
Bij het software bouwen, maken we meestal geen op zichzelf staande programma’s meer. We bouwen vandaag eerder Applicatie Ecosystemen. Wanneer we dus een stuk software schrijven, mogen we niet zomaar de ontwikkeling lokaal optimaliseren, maar moeten we ook continu rekening houden met het grotere geheel. In deze blog maken we een verkenning van een aantal zaken waar we rekening mee moeten houden bij het bouwen van een ecosysteem, en van concrete principes die we kunnen toepassen bij het uitbouwen van een erbij passende modulaire architectuur.
De Paradox van de Afhankelijkheid
Er heerst grote waarde in zaken met elkaar verbinden, en in reeds bestaande zaken te hergebruiken bij het bouwen van nieuwe dingen. Gegevens, en ook de manier waarop ze worden verwerkt, ja, soms zelfs hele stukken van een applicatie, van één instelling, kunnen ook van pas komen bij een andere. En uiteraard geldt hetzelfde ook al binnen één en dezelfde instelling. Er is dus een meerwaarde te vinden door zaken met elkaar te verbinden en door zaken van elkaar te gaan hergebruiken. Dit is ook het hele opzet achter het ReUse verhaal binnen onze sector. Connecties en communicaties tussen systemen creëren hergebruik, efficiëntie en business waarde.
Maar wanneer we zaken verbinden, maken we ze van elkaar afhankelijk. Die afhankelijkheid heeft op technisch vlak vooral nadelen. Denk maar aan het onbeschikbaar zijn van een dienst waarvan andere diensten rechtstreeks afhangen; vaak worden deze laatste dan eveneens onbeschikbaar. Maar ook semantisch maakt het de zaken moeilijker. We mogen niet zomaar puur lokaal nadenken over alle concepten die we in onze computerprogramma’s verwerken; nee, we moeten er rekening mee houden dat ze geïntegreerd of hergebruikt kunnen worden. We moeten ervoor proberen te zorgen dat de betekenis ervan voorbijgaat aan wat puur noodzakelijk is voor ons specifieke geval. Dat soort zaken maakt het ontwikkelen van software een stuk moeilijker. Dit niet doen is echter nog erger: de “technical debt” die ontstaat door teveel kortetermijn- en lokaal denken, zal dan op termijn alleen maar onbeheersbaarder worden.
En dat is dus de paradox: de afhankelijkheid tussen de systemen binnen een applicatie ecosysteem creëert enorme business waarde, maar maakt de IT een stuk lastiger (en duurder).
De “Mesh” Architectuur
Een goede architectuur kan echter soelaas brengen in dit verhaal, en consequent rekening houden met hergebruik kan uiteindelijk zelfs geld gaan besparen. Het gebruik van een Service Oriented Architecture (SOA) is daarbij één van onze belangrijkste wapens om de afhankelijkheden in ons ecosysteem de baas te kunnen, met de Microservices Architectuur als ultieme voorbeeld. Dit zijn echter slechts voorbeeld technische implementaties van het belangrijke concept Modulariteit (dat men in principe zelfs binnenin een monolithisch systeem kan implementeren). Wat proberen we hiermee te bereiken?
- Modules zijn zo onafhankelijk van elkaar als maar kan (maar maken toch van elkaar gebruik vanwege de waarde die dit heeft): ze zijn liefst “loosely coupled”: veranderingen in de werking of het ontwerp van één module hebben zo weinig mogelijk impact op de werking of het ontwerp van een andere. Dit laat toe om ze apart van elkaar te laten werken en ze te laten onderhouden door aparte teams, zonder dat er continu overleg of downtime moet zijn (in het geval van een monoliet verliest men wel dit downtime voordeel).
- Modules zijn voldoende klein. Men volgt hier de Unix filosofie “do one thing and do it well”. In de praktijk wil dit zeggen dat modules gericht zijn op het aanbieden van één bepaalde business capabiliteit, die in principe apart kan worden gedeployed. Hoe men precies de context van een service afbakent, is één van de belangrijkste onderdelen van de Domain Driven Design (DDD) ontwikkelingsmethode.
Het tweede punt is niet te onderschatten en één van de moeilijkste zaken, reeds bij de business en functionele analyse en ook verderop in het ontwerp van software. In deze blog richten we ons echter op de aspecten van een groter ecosysteem, en daarom zullen we ons hier beperken tot de eerste vraag:
Hoe houden we onze modules zo goed mogelijk onafhankelijk, terwijl we ze toch laten communiceren?
Een aantal helpende Principes
We gaan er vanaf hier van uit dat we onze modules verpakken in aparte services, en we zullen nu een aantal ontwerpprincipes overlopen die ons gaan helpen bij het uitbouwen van een ecosysteem architectuur waarin we een grote onafhankelijkheid, maar ook herbruikbaarheid, van onze services nastreven.

1. Het gebruik van APIs. Dit principe is reeds goed gekend en vormt een basissteen van SOA: Een service stelt zich open naar de buitenwereld toe via zijn API, en deze API is dan ook het enige waarvan andere services afhankelijk kunnen zijn. Op die manier beperkt men dus de afhankelijkheid die andere zaken m.b.t. een service zullen hebben, tot wat strikt noodzakelijk is. Men is hier echter wel nog semantisch en syntactisch afhankelijk van de APIs van andere services die men wenst te gebruiken, en ook technisch afhankelijk van het online zijn van die andere services.
2. Het gebruik van Events. Event Driven Architecture is ook al oud, maar maakt meer recent furore dankzij de Reactive beweging. In plaats van (of naast) communicatie via een API, kan men de communicatie tussen services ook via het versturen van events laten gebeuren. Daar hoort bij dat een service die een event verstuurt, niet op voorhand weet welke andere services dit event zullen ontvangen. Services hebben hier enkel controle over de events die ze zelf versturen en dewelke ze zelf wensen te ontvangen. Het is duidelijk dat hier de onafhankelijkheid nog sterker is dan in het geval van APIs: men is niet langer rechtstreeks afhankelijk van de interface, noch van het online zijn, van een andere service. Men is enkel nog technisch afhankelijk van het online zijn van de Event Bus (een middleware systeem dat men met grote redundantie kan opzetten), en semantisch afhankelijk van de definitie van de betrokken events (een niet te vermijden afhankelijkheid die wordt opgelegd door de business vereiste van het gebruik van de betreffende business capabiliteit die door het event mede wordt ondersteund).
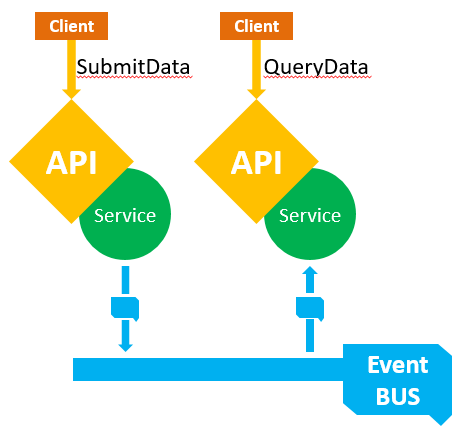
3. CQRS. Wanneer we microservices bouwen die zo klein en onafhankelijk mogelijk zijn, betekent dit eigenlijk dat we een onderscheid moeten beginnen maken tussen services die data binnenkrijgen en/of (deels) verwerken, en services die daarop verder bouwen om informatie te verschaffen en vragen te kunnen beantwoorden. Typisch zullen dit verschillende business capabilities zijn, en dus een aparte service vereisen. Bovendien maken we de microservices liefst zo klein, dat er vaak data van meerdere microservices afkomstig, nodig zal zijn om bepaalde queries te beantwoorden, waardoor het sowieso minder vanzelfsprekend wordt om de queries te implementeren als onderdeel van één van die microservices; ook daardoor wordt het dus logischer om ze in een aparte dienst te deployen. Dit principe noemen we Command Query Responsability Segregation (CQRS): we scheiden de ver-antwoordelijkheid voor het behandelen van commando’s (opnemen en verwerken van data) en die voor het beantwoorden van queries (teruggeven van, meestal verwerkte, data) in aparte services.
4. Sagas. Soms is het nodig dat in een applicatie zaken gebeuren die ofwel gezamenlijk slagen, ofwel gezamenlijk falen. Dit noemt men een transactie. Zoals reeds in een eerdere blog vermeld, is het nuttig om transacties binnen onze systemen te minimaliseren en goed na te denken op business niveau of ze echt wel nodig zijn. Desalniettemin zullen we ze toch niet geheel kunnen vermijden. Binnen één microservice is de implementatie hiervan doorgaans geen probleem: de onderliggende database zal dit ondersteunen volgens het tweefasig “commit” protocol (2 Phase Commit, 2PC). Wat we echter absoluut moeten vermijden, is om dit protocol toe te passen op meerdere services tegelijk in een gedistribueerde omgeving. Om dan toch tegemoet te komen aan de nood aan gedistribueerde transacties, kunnen we sagas gebruiken. Een saga bestaat uit een reeks lokale transacties (binnen één service), waarbij elke service een event zal publiceren om de volgende transactie binnen de saga te triggeren in de volgende service die eraan meedoet. Indien één van de lokale transacties faalt, dan zal het verstuurde event verschillen van wat het normaal is, en dan volgen compenserende transacties in de services die reeds aan beurt kwamen, om de eerdere veranderingen terug ongedaan te maken. Men kan sagas op 2 manieren implementeren: de eerste is een choreografie, waarbij de services zelf weten wat ze wanneer moeten doen (op basis van de events die ze binnenkrijgen). De tweede optie is de orchestratie, waarbij één service zal optreden als de organisator van het gebeuren en de transactie stap voor stap opvolgt. De communicatie met participerende services kan hier ook met events plaatsvinden, maar eventueel ook via rechtstreekse API calls om de opeenvolgende opdrachten te geven (de antwoorden komen dan wel best via events terug binnen in de orchestrator, anders zondigt men tegen CQRS). Een voorbeeld van een saga (met choreografie) is het verhaal van de webshop in de vorige blog over Event-Driven APIs.
Naast deze 4 principes zijn er nog een aantal secundaire ondersteunende zaken die we mogelijk kunnen doen binnen ons ecosysteem. Denk bijvoorbeeld aan het gebruik van Event Sourcing, of het inzetten van NewSQL databases om een microservice met toestand goed te kunnen schalen. Deze zaken bespraken we reeds voldoende in vorige blogposts.
Besluit: even Wennen
Een moderne architectuur voor een complex Applicatie Ecosysteem bestaat uit meer dan alleen maar APIs, en kan best stevig gebruik maken van de toegevoegde waarde die EDA en CQRS bieden. Wanneer men eerder traditionele architecturen gewend is, is de verhoogde complexiteit natuurlijk even wennen. De voordelen overwegen volgens ons echter op de nadelen van deze leercurve. Eens men deze zaken in de vingers heeft en een aantal keer heeft toegepast, zal men zowel op technisch vlak als op business vlak de pluspunten beginnen ondervinden.
Om het allemaal een beetje behapbaarder te maken, zullen we in een volgende blog trachten deze principes verder te illustreren aan de hand van een voorbeeld applicatie ecosysteem.
_________________________
Dit is een ingezonden bijdrage van Koen Vanderkimpen, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.
Leave a Reply