In dit artikel illustreren we de problematiek waarop Master Data Management (MDM) een antwoord biedt. Vervolgens definiëren we deze tak van de informatica aan de hand van voorbeelden en tonen we de verbanden met data governance en datamanagement. We stellen ook een implementatiemethode voor, evenals de bijbehorende architecturen met hun voor- en nadelen.
De probleemstelling
Master Data Management heeft als doel twee soorten problemen op te lossen.
Enerzijds kunnen bepaalde gegevens verspreid, gedupliceerd en heterogeen zijn in verschillende semantisch met elkaar verbonden toepassingen en databases (DB’s).
Anderzijds kunnen gegevens tussen verschillende DB’s verschillen (bijvoorbeeld wat betreft het formaat of het definitiedomain) of in een verschillend tempo evolueren. Dit kan leiden tot ernstige bedrijfsproblemen. Zo vormen een gebrek aan traceerbaarheid tussen onderling afhankelijke databases of een gebrek aan “AI-ready” gegevens, een belemmering voor de efficiënte implementatie van AI-projecten, die momenteel in opkomst zijn.
Master Data Management is dus een vakgebied dat zich richt op het elimineren van inconsistenties en operationele storingen en het verbeteren van de kwaliteit van de gegevens en de dienstverlening.
Definitie en voorbeelden
Master Data Management is meer een vakgebied dan een softwareprogramma en is gebaseerd op data governance en datamanagement.
Bij data governance legt het management van een instelling verschillende zaken vast. Een verantwoordingskader op hoog niveau moet de voorwaarden voor het beheer van masterdata vastleggen (“policy settings”). Deze masterdata zijn van fundamenteel belang voor het bedrijf (bijvoorbeeld het adres van de werkgever of het bedrijf) en worden gedeeld tussen verschillende databases. Daartoe moeten rollen worden vastgesteld op verschillende niveaus: business- en technisch beheer van MDM, van het meta-informatiesysteem, van de datakwaliteit, van de architectuur, enz. Ten slotte wordt een passende organisatie opgezet voor de evaluatie, creatie, consumptie en controle van de data.
Op basis van de policy settings maakt datamanagement het mogelijk om op iteratieve en incrementele wijze masterdata te identificeren, definiëren en modelleren via een eerste case study die door de betrokken business wordt gevalideerd, met het oog op een bredere aanpak die drie gelijktijdige assen omvat.
In de eerste plaats moet een meta-informatiesysteem of transversale woordenlijst (“glossarium”) met data met een hoge toegevoegde waarde (“Data Catalog”) worden opgezet, een onderwerp waarover we in maart 2025 een blogartikel in het Frans en het Nederlands hebben gepubliceerd (6). De Data Catalog kan ook data beheren die niet tussen databases wordt gedeeld en waarvan de documentatie belangrijk is.
Ten tweede moet een aanpak worden geïmplementeerd die gericht is op de kwaliteit van de data (6, 7, 8, 9, 10, 11). Deze omvat twee soorten methoden. Correctieve methoden (9), via datakwaliteitsinstrumenten (Batch en Rest API in de ReUse-catalogus), maken het mogelijk om problemen (afwijkingen, vermoedelijke dubbele vermeldingen, te verwijderen adressen, enz.) aan te pakken wanneer deze zich al in de databases voordoen. Preventieve methoden (7, 8, 11) maken het mogelijk om het ontstaan van afwijkingen te voorkomen door de oorzaak (of oorzaken) ervan op te sporen tussen instellingen en verzenders in de informatiestromen (bijvoorbeeld problemen met de interpretatie van de wet, het ontstaan van een nieuw concept (virusmutaties, …), inconsistente definities, bugs, …) en deze structureel aan de bron te verwijderen, zodat ze niet meer/niet in de data voorkomen (in de toekomst, zie ReUse-catalogus).
Onderstaande figuur illustreert op schematische wijze de twee methoden, die op elkaar kunnen inwerken.
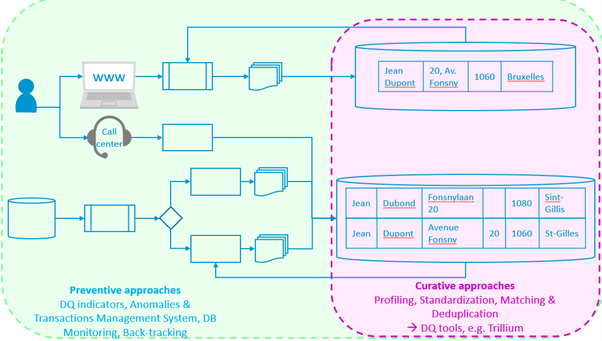
Ten derde zorgt een Master Datamanagement-systeem voor de keuze van een integratie tussen de betreffende databases en de datacatalogus (of meta-informatiesysteem). Er bestaan verschillende architecturen, die we later zullen bespreken.
Deze belangrijke stappen maken het mogelijk om gesynchroniseerde gegevens in verschillende projecten en toepassingen transversaal te beheren. Het doel van de MDM-aanpak is om inspanningen te bundelen en de synchronisatie, kwaliteit, uitwisseling en controle van data tussen de verschillende silo’s te waarborgen. En dit vrijwel in realtime of in uitgestelde modus (wanneer een goedkeuringsworkflow nodig is voor de validatie van wijzigingen en versies).
Bijvoorbeeld (2, 5): MDM maakt het mogelijk om gevallen te behandelen waarin twee verschillende termen in dezelfde betekenis worden gebruikt en moeten worden geharmoniseerd (bv. te betalen bedrag, verschuldigd bedrag) of gevallen waarin eenzelfde term verschillende betekenissen kan hebben (zo kan loon bijvoorbeeld brutoloon, basisloon, loon en salaris, of nettoloon betekenen, enz.). In onze Belgische context moet ook rekening worden gehouden met de harmonisatie tussen de termen in de verschillende gebruikte talen, wat een extra factor van complexiteit is. Er is namelijk geen noodzakelijk één-op-één verband tussen de verschillende termen in de verschillende landstalen voor een bepaald concept.
Masterdata zijn dus de kleinste samenhangende sets van identifiers en attributen die op unieke wijze de belangrijkste entiteiten van een instelling of onderneming beschrijven en worden gebruikt in verschillende conceptueel en functioneel met elkaar verbonden databases en businessprocessen.
Masterdatamanagement: implementatiemethode
Aangezien een Master Datamanagement-project in de eerste plaats een businessproject is, omvat het, voordat een IT-systeem wordt geïmplementeerd, de volgende, vaak iteratieve stappen (1, 3, 4):
- Bepaal de omvang van het project (begin met een “bescheiden” essentieel project, dat incrementeel en iteratief kan zijn, “nice to have”)
- Een agenda (planning) voor de implementatie opstellen, een continu project (ontwerp en onderhoud) ondersteund door de hiërarchie, met inbegrip van de volgende punten:
- Accent leggen (analyse) en identificeren:
- De gebruikers van de data, hun doelstellingen
- De authentieke bronnen
- De belangrijkste concepten en de masterdata (unieke identificatie, hoofdcategorieën, …). Let op: soms zijn compromissen nodig, de keuze van de masterdata is niet noodzakelijkerwijs deterministisch
- Gebeurtenissen/processen die van invloed kunnen zijn op de masterdata (bijwerking, delen en verwijderen als gevolg van wetgevende wijzigingen of de werkelijke situatie – bijvoorbeeld: mutaties van virussen en veranderingen in medische concepten, enz.)
- De bijbehorende organisatie (bijv. validatieworkflow)
- Het beheer van versies van masterdata en metadata (6)
- De kwaliteit van de data: evaluatie en verbetering (6, 7, 8, 9, 10, 11) – zie hierboven
- Beveiliging en privacy
- Definieer KPI’s of metrics om de resultaten van de MDM-aanpak te valideren, meten en opvolgen, bijvoorbeeld:
- Kwaliteitsbarometers DmfA: opvolging van anomalieën, financiële indicatoren (AR-KB 2017), … (11)
- Metingen van de traceerbaarheid tussen semantisch gekoppelde databases.
- Zoals hierboven vermeld, stapsgewijs een referentiekader of glossarium van data of een meta-informatiesysteem (6) opstellen, rekening houdend met de belangrijke functionaliteiten voor een latere productie:
- Versiebeheer (planning) van masterdata en metadata (evoluerende wetgeving, verjaringstermijn, bewijskracht, opkomst van nieuwe concepten, …)
- Validatieworkflow
- Meertaligheid
- Erfenis
- Standaard en uitwisselingsformaat (“Write Once Publish Many”)
- Multibase en meertalig zoeken
- Een strategie voor evolutie en change management opstellen voor de overgang van de huidige situatie (“AS IS”) naar de toekomstige situatie (“TO BE”)
- Rollen en business- en IT-teams (MDM, Data Quality, Architectuur, …) opstellen
- Standaarden definiëren (aanbevolen voor analyse: (12))
- Een methode bepalen voor de integratie van de betrokken databases; via het referentiekader of glossarium voor transversale data, dat we in het volgende punt zullen bekijken: de integratiearchitecturen, met hun voor- en nadelen op het vlak van:
- datakwaliteit (10)
- beveiliging en privacy
- prestaties
- mate van intrusiviteit in de betrokken informatiesystemen
Integratiearchitecturen tussen databases en eventueel gekoppelde Data Catalogs, met hun voor- en nadelen
De volgende schema’s zijn aangepast uit (5) en gewijzigd in overeenstemming met de huidige oplossingen (1, 2, 3, 4)
- Virtuele directories
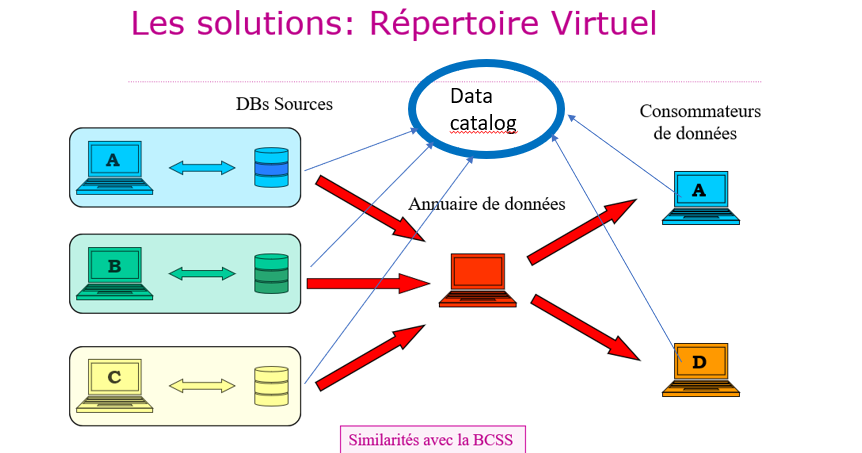
Met een virtuele directory maakt het dataregister (in het midden van het schema, in het rood) het mogelijk om, op basis van een kennisbank met toegangsrechten, data uit de brondatabases over te dragen naar de gebruikers. Er zijn overeenkomsten met de KSZ, een stellair netwerk dat de uitwisseling van data tussen instellingen mogelijk maakt. Wat de sociale zekerheid betreft, kunnen gegevensgebruikers een glossarium van de data (of “Data Catalog” in het schema) raadplegen in de verschillende versies, online op het portaal van de sociale zekerheid (6). Dit is een goede oplossing in de genoemde context.
- Voordelen: eerbiediging van de privacy, veiligheid, de brondata hoeven niet te worden gewijzigd
- Nadelen: mogelijke prestatieproblemen, de dataproducenten moeten hun Data Catalog delen, uniformiseren, in hetzelfde tempo bijwerken en toegankelijk maken voor de gebruikers.
- Consolidatie
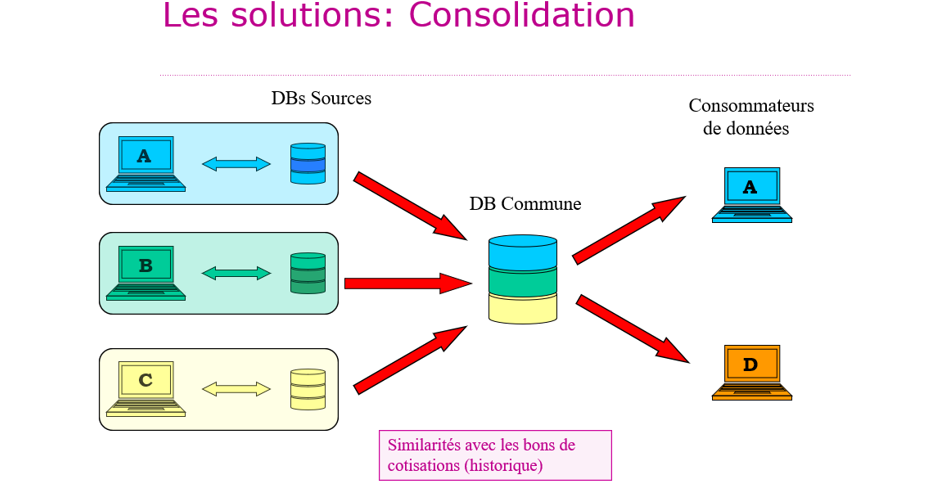
Bij consolidatie worden de brondata in één keer (“one shot”) naar een gemeenschappelijke database gekopieerd. Er staat geen “Data Catalog” op het schema, omdat de gemeenschappelijke database vervolgens wordt gedesynchroniseerd van de “brondata” die zij geacht wordt te vertegenwoordigen. Deze oplossing wordt niet aanbevolen. Ze werd in het verleden in de toepassing gebracht voor het beheer van zorgpremies, maar werd later opgegeven.
- Voordelen: eenvoudig voor data-producenten: de brondatabases hoeven niet te worden gewijzigd
- Nadelen: de brondatabases en hun Data Catalog kunnen in hun eigen tempo evolueren en de gemeenschappelijke database in een ander tempo (“ghost factory”, bron van redundantie): er doen zich problemen voor op het vlak van de kwaliteit van de ‘geconsolideerde’ data, het delen van een “gemeenschappelijke Data Catalog” heeft geen zin meer.
- Samenwerking
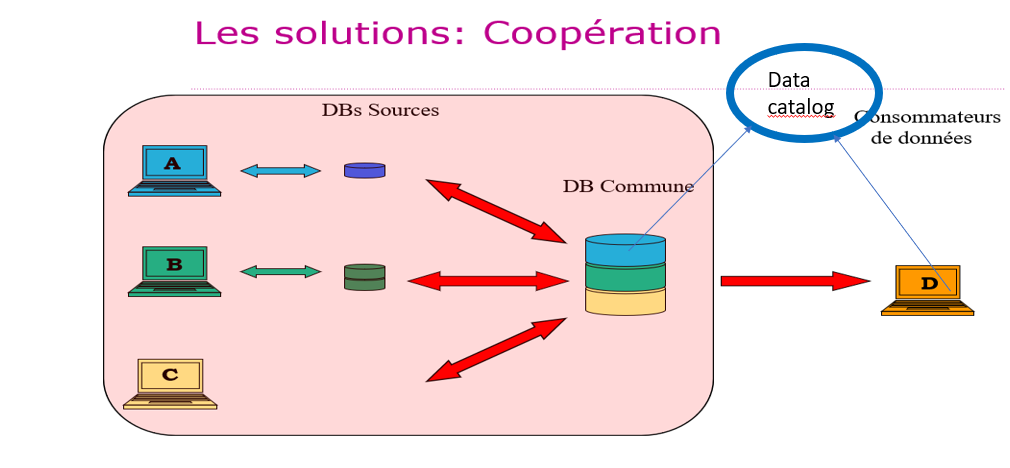
Bij samenwerking delen de brondatabases de gemeenschappelijke “masterdata” in een nieuwe database en blijven ze hun niet-gemeenschappelijke data beheren. Voor gemeenschappelijke data die in één exemplaar worden beheerd (dus zonder redundantie), wordt een “Data Catalog” ter beschikking gesteld van alle datagebruikers en gezamenlijk bijgewerkt door de dataproducenten. Dit is een goede oplossing als de brondatabases moeten worden geherstructureerd omdat ze bijvoorbeeld technisch en conceptueel verouderd zijn
- Voordelen: de masterdata zijn op één plek toegankelijk (wat goed is voor de datakwaliteit) en hun ‘Data Catalog’ is gemeenschappelijk, het voor datagebruikers toegankelijke deel wordt verspreid. De privacy en veiligheid zijn gewaarborgd. Elke data-producent blijft zijn eigen data beheren en deze worden niet gedeeld.
- Nadelen: de brondatabases moeten worden geherstructureerd, mogelijke prestatieproblemen.
- Centralisatie
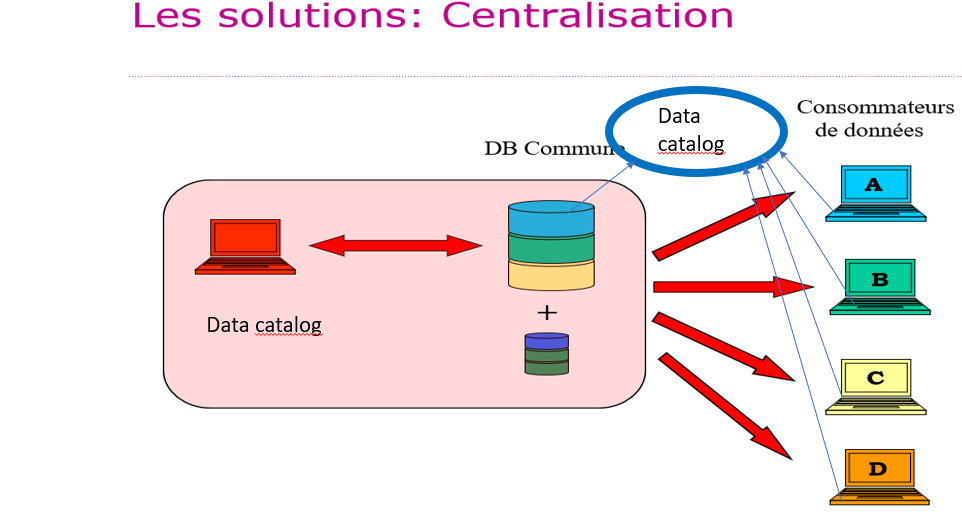
Voorlopige conclusies
Wat de voorgestelde architecturen betreft (en rekening houdend met alle voorafgaande stappen die in dit artikel zijn geïllustreerd), lijkt de virtuele directory met “Data Catalog” de beste oplossing. Als een (herstructurering van) de brondatabases nodig is, kan samenwerking worden overwogen.
In een volgende blogartikel over Master Data Management zullen we kijken naar de lessen die in België en in het buitenland zijn geleerd over het gebruik van Master Data Management op basis van de tools en implementatiemethoden, en zullen we een typologie van MDM-tools geven met een kritische en constructieve blik.
Referenties
(1) DUBOIS P. et al. (University of Paris), Harnessing Data Integrity: A Study of Master Data Management Best Practices. MZ Computing Journal, vol 5, issue 1, 2023.
(2) Hype Cycle for Data and Analytics Governance 2025, Gartner, 19 June 2025 – ID G00827117.
(3) LEPENIOTIS P, Master data management: its importance and reasons for failed implementations. Doctoral Thesis, Sheffield Hallam University Press, 2020 (3 vol.).
(4) SINGH A. et al., Best Practices for Creating and Maintaining Material Master Data in Industrial Systems In International journal of research and analytical reviews, vol 10, issue 1, Janvier 2023.
(5) TRIGAUX J.-C., Master Data Management – Mise en place d’un référentiel de données. Bruxelles, Smals Research, Deliverable 2009/TRIM4/01.
(6) BOYDENS I., De kern van data governance: ‘data catalogs’ of Metadata Management Systemen, Brussel, Smals Research, blogartikel, 19/03/2025 (link beschikbaar naar de Franstalige versie).
(7) BOYDENS I., HAMITI G. en VAN EECKHOUT R., A service at the heart of database quality. Presentation of an ATMS prototype. In Le Courrier des statistiques, Parijs, INSEE, 2023, nr. 6, 11 p. (gepubliceerd op 2/10/2023). Link naar het artikel.
(8) BOYDENS I., HAMITI G. en VAN EECKHOUT R., Data Quality: “Anomalies & Transactions Management System” (ATMS), prototype & “work in progress”, Brussel, Smals Research, blogartikel, 02/12/2020, last update 04/07/2025. (link beschikbaar naar de Franstalige versie).
(9) BOYDENS I., CORBESIER I. en HAMITI G., Data Quality Tools : retours d’expérience et nouveautés, Brussel, Smals Research, blogartikel, 07/12/2021.
(10) BOYDENS I., Dix bonnes pratiques pour améliorer et maintenir la qualité des données, Brussel, Smals Research, blogartikel, 16/06/2014, last update: december 2021.
(11) BOYDENS I., Data Quality & Back Tracking : depuis les premières expérimentations à la parution d’un Arrêté Royal, Brussel, Smals Research, blogartikel, 14/05/2018.
(12) XLS en het FedVoc-bestand gepubliceerd op GitHub van BelgIF GitHub – belgif/fedvoc: Federal Vocabularies