Dans un précédent article de blog, nous avons décrit quelques techniques permettant d’améliorer la qualité des réponses dans un système génératif de questions-réponses.
Pour rappel, RAG (Retrieval Augmented Generation) est l’architecture appropriée pour éviter les hallucinations en fournissant aux modèles de langage un contexte. Avant que le modèle de langage ne génère une réponse, il récupère d’abord les informations les plus pertinentes pour la question (retrieval). Ces informations sont ensuite fournies en tant que contexte au modèle de langage, qui a pour mission de générer une réponse sur la base de ce contexte (generation). Des erreurs peuvent se produire à la fois lors de l’étape dite du retrieval et lors de l’étape dite de la generation. Il est donc nécessaire de surveiller la qualité.
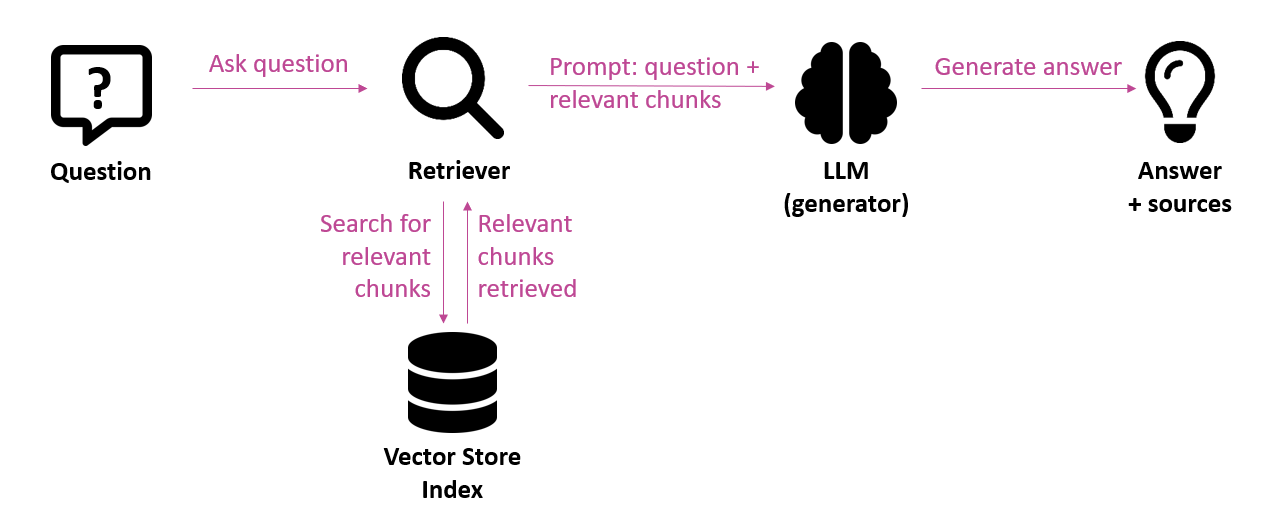
Dans cet article, nous examinons l’importance de mesurer la qualité d’un système RAG, les défis à relever, les mesures que nous pouvons appliquer et les outils et cadres qui peuvent nous aider à le faire.
L’importance de l’évaluation
Avant de décrire comment évaluer un système génératif de réponse aux questions, prenons le temps de réfléchir aux raisons de cette évaluation.
Un système génératif de réponse aux questions est intrinsèquement sujet à des erreurs (hallucinations, imprécisions). Il est donc important de connaître la qualité des résultats afin d’identifier les points de friction et d’être en mesure d’améliorer la qualité de manière ciblée.
Les évaluations permettent d’établir un benchmark d’une première version du système de questions-réponses. La qualité des nouvelles versions du système peut ensuite être comparée à ce baseline ou aux versions précédentes. Ainsi, l’impact des changements peut être mesuré, comme l’amélioration de la composante de retrieval, le déploiement d’un modèle de langage différent ou la modification du prompt.
Les évaluations peuvent aider à décider si le système doit être mis en production ou non. Elles peuvent renforcer la confiance dans le système en démontrant qu’il est précis et fiable.
Les défis de l’évaluation
Métriques – Contrairement aux logiciels traditionnels, l’output des applications LLM n’est pas déterministe : une entrée spécifique peut conduire à de multiples outputs corrects (ou erronés). L’output peut être subjectif. Par conséquent, nous ne pouvons pas simplement utiliser “vrai ou faux” comme critère d’évaluation, nous devons recourir à d’autres critères. Comparons cela à l’évaluation d’une dissertation (non déterministe) par rapport à l’évaluation de réponses à des questions à choix multiples (déterministe).
Scalabilité – Pour avoir une première impression rapide de la qualité d’un système génératif de questions-réponses, vous pouvez effectuer des tests manuellement, par exemple en posant une vingtaine de questions et en évaluant manuellement la qualité des réponses générées. Mais cette méthode est difficile à maintenir si vous souhaitez effectuer une évaluation à plus grande échelle, avec un set de test plus important ou lorsque toutes les réponses sont évaluées alors que le système fonctionne en production. Dans ce cas, il est intéressant d’effectuer des évaluations automatiques. Cela implique l’utilisation d’un modèle de langage pour évaluer un aspect particulier. On parle alors de “LLM-as-judge“.
Qualité – L’utilisation de modèles de langage pour évaluer les résultats des modèles de langage est quelque peu surprenante. De telles évaluations automatiques peuvent elles-mêmes contenir des erreurs ; nous devons être vigilants quant à leur qualité.
Rentabilité – L’exécution d’évaluations automatiques basées sur des modèles de langage implique des coûts pour l’utilisation de ces LLM typiquement offerts comme un service API dans le cloud. Si nous ne faisons pas attention, le coût de ces évaluations peut augmenter considérablement et même dépasser le coût de traitement des requêtes des utilisateurs finaux.
Confidentialité – La réalisation d’évaluations basées sur les LLM peut exposer des informations confidentielles aux fournisseurs de services LLM basés sur le cloud.
Granularité – Vous voulez non seulement connaître le degré de précision de la réponse générée, mais aussi découvrir la cause de toute erreur ou inexactitude. Pour ce faire, vous devez conserver des log traces détaillés.
Il est évidemment important d’interpréter ce qui a été mesuré par une métrique particulière. Ci-dessous, nous essayons d’expliquer clairement les métriques les plus couramment utilisées.
Métriques d’évaluation
Bien qu’il n’y ait pas encore de normalisation des métriques, des initiatives émergent qui peuvent fournir des orientations importantes. Par exemple, la RAG triad de TruEra décrit trois métriques liées à la requête de l’utilisateur final (query), au contexte récupéré par le retrieval system (context) et à la réponse éventuellement générée par le modèle de langage (response).
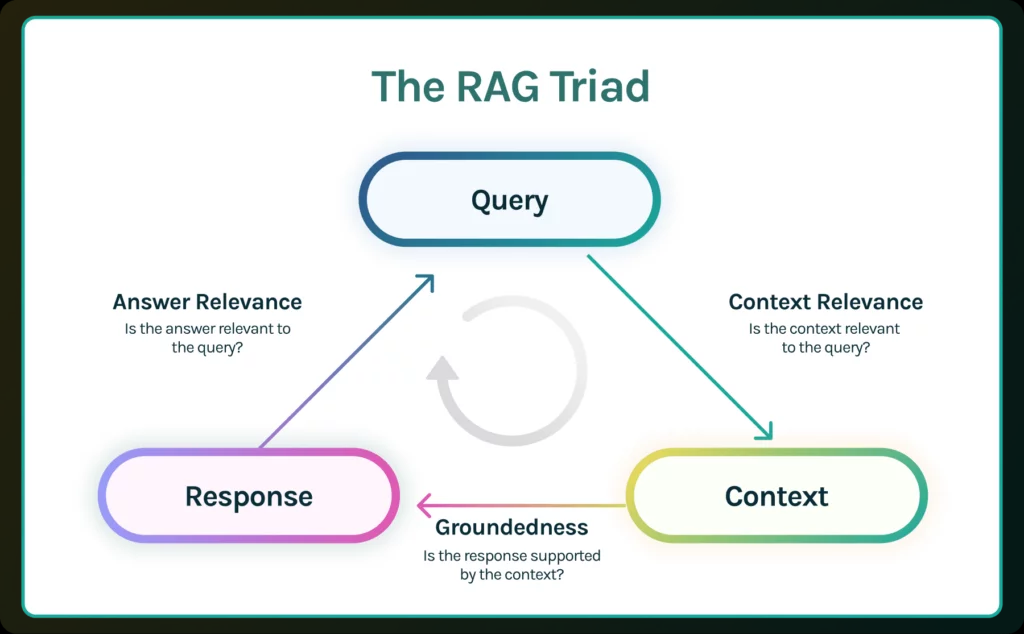
- Context relevance indique le degré de pertinence du contexte par rapport à la question posée. Le contexte récupéré lors de l’étape retrieval est basé sur une recherche sémantique (similarity search), ce qui ne signifie pas nécessairement que ce contexte est pertinent par rapport à la question posée. Cette métrique permet d’identifier les problèmes éventuels lors de l’étape de retrieval.
- Groundedness indique dans quelle mesure la réponse est étayée par le contexte. Même si tout le contexte pertinent est fourni au modèle de langage, ce dernier peut toujours inventer (une partie de) la réponse. Cette métrique vérifie si (les différentes parties de) la réponse peuvent être retracées jusqu’aux statements du contexte. En d’autres termes, peut-on trouver des preuves de la réponse dans le contexte fourni ? Si le score groundedness n’est pas assez élevé, la réponse générée peut ne pas être transmise à l’utilisateur, mais plutôt indiquer qu’il n’y a pas assez d’informations disponibles pour répondre à la question.
- Answer relevance indique dans quelle mesure la réponse est effectivement une réponse à la question posée. La réponse peut être correcte sur le plan factuel et étayée par le contexte, sans pour autant constituer une réponse à la question posée. Cette métrique ne tient pas compte de l’exactitude factuelle de la réponse, mais pénalise les réponses incomplètes ou redondantes
Outre ces trois métriques, la réponse peut également être comparée à une réponse de référence (ground truth ou réponse d’un expert considérée comme correcte), comme les métriques du framework Ragas :
- Answer semantic similarity donne une évaluation de la similarité sémantique entre la réponse générée et la réponse de référence.
- Answer correctness: il s’agit d’une combinaison de l‘answer semantic similarity et de l’answer factual similarity. L’idée de la factual similarity est de mesurer la pertinence des énoncés de la réponse générée par rapport à ceux de la réponse de référence.
En outre, il existe également des métriques permettant d’évaluer la stratégie de chunking, telles que celle proposée par Galileo :
- Chunk attribution indique combien de chunks et quels chunks ont été utilisés pour générer la réponse. L’extraction d’un trop grand nombre de chunks qui ne contribuent pas à la réponse diminue la qualité du système et entraîne des coûts plus élevés parce que de nombreux tokens sont envoyés inutilement au modèle de langage.
- Chunk utilization mesure, pour un chunk donné, la part de celui-ci qui a été effectivement utilisée pour générer la réponse. Un score faible signifie qu’une grande partie du chunk n’est pas pertinente pour répondre à la question. Un ajustement de la taille des chunks peut permettre d’optimiser le système.
Ces deux métriques peuvent être utilisées pour optimiser la stratégie de chunking. Des valeurs optimales pour ces métriques signifient que moins d’informations non pertinentes sont fournies au modèle de langage, ce qui réduit les coûts et aide le modèle à rester concentré.
Pour toutes les métriques susmentionnées, l’accent est mis sur la qualité des réponses ou sur les éléments qui y contribuent. En outre, les métriques peuvent également être évaluées pour vérifier si les réponses sont nuisibles (contenu nuisible ou inapproprié, jailbreaks, etc.), ou si elles ont la bonne forme (cohérentes, concises, le bon ton, etc.). Les aspects non fonctionnels peuvent également être pris en compte, tels que la latence et le coût.
Enfin, il est important de mentionner que les métriques basées sur le LLM ne sont pas définies à l’aide de formules mathématiques. Des erreurs sont possibles et le résultat de la mesure doit être considéré comme une indication approximative. Par conséquent, l’évaluation par des experts business reste indispensable.
Dans ce contexte, on parle d’alignement : il s’agit de s’assurer que l’application d’IA générative répond aux attentes du business.
Quand évaluer ?
Les évaluations peuvent en principe être effectuées à chaque étape du cycle de vie d’une application : à chaque correction de bogue ou mise à jour de fonctionnalité, à chaque déploiement et une fois que l’application est opérationnelle.
Il existe des moyens d’intégrer des évaluations automatiques dans le pipeline CI, par exemple pre-commit ou pre-release. Des outils comme CircleCI misent sur ce type de support.
Afin de mesurer l’évolution de la qualité entre les différentes itérations du système, il est important de mettre en place un set de test fixe avec un certain nombre de questions et les réponses de référence correspondantes. Les questions doivent être aussi représentatives que possible du type de questions qui seront effectivement posées par les utilisateurs finaux.
Les métriques utilisées pour améliorer le système avant sa mise en production peuvent également être utilisées pendant la phase de production pour vérifier si les réponses aux questions réelles des utilisateurs finaux sont suffisamment précises. Comme indiqué précédemment, le coût de l’utilisation de modèles de langage en tant qu’évaluateur doit être pris en compte afin de ne pas faire dérailler les coûts.
Outils et frameworks
Sans vouloir être exhaustifs, voici quelques outils et cadres qui peuvent fortement appuyer la conduite des évaluations :
- Galileo est une plateforme d’évaluation et de suivi des applications d’IA générative. Elle fournit des métriques spécifiques pour l’optimisation de la stratégie de chunking (chunk attribution et chunk utilisation, voir ci-dessus). Il est également possible d’appliquer des guardrails en temps réel : la réponse peut être ajustée, par exemple en cas d’hallucinations ou de contenu nuisible. Les résultats des évaluations peuvent être inspectés visuellement dans une console qui est basée sur le cloud par défaut, mais qui peut également être hébergée sur une infrastructure interne. Enfin, pour réduire le coût des évaluations et préserver la confidentialité des données, Galileo travaille sur une solution basée sur des modèles plus légers qui peuvent être exécutés localement.
- Ragas est un framework open source pour évaluer les applications basées sur RAG. Il fournit un ensemble complet de métriques qui évaluent l’ensemble du système. Il s’agit notamment de mesures qui comparent la réponse générée à une réponse de référence (answer semantic similarity et answer correctness).
- TruLens est un projet communautaire open source sous l’égide de TruEra. TruEra a inventé le terme “RAG triad” qui combine 3 métriques pour évaluer les hallucinations dans les applications basées sur le LLM.
Conclusion
Les frameworks d’évaluation des applications RAG permettent un suivi et une évaluation systématiques de la qualité des systèmes génératifs de questions-réponses. Ils permettent de mesurer différents aspects, tels que la capacité à récupérer des informations pertinentes (retrieval) et la qualité des réponses générées. Ces métriques sont essentielles pour comprendre les faiblesses d’un système RAG et apporter les ajustements nécessaires.
L’utilisation d’un LLM peut automatiser l’exécution des évaluations et rendre les tests évolutifs. Cependant, il faut faire attention aux coûts que cela peut engendrer. Un modèle de langage en tant qu’évaluateur n’est pas exempt d’erreurs, mais il peut fournir un aperçu suffisant des domaines d’amélioration possibles d’un système génératif de questions-réponses. Toutefois, les résultats des mesures doivent être considérés comme une indication approximative ; nous ne pouvons pas nous y fier aveuglément. Par conséquent, l’évaluation par des experts business reste indispensable.
Ce post est une contribution individuelle de Bert Vanhalst, IT consultant chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.