 Venant de finaliser une étude sur l’archivage des bases de données avec un collègue, nous avons mené un examen du marché via l’examen de quatre solutions existantes. Nous les avons confrontées à notre définition de l’archivage et aux différentes caractéristiques identifiées comme importantes pour ce type de solution.
Venant de finaliser une étude sur l’archivage des bases de données avec un collègue, nous avons mené un examen du marché via l’examen de quatre solutions existantes. Nous les avons confrontées à notre définition de l’archivage et aux différentes caractéristiques identifiées comme importantes pour ce type de solution.
Pour mener cette étude, nous sommes partis de la définition suivante de l’archivage (déjà exposées ici) :
 « Archiver consiste à prendre un objet et à le transférer sous certaines conditions dans un système qui permettra d’en assurer la préservation pendant un certain laps de temps avec toute la sécurité requise ».[1] Ce qui implique les actions suivantes :
« Archiver consiste à prendre un objet et à le transférer sous certaines conditions dans un système qui permettra d’en assurer la préservation pendant un certain laps de temps avec toute la sécurité requise ».[1] Ce qui implique les actions suivantes :
- sélection de l’information ;
- transfert dans un autre système pour en assurer la sécurité (gestion de l’intégrité et de l’authenticité) ;
- préservation de l’information, c’est-à-dire aussi la couche physique que la couche logique et sémantique ;
- gestion de la durée de conservation de l’information.
Il s’agit donc d’une définition et d’une acceptation plus large (issues du domaine du « records management ») que le transfert de vieilles données « à la cave », conception encore largement répandue et reprise sous le terme anglais « archiving ».
Nous avons envoyé cette définition, accompagnées d’autres éléments importants (Database Archiving – General information about existing solutions), aux fournisseurs que nous avons contactés en leur demandant de positionner leur solution par rapport à ces différents points. Sur cette base, nous avons pu distinguer différentes familles :
- Au niveau de la forme d’archivage : certains systèmes vont archiver les données sous la forme d’une autre base de données, de même type que la base de données de production ou non, tandis que d’autres vont archiver les données sous forme de fichiers, eux-mêmes référencés à l’aide de métadonnées. Si la forme « base de données » peut présenter des avantages, notamment en termes d’accès et de consultation, elle ne représente pas une solution à long terme. La conservation des données sous forme de fichiers est donc vivement recommandée à long terme.
- Au niveau du processus de capture : certaines solutions (dites PULL) se connectent à la base de données source en vue d’extraire elles-mêmes les données sur la base des paramètres introduits. Ces solutions proposent des fonctionnalités avancées de data profiling, d’extraction, … Les autres systèmes (dits PUSH) sont plus passifs : les données sont extraites de la base de données de production et poussées vers la solution d’archivage (on parle de versement). Les systèmes PULL offrent une aide non négligeable aux utilisateurs mais posent néanmoins des questions de sécurité (puisque la solution d’archivage doit disposer de droits de suppression dans la base de données de production) et gèrent rarement les questions d’intégrité (cf. point suivant).
- Au niveau de la gestion de l’intégrité : certains systèmes font de la gestion et du contrôle de l’intégrité des données une fonctionnalité au cœur de la solution, tandis que d’autres laissent ce soin à un outil tiers (que ce soit au niveau software ou hardware).
Voici le tableau récapitulatif des solutions examinées (les solutions ont été anonymisées) :
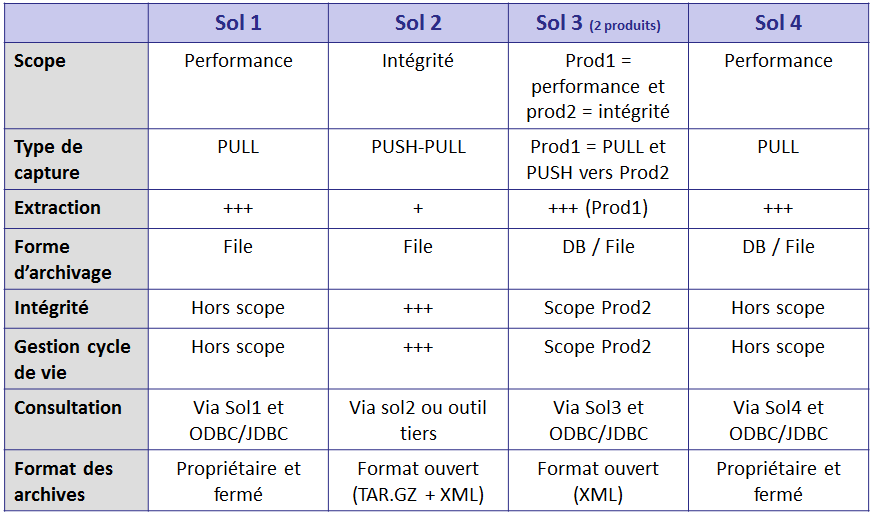
Sur cette base, les éléments suivants ont pu être mis en évidence :
- Les solutions positionnées sur le marché du « Database Archiving » sont toutes de type PULL. Ce positionnement est en cohérence avec la définition du terme anglais « archiving » qui consiste à déplacer des données moins utilisées ou ‘obsolètes’ vers un espace tiers afin d’optimiser les applications en production. Ces solutions ne traitent quasiment jamais de l’intégrité des données archivées. Par conséquent ces solutions ne répondent pas de manière complète à la problématique de l’archivage selon la définition que nous y avons donnée.
Ces solutions présentent toutefois des fonctionnalités avancées pour l’extraction des données. - Les solutions de type PUSH se situent davantage sur le marché du records management. Dans ce cas, l’intégrité fait partie inhérente des solutions mais elles disposent de fonctionnalités de gestion du cycle de vie.
- Pour une couverture fonctionnelle complète de la définition de l’archivage que nous avons proposée, deux outils seront donc nécessaires, quoique la partie extraction puisse être exécutée manuellement, c’est-à-dire par des administrateurs de la base à l’aide de requêtes SQL.
- La méthode PULL est transactionnelle, ce qui correspond davantage à la manière de travailler dans le monde des bases de données. La transaction est terminée quand les données sont archivées, alors que dans le cas de la méthode PUSH, la transaction se terminerait par le dépôt des données sur un file system où la solution d’archivage les capture. Par conséquent, la méthode PUSH ne permet pas une transaction unique positionnant d’abord l’archivage effectif des données et ensuite la suppression desdites données.
- Les fonctionnalités d’extraction sont uniquement disponibles pour les bases de données relationnelles. Aucun fournisseur n’a de connecteurs vers des bases de données non relationnelles, même ceux qui ont des relations historiques avec ce type de base de données.
- La consultation des données archivées issues d’un DBMS est plus mures dans le cas des outils PULL que PUSH. Ces solutions proposent généralement des fonctionnalités d’accès soit via IHM, soit via des connecteurs ODBC/JDBC (ce qui rend les accès applicatifs possibles). Dans le cas des outils PUSH, des fonctionnalités de consultation et d’accès sont possibles mais plus génériques et elles prennent donc moins en compte les spécificités des données issues d’un DBMS.
- Enfin, plusieurs solutions archivent les données dans un format ouvert et documenté (CSV, XML, containeur tar.gz), ce qui est un atout pour un archivage pérenne. Les solutions proposant des formats propriétaires ne sont donc pas à privilégier.
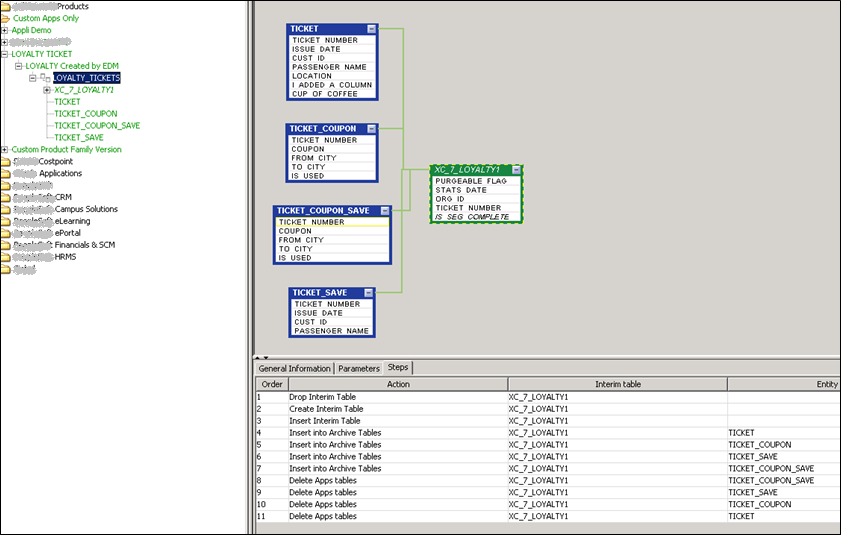
La solution effectue un profiling de la base de données et en propose une schéma que l’utilisateur peut enrichir.
Un conseil pour finir : indiquez bien aux fournisseurs votre définition de l’archivage afin de pouvoir examiner leurs solutions de manière critique.
[1] M.-A. Chabin, Moreq2 et archivage sécurisé, Fédération Nationale des Tiers de Confiance, 2009, p. 6.
Leave a Reply