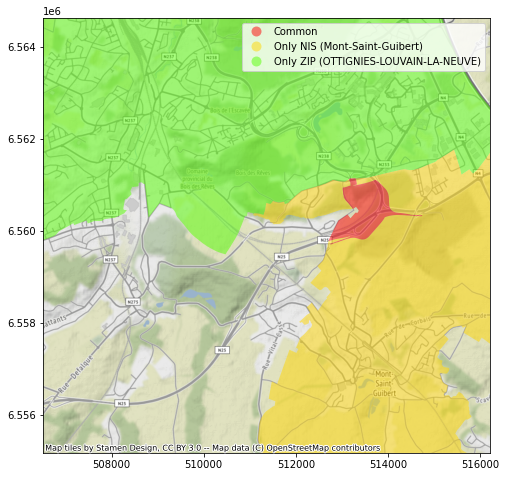
Louvain-La-Neuve 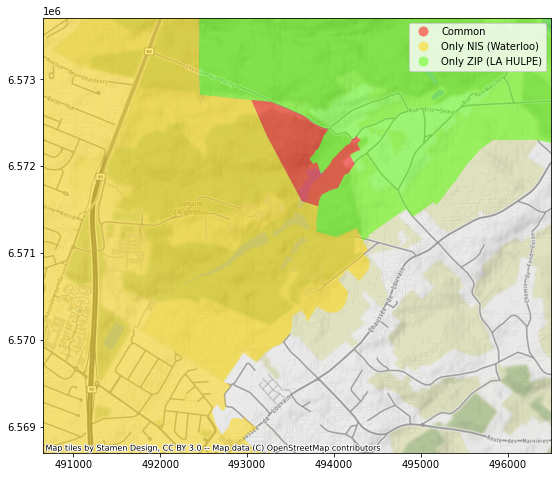
Waterloo
Le mot de la fin
Les ambiguïtés que nous avons identifiées sont fréquemment des zones boisées ou inhabitées, mais ça n’est pas toujours le cas. Difficile de dire s’il s’agit d’erreur de qualité dans les données, ou bien si deux administrations ne sont effectivement pas d’accord sur l’affectation de ces territoires. Ce qui pourrait éventuellement causer quelques difficultés en cas, par exemple, de catastrophe sur le territoire concerné.
Nous avons uniquement fait l’analyse au niveau des communes principales. On peut imaginer observer d’autres surprises en descendant l’analyse au niveau des sections de communes et entités, quand la correspondance peut se faire. Mais à nouveau, des techniques d’analytiques classiques ne nous auraient pas permis d’identifier ces incohérences : la jointure spatial ne permet pas uniquement d’enrichir un dataset, mais également d’y mettre en avant des erreurs ou des imprécisions.
Leave a Reply