Tegenwoordig lezen we veel nieuws over doorbraken in artificiële intelligentie (AI), zoals zelfrijdende auto’s, spraakherkenning, automatische vertalingen, enz. Deze ontwikkelingen zouden een overheid kunnen motiveren om AI te bestuderen. Tegenwoordig overheerst nog de pragmatische invalshoek, waarbij we een specifieke AI-oplossing moeten uitkiezen voor elk individueel probleem.
Men zou bijvoorbeeld inzichten kunnen afleiden uit gegevens van overheden. Het is nuttig om dit proces uit te voeren op een computer want we zouden liever niet manueel grote hoeveelheden gegevens lezen om de interessante patronen en verbanden af te leiden. Bovendien valt een inzicht misschien pas op als de gegevens worden gelezen in de goede volgorde, bijvoorbeeld door een aantal stukjes informatie te lezen vlak na elkaar die allemaal eenzelfde interessante patroon bevatten. Men weet typisch niet op voorhand welke patronen aanwezig zijn, dus kan men de gegevens niet sorteren om de patronen er manueel uit te halen. Het vinden van patronen laten we daarom best door een computer gebeuren, die vele mogelijkheden kan overwegen.
 In deze blog bespreken we een algemeen idee gebaseerd op principes uit Data Mining. We bespreken concreet het principe van regels. Een regel van de vorm A → B drukt de voorspelling uit dat patroon B voorkomt als patroon A wordt waargenomen. We lezen de regel dus als volgt: “als A dan B”. Dergelijke voorspellingen kunnen gebruikt worden om suggesties te doen, om anomalieën te detecteren, en om automatisch beslissingen te nemen.
In deze blog bespreken we een algemeen idee gebaseerd op principes uit Data Mining. We bespreken concreet het principe van regels. Een regel van de vorm A → B drukt de voorspelling uit dat patroon B voorkomt als patroon A wordt waargenomen. We lezen de regel dus als volgt: “als A dan B”. Dergelijke voorspellingen kunnen gebruikt worden om suggesties te doen, om anomalieën te detecteren, en om automatisch beslissingen te nemen.
We vertrekken vanuit de observatie dat veel gegevens van een overheid in gestructureerde vorm worden opgeslagen. Voorbeelden van dergelijke gegevens zijn:
- de data waarop de identiteitskaart van een persoon is uitgegeven,
- de voorgaande en huidige domicilieadressen van elke burger,
- de hoeveelheid belasting die elke burger heeft betaald per jaar,
- de bijdragen aan de sociale zekerheid die elke werkgever heeft betaald per kwartaal.
Gestructureerde gegevens staan in contrast met vrije tekst, afbeeldingen, video’s, geluid, enz.
Patronen en regels
In het vervolg nemen we voor de eenvoud aan dat elke gestructureerde gegevensbron conceptueel bestaat uit een verzameling van entiteiten, zoals mensen, gebouwen, bedrijven, enz. We bekijken elke entiteit als een verzameling van attributen, waarbij elk attribuut een key-value paar is.
We definiëren een patroon als een combinatie van constraints op individuele attributen. De “support” van een patroon X is het aantal voorkomens (of de relatieve frequentie) van X over alle entiteiten heen. Ter illustratie beschouwen we de volgende tabel:
| Persoon_id | Leeftijd | Straat | Gebied_code | Taal |
| 1 | 30 | Straat A | 3000 | Nederlands |
| 2 | 40 | Straat B | 3000 | Frans |
| 3 | 50 | Straat B | 3000 | Frans |
| 4 | 60 | Straat C | 5000 | Frans |
Elke rij stelt een entiteit voor, in dit geval een persoon. Voorbeelden van patronen zijn:
- Straat = “Straat A”;
- Leeftijd > 35;
- Leeftijd > 35 en Gebied_code = 3000.
De support van deze patronen zijn, respectievelijk: 1 rij, 3 rijen, en 2 rijen.
Als we vanuit de gestructureerde gegevens zouden kunnen leren welke patronen vaak samengaan, kunnen we het ene patroon voorspellen na de observatie van een ander patroon. In het bijzonder zouden we regels kunnen leren van de vorm A → B, waar A en B patronen zijn. Deze regel zegt dat als we patroon A zien dat we dan patroon B verwachten. Bij elke regel hoort een betrouwbaarheidsscore, gedefinieerd als volgt:
De betrouwbaarheid van A → B is de support van het gecombineerde patroon A + B gedeeld door de support van patroon A.
Merk op dat het gecombineerde patroon A + B typisch strenger is dan patroon A, en daardoor enkel kan aanwezig zijn in de entiteiten die reeds voldoen aan patroon A. Daardoor is de support van A + B kleiner of gelijk aan de support van A. Intuïtief bekeken, drukt de betrouwbaarheid uit hoe zeker we zijn om patroon B te voorspellen als we patroon A waarnemen.
In het bovenstaande voorbeeld, zouden we de volgende regels kunnen afleiden uit de gegevens:
- Met 2/2 betrouwbaarheid (100%), als Straat= “Straat B” en Gebied_code = 3000 dan (→) Taal = “Frans”;
- Met 2/3 betrouwbaarheid (66%), als Gebied_code = 3000 dan (→) Taal = “Frans”.
Met regels zouden we de volgende toepassingen kunnen uitwerken:
- Men kan waarden voor een attribuut suggereren op basis van andere attributen. Dit zou men decision support kunnen noemen.
- Wanneer een entiteit wordt aangemaakt (of gewijzigd), kan men controleren dat bepaalde verwachtingen rond de attributen voldaan zijn. Anders gezegd: men kan verwachtingen gebruiken als beperkingen. Schendingen van verwachtingen kunnen gemeld worden als anomalieën.
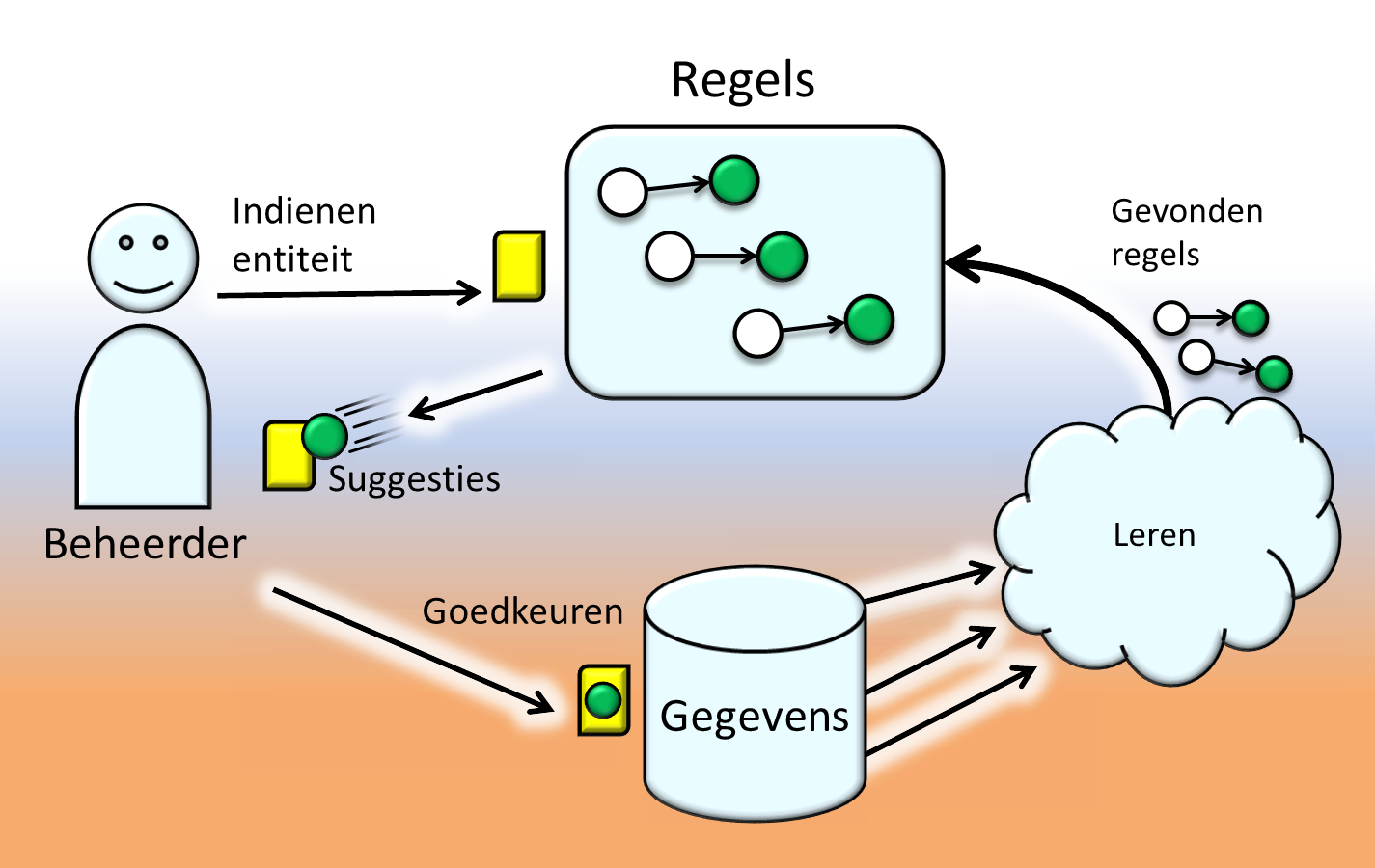
Beide mechanismen zijn gebaseerd op voorspellingen, zoals we hieronder zullen toelichten. Met kennis van de regel A → B kunnen we suggereren dat patroon B kan toegepast worden nadat patroon A wordt waargenomen. Als een beheerder verantwoordelijk blijft voor de uiteindelijke beslissing, dan bekijken we regels enkel als een suggestie-mechanisme. In de context van anomalie-detectie kunnen we een melding sturen naar de beheerder wanneer een voorspelling wordt geschonden bij een entiteit. Ter illustratie:
- Stel dat de bovenstaande voorbeeld-gegevens van personen uit een enquête zouden komen, en dat mensen soms vergeten hun taal in te vullen. In dat geval zouden we kunnen overwegen om een suggestie-mechanisme aan te bieden dat de taal afleidt uit de straat en de gebiedscode. Natuurlijk hangt het af van de toepassing of de voorgestelde waarden aanvaardbare plaatsvervangers zijn, of dat meer echte gegevens moeten verzameld worden.
- Als een voorbeeld van anomalie-detectie, stel dat we proberen om de volgende entiteit toe te voegen aan de tabel: Staat= “Straat B”, Gebied_code = “3000”, en Taal = “Nederlands”. De eerste regel hierboven zou dan geschonden zijn. Als de betrouwbaarheid van een geschonden regel hoog is, zoals hier (100%), dan zou het nuttig kunnen zijn om de anomalie te melden aan een beheerder. Afhankelijk van de toepassing, zou anomalie-detectie kunnen helpen bij het vinden van administratieve fouten of problemen met entiteiten.
Als een regel voldoende wordt vertrouwd, en de patronen erin voldoende concreet zijn, dan kan de regel ook automatisch worden uitgevoerd om gegevens aan te vullen of te veranderen. Daarom zouden regels een manier kunnen zijn om automatisering te bekomen.
Toepasbaarheid
Men zou regels kunnen leren uit verschillende vormen van gestructureerde gegevens zoals:
- Standaard tabellen zoals in het bovenstaande voorbeeld.
- XML of JSON gegevens wanneer de diepte van deze structureren op voorhand begrensd is.
- Doorlopende “streams” waar gestructureerde formaten worden gebruikt om individuele boodschappen voor te stellen. Het leren van regels over streams kan real-time aanvulling van gegevens of anomalie-detectie mogelijk maken.
Nuttige eigenschappen
We bespreken enkele nuttige eigenschappen van het automatisch afleiden van regels:
| Eigenschap | Uitleg |
| Geen bijkomende training gegevens nodig | Regels kunnen afgeleid worden uit bestaande gestructureerde bronnen omdat we op zoek gaan naar patronen die daar ingebed zitten en de verbanden tussen die patronen. Het leerproces kan daarom op de achtergrond gebeuren, zonder expliciete feedback te hoeven vragen aan beheerders. |
| Documentatie-vorming | Regels kunnen bepaalde beslissingen motiveren. Immers, als een beslissing gebaseerd is op een regel met hoge betrouwbaarheid, dan kunnen we voorgaande entiteiten bekijken waarop die regel van toepassing was. (Dat zijn de entiteiten die de betrouwbaarheidsscore hebben bepaald.) Het is hierbij niet altijd nodig dat de regel op zichzelf leesbaar is, want deze zou heel lang kunnen zijn. De regel dient eerder als een middel om verbanden te leggen tussen entiteiten. |
| Aanpasbaarheid | Individuele regels kunnen uitgeschakeld worden indien de voorspellingen zinloos zijn. De betrouwbaarheidsscores zouden ook frequent moeten herrekend worden, om de laatste veranderingen te volgen in de gegevens. Gebruikers kunnen numerieke grenzen aanpassen om te zeggen vanaf welke betrouwbaarheidsscore een regel mag gebruikt worden. |
| Onafhankelijkheid van tools | Regels zijn zelf in principe objectieve gegevens. Vanuit dat oogpunt zouden regels die gevonden zijn door de ene tool combineerbaar moeten zijn met regels die worden gevonden door een andere tool. Anders geformuleerd: het belangrijkste is welke regels worden gevonden en niet welke techniek daarvoor werd gebruikt. In principe mogen experts ook nog manueel regels toevoegen (en automatisch de betrouwbaarheid daarvan laten berekenen.) |
Aanvullende opmerkingen
Verwante onderzoeksgebieden
We geven enkele wetenschappelijke onderzoeksgebieden verwant aan het thema in deze blog (Engelstalige terminologie):
- association rule mining,
- inductive logic programming,
- knowledge representation and reasoning.
Slim gokken
![]()
In het algemeen zijn er teveel mogelijke patronen en regels om systematisch op te sommen of op te slaan. Maar men kan patronen en regels proberen slim te gokken. Het is in principe ook mogelijk om variaties van bestaande regels te verkennen, ten einde
- meer algemene regels te vinden;
- of om regels met lage betrouwbaarheid om te vormen naar regels met hogere betrouwbaarheid, bijvoorbeeld door een meer specifiek patroon te gebruiken in de preconditie.
Trade-off: betrouwbaarheid en support
Er zit een trade-off tussen betrouwbaarheid en support. Regels gebaseerd op gedetailleerde patronen zouden heel betrouwbaar kunnen zijn, maar helaas met een te kleine support om statistisch significant te zijn. Een kleine support duidt immers op zeldzaamheid van het patroon. Daarom zou men aandacht kunnen besteden aan representaties van patronen die zorgen voor een grotere support. Hulpmiddelen daarvoor zijn:
- beperkingen op getal-attributen kan men weergeven met intervallen (en niet met concrete waarden);
- gebruik maken van de NOT operator (“niet”), om te zeggen dat een attribuut niet een bepaalde waarde heeft;
- gebruik maken van de OR-operator om meerdere specifieke patronen te bundelen.
Bijvoorbeeld, door te zeggen NOT Straat = “Straat Z”, laten we toe dat het straat-attribuut zeer veel waarden kan aannemen, zolang het maar niet “Straat Z” is, zoals: “Straat A”, “Straat B”, “Straat C”, en tal van andere mogelijke waarden. De support van het patroon NOT Straat = “Straat Z” kan daarom heel hoog zijn in een concrete tabel.
We geven nu een voorbeeld van het gebruik van de OR-operator. Beschouw het volgende patroon, waarbij we voor de leesbaarheid telkens een komma schrijven om “and” voor te stellen:
P= (a OR b), (u OR v), (x OR y).
Patroon P vervangt de volgende verzameling van specifieke patronen waarin enkel de AND-operator wordt gebruikt (ook weer vervangen door komma):
- a, u, x
- a, u, y
- a, v, x,
- a, v, y,
- b, u, x,
- b, u, y
- b, v, x,
- b, v, y.
De support van P kan veel hoger zijn dan de support van de individuele AND-patronen. Dit voorbeeld illustreert bovendien dat een representatie met een geneste OR-operator efficiënter kan zijn voor de opslag van de patronen en regels.
Leave a Reply