Cet article est aussi disponible en néerlandais.
Comme outil de génération de code pour les développeurs de logiciels, Github Copilot domine le marché aujourd’hui. Cette situation devrait perdurer, d’autant plus que l’outil s’est enrichi d’une fonctionnalité de messagerie instantanée à la ChatGPT. Propriété de Microsoft, Github bénéficie d’une ligne directe avec OpenAI, et est donc le premier à profiter du rôle de pionnier que cette société continue de jouer dans le développement de grands modèles de langage (abrégé LLM en anglais)
On en oublierait presque qu’il existe d’autres options. La première alternative à grande échelle construite sur une base open source, incluant des jeux de données d’apprentissage ouverts, est StarCoder, dont une version 2 a récemment vu le jour. Elle est développée dans le cadre de l’initiative BigCode de ServiceNow et de HuggingFace. L’article qui l’accompagne offre un aperçu fascinant de la construction d’un modèle de langage pour la génération de code. Peu après StarCoder, WizardCoder, CodeLLama, DeepSeekCoder et quelques autres sont apparus sur la scène, pas tous fondés sur un ensemble de données ouvertes, mais librement accessibles et réutilisables via HuggingFace.
Aujourd’hui, il existe aussi suffisamment d’outils pour faciliter l’exécution de ces modèles sur votre propre machine. Vous pouvez donc avoir votre propre assistant de codage personnel, hébergé par vous-même et entièrement privé. Pour cela, il vous faut un matériel suffisamment puissant, un LLM axé sur les tâches de code completion ou sur les conversations concernant le code, et une extension pour l’environnement de développement (IDE). Le LLM et l’extension de l’IDE communiquent entre eux via une API, qui peut être compatible ou non avec celle d’OpenAI, ce qui permet de passer facilement d’un modèle commercial (OpenAI) à un modèle open source le cas échéant.
Extensions pour IDE
L’installation d’une extension est simple en soi. Github Copilot existe depuis longtemps en tant qu’extension pour VSCode et aujourd’hui également pour IntelliJ IDEA – même si au moment de la rédaction de cet article, la version d’IntelliJ contient encore un peu moins de fonctionnalités.
Parmi les alternatives open source, Continue figure probablement parmi les meilleures à ce jour. Il en existe d’autres – Huggingface a développé llm-vscode par exemple – et il ne fait aucun doute que d’autres viendront s’ajouter. Tout comme Github Copilot, Continue existe également sous forme d’extension pour VSCode ou IntelliJ. L’outil peut utiliser à la fois des générateurs commerciaux basés sur le cloud (notamment GPT-4) et des solutions open source auto-hébergées, qui ne doivent pas nécessairement émuler l’API d’OpenAI et autorisent de nombreuses personnalisations.
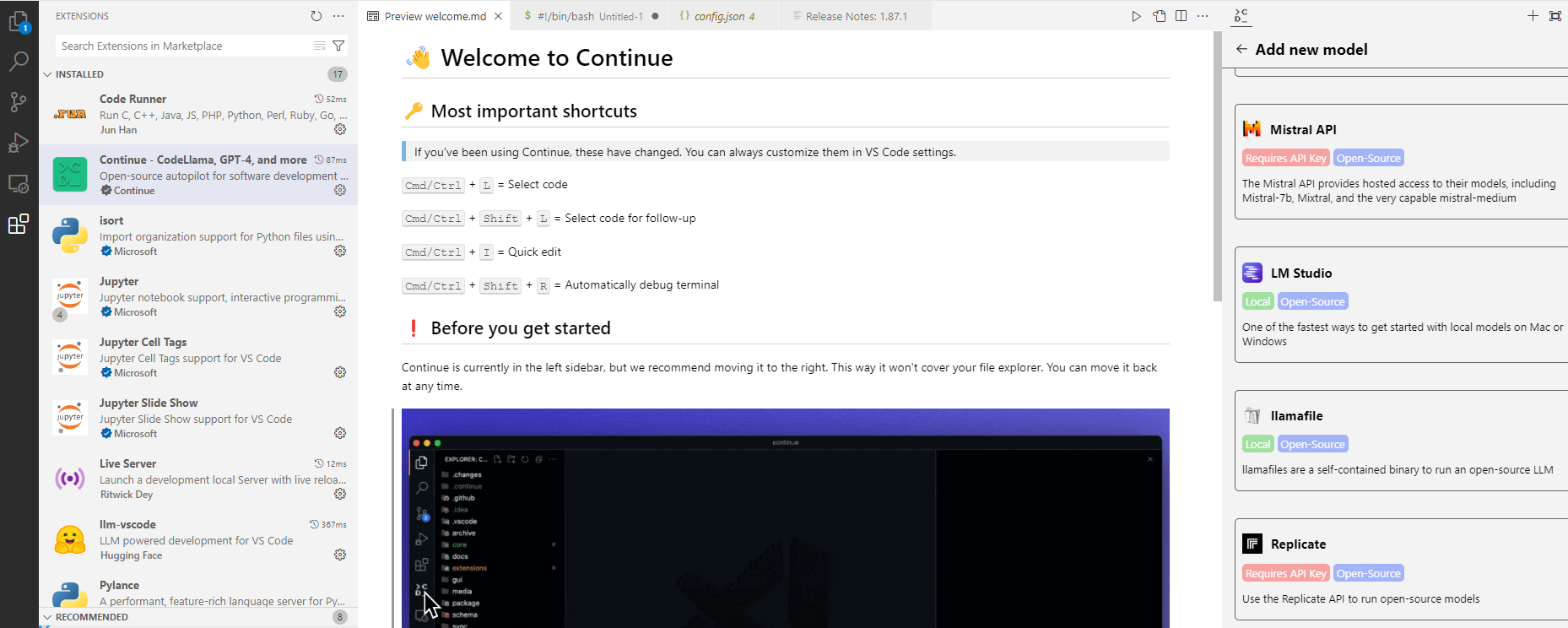
Il demeure important de prendre le temps de se familiariser avec l’extension. La documentation de Continue constitue une bonne base à cet effet. Pour chaque serveur et chaque LLM, il se peut que vous deviez définir différentes options de configuration et que vous souhaitiez apporter des modifications à l’invite de commande sous-jacente. Il convient également de savoir comment activer et désactiver l’extension dans l’IDE et de connaître les raccourcis et commandes disponibles. YouTube peut être un bon point de départ pour trouver des tutoriels et des exemples d’autres utilisateurs.
Un LLM sur votre ordinateur portable
Notamment sous l’impulsion du projet open source llama.cpp, des efforts considérables ont été faits au cours de l’année écoulée pour faire en sorte que les LLM puissent également être déployés sur du matériel informatique grand public. Un processeur graphique (GPU) au coût prohibitif n’est plus nécessaire, même s’il offre un gain de temps considérable. Globalement, llama.cpp permet de reconditionner un modèle au format GGUF (GPT-Generated Unified Format). Il s’agit ici d’appliquer un maximum d’optimisations :
- l’utilisation de jeux d’instructions du processeur (
- l’utilisation de bibliothèques hautement optimisées pour les calculs sous-jacents, telles que openBLAS ou Accelerate et Metal d’Apple ;
- la quantification du modèle, par la réduction de la précision des poids dans les couches des réseaux neuronaux. Les nombres (à virgule flottante) de 16 ou 32 bits du modèle original sont ici convertis en nombres entiers de 8 bits, voire de 6 bits ou même de 4 bits. Cela permet d’économiser de la mémoire et d’accélérer les calculs, au prix d’une perte de qualité relativement faible.
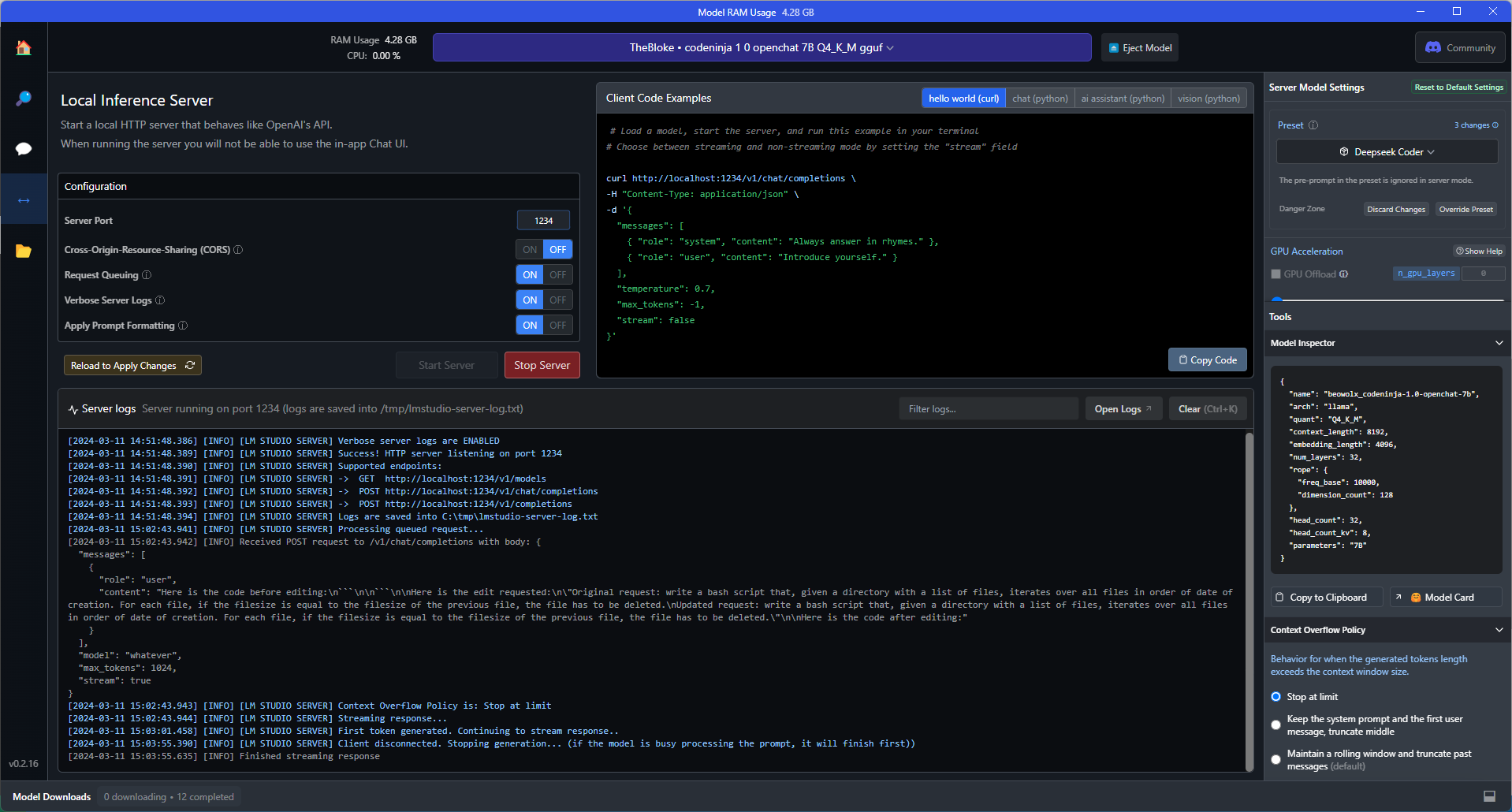
L’hébergement local d’un LLM peut être réalisé à l’aide d’outils tels que LM Studio. Ceux-ci vous permettent de télécharger différents modèles au format GGUF. Un onglet séparé dans l’application vous permet de démarrer un serveur d’inférence utilisant le protocole HTTP autour d’un modèle téléchargé et activé, qui simule l’API d’OpenAI. Une fois ce serveur mis en place, par exemple sur le port 1234, le modèle est accessible via un appel à http://localhost:1234/v1/chat/completions .
Cette configuration dans l’extension Continue se fait par l’ajout du LLM au fichier .continue/config.json, suivant ces instructions et selon les directives pour LM Studio en tant que fournisseur de modèle. Vous pouvez adapter le titre et le modèle comme bon vous semble, et il vous suffit d’ajouter la ligne "apiBase":"http://127.0.0.1:1234/v1" Dans l’extension, vous verrez alors apparaître une nouvelle option, et vous pourrez commencer à l’utiliser.
Interlude : à propos du matériel
La gestion des GPU n’est déjà pas une partie de plaisir pour un développeur sur une seule machine. Les problèmes d’incompatibilité entre les différentes versions de toutes sortes de bibliothèques logicielles et de pilotes de GPU peuvent prendre des jours à résoudre. L’offre du marché des GPUs pour data centers, dominée par le monopole de nVIDIA, reste d’un coût prohibitif. À cela s’ajoute le coût de l’acquisition des connaissances très spécialisées nécessaires au fonctionnement de ces systèmes. Le matériel que vous choisirez sera probablement complètement obsolète dans quelques années. Un nouveau matériel, conçu spécifiquement pour accélérer le type de calculs des modèles d’IA, fait l’objet d’un travail acharné. Google a déjà présenté le TPU, mais d’autres fabricants se concentrent aujourd’hui pleinement sur les NPU (Neural Processing Units), et certains osent entrer en concurrence directe avec nVIDIA.
Si vous n’avez pas le temps de vous occuper des pilotes de GPU et que vous n’avez pas l’ambition d’entraîner les modèles vous-même, la possibilité de les utiliser sur un CPU ordinaire est plus que bienvenue. Bien sûr, vous êtes alors limité aux LLM ou aux modèles d’IA dont la taille le permet. Les LLM “domestiques” typiques ont 3, 7 ou 13 milliards de paramètres ; les modèles plus grands sont agressivement quantifiés pour économiser de l’espace sur le disque et la mémoire. Ils ne seront pas en mesure d’égaler la qualité de GPT-4 aujourd’hui, mais heureusement, des classements existent pour aider à opérer un choix – pour les LLM ouverts en général, spécifiquement avec des benchmarks de vitesse (débit), ou pour les LLM générateurs de code en particulier.
Plus les LLM sont grands, plus la qualité du résultat est élevée (en général), mais plus la mémoire et la puissance de traitement requises sont importantes. Un LLM doit de préférence pouvoir être entièrement chargé dans la mémoire, de sorte que 16 GB de RAM n’est pas un luxe – plus c’est encore mieux, surtout si vous voulez faire fonctionner un IDE sur la même machine. Pour fournir une réponse, le modèle complet doit souvent être exécuté plusieurs fois. Par conséquent, le goulot d’étranglement est souvent la bande passante entre le CPU et la RAM. Les CPU dotés d’une grande mémoire cache interne semblent avoir une longueur d’avance (voir également les benchmarks spécifiques à l’IA [1,2] d’Anandtech). Lors du choix du reste du matériel, la bande passante de la mémoire devrait certainement entrer en ligne de compte. Même ceux choisissant un GPU pourraient préférer considérer cette bande passante plutôt que le nombre de cœurs du GPU. Enfin, dans les environnements virtualisés (VM, VPS), il est important que le CPU virtuel prenne en charge les mêmes jeux d’instructions avancés, tels que AVX-512.
Un LLM sur votre serveur
Si vous disposez d’une machine plus puissante, il peut être intéressant d’y exécuter le LLM. ollama est probablement l’outil le plus populaire pour héberger des modèles sur Mac ou Linux sans trop de difficultés, et depuis peu également sur Windows. LocalAI est toutefois une option tout aussi intéressante dans la liste des fournisseurs de LLM pour Continue, car il propose des conteneurs Docker, avec ou sans support GPU. Sur une machine Linux équipée de Docker, un one-liner dans le terminal suffit pour télécharger le modèle CodeLlama open source et l’héberger sur le port 1234 :
docker run -ti -p 1234:8080 localai/localai:v2.7.0-ffmpeg-core codellama-7b-gguf Cependant, son démarrage prend un certain temps, car le modèle est téléchargé dans le conteneur. Il est plus intéressant de stocker soi-même une série de modèles dans un répertoire local et d’y associer une API à l’aide d’un conteneur LocalAI. Des instructions relativement simples sont disponibles pour cela aussi. Nous pouvons par exemple les appliquer au LLM LLM DeepSeek de 6,7 milliards de paramètres, quantifiés à 4 bits. Il peut être téléchargé directement depuis Huggingface dans le répertoire local ./models-gguf à l’aide d’une commande wget du type :
wget https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/resolve/main/deepseek-coder-6.7b-instruct.Q4_K_M.gguf -O ./models-gguf/deepseek-6.7b-instruct-Q4Démarrer une API autour des modèles de ce répertoire sur le port 8001 (vous pouvez aussi placer plusieurs modèles dans le même répertoire et les héberger simultanément), peut alors se faire avec la commande suivante . Ajoutez éventuellement -d pour qu’elle s’exécute en arrière-plan, et n’hésitez pas à expérimenter les paramètres context-size et threads en fonction de la puissance de votre serveur :
docker run -p 8001:8080 -v $PWD/models-gguf:/models -ti --rm quay.io/go-skynet/local-ai:v2.7.0-ffmpeg-core --models-path /models --context-size 1600 --threads 16Exemple
Nous pouvons maintenant comparer différents LLM pour le code. Nous nous en tiendrons ici à l’anecdote et prendrons l’écriture d’un script shell bash comme exemple simple. Nous partons du problème suivant : une routine de sauvegarde a effectué des sauvegardes nocturnes d’un système pendant des années. Pour libérer de l’espace disque, nous voulons supprimer toutes les sauvegardes qui ne diffèrent pas des précédentes. Nous lançons la commande suivante, en décrivant la tâche le plus précisément possible afin d’obtenir les meilleurs résultats : “Write a bash script that, given a directory, iterates over all its files in order of date of creation. For each file, if the filesize is equal to the filesize of the previous file, the file has to be deleted.”
Le fichier .continue/config.json de notre extension Continue contient la liste suivante de modèles : un sur le propre ordinateur portable dans LM Studio chargé sur le port 1234, et deux sur un serveur séparé, mais sur le même réseau local, hébergé par LocalAI sur le port 8001.
{
"title": "myLaptop-LMStudio",
"model": "whatever is loaded in LMstudio",
"apiBase": "http://127.0.0.1:1234/v1",
"completionOptions": {},
"provider": "lmstudio"
},
{
"title": "localAI-mistral",
"model": "mistral-7b-code16kqlora-Q4",
"apiBase": "https://192.168.0.100:8001/v1",
"apiKey": "",
"completionOptions": {},
"provider": "openai"
},
{
"title": "localAI-deepseek",
"model": "deepseek-6.7b-instruct-Q4",
"apiBase": "https://192.168.0.100:8001/v1",
"apiKey": "",
"completionOptions": {},
"provider": "openai"
},Comme référence, nous prenons ChatGPT, qui propose la solution (correcte) suivante.
En outre, elle est également suivie d’une explication détaillée de la signification des différentes parties (non présentée ici) :
#!/bin/bash
# Directory containing the files
DIR="/path/to/your/directory"
# Variable to hold the size of the previous file. Initialized to 0.
prev_size=0
# List all files in the directory, sorted by creation date
# Note: '%T@' sorts by creation time, '%p' prints the file's name
# 'sort -n' ensures the list is sorted numerically
# Note that creation time sorting may depend on filesystem and OS support
files=$(find "$DIR" -type f -printf "%T@ %p\n" | sort -n | cut -d ' ' -f 2-)
# Iterate over the sorted list of files
for file in $files; do
# Get current file size
current_size=$(stat -c %s "$file")
# Check if current file size is equal to the previous file's size
if [ "$current_size" -eq "$prev_size" ]; then
# Sizes are equal, delete the current file
echo "Deleting file: $file"
rm "$file"
fi
# Update previous size to current file's size
prev_size=$current_size
doneDans LMStudio, nous chargeons le modèle “CodeNinja 1.0 openchat 7B Q4_K_M“. Il faut plus d’une minute pour générer la réponse à la même question : 20 secondes d’attente pour l’apparition de la première lettre de la réponse, puis environ 2 secondes par ligne (bien sûr, notre ordinateur portable n’est pas très puissant : un CPU Core i7-10610U avec 32GB de RAM). Le résultat se présente comme suit :
#!/bin/bash
for f in $(ls -t -l --time-style=full /path/to/directory)
do
if [[ $f == "total"* ]]; then
continue;
fi
filename=$(basename "${f% *}")
# Checks whether the file is already deleted. If not, compares it with the previous file:
prev_file=""
while IFS= read -r line; do
if [[ $line == $filename ]]; then
prev_file=$line
break;
fi
done <<<"$(ls -l /path/to/directory | tail -n 2)"
if [[ -z $prev_file || "$f" = "${prev_file}" ]]; then
# If the file is deleted, nothing to do. If not, deletes it:
if [[ -z $prev_file ]] || [[ "$(stat -c %s ${filename})" == "$(stat -c %s ${prev_file})" ]]; then
rm /path/to/directory/$filename
fi
fi
doneNous chargeons le modèle DeepSeek de 6,7 milliards de paramètres dans LocalAI sur une VM Debian dans Proxmox. La VM se voit allouer beaucoup de mémoire vive et 12 cœurs du micro-processeur AMD Threadripper 3960X sous-jacent (24 cœurs au total mais pas de support AVX-512). Nous créons ainsi à un rythme d’environ 3 lignes par seconde le résultat suivant :
#!/bin/bash
# Check if directory is provided
if [ $# -ne 1 ]; then
echo "Usage: $0 directory"
exit 1
fi
# Check if directory exists
if [ ! -d "$1" ]; then
echo "Directory $1 does not exist"
exit 1
fi
# Change to the directory
cd "$1"
# Get the list of files in order of creation date
files=$(ls -t)
# Initialize previous_size to 0
previous_size=0
# Iterate over the files
for file in $files; do
# Get the size of the file
size=$(stat -c%s "$file")
# If the size is equal to the previous size, delete the file
if [ $size -eq $previous_size ]; then
rm "$file"
echo "Deleted $file"
fi
# Update previous_size
previous_size=$size
doneEnfin, sur la même VM, nous pouvons également essayer Mistral, pour lequel nous choisissons au hasard la version mistral-7B-code-16K-qlora qui a été légèrement adaptée par fine-tuning pour le code par un internaute. Il s’avère que sa réponse est rapide, générant le résultat compact suivant en quelque 2 secondes (malheureusement sans documentation, et en proposant la commande complexe awk ) :
for file in $(find directory -type f -exec du -sh {} + | sort -h | awk '{print NR ":\t" $1}'); do
size=$(du -sh "$file" | awk '{print $1}')
if [[ $size == $previous_size ]]; then
rm "$file"
fi
previous_size=$size
doneJe laisse volontiers au lecteur le soin de procéder à une comparaison plus approfondie de ces résultats. Si nous devons tirer une dernière leçon de cette expérience, c’est que même si les modèles ont le même nombre de paramètres et sont entraînés dans le même but, il peut y avoir de très grandes différences de résultat et de style entre eux !
Conclusion
À la vitesse de l’éclair, toutes sortes de fonctions alimentées par l’IA trouvent leur place dans l’IDE. Les dernières notes de mises à jour de Visual Studio Code mentionnent, par exemple, la prise en charge de la reconnaissance vocale dans plusieurs langues, en plus de plusieurs fonctionnalités de CoPilot. En tant que développeur, il est inévitable que vous soyez confronté à cette situation. Les développeurs qui travaillent avec des données sensibles ou du code protégé par des droits d’auteur doivent se méfier à juste titre de ces outils qui envoient le contenu de leur IDE à un service cloud tiers pour proposer des suggestions.
Grâce notamment au projet llama.cpp, une voie alternative open source a récemment vu le jour, qui permet de mettre en place et d’exploiter soi-même une telle assistance au codage avec des LLM. Les modèles plus petits qui peuvent fonctionner sur du matériel grand public n’offrent actuellement pas la même qualité et la même vitesse que Github CoPilot ou ChatGPT. Toutefois, de nouvelles améliorations apparaîtront régulièrement au cours des prochaines années, de sorte que la voie à suivre semble prometteuse à tous points de vue.
______________________
Ce post est une contribution individuelle de Joachim Ganseman, spécialisée en intelligence artificielle chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.
Leave a Reply