Een chatbot is een virtuele assistent die automatisch kan antwoorden op vragen of uitspraken. We hebben reeds een vorige blog gemaakt over dit onderwerp. In deze blog gaan we onze ervaringen bespreken rond chatbots die slechts een oppervlakkig gesprek onderhouden met een eindgebruiker.
Alvorens we in details treden, willen we graag nog even de aanpak situeren in een groter geheel. Een eerste belangrijke eigenschap van de aanpak is dat deze manueel is: we moeten handmatig een script opstellen van het gedrag (of de redeneringen) van de chatbot. Dit is een ontwerp-oefening, die meestal in teamvorm wordt uitgevoerd, bijvoorbeeld met een ontwerper en een tester. (Opmerking: We bespreken een alternatief voor de manuele aanpak in het addendum van deze blogpost).
In het vervolg van deze blog gaan we verder met de manuele aanpak, waarbij we de dialoog zelf moeten ontwerpen. De ontwerper zorgt er zelf voor dat de gegenereerde uitspraken passend zijn. Dit is een beproefde methode, die al wordt toegepast sinds het ontstaan van chatbots. Essentieel probeert een dergelijke chatbot bepaalde keywords of combinaties van keywords te herkennen. Echter, een moderne toevoeging aan dit principe is de zogenaamde “natural language processing”, waarbij uit training data wordt geleerd welke keywords belangrijk zijn, zonder dat iemand dit manueel moet programmeren.
In de manuele aanpak, bestaat een mogelijke strategie van de ontwerper uit de volgende deeltaken:
- In samenspraak met eindgebruikers, bepaal de intenties die de eindgebruiker zou willen communiceren aan de chatbot. Deze intenties zou men kunnen beschouwen als een soort commando’s die de chatbot zal verstaan en uitvoeren.
- Voor elke intentie moet training data verzameld worden om de keywords (of combinaties daarvan) te leren die kenmerkend zijn voor die intentie. Voor deze training data volstaan fragmenten of losse zinnen (zonder een bijhorend volledig gesprek).
- Bepaal of bij sommige intenties wedervragen moeten gesteld worden, ofwel om de intentie te verduidelijken ofwel om ontbrekende stukjes informatie op te vragen. Dit leidt tot een ontwerp van dialoog flow, bijvoorbeeld in de vorm van een decision tree.
Er zijn talrijke software platformen beschikbaar waarmee men manueel dialoog kan ontwerpen. Enkele voorbeelden: IBM Watson Conversation, Api.ai, Wit.ai, en recast.ai.
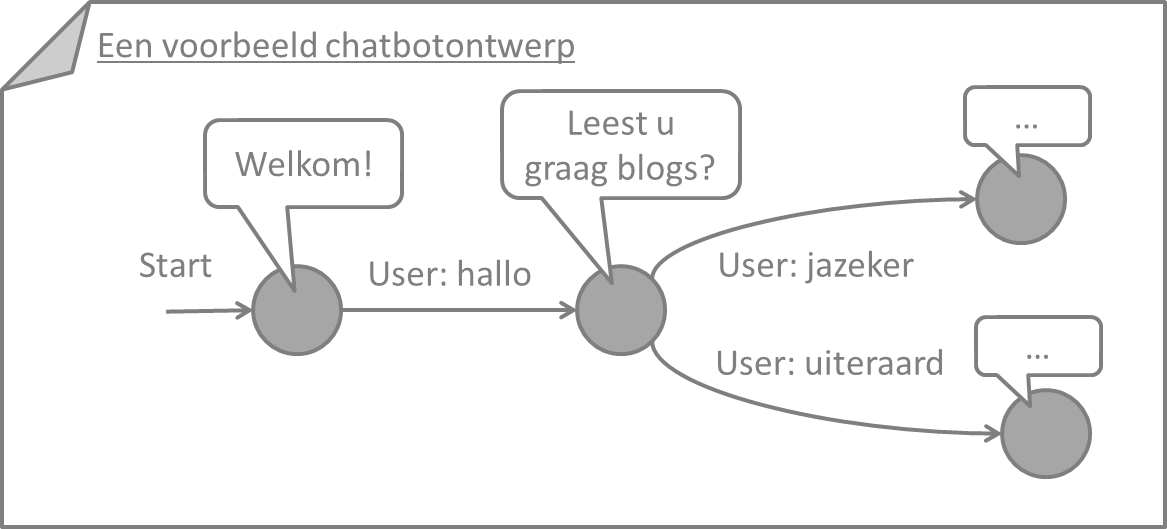
Ondiepe dialoog
In de manuele aanpak tot chatbots, kunnen we een onderscheid maken tussen diepe en ondiepe dialoog. Bij (visuele) inspectie van een decision tree of netwerkstructuur van de dialoog, zou men van ondiepe dialoog kunnen spreken als de chatbot eenduidig een antwoord kan geven na slechts één of twee wedervragen gesteld te hebben (of zelfs geen wedervragen, waarbij intenties meteen duidelijk zijn en kunnen afgehandeld worden).
De technische uitleg en demonstratie van chatbot-platformen gebeurt heel vaak met ondiepe dialoogstructuren. Bijvoorbeeld, IBM Watson Conversation heeft de car demo. Daarin speelt de chatbot de rol van intelligente auto. De gebruiker kan vragen om het licht aan of uit te doen (“turn light on/off”); waarbij geen wedervragen van de chatbot nodig zijn. Een ander commando is de radio aanzetten (“turn radio on”). In het geval van de radio vraagt de chatbot eerst naar het type muziek (met keuze uit een vaste lijst); er is dus één wedervraag nodig. Een ander commando is het rijden naar een restaurant (“find food”); in dat geval zal de chatbot twee wedervragen stellen, om (1) het type gerecht en (2) de voorkeurslocatie van het restaurant te vragen. Bij deze car demo komen de wedervragen van de chatbot telkens overeen met het vragen naar een beperkt aantal parameters, waardoor de diepte van de dialoog beperkt blijft.
Een vorige blogpost bespreekt een methode om diepe dialoog te ontwerpen. Echter, diepe dialogen kunnen een uitdaging vormen om te ontwerpen, en vergen vermoedelijk meerdere design- en test-iteraties. Daarom gaan we in de rest van deze blog onze ervaringen bespreken met het ontwerp van ondiepe dialoog. Het blijkt dat dergelijke chatbots relatief overzichtelijk kunnen zijn, en geen volledig team vereisen om te ontwikkelen.
Acties en context
Alvorens we onze ervaring met het ontwikkelen van ondiepe dialoog kunnen toelichten, hebben we nog een paar extra concepten nodig, namelijk, (1) het uitvoeren van acties en (2) context.
Een veelvoorkomend principe bij chatbot-platformen is het koppelen van acties aan intenties. Men herkent dan niet alleen welke intentie er werd opgegeven door de gebruiker (wat nodig is om de dialoog-flow te sturen), maar men roept tegelijk een functie aan op een losstaand systeem. De technische manier om een dergelijke functie-oproep te implementeren gebeurt via een zogenaamde “webhook”, wat een webserver is die data ontvangt van het chatbotplatform. De doorgestuurde data bestaat uit twee delen:
- De naam van de actie die op de webserver moet uitgevoerd worden, en
- De parameters die daarbij nodig zijn.
In de car demo van IBM Watson Conversation, in de intentie van de radio aanzetten, zou een gekoppelde actie bijvoorbeeld kunnen zijn: “play-music”, met een genre-parameter.
Om dergelijke actie-koppelingen mogelijk te maken, gaat de chatbot parameters bijhouden in zijn werkgeheugen. Men kan dit werkgeheugen zien als een verzameling van key-value paren. Elke parameter heeft een unieke naam (de key) en een bijhorende waarde. In het vakjargon duidt men deze verzameling van key-value paren aan als de context (bijvoorbeeld bij Watson Conversation en api.ai).
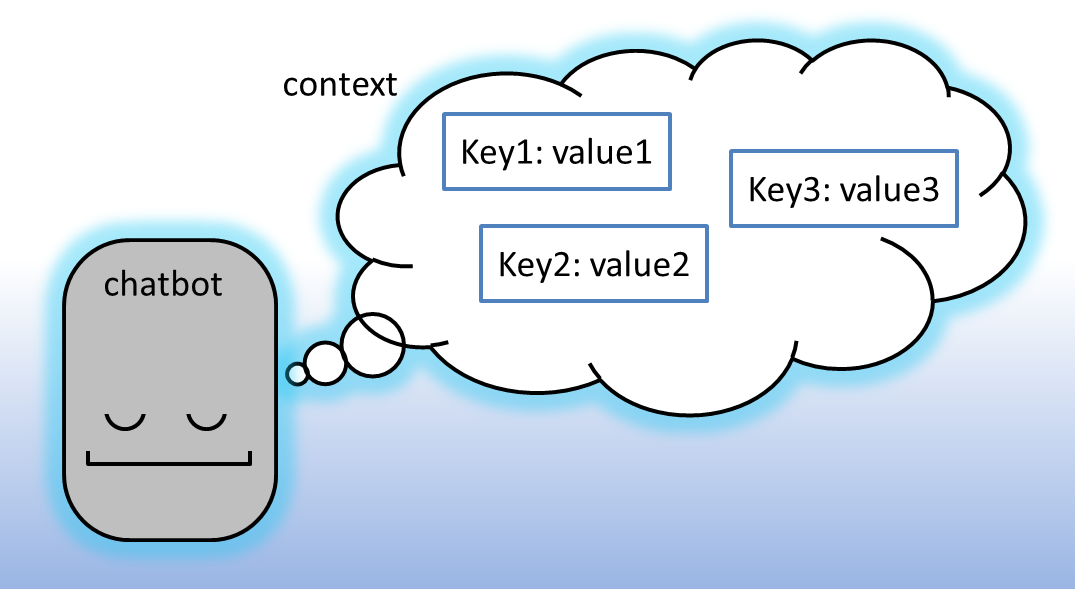
Vaak laten de chatbot-platformen die acties ondersteunen ook toe om de context aan te passen. Zo wordt het via chat mogelijk voor de eindgebruiker om key-value paren te toe voegen, te verwijderen, of aan te passen. De eindgebruiker kan dit ervaren als flexibel omdat de volgorde van de aanpassingen soms minder van belang is; vooral belangrijk is welke key-value pairs de chatbot in zijn context heeft.
Opmerking
Het koppelen van acties aan intenties lijkt op standaard functie-oproepen met parameters in programmeertalen. Dit idee past dus vrij goed in de denkwereld van programmeurs.
Dimona case
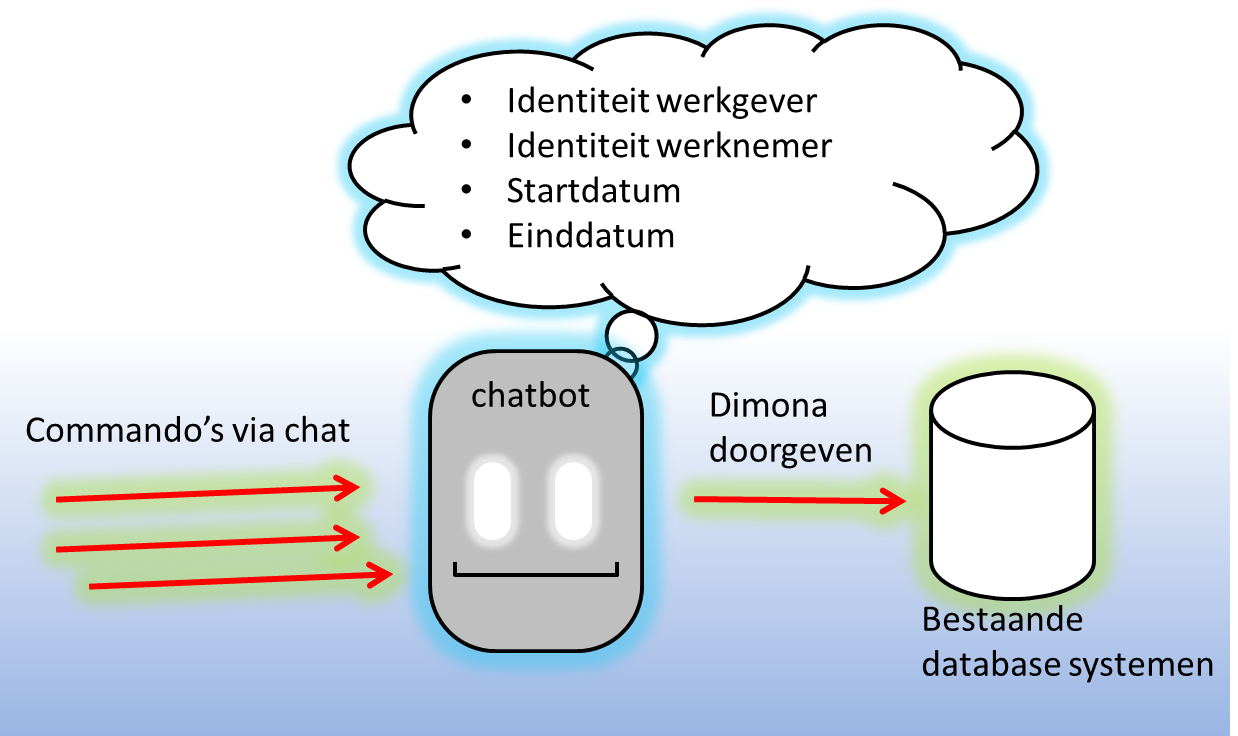
In de Belgische sociale zekerheid zijn bepaalde werkgevers verplicht om een onmiddellijke aangifte te doen van de tewerkstelling van hun werknemers. De naam van een dergelijke aangifte is Dimona, een afkorting van “Déclaration Immédiate/Onmiddellijke Aangifte”. Het begin van de tewerkstelling wordt gemeld via een Dimona-IN, en het aflopen van de tewerkstelling gebeurt met een Dimona-OUT. In beide gevallen zijn drie belangrijke gegevens nodig, namelijk:
- Een identificerend nummer voor de werkgever; we zullen voor de eenvoud veronderstellen dat dit altijd het RSZ-nummer is van de werkgever.
- De identiteit voor de werknemer; we zullen daartoe het rijksregisternummer veronderstellen.
- Een datum. Bij een Dimona-IN hoort een startdatum, en bij een Dimona-OUT een einddatum.
Men zou in principe een chatbot kunnen maken waarmee werkgevers Dimona aangiften kunnen doen, gebaseerd op een eenvoudige dialoog. Voor elk type Dimona aangifte dat de werkgever wil uitvoeren, verstrekt de werkgever de benodigde informatie aan de chatbot. De chatbot begeleidt dit proces nauwgezet door ontbrekende informatie op te vragen. Daartoe volstaat een ondiepe dialoog: de werkgever geeft een commando om een aangifte te doen van type “in” of “out”, en de chatbot moet enkel vragen om ontbrekende gegevens aan te vullen (bijvoorbeeld als de werkgever nog geen rijksregisternummer van de werknemer heeft opgegeven).
Om het verband te leggen naar de bovenstaande algemene uitleg van key-value pairs, bestaat het werkgeheugen van de Dimona chatbot uit:
- het RSZ-nummer van de werkgever,
- het rijksregisternummer van de werknemer,
- een startdatum (enkel nuttig bij Dimona-In), en
- een einddatum (enkel nuttig bij Dimona-Out).
De werkgever kan de gegevens van dit werkgeheugen aanpassen in een willekeurige volgorde. Bijvoorbeeld, men kan eerst het rijksregisternummer geven en pas daarna een datum, of omgekeerd. Hierdoor moet de werkgever enkel de intentionele commando’s kennen van de chatbot, en geen strikte volgorde daarvan.
We hebben dit ontwerp kunnen implementeren met api.ai, maar het zou in principe ook kunnen gebeuren met IBM Watson Conversation.
Conclusie
Als een praktische use case toelaat om de dialoog op een ondiepe manier uit te werken, kan men overwegen om manueel chatbots te ontwikkelen. Een aantal eigenschappen van het manuele ontwerp van ondiepe dialoogstructuren zijn:
- Vele chatbot-platformen ondersteunen dit.
- De overzichtelijkheid ten gevolge van de ondiepe dialoogstructuur maakt het mogelijk om een chatbot te ontwikkelen met een klein team en bescheiden middelen. De technische invalshoek, waarbij intenties worden gezien als functieoproepen (“function calls”) met parameters, past in de denkwereld van programmeurs. Hierdoor kan bestaand IT personeel worden ingeschakeld om chatbots te helpen ontwikkelen.
- Het is relatief eenvoudig om nieuwe intenties toe te voegen, althans als de nieuwe intentie voldoende verschilt van reeds bestaande intenties qua training data.
Echter, zoals opgemerkt in een vorige blog, hebben chatbot-platformen meestal geen ondersteuning voor spellingsfouten. Ofwel wordt van de eindgebruiker vereist dat hij correcte spelling gebruikt, ofwel moet er een automatische correctie gebeuren op voorhand (waarbij men moet opletten om geen verkeerde vervangingen te doen).
Addendum: semi-automatische aanpak
Ter volledigheid merken we op dat er naast de manuele aanpak ook een semi-automatische aanpak bestaat. Bij een semi-automatische oplossing wordt geleerd uit gespreksdata welke uitspraken van eindgebruikers belangrijk of frequent zijn, en bovendien wat een gepast antwoord daarop zou kunnen zijn. We vermelden graag het woordje “semi” omdat men relevante gespreksdata moet verzamelen of opzoeken (vaak een niet-geringe inspanning).
Een voorbeeld van een semi-automatische chatbot is Chatterbot. De training data bestaat uit (zin, antwoord)-koppels. Telkens als een eindgebruiker iets schrijft wordt de input vergeleken met de zinnetjes in de data; het antwoord bij het best passende zinnetje wordt teruggegeven. De voortzetting van de dialoog gebeurt eerder op een adhoc manier, waardoor weinig controle is op de kwaliteit van het gesprek. Voor chatbots in de context van overheden is het evenwel belangrijk om correct en voorspelbaar te zijn, waardoor we voorlopig minder geïnteresseerd zijn in dergelijke adhoc chatbots.
Ter volledigheid merken we op dat een nieuwe categorie van een semi-automatische chatbots wordt vertegenwoordigd door Amelia van IpSoft. Dit product is gebaseerd op principes van het menselijk brein, en behoort tot de state of the art. De training bestaat uit het toelaten aan Amelia om echte chatconversaties mee te lezen, tussen bijvoorbeeld een medewerker en een klant. Geleidelijk leert Amelia hoe een gesprek moet opgebouwd worden, en welke acties zij mag (of moet) ondernemen. Op dat moment kan zij zelf in contact treden met klanten. Dit product lijkt voorlopig vrij uniek te zijn op de markt. We kunnen echter nog niet uitweiden over onderwerp, omdat de principes en kosten-baten verhoudingen van Amelia ons nog niet bekend zijn.