In een vorige blogpost hebben we een aantal technieken beschreven voor het verbeteren van de kwaliteit van de antwoorden in een generatief vraag-antwoordsysteem.
Ter herinnering, RAG (Retrieval Augmented Generation) is de aangewezen architectuur om hallucinaties te vermijden door taalmodellen van context te voorzien. Vooraleer het taalmodel een antwoord genereert, wordt eerst de meest relevante informatie voor de vraag opgezocht (retrieval). Die informatie wordt dan als context meegegeven aan het taalmodel met als opdracht om een antwoord te genereren op basis van die meegeleverde context (generation). Zowel bij de retrieval-stap als bij de generatie-stap kunnen er fouten optreden. Daarom is het nodig om de vinger aan de pols te houden om de kwaliteit te bewaken.
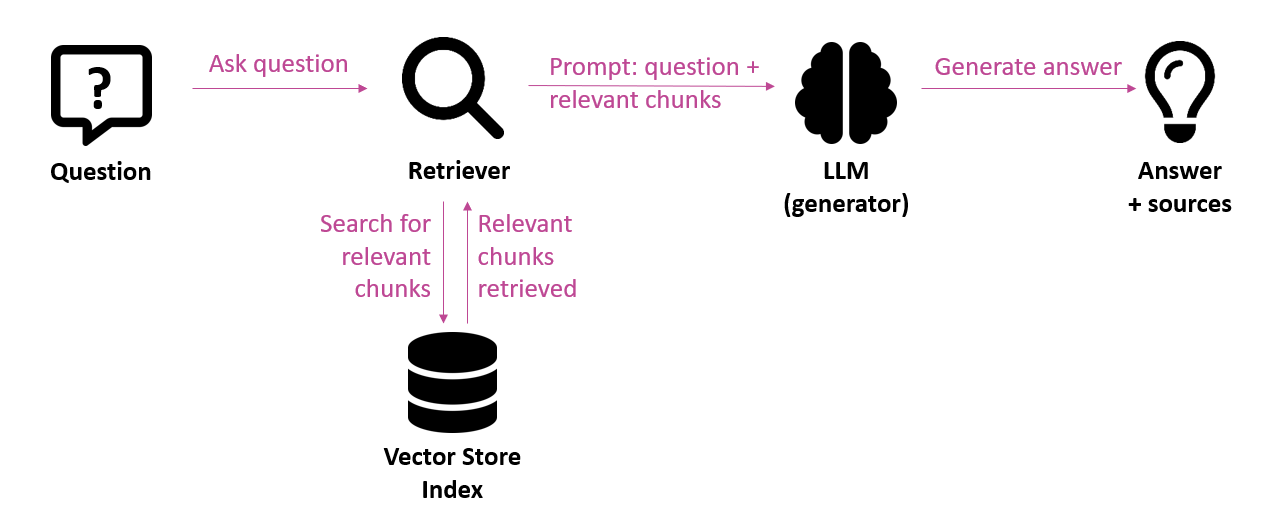
In dit artikel bespreken we het belang van het meten van de kwaliteit van een RAG systeem, de uitdagingen die zich stellen, de metrieken die we kunnen toepassen en de tools en frameworks die ons daarbij kunnen ondersteunen.
Het belang van evalueren
Vooraleer we aangeven hoé we een generatief vraag-antwoordsysteem kunnen evalueren, staan we toch even stil bij het waarom.
Een generatief vraag-antwoordsysteem is inherent onderhevig aan fouten (hallucinaties, onnauwkeurigheden). Het is daarom belangrijk om de kwaliteit te kennen van de output om pijnpunten bloot te leggen en de kwaliteit gericht te kunnen verbeteren.
Evaluaties laten toe om een benchmark op te stellen van een eerste versie van het vraag-antwoordsysteem. De kwaliteit van nieuwere versies van het systeem kan dan vergeleken worden met deze baseline of vorige versies. Zo kan de impact van veranderingen gemeten worden, zoals het verbeteren van de retrieval component, het inzetten van een ander taalmodel of een aanpassing van de prompt.
Evaluaties kunnen helpen bij het nemen van de beslissing om het systeem al dan niet in productie te nemen. Ze kunnen het vertrouwen in het systeem vergroten door aan te tonen dat het nauwkeurig en betrouwbaar is.
De uitdagingen bij evalueren
Metrieken – In tegenstelling tot traditionele software, is de output van LLM-gebaseerde toepassingen niet deterministisch: een specifieke input kan leiden tot meerdere correcte (of foutieve) outputs. De output kan subjectief zijn. Daarom kunnen we als evaluatiecriterium niet eenvoudig “juist of fout” gebruiken en moeten we onze toevlucht nemen tot andere criteria. Vergelijk het met het evalueren van een opstel (niet deterministisch) versus het evalueren van antwoorden op meerkeuzevragen (wel deterministisch).
Schaalbaarheid – Om snel een eerste indruk te krijgen van de kwaliteit van een generatief vraag-antwoordsysteem kan je manueel enkele testen uitvoeren, bijvoorbeeld een 20-tal vragen stellen en de kwaliteit van de gegenereerde antwoorden manueel evalueren. Maar dit is moeilijk vol te houden als je op grotere schaal wil evalueren, bij een grotere testset of bij het evalueren van alle antwoorden als het systeem in productie draait. In dat geval loont het de moeite om automatische evaluaties uit te voeren. Daarbij wordt een taalmodel ingezet om een bepaald aspect te beoordelen. Er wordt gesproken van “LLM-as-judge”.
Kwaliteit – Het gebruik van taalmodellen voor het evalueren van de output van … taalmodellen is enigszins verrassend. Dergelijke automatische evaluaties kunnen op zich ook fouten bevatten; we moeten waakzaam zijn over de kwaliteit ervan.
Kostenefficiëntie –Het uitvoeren van automatische evaluaties op basis van taalmodellen brengt kosten met zich mee voor het gebruik van die LLM’s die typisch als API service in de cloud aangeboden worden. Als we niet opletten kan de kost voor die evaluaties fors oplopen en de kost van het afhandelen van de vragen van eindgebruikers zelfs overstijgen.
Vertrouwelijkheid – Bij het uitvoeren van evaluaties op basis van LLM’s kan vertrouwelijke informatie blootgesteld worden aan de leveranciers van cloudgebaseerde LLM diensten.
Granulariteit – Je wil niet alleen weten hoe nauwkeurig het gegenereerde antwoord is, maar je wil ook de oorzaak achterhalen van eventuele fouten of onnauwkeurigheden. Daarvoor is het nodig om gedetailleerde log traces bij te houden.
Het interpreteren van wat nu precies gemeten werd met een bepaalde metriek is uiteraard belangrijk. Hierna trachten we de meestgebruikte metrieken duidelijk toe te lichten.
Evaluatiemetrieken
Alhoewel er nog geen standaardisatie is van metrieken, duiken er toch initiatieven op die een belangrijk houvast kunnen bieden. Zo beschrijft de RAG triad van TruEra 3 metrieken die verband houden met de vraag van de eindgebruiker (query), de context opgehaald door het retrieval systeem (context) en het antwoord dat uiteindelijk gegenereerd wordt door het taalmodel (response).
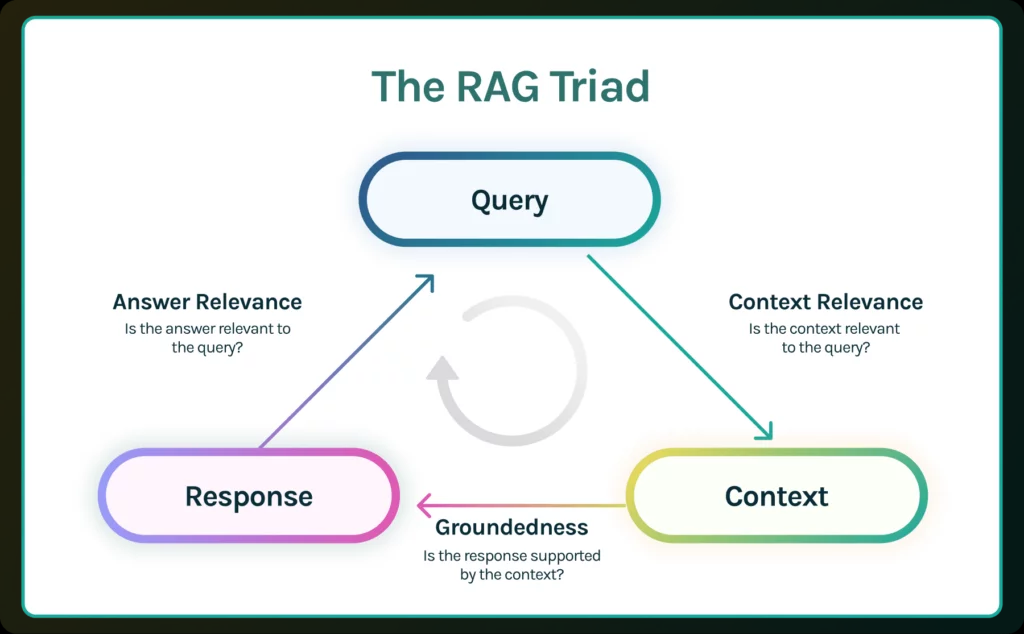
- Context relevance geeft aan hoe relevant de context is voor de gestelde vraag. De context die opgehaald wordt in de retrieval stap is gebaseerd op een semantische zoekopdracht (similarity search), wat niet noodzakelijk betekent dat die context relevant is voor de gestelde vraag. Deze metriek helpt om eventuele problemen te identificeren in de retrieval stap.
- Groundedness geeft aan in hoeverre het antwoord ondersteund wordt door de context. Zelfs indien alle relevante context aangeleverd wordt aan het taalmodel, kan het taalmodel nog altijd een (deel van het) antwoord verzinnen. Deze metriek checkt of (de verschillende delen van) het antwoord teruggeleid kunnen worden tot statements in de context. Met andere woorden: is er voor het antwoord bewijs terug te vinden in de aangeleverde context? Indien de groundedness score niet hoog genoeg is kan ervoor gekozen worden om het gegenereerde antwoord niet door te geven aan de gebruiker, maar eerder aan te geven dat er niet genoeg informatie beschikbaar is om de vraag te beantwoorden.
- Answer relevance geeft aan in hoeverre het antwoord effectief een antwoord is op de gestelde vraag. Het antwoord kan feitelijk correct zijn en ondersteund zijn door de context, maar toch geen antwoord zijn op de gestelde vraag. Deze metriek houdt geen rekening met de feitelijke correctheid van het antwoord, maar straft wel onvolledige of redundante antwoorden af.
Naast deze 3 metrieken kan het antwoord ook vergeleken worden met een referentie-antwoord (ground truth, of expert-antwoord dat als correct beschouwd wordt), zoals deze metrieken uit het Ragas framework:
- Answer semantic similarity geeft een beoordeling van de semantische overeenkomst tussen het gegenereerde antwoord en het referentie-antwoord.
- Answer correctness: dit is een combinatie van semantic similarity en factual similarity. Het idee van factual similarity is om te meten in hoeverre de beweringen in het gegenereerde antwoord overeenkomen met die in het referentie-antwoord.
Verder zijn er ook metrieken om de chunking strategie te evalueren, zoals deze van Galileo:
- Chunk attribution geeft aan hoeveel chunks en welke chunks gebruikt werden voor het genereren van het antwoord. Teveel chunks ophalen die niet bijdragen tot het antwoord verlaagt de kwaliteit van het systeem en leidt tot hogere kosten omdat er onnodig veel tokens naar het taalmodel worden gestuurd.
- Chunk utilization meet voor een bepaalde chunk hoeveel ervan effectief gebruikt werd voor het genereren van het antwoord. Een lage score betekent dat een groot deel van de chunk niet relevant is voor het beantwoorden van de vraag. Een bijsturing van de grootte van de chunks kan het systeem optimaliseren.
Deze beide metrieken kunnen gebruikt worden om de chunking strategie te optimaliseren. Optimale waarden voor deze metrieken betekent dat er minder irrelevante informatie aangeleverd wordt aan het taalmodel, wat de kosten beperkt en het model helpt om de focus te behouden.
Bij alle bovenvermelde metrieken ligt de focus op de kwaliteit van de antwoorden of zaken die daartoe bijdragen. Daarnaast kunnen ook metrieken geëvalueerd worden om na te gaan of de antwoorden schadelijk zijn (schadelijke of ongepaste inhoud, jailbreaks, etc), of de juiste vorm hebben (coherent, beknopt, de juiste toon, etc). Ook non-functionals kunnen meegenomen worden zoals latency en kost.
Tot slot is het belangrijk om te vermelden dat LLM-gebaseerde metrieken niet met behulp van wiskundige formules gedefinieerd zijn. Fouten zijn mogelijk en het meetresultaat moet gezien worden als een approximatieve indicatie. Daarom blijft een evaluatie door business experten onmisbaar.
Men spreekt in deze context over alignment: ervoor zorgen dat de generatieve AI toepassing antwoordt volgens de verwachtingen van de business.
Wanneer evalueren?
Evaluaties kunnen in principe uitgevoerd worden bij elke fase van de levenscyclus van een toepassing: bij elke bugfix of feature update, bij elke deployment, en eens de toepassing operationeel is.
Er zijn mogelijkheden om automatische evaluaties te integreren in de CI pipeline, bijvoorbeeld pre-commit of pre-release. Tools als CircleCI zetten in op dergelijke ondersteuning.
Om de verandering van de kwaliteit te kunnen meten over verschillende iteraties van het systeem heen is het belangrijk om een vaste testset op te stellen met een aantal vragen en overeenkomstige referentie-antwoorden. De vragen zijn best zo representatief mogelijk voor het soort vragen die effectief zullen gesteld worden door eindgebruikers.
De metrieken die gebruikt worden om het systeem te verbeteren vóór de inproductiestelling kunnen ook gebruikt worden tijdens de productiefase om na te gaan of échte vragen van eindgebruikers nauwkeurig genoeg beantwoord worden. Zoals eerder vermeld moet hier zeker de kost in overweging genomen worden voor het gebruik van taalmodellen als evaluator zodat de kosten niet ontsporen.
Tools en frameworks
Zonder exhaustief te willen zijn, zijn hieronder enkele tools en frameworks aangegeven die het uitvoeren van evaluaties sterk kunnen ondersteunen:
- Galileo is een platform voor het evalueren en monitoren van generatieve AI toepassingen. Het biedt specifieke metrieken voor het optimaliseren van de chunking strategie (chunk attribution en chunk utilization, zie hierboven). Er is ook de mogelijkheid om in realtime guardrails toe te passen: het antwoord kan bijgestuurd worden, bijvoorbeeld in het geval van hallucinaties of schadelijk content. De resultaten van de evaluaties zijn visueel te inspecteren in een console die standaard cloudgebaseerd is, maar ook op eigen infrastructuur kan gehost worden. Om de kost van evaluaties te drukken en gegevens vertrouwelijk te houden werkt Galileo tenslotte aan een oplossing op basis van lichtere modellen die lokaal kunnen draaien.
- Ragas is een open source framework voor het evalueren van RAG-gebaseerde toepassingen. Het biedt een uitgebreide set aan metrieken die het gehele systeem evalueren. Zo zijn er ook metrieken die het gegenereerde antwoord vergelijken met een referentie-antwoord (answer semantic similarity en answer correctness).
- TruLens is een open source community project onder de vleugels van TruEra. TruEra bedacht de term “RAG triad” die 3 metrieken combineert voor het evalueren van hallucinaties in LLM-gebaseerde toepassingen.
Conclusie
Frameworks voor het evalueren van RAG toepassingen laten toe om de kwaliteit van generatieve vraag-antwoordsystemen systematisch te beoordelen en op te volgen. Ze voorzien een manier om verschillende aspecten te meten, zoals het vermogen om relevante informatie op te halen (retrieval) en de kwaliteit van de gegenereerde antwoorden. Dergelijke metrieken zijn cruciaal om inzicht te krijgen in de eventuele zwakke punten van een RAG systeem en waar nodig te kunnen bijsturen.
Het gebruik van een LLM kan het uitvoeren van evaluaties automatiseren en het uitvoeren van testen schaalbaar maken. Het is wel opletten met de kosten die dit teweeg kan brengen. Een taalmodel als evaluator is bovendien niet vrij van fouten, maar ze kunnen voldoende inzicht bieden in de mogelijke verbeterpunten van een generatief vraag-antwoordsysteem. De meetresultaten moeten echter gezien worden als een approximatieve indicatie, we kunnen er niet blind op vertrouwen. Daarom blijft een evaluatie door business experten onmisbaar.
Dit is een ingezonden bijdrage van Bert Vanhalst, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.