Een chatbot is een computerprogramma dat automatisch kan antwoorden op berichten van eindgebruikers. Vaak gebeurt de communicatie tekstueel, zoals in een echte chatconversatie. Men kan echter ook bijkomende technologie toevoegen om spraak-gebaseerde communicatie toe te laten. In deze blog gaan we verder in op tekst-gebaseerde chatbots. Enkele voorbeelden van chatbot-technologieën zijn: IBM Watson Conversation, en Api.ai.
Met chatbot-technologie kan je bestaande toepassingen of websites verrijken met een interactieve ervaring voor de eindgebruiker. Bijvoorbeeld, aan een website kan men een chatvenster toevoegen waarmee de eindgebruiker eenvoudige vragen kan doorgeven aan de chatbot. Als de chatbot reeds kan antwoorden op veelgestelde vragen, kan de toegankelijkheid van de website worden verhoogd.
Deze toepassing brengt ons naar zogenaamde “frequently asked questions”, afgekort FAQ. Een FAQ is een verzameling van (veelgestelde) vragen met bijhorende antwoorden (https://en.wikipedia.org/wiki/FAQ).
Men treft FAQs vaak aan op websites. Bijvoorbeeld, er bestaat een FAQ over de elektronische identiteitskaart (eID): https://faq-eid.belgium.be/. We gebruiken eID als voorbeeld in deze blog, maar de behandelde concepten zijn algemeen toepasbaar.
Het nadeel van een FAQ is echter dat deze manueel moet doorzocht worden. Dat kan ofwel door stap voor stap alle vragen te overlopen, ofwel door te zoeken met de juiste keywords, namelijk, de woorden die effectief voorkomen in de FAQ.
Met chatbot-technologie kunnen we dit manuele zoekproces iets flexibeler maken. Het resultaat zullen we een FAQ-chatbot noemen. We beschrijven hieronder de concepten en een methodologie om dit te doen.
Flexibiliteit in verwoording en dialoog
Een eerste conceptuele stap van FAQ naar chatbot, is toelaten dat eenzelfde vraag op verschillende manieren kan verwoord worden. Dit hoeft niet beperkt te zijn tot het herkennen van synoniemen voor eenzelfde woord. We kunnen immers toelaten dat twee zinnen met een compleet verschillende structuur ook als eenzelfde vraag worden geïnterpreteerd. Bijvoorbeeld, in de context van technische problemen met eID zouden de volgende verwoordingen kunnen verwijzen naar telkens hetzelfde probleem:
- Ik heb een probleem met authentificatie in Firefox
- Hallo, de authentificatie in Firefox werkt niet
- Ik heb een probleem met mijn eID in Firefox
De bijhorende vraag zou eenduidig kunnen verwoord worden als: “Er is een probleem bij het aanmelden via eID in de Firefox webbrowser”.
In het ideale geval weten we op elke vraag meteen een geschikt antwoord; of anders gezegd, voor elk probleem weet de chatbot een oplossing. Maar een tweede belangrijke conceptuele stap, is erkennen dat we op sommige vragen niet meteen een gepast antwoord kunnen geven. Vragen van eindgebruikers kunnen soms te vaag zijn. In de context van technische problemen met eID, kunnen volgende verwoordingen als vaag worden gezien:
| Vraag | Wat blijft onduidelijk |
| Ik kan me niet authentificeren met eID |
|
| Combinatie browser en eID werkt niet |
|
| Probleem help |
|
Bij vage vragen willen we graag zelf bijkomende vragen stellen aan de eindgebruiker om het onderwerp van de vraag verder af te bakenen. Er ontstaat dan een diepere dialoog-structuur. Verdergaand op de bovenstaande vage vraag “probleem help”, zou het gesprek bijvoorbeeld als volgt kunnen verlopen:
- Gebruiker: Probleem help
- Chatbot: Welk operating systeem gebruikt u?
- Gebruiker: Windows 10
- Chatbot: Heeft u de eID QuickInstall procedure gevolgd?
- Gebruiker: Bedankt, ik zal dat eens proberen
- Chatbot: Graag gedaan.
Met geschikte wedervragen is het mogelijk om de eindgebruiker zo goed mogelijk te helpen.
Dialoog als netwerkstructuur
De bovenstaande principes, van flexibele verwoording en dialoog, kunnen worden uitgewerkt in een flowchart of netwerkstructuur. De knopen in dit netwerk stellen samenvattingen voor van wat de eindgebruiker heeft gezegd. Aan de knopen kunnen we tekstballonnetjes hangen om te specifiëren wat de chatbot moet zeggen als die knoop wordt bereikt. Zo’n tekstballonnetje definiëert dus de output van een knoop.
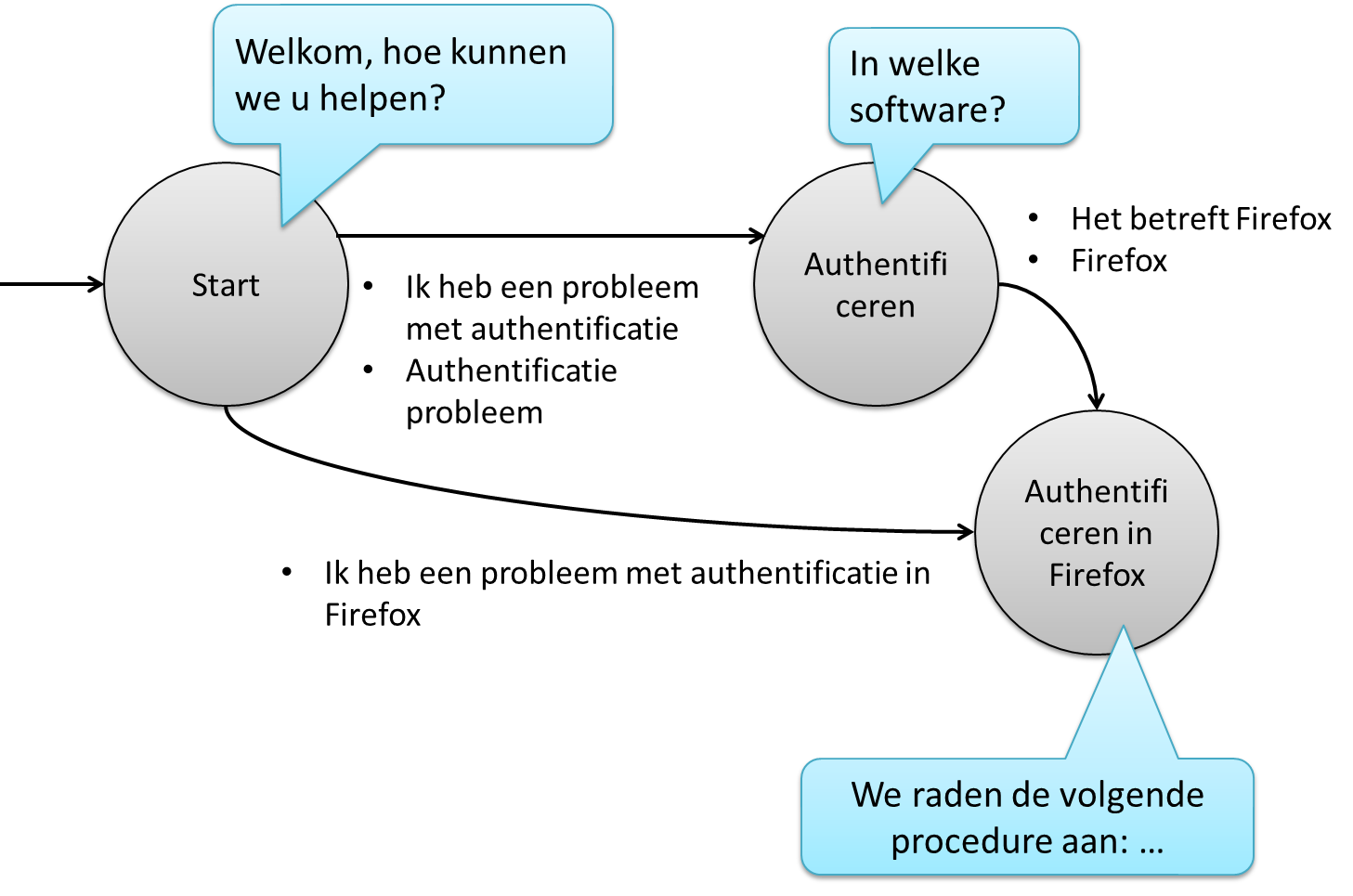
In een dergelijk netwerk duiden we altijd een start-knoop aan: hier begint het gesprek. Verder trekken we ook bogen van de ene knoop naar de andere om aan te geven hoe het gesprek wordt gestuurd als de eindgebruiker bepaalde woorden of volgorden van woorden ingeeft. Een boog zal typisch meerdere variaties bevatten van zinnetjes, om de flexibiliteit te verhogen waarmee de eindgebruiker het gesprek kan sturen. Bij een boog van knoop A naar knoop B zeggen we dat A de source knoop is, en B de target knoop.
Met elk nieuw bericht van de eindgebruiker, bewegen we doorheen de structuur van het netwerk, van de ene context-knoop naar de andere. Men kan de knopen ook bekijken als de gedachten van de chatbot. Tijdens een gesprek bezoekt de chatbot dan meerdere opeenvolgende gedachten: bij elk nieuw bericht van de eindgebruiker krijgt de chatbot een beter beeld van wat gezegd is en waarover de eindgebruiker wil praten.
Nota over training
In de praktijk moet de netwerkstructuur van de dialoog worden geïmplementeerd via een chatbot-technologie. De zinnetjes op een boog van knoop A naar knoop B worden training data voor de chatbot-technologie. De bedoeling is dat de technologie veralgemeningen gaat leren, door aan te leren welke woorden en combinaties van woorden de verschillende zinnetjes kenmerken. Als later tijdens een echt chat-gesprek we ons bevinden in knoop A, en de eindgebruiker schrijft een zinnetje dat lijkt op de zinnetjes die wij hebben opgeschreven (op de bogen die vertrekken vanuit A), dan kunnen we doelbewust bewegen naar een bepaalde target knoop van A. Hierop komen we later terug.
Context-afhankelijke interpretatie
De bovenstaande voorstelling van dialoog als een netwerkstructuur laat in principe toe dat we aan eenzelfde zin (of woord) van de eindgebruiker een andere betekenis toekennen afhankelijk van de knoop. Dit lijkt heel natuurlijk, maar niet alle chatbot-technologieën ondersteunen dit. Toch willen we graag benadrukken dat dit een belangrijk aspect kan zijn van een helpdesk-achtige chatbot die moet kunnen omgaan met vage zinnetjes (of woorden) van eindgebruikers.
Bijvoorbeeld, stel dat we een chatbot willen maken die technische vragen moet beantwoorden van werknemers in een IT bedrijf. Stel dat deze werknemers onder andere de volgende twee problemen kunnen hebben:
- Een probleem met Internetverbinding, waarbij werknemers het woord “web browser” of “browser” willen vermelden.
- Een probleem met een data tool (bijvoorbeeld voor boekhouding), waarin een bepaald onderdeel van de user interface wordt aangeduid met “data browser” of gewoon “browser”.
Het woord “browser” heeft dus in twee verschillende contexten een compleet andere betekenis.
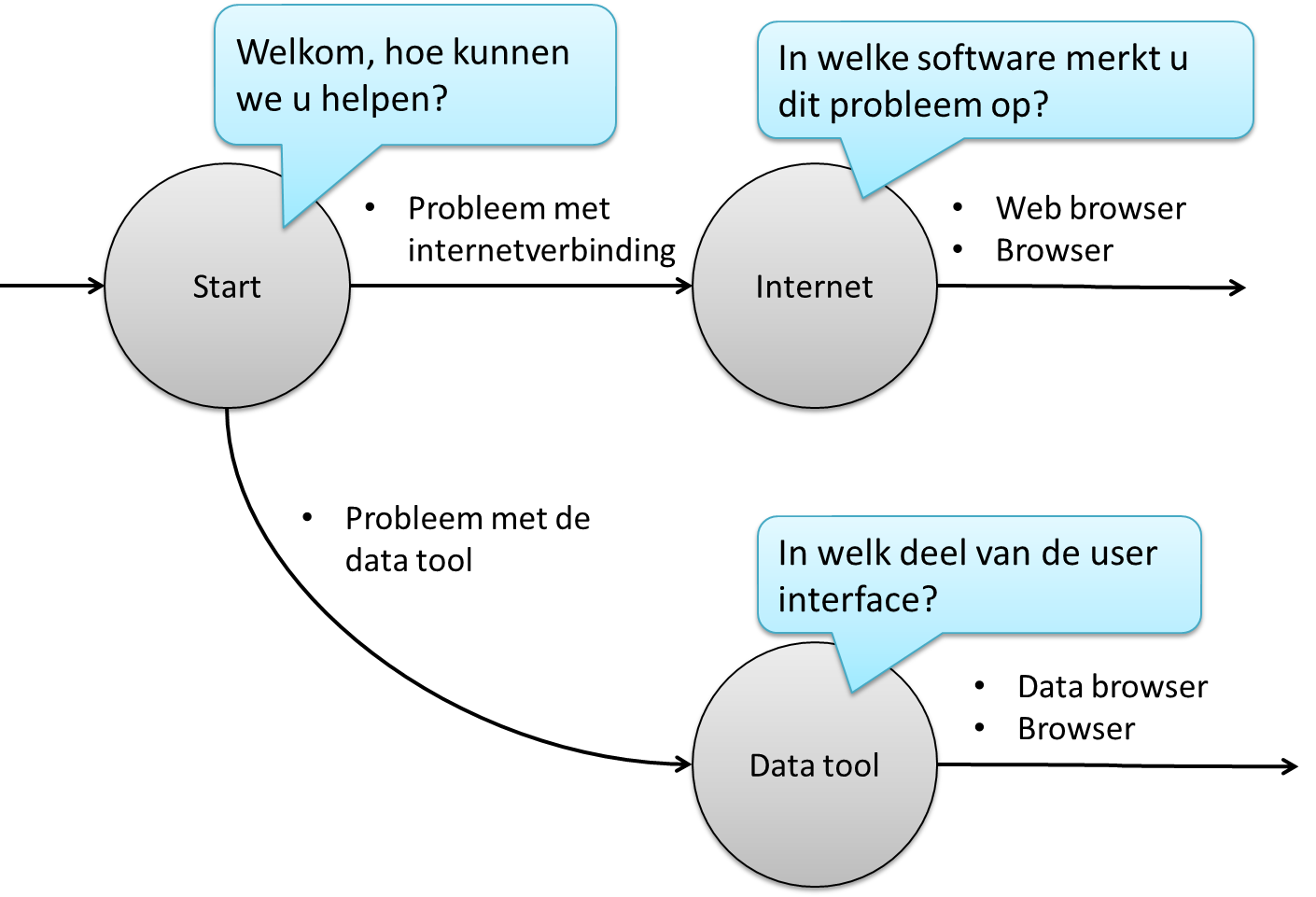
In het gedachtegoed dat we de eindgebruiker een flexibele interactie willen aanbieden via de chatbot, zou het niet kloppen om werknemers te vragen om steeds “web browser” te zeggen in de context van een internet probleem, of steeds “data browser” te zeggen in de context van een probleem met de data tool. Immers, de eindgebruiker heeft mogelijk al kenbaar gemaakt in een voorgaande zin binnen welke context de vraag zich afspeelt. Het is in principe redundant om “web” en “data” te vermelden (hoewel het is toegelaten).
Ontwikkelingsproces
We beschrijven hieronder een concreet stappenplan om een chatbot op te stellen als gids voor technische informatie, zoals die voorkomt in een FAQ.
Een eerste ruwe versie van de chatbot kan bekomen worden door een FAQ als basis te gebruiken:
- Zet de (eenduidige) vragen van de FAQ om naar vragen die vertrekken vanuit de start-knoop. Als we veronderstellen dat elke vraag in de FAQ uniek is, dan krijgt elke vraag typisch een eigen target-knoop. De output van een target-knoop voor vraag Q bevat het antwoord dat de FAQ geeft op vraag Q.
- Opgelet, bij een technische FAQ is het antwoord soms een lange procedure. In dat geval kan de output (het antwoord van de chatbot) best bestaan uit een korte samenvatting en een link naar een document met meer gedetailleerde informatie. De link kan bijvoorbeeld naar de oude FAQ zijn, die mag blijven bestaan naast de chatbot.
Vervolgens gaan we deze eerste versie flexibeler maken, zodat de eindgebruiker niet exact dezelfde terminologie moet gebruiken als de oorspronkelijke FAQ. Bovendien willen we toelaten dat aan het begin van het gesprek ook vragen mogen gesteld worden die minder eenduidig zijn als die in de FAQ. Daartoe kunnen we transcripts (chatlogs) verzamelen van conversaties tussen eindgebruikers en echte helpdeskmedewerkers. We maken eerst een selectie van transcripts die overeenkomen met de beoogde inhoud van de chatbot. We zetten vervolgens elke geselecteerde transcript om naar een of meerdere dialoog-paden. Zo’n dialoog-pad ziet eruit als volgt:
- In het begin voegen we de start-knoop toe; deze is altijd dezelfde. Men zou deze “start” of “début” kunnen noemen.
- Elke zin van de gebruiker blijft in principe (letterlijk) staan. Maar deze mag ook herschreven en lichtjes verbeterd worden. Herschrijvingen kunnen aanleiding geven tot verschillende training labels tussen twee opeenvolgende knopen, en dus meerdere dialoog-paden (ook al worden dezelfde knopen bezocht).
- Op elk moment dat de helpdeskmedewerker een antwoord geeft, maken we een dialoog-knoop:
- Het label van de knoop is een professionele, en bondige, samenvatting van hetgeen reeds aan bod is gekomen.
- De output van de knoop is de reactie van de medewerker. Zoals eerder gezegd, als het antwoord te lang is dan kan er ook gewoon een link worden gegeven naar een ander document (zoals de oude FAQ).
- Bij het omzetten van een nieuw transcript, proberen we knopen te hergebruiken uit omzettingen van vorige transcripts, indien die vorige knopen van toepassing zouden zijn. Redenen om knopen te hergebruiken zijn: (1) niet ingaan op elke nuance die eindgebruikers vermelden, ten einde onbelangrijke details te negeren en de dialoog beter te leiden, (2) specifieke antwoorden/outputs hergebruiken en optimaliseren (qua spelling en inhoud). Bij het invoegen van een knoop maken we dus de overweging of we een nieuwe knoop maken of een oude knoop hergebruiken.
Nota bij gebruik van transcripts
We werken best met transcripts (chatlogs) waarin de eindgebruiker telkens enkele korte zinnen (één of twee) schrijft alvorens de medewerker reageert.
- Dit helpt de onderliggende chatbot software bij het matchen van toekomstige zinnetjes van eindgebruikers. Chatbot software maakt vaak gebruik van woorden en woord-volgorden, en het is eenvoudiger om te veralgemenen uit de training data als deze geen lange zinnen bevat. Het blijft in het ideale geval wel mogelijk dat de eindgebruiker nog lange zinnen mag schrijven aan de chatbot, omdat de chatbot in essentie daarin toch op zoek gaat naar de aangeleerde woorden en woord-volgorden.
- Bovendien is deze aanname nuttig bij het opstellen van knopen uit transcripts, waar voor elke knoop een duidelijke samenvatting moet genoteerd worden van wat er reeds gezegd is in het gesprek. Als we vertrekken vanuit een source knoop, en we willen een target knoop maken, is het eenvoudiger om slechts enkele korte zinnen van de eindgebruiker samen te vatten (die werden geschreven na de source knoop).
Mogelijke aanbevelingen
FAQ-chatbots zijn een flexibele manier om met FAQ gegevens om te gaan, wat betekent dat deze chatbots zodanig kunnen opgesteld worden dat ze (1) voorspelbaar en (2) zo correct mogelijk zijn. Deze eigenschappen staan in contrast met andere soorten chatbots, die vooral plezierig en onvoorspelbaar moeten overkomen via humor of icoontjes.
Voorspelbaarheid en correctheid lijken wenselijke eigenschappen voor een eerste generatie chatbots in de context van een overheid.
Technische opmerkingen
- De bovenstaande concepten, rond dialoog-netwerken en context-afhankelijke interpretatie van zinnen, worden goed ondersteund door de chatbot-technologie Api.ai (https://api.ai).
- Het is te verkiezen om correcte spelling te gebruiken in het opstellen van de chatbot zelf, omdat correcte spelling een handig referentiepunt is waarop toekomstige uitbreidingen van data kunnen afgestemd worden. Opgelet: chatbot-technologieën bieden niet altijd ondersteuning voor het omgaan met spellingsfouten. Bijgevolg, om spellingsfouten toe te laten bij de input van eindgebruikers, kan het nodig zijn om automatisch spellingscorrecties te doen op de input alvorens deze door te sturen aan de chatbot.