Introduction
La détection d’anomalies (aussi souvent appelées « outliers », ou encore « valeurs aberrantes ») est un problème récurrent en data science/machine learning. Cette détection est bien souvent considérée comme une simple tâche préliminaire, mais peut parfaitement être la finalité de l’application :
- En tant que tâche préliminaire, la détection a lieu durant l’analyse exploratoire, afin de limiter les soucis de « garbage in, garbage out ». L’objectif est donc ici de corriger ou d’enlever ces anomalies pour éviter qu’elles ne soient utilisées durant la phase d’entrainement du modèle prédictif, car cela risquerait d’affecter négativement ses performances.
- En tant que tâche principale, la détection d’observations présentant des profils anormaux peut par exemple servir à détecter des activités frauduleuses, des erreurs, ou encore des intrusions (IDS: Intrusion Detection System) [1].
La détection d’anomalies est donc une tâche très importante qui trouve un grand nombre d’applications dans de nombreux domaines [1], visant à trouver des observations qui ne se conforment pas au reste des données [2].
Cet article de blog s’intéresse au problème de la détection d’anomalies dans des données, et a pour objectif de présenter les solutions basées sur une approche machine learning.
Les différents types d’anomalies
Avant de discuter des outils permettant la détection d’anomalies, commençons dans un premier temps par définir les différents types d’anomalies qui peuvent être détectés. Dans la littérature, on considère souvent qu’il y a 3 types d’anomalies [3] :
- L’anomalie ponctuelle
Il s’agit de la forme la plus simple d’anomalies : une instance individuelle considérée comme anormale vis-à-vis du reste des données.
Ces anomalies sont encore parfois divisées en 2 sous-catégories, les anomalies globales (significativement différentes du reste des données) et les anomalies locales (différentes du voisinage local). Exemple illustratif :
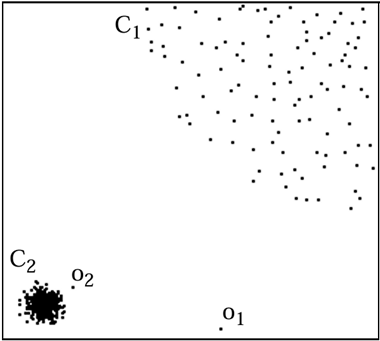
Figure 1 : Exemple d’anomalies locale et globale (image extraite de [4])
Dans la Figure 1, on peut voit deux anomalies : o1, une anomalie globale fortement différente des autres observations, et o2, une anomalie locale par rapport à son voisinage (le groupe C2).
- L’anomalie contextuelle
Une anomalie est dite « contextuelle » si, dans un contexte différent, elle peut être considérée comme normale. Par exemple, si l’on s’intéresse aux précipitations : un certain niveau de précipitations, qui est anormal à un endroit donné, pourrait parfaitement être considéré comme normal à un autre endroit. On a donc ici deux types d’attributs : des attributs contextuels qui définissent le contexte (souvent des attributs temporels ou spatiaux) et des attributs comportementaux dans lesquelles on va chercher les anomalies (dans notre exemple : les précipitations).
- L’anomalie collective/anomalie de groupe
Dans cette dernière catégorie, il ne s’agit plus d’une anomalie individuelle mais d’un ensemble d’anomalies, formant un groupe dont les caractéristiques sont inhabituelles.
Les méthodes de détection
Souvent (et particulièrement lorsqu’il s’agit d’une simple tâche préliminaire de data cleansing), la détection d’anomalies dans les données se fait simplement via des outils statistiques (par exemple, en utilisant les écarts-types, les quantiles, ou via des tests statistiques). Dans le cadre de cet article, nous n’allons pas explorer ces approches statistiques et nous concentrer sur les approches machine learning de la détection d’anomalies.
Quel type d’apprentissage ?
Il existe principalement deux approches pour détecter des anomalies, les méthodes basées sur l’apprentissage supervisé et celles basées sur l’apprentissage non-supervisé. Pour rappel, l’apprentissage supervisé utilise des données labélisées : cela nécessite d’avoir, en plus des données, des exemples d’anomalies préalablement identifiées afin que le modèle de détection puisse apprendre à les différencier des données normales. A l’inverse, l’apprentissage non-supervisé se base entièrement sur les données et ne requiert pas de disposer d’un ensemble d’anomalies pré-identifiées.
Dans le cadre de cet article, nous allons explorer les approches non-supervisées. Ces dernières ont en effet une spécificité intéressante par rapport aux modèles supervisés (outre le fait de ne pas nécessiter de données labélisées) : la découverte de nouvelles formes d’anomalies.
En effet, un modèle supervisé aura tendance à identifier des anomalies présentant des caractéristiques similaires à celles des anomalies labélisées. Par conséquent, même dans les cas où des données labélisées existent, il sera souvent intéressant de coupler un modèle supervisé, entrainé pour détecter plus finement certains profils prédéfinis d’anomalies, avec un modèle non-supervisé, qui pourra potentiellement trouver des anomalies présentant des profils complètement différents.
Quelques algorithmes classiques de détection d’anomalies
Avant de commencer, nous allons séparer les algorithmes de détection d’anomalies en 2 catégories : les détecteurs et les modèles de détection. Un modèle de détection va, comme son nom l’indique, construire un modèle qui peut être utilisé de façon isolée : par exemple si l’on dispose d’une nouvelle observation, on peut simplement l’entrer dans le modèle pour estimer s’il s’agit d’une anomalie. A l’inverse, un détecteur n’aura pas de modèle entrainé pouvant être utilisé par la suite : si une nouvelle observation arrive, il faudra la recontextualiser en la plaçant parmi les autres données, voire éventuellement entièrement relancer le processus de détection d’anomalies.
Les détecteurs sans modèles
Une première approche intuitive pour identifier si une observation est une anomalie ou non se base sur l’idée qu’une anomalie a tendance à être éloignée de ses voisins. Ainsi, en mesurant la distance moyenne (distance euclidienne par exemple) entre une observation et ses k plus proches voisins (k-NN), ou simplement la distance entre une observation et son kième plus proche voisin (kth-NN) [5], on peut estimer le risque qu’une observation soit une anomalie : si l’observation est loin des autres, on peut supposer qu’il s’agit d’une anomalie.
Cette approche basée sur la distance a l’avantage d’être intuitive, facile à implémenter et à interpréter, mais elle est rapidement limitée. Si on reprend l’exemple de la Figure 1, on observe toutes les observations du cluster C1 sont plus éloignées les unes des autres que o2 ne l’est des observations de C2. Résultat : un algorithme basé sur la distance retrouvera facilement l’anomalie o1, mais pas o2. Une approche alternative très connue, le Local Outlier Factor (LOF) [4] se base sur la densité plutôt que sur la distance. Cela permet de gérer les cas où les données contiennent des clusters (C1 et C2 dans la Figure 1) qui n’ont pas la même densité.
L’idée est la suivante : observer si la densité autour d’une observation est cohérente avec la densité de ses k plus proches voisins. Ainsi, si l’on prend une observation faisant partie du groupe C1, la densité autour de cette observation est cohérente par rapport à la densité autour de ses voisins proches, là où, pour l’observation o2, la densité autour de o2 est différente de la densité autour de ses plus proches voisines au sein de C2. L’algorithme LOF consiste donc à détecter des anomalies en regardant si leur densité est cohérente avec la densité de leur environnement local.
Un dernier type de détecteur que nous allons voir se base sur le partitionnement de données (clustering). L’objectif bien connu du clustering va être de détecter des groupes d’observations ayant des caractéristiques similaires. Cela permet notamment de :
- Chercher une observation se trouvant loin du centroïde de son cluster, ou se trouvant dans un micro-cluster qui ne contient qu’une observation (anomalie ponctuelle).
- Chercher des clusters anormaux (anomalies collectives).
Par exemple, Jiang et al. [6] proposent de partitionner les données, puis de calculer « l’outlier factor » de chaque cluster (basé sur la distance entre ce cluster et les autres), afin de trouver des clusters d’anomalies. De leur côté, He et al. [7] proposent l’algorithme FindCBLOF (CBLOF : cluster-based local outlier factor) qui partitionne les données, puis cherche les anomalies en utilisant à la fois la taille des clusters (les clusters trop petits pouvant représenter des anomalies collectives) et les distances entre les observations et les centroïdes des clusters.
Les modèles de détection
Maintenant que nous avons vu des approches sans modèle, nous allons encore rapidement passer à des approches basées sur des modèles de détection d’anomalies. Cette section sera relativement courte et ne présentera que deux modèles parmi les plus connus : « l’isolation forest » et le « one-class SVM ».
L’isolation forest [8] se base sur le principe qu’une anomalie, puisqu’elle présente des caractéristiques inhabituelles, devrait être plus facile à isoler qu’une observation normale.
L’idée est simple : on va piocher au hasard une variable et une valeur (par exemple : âge (variable) et 21.3 (valeur)), et les utiliser pour séparer les données en deux sous-groupes (branches). Chacun de ces groupes sera ensuite lui-même divisé de façon aléatoire en sous-groupes, qui seront à leur tour divisés, et ainsi de suite de manière récursive, formant un arbre de décision (decision tree), construit de manière aléatoire, que l’on appelle un isolation tree.
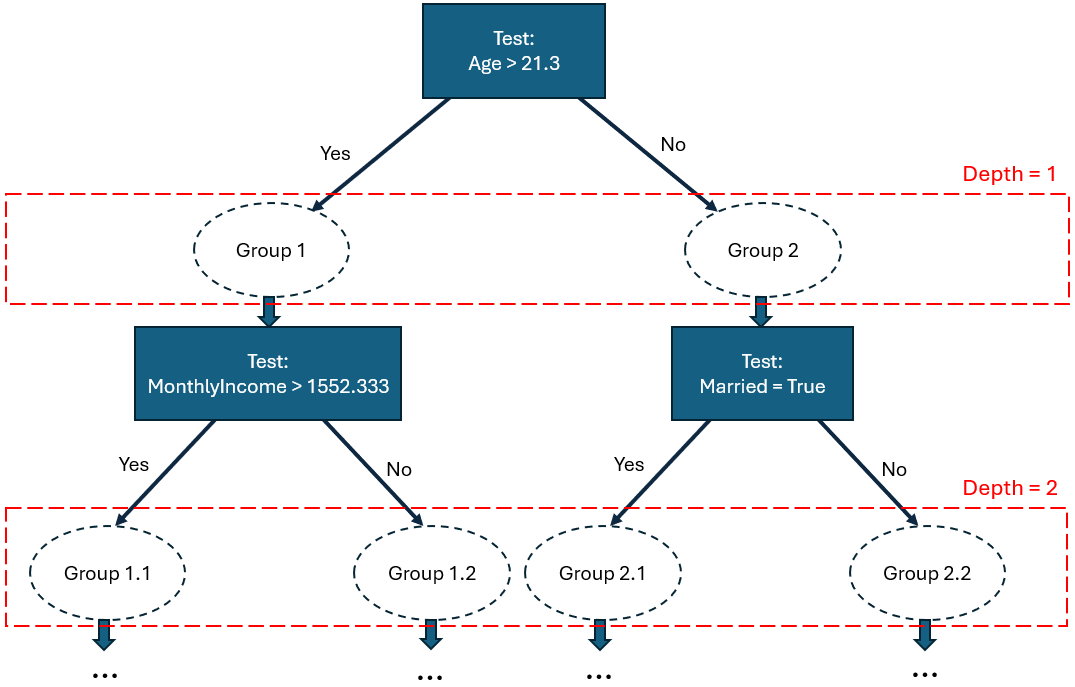
Figure 2 : Exemple illustratif d’isolation tree
Durant le développement de l’arbre, aussitôt qu’un groupe ne contient plus qu’une seule observation, ce groupe n’est plus divisé en sous-groupes. Une Isolation Forest est donc composée d’un grand nombre de ces arbres aléatoires, avec l’idée qu’une observation normale devrait être plus difficile à isoler (et donc, demander en moyenne plus de divisions aléatoires de l’espace) qu’une anomalie (voir Figure 3).
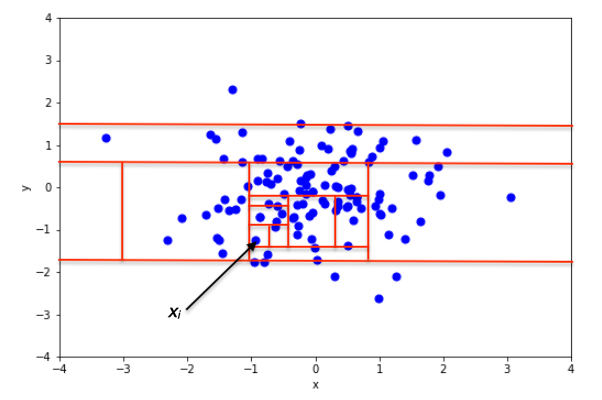
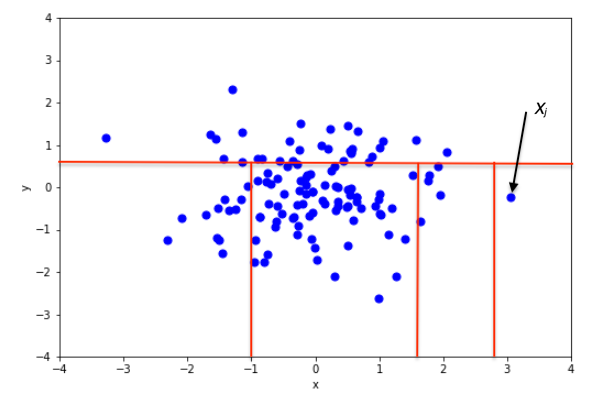
Figure 3 : Exemple d’isolation d’une observation normale (xi) et anormale (xj) (image extraite de [9])
Pour identifier si une observation est une potentielle anomalie, il suffit simplement de regarder à quelle profondeur elle se trouve isolée dans les différents arbres. Les anomalies devraient en moyenne se retrouver isolées peu profondément dans les arbres, car elles sont plus faciles à isoler.
Le one-class SVM (OCSVM) [10] est le second modèle que détection auquel nous allons nous intéresser dans cet article. Notez que l’algorithme sous-jacent à l’OCSVM est nettement moins intuitif et facile à expliquer que l’isolation forest, nous n’allons donc pas nous attarder sur son fonctionnement. Cependant, nous allons tout de même le présenter rapidement, car il s’agit d’un modèle classique bien connu en détection d’anomalies.
L’OCSVM essaie de trouver la région où les données sont densément situées, et de considérer les points en dehors de cette région comme anormaux. L’objectif pour l’OCSVM est d’apprendre la forme de la « normalité », afin de déterminer une frontière qui séparerait les observations normales des anomalies. La spécificité de l’algorithme OCSVM est que, plutôt que d’utiliser directement les caractéristiques (features) des observations pour déterminer la frontière entre observations normales et anormales, il va projeter les observations dans un espace transformé, permettant de dessiner des frontières complexes entre données normales et anormales.
Exemple illustratif
Pour illustrer la détection d’anomalies, nous avons généré des données artificielles en 2 dimensions, contenant :
- Des données « normales » : générées suivant une distribution normale.
- Des anomalies : générées au hasard suivant une distribution uniforme.
Les données normales et les anomalies ont été mélangées et nous avons appliqué 3 algorithmes de détection d’anomalies dessus (OCSVM, Isolation Forest et LOF). Les résultats sont visibles dans les Figures 4 – 6 :
- Figure 4 : Un seul groupe d’observations normales ;
- Figure 5 : Deux groupes d’observations normales légèrement séparés ;
- Figure 6 : Deux groupes d’observations normales bien séparés.
Pour chacune de ces figures, les observations normales sont affichées en blanc et les anomalies en noir, afin de pouvoir facilement les distinguer visuellement. Ces labels (normal vs. anomalie) n’ont évidemment pas été fournis aux algorithmes, qui tournent de façon non-supervisés.
Pour chacun de ces 3 algorithmes, nous avons mis en évidence en rouge la frontière utilisée par l’algorithme pour différencier les données normales des anomalies. Les observations dans la zone orange (à l’intérieur de la frontière) sont considérées par l’algorithme comme normales, et les observations dans la zone bleue sont considérées comme des anomalies (bleu clair : légèrement anormal ; bleu foncé : fortement anormal).
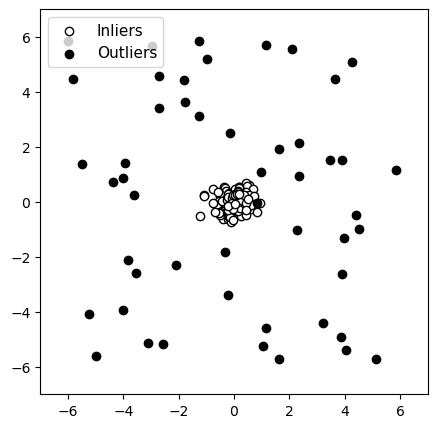
Données originales
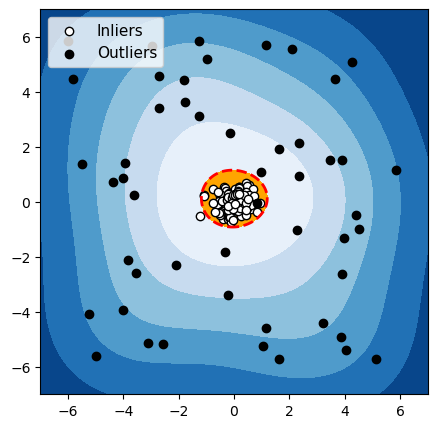
OCSVM
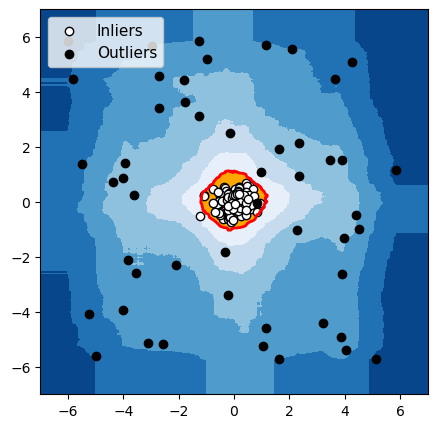
Isolation Forest
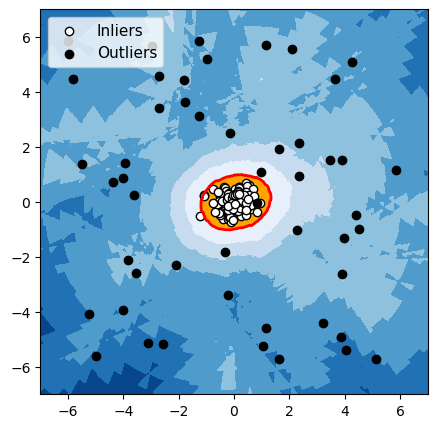
LOF
Figure 4 : Détection d’anomalies avec un groupe de données normales
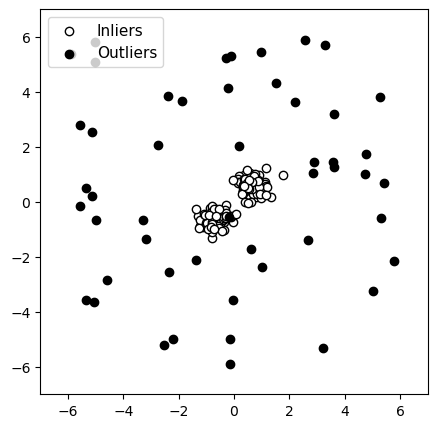
Données originales
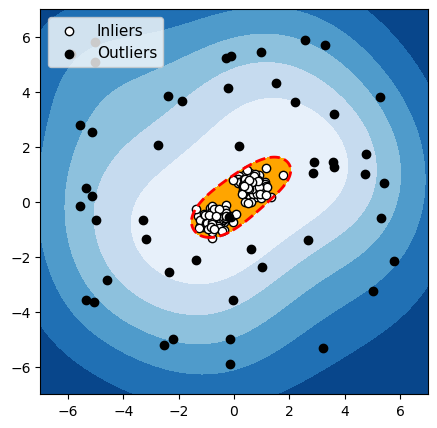
OCSVM
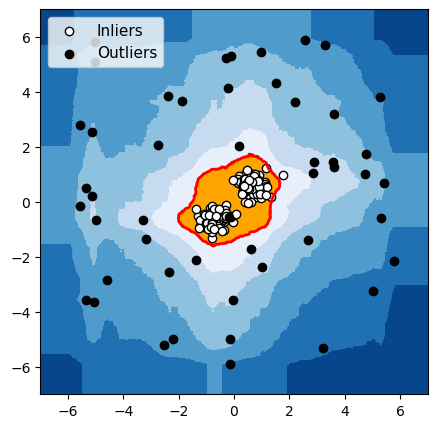
Isolation Forest
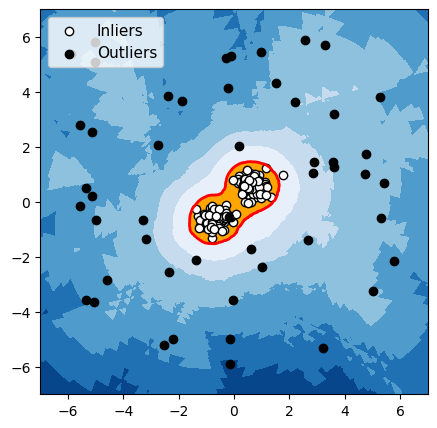
LOF
Figure 5 : Détection d’anomalies avec deux groupes légèrement séparés de données normales
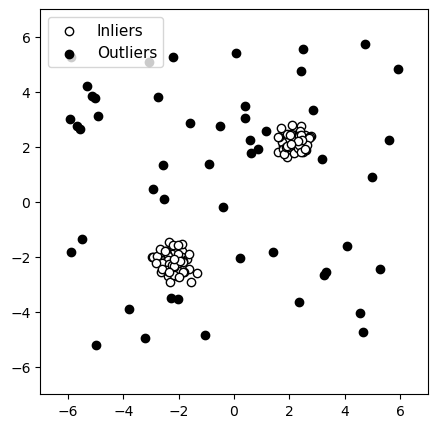
Données originales
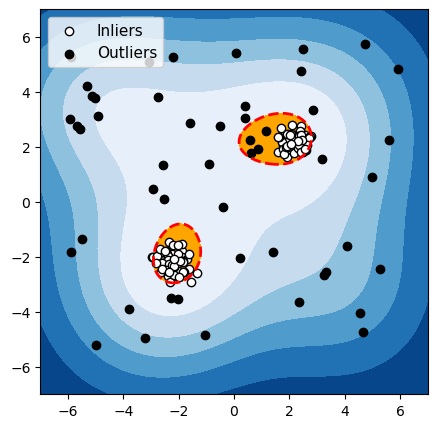
OCSVM
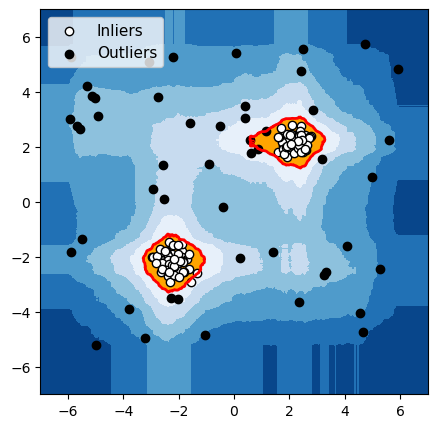
Isolation Forest
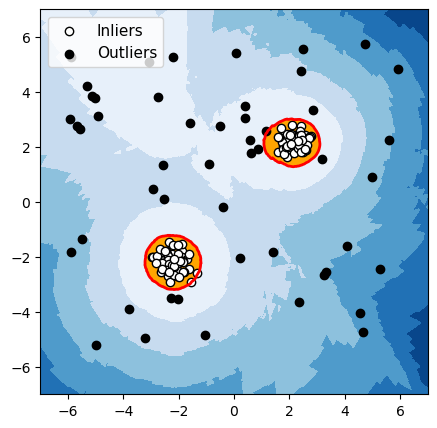
LOF
Figure 6 : Détection d’anomalies avec deux groupes fortement séparés de données normales
Evaluer la détection
Réussir à quantifier la qualité de la détection d’anomalies n’est pas une tâche aisée. Commençons par le cas le plus facile : si nous disposons d’anomalies pré-identifiées (labels). Dans ces cas, un algorithme de détection d’anomalies pourra être validé en vérifiant si celui-ci parvient à retrouver les anomalies déjà connues, en utilisant des mesures classiques (recall, precision, F1-measure, etc.)
En l’absence de label, c’est là que ça se complique. Dans ce cas, il faudra vérifier manuellement les observations identifiées par l’algorithme, afin de confirmer si celles-ci sont effectivement anormales. Cela demande non seulement d’avoir des bonnes connaissances du domaine d’où sont issues les données, mais aussi de comprendre pourquoi l’observation a été identifiée par l’algorithme comme anomalie. En effet, puisqu’il y a souvent un grand nombre de variables dans les données, et que la frontière (entre données normales et anormales) utilisée par l’algorithme est généralement complexe, il est parfois difficile de comprendre pourquoi certaines observations ont été identifiées comme des anomalies par un algorithme. Il peut alors être utile d’utiliser des outils d’explicabilité (par exemple : SHAP, LIME) pour comprendre les décisions de l’algorithme.
Conclusion
Nous avons choisi, dans cet article de blog, de présenter une sélection d’algorithmes (non-supervisés) basés sur des approches variées (distance, densité, isolation, etc.), afin d’illustrer la grande diversité d’algorithmes qui existent. Cependant, rappelons que nous n’avons pas exploré les méthodes supervisées (souvent plus précises car spécialisées dans la détection de patterns prédéfinis) et les approches statistiques. La détection d’anomalies est donc un domaine vaste offrant de nombreux outils. Les algorithmes non-supervisés offrent une grande flexibilité, car ils ne requièrent pas de labels et peuvent détecter des nouvelles formes d’anomalies. Dans la pratique, puisque chaque algorithme de détection est différent, il est parfois utile de combiner plusieurs algorithmes de détection d’anomalies afin d’avoir une plus grande variété dans les formes d’anomalies détectées.
[1] : Chandola, V., Banerjee, A., & Kumar, V. (2009). Anomaly detection: A survey. ACM computing surveys (CSUR), 41(3), 1-58.
[2] : Samariya, D., & Thakkar, A. (2023). A comprehensive survey of anomaly detection algorithms. Annals of Data Science, 10(3), 829-850.
[3] : Nassif, A. B., Talib, M. A., Nasir, Q., & Dakalbab, F. M. (2021). Machine learning for anomaly detection: A systematic review. Ieee Access, 9, 78658-78700.
[4]: Breunig, M. M., Kriegel, H. P., Ng, R. T., & Sander, J. (2000). LOF: identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD international conference on Management of data (pp. 93-104).
[5] : Ramaswamy, S., Rastogi, R., & Shim, K. (2000). Efficient algorithms for mining outliers from large data sets. In Proceedings of the 2000 ACM SIGMOD international conference on Management of data (pp. 427-438).
[6] : Jiang, S. Y., & An, Q. B. (2008). Clustering-based outlier detection method. In 2008 Fifth international conference on fuzzy systems and knowledge discovery (Vol. 2, pp. 429-433). IEEE.
[7] : He, Z., Xu, X., & Deng, S. (2003). Discovering cluster-based local outliers. Pattern recognition letters, 24(9-10), 1641-1650.
[8] : Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008). Isolation forest. In 2008 eighth ieee international conference on data mining (pp. 413-422). IEEE.
[9] : Isolation forest – Wikipedia
[10] : Schölkopf, B., Platt, J. C., Shawe-Taylor, J., Smola, A. J., & Williamson, R. C. (2001). Estimating the support of a high-dimensional distribution. Neural computation, 13(7), 1443-1471.