 Het opdelen van een applicatie in apart uitrolbare componenten is reeds lang een kwestie van relatief grote “tiers”. Van zuiver monolithische applicaties zijn we gedurende de voorbije decennia langzaamaan geëvolueerd, via 2-tier en 3-tier applicaties, naar N-tier. Tegenwoordig neemt deze evolutie extremere vormen aan: applicaties bestaan uit steeds meer en steeds kleinere componenten, die uiteindelijk tot microservices evolueren.
Het opdelen van een applicatie in apart uitrolbare componenten is reeds lang een kwestie van relatief grote “tiers”. Van zuiver monolithische applicaties zijn we gedurende de voorbije decennia langzaamaan geëvolueerd, via 2-tier en 3-tier applicaties, naar N-tier. Tegenwoordig neemt deze evolutie extremere vormen aan: applicaties bestaan uit steeds meer en steeds kleinere componenten, die uiteindelijk tot microservices evolueren.
Op termijn kan deze architecturale stijl de grenzen tussen verschillende applicaties gaan vervagen, om ze te transformeren tot een applicatie-ecosysteem bestaande uit vele herbruikbare, onafhankelijk uitrolbare en afzonderlijk schaalbare componenten.
De Geschiedenis van “Tiers”
De meest traditionele applicaties zijn monolithisch: één programma dat al zijn functies vervult zonder afhankelijk te zijn van externe hulpmiddelen. Lang geleden werden de meeste applicaties op deze manier gebouwd, en vandaag zijn heel wat desktop applicaties hier nog steeds voorbeelden van. Met de opkomst van netwerken en Database Management Systemen (DBMS), werd echter voor vele applicaties een meer component-gebaseerde uitrol nodig. Voor een gedistribueerde applicatie werd het b.v. nodig om een “client” en een “server” of “backend” te hebben, om op die manier een gebruiker toe te laten de applicatie op een andere plaats (op een andere machine) te gebruiken dan de plaats waar de kern van de applicaties zich bevindt (meestal ook met het doel om meerdere gebruikers gelijktijdig van de applicatie gebruik te kunnen laten maken). Dit wordt de “client-server” of “2-tier” architectuur genoemd. Voor applicaties, die aan geavanceerde I/O doen, werd het daarnaast ook noodzakelijk om de verantwoordelijkheid hiervoor bij een DBMS te leggen. Dit systeem wordt dan de “data tier” van de applicatie.
Uiteraard leidden deze twee architecturen reeds snel tot de zogenaamde “3-tier” architectuur, met een client tier en een backend die werd gesplitst in een tier voor de business logic en een data tier. Tegenwoordig zijn er vaak nog meer opsplitsingen mogelijk. In de context van web-applicaties zal men b.v. de client tier nog in twee delen splitsen: de eigenlijke client in de browser, en een “web tier” om de client via het web te kunnen aanbieden. Men zou deze laatste zelfs nog kunnen opdelen in aparte servers voor het statische en dynamische gedeelte van de applicatie. Ook wordt het mogelijk dat een applicatie meerdere verschillende databronnen gebruikt, of dat haar business logica verdeeld geraakt over meerdere tiers (b.v. application logic vs domain logic). Langzaamaan verdwijnt dan ook de notie van tiers (waarbij men een min of meer hiërarchische en lineaire relatie verwacht tussen de componenten), om plaats te maken voor een flexibeler systeem, waarbij de communicatie flexibeler vormen kan aannemen…
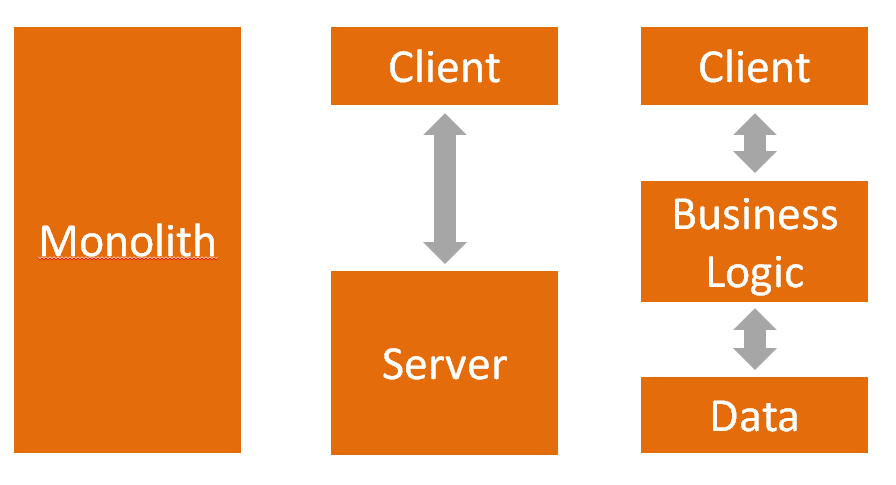
Van links naar rechts: een monolithische applicatie, een 2-tier, en een 3-tier applicatie.
Tiers of Lagen?
De opdeling in tiers klinkt allicht bekend in de oren voor wie reeds met software architectuur bezig is, en doet ook denken aan de opdeling van een applicatie in lagen (“layers”). De beide termen, tiers en layers, worden soms zelfs als synoniemen beschouwd (zuiver taalkundig zijn ze dat ook, en in het Nederlands kunnen we ze beide vertalen als “lagen“). Dit is logisch: er is een grote similariteit tussen deze beide concepten, en bijgevolg is er dus enige verwarring aanwezig.
Lagen voorzien in een logische scheiding binnen de architectuur van een applicatie, waarbij het zaak is om tussen deze lagen, die functioneel gezien zo coherent mogelijk moeten zijn, een zo groot mogelijke onderlinge onafhankelijkheid te creëren (het zogenaamde “loskoppelen“). Ze hebben eerder als doel om functionele belangen (user interface (UI), applicatielogica, business logica, data access, etc.) gescheiden te houden en de applicatie aldus makkelijker onderhoudbaar te maken op lange termijn, doordat deze belangen apart benaderd kunnen worden. Tiers daarentegen, zijn fysiek gescheiden onderdelen van een applicatie, die apart van elkaar worden ontplooid, waardoor ze niet alleen het aparte onderhoud en de aparte ontwikkeling verder doortrekken, maar ook apart hergebruiken en schalen mogelijk maken.
De verwarring tussen de beide concepten ontstaat allicht omdat de logische layers in de praktijk zeer vaak corresponderen met de fysieke tiers: de UI zit in de client tier, de business logica zit in de logic tier, en de database-laag komt overeen met de data tier. De scheiding in losgekoppelde lagen is daarnaast de ideale manier om ervoor te zorgen dat tiers los van elkaar kunnen worden gedeployed. Daarenboven wordt het onderscheid ook vervaagd in de context van de Cloud: Tiers zijn dan wel fysiek gescheiden, maar door het gebruik van Cloud-technologie (IaaS of PaaS) kunnen ze evenwel worden gehost op dezelfde fysieke of zelfs virtuele machine. Ze zouden eenvoudig in verschillende Containers kunnen worden geplaatst (zij het JEE, Docker of andere containers).
Om te besluiten: layers vormen dus de bouwstenen van een applicatie op een logische manier, en beïnvloeden sterk de architectuur en het design ervan. Tiers, op hun beurt, definiëren de opdeling van een applicatie in onafhankelijk uitrolbare componenten. Ze hebben ook een sterke impact op de architectuur, maar eerder op het niveau van de interacties tussen de applicatie en andere systemen binnen een groter geheel, en op het niveau van de infrastructuur. Tiers kunnen moeilijk zonder layers: het loskoppelen van delen van de applicatie is nodig om ze apart te kunnen uitrollen. Beide zijn onontbeerlijk om de complexiteit van een applicatie in beheersbare blokken op te delen.
Richting Microservices
Over de interessante evoluties binnen applicatie-architectuur en lagen, kunnen we in de toekomst nog een blog schrijven. Vandaag ligt de focus op tiers, en hoe het opsplitsen van een applicatie in componenten en diensten verregaande gevolgen kunnen hebben voor applicatie-ecosystemen.
Ik heb het reeds in verscheidene blogs over applicatie-ecosystemen gehad, maar nagelaten het concept eenduidig te definiëren. Bij deze dan een poging tot definitie:
Een ecosysteem van applicaties is een groep applicaties (en gerelateerde IT entiteiten) die werken rond een gelijkaardig business domein, of die toebehoren aan eenzelfde organizatie (of beide). Soms betreft het zelfs groepen van applicaties die rond verschillende maar gerelateerde business domeinen werken. Typisch verwerken ze dezelfde of sterk gerelateerde gegevens, en vrij vaak interageren ze ook met elkaar, en/of worden ze gebruikt door dezelfde groep van eindgebruikers.
Hieruit volgt dat binnen een applicatie-ecosysteem er een groot potentieel (!) bestaat voor hergebruik. Of dit potentieel effectief wordt gehaald, hangt sterk af van gemaakte keuzes betreffende enterprise, applicatie en systeem-architectuur.
Een kritiek die is komen te ontstaan op de N-tier architectuur, is dat een applicatie nog steeds te geïsoleerd en self-contained is: alle business-logica zit vaak in één tier, alle persistentie-logica in een andere, etc. Men zou zelfs kunnen zeggen dat we de monolithische applicatie hebben vervangen door monolithische tiers! En dit terwijl applicaties steeds complexer worden en verregaandere behoeften hebben, zoals de integratie van business rules, taakbeheer en workflows; allemaal zaken die zo complex zijn, dat ze al een toepassing op zichzelf kunnen vormen.
Service Oriented Architecture (SOA) is een stap in de goede richting, maar historisch gezien richt deze methodiek zich op interacties tussen verschillende applicaties, binnen het ruimere opzicht van enterprise architectuur. Microservices nemen de ideeën van N-tier en SOA samen, en drijven ze naar een nieuw summum: elke aparte applicatie wordt nu beschouwd als zijn eigen mini-ecosysteem van onafhankelijk uitrolbare diensten, zich elk focussend op een verschillende business capabiliteit, zo klein gemaakt als maar kan (vandaar “micro”), en met zo min mogelijk gecentraliseerde orchestratie. Meestal heeft elke microservice – indien deze nood heeft aan persistentie – ook zijn eigen database (of een ander soort persistentiesysteem), die enkel en alleen voor deze microservice wordt ingeschakeld.
Deze stijl verhoogt sterk de Agility van SOA: de kleinere services kunnen meer cohesief op zichzelf staan, en intern zijn ze meestal ook eenvoudiger dan volledige applicaties typisch zijn. Daarnaast kunnen onderhoud en evolutie van alle microservices apart van elkaar worden beheerd. Dit alles maakt dat deze aparte microservices makkelijker te bouwen en onderhouden zijn dan de volledige applicatie (uiteraard kruipt er wel enig werk in het op een goede manier opdelen van de applicatie in verschillende microservices). Men kan zelfs zo ver gaan als volledige microservices te vervangen door nieuwere en betere: indien ze klein genoeg zijn, kan de kost gerechtvaardigd zijn om een dergelijk stuk software – huiver – weg te gooien.
Daarnaast wordt het voor ontwikkelteams ook mogelijk om flexibeler te kiezen welke technologie, welke talen en welke raamwerken ze zullen gebruiken om hun specifieke microservice zo optimaal mogelijk te implementeren. Ze zouden Java, Node.js, of eender welke andere technologie kunnen kiezen, zo lang ze maar overeenkomen over een gestandaardiseerd communicatiekanaal. Dit kanaal, op zijn beurt, zien we meer en meer evolueren richting RESTful APIs: een robuuste de facto standaard.
Deze evolutie wordt verder nog versterkt door de opkomst van Container technologie: deze zijn de infrastructuurplatformen van de toekomst (of zelfs al van vandaag), en zijn “lichter” en makkelijker inzetbaar dan virtuele machines, waardoor het kosten-effectief wordt om een groter aantal kleinere services te hosten i.p.v. een klein aantal zwaardere applicatie(s)(-tiers). De beide technologische evoluties werken op die manier hand in hand om de schaalbaarheid van applicaties te verbeteren op een fijnmazig niveau: elke microservice kan onafhankelijk van de andere worden geschaald, en via containers kan er voor worden gezorgd dat de eronder liggende infrastructuur, gebruikt door het geheel aan services, een betere match vormt met het evoluerend verbruikspatroon.
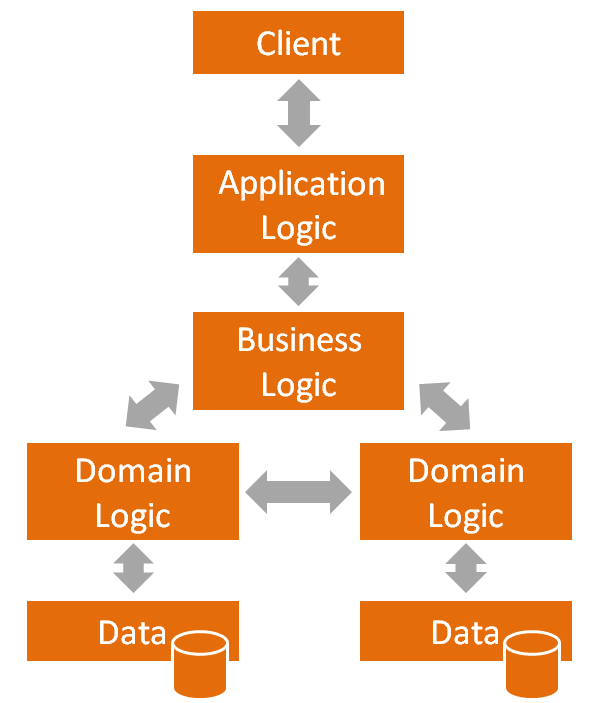
Een N-tier applicatie die evolueert richting microservices: de applicatielogica zit in een aparte “tier”, of nog: de applicatielogica wordt aan de client aangeboden als een aparte service. Deze maakt op zijn beurt gebruik van een business logic tier, of nog: van business logic services. Onderaan staan dan de tiers of diensten die de entiteiten van de business (het domein) ondersteunen en persisteren.
Microservices maken het mogelijk voor een organizatie om meer Agile te werken en cross-functionele teams te bouwen, gefocust op business capabiliteiten, i.p.v. teams gefocusd op specifieke IT functies (UI specialisten, middleware specialisten, DBA’s, …). Wanneer een applicatie monolithisch wordt gebouwd, is er vaak veel heen-en-weer “gedoe'” tussen verschillende teams nodig om cross-functionele zaken te implementeren, met het gevaar dat business logica doorsijpelt op plaatsen waar deze niet hoort te zitten (b.v. in de UI of de data laag). Een meer expliciete scheiding van de applicatie in service componenten maakt de grenzen duidelijker, zowel tussen de microservices als tussen de teams die ze implementeren, waardoor er meer onafhankelijkheid in het implementatieproces kan worden gestopt. Een meer servicegericht model van samenwerking wordt op deze manier mogelijk: teams worden klant van elkaar omdat hun producten klant zijn van elkaar.
Ecosystemen van Services
Binnen een applicatie-ecosysteem van enige omvang, is er altijd al op vele niveau’s de nood geweest aan integraties. Met een beetje geluk waren deze integraties gekend wanneer een applicatie werd gebouwd, maar vaak is het echter zo dat de nood aan integratie achteraf ontstaat, wanneer een applicatie reeds enige tijd in productie is. Integraties komen ook voor op het UI niveau, waar ze leiden tot portaal technologie en integration-at-the-glass. Of ze komen voor op het niveau van de data, wat vaak tot gevolg heeft dat een database wordt gedeeld tussen verschillende applicaties. Er zijn reeds verdienstelijke pogingen gedaan om al deze integraties op te vangen via middleware, maar zelfs de alomtegenwoordige Enterprise Service Bus (ESB) is geen panacee.
We kunnen nooit vrij zijn van de onverwachtheid van sommige integratie-behoeftes, maar microservices kunnen een aantal van de moeilijkheden helpen verminderen. Enerzijds komt dit door de standaardisatie van de communicatie tussen microservices. Anderzijds doordat business capabiliteiten dankzij deze architectuur worden opgedeeld in kleinere stukken, wordt het makkelijker om een component te gaan hergebruiken in een andere applicatie, en deze apart te schalen indien hij daardoor zwaarder belast wordt. Bovendien kunnen we applicaties op zo’n manier opsplitsen, dat hergebruik wordt aangemoedigd: er zullen enerzijds applicatiespecifieke microservices deel uitmaken van een applicatie, maar anderzijds zullen er ook microservices zijn die een bepaalde business problematiek of capabiliteit ondersteunen, die onafhankelijk is van applicatielogica; deze laatste zijn vaak in meerdere toepassingen nuttig. Verder kunnen we ook nog microservices hebben die verantwoordelijk zijn voor een bepaald deel van de persistentie-behoeften van de applicatie. Services zo klein dat ze data betreffen die ook door andere applicaties gebruikt wordt. Deze “data services” zullen de poortwachters zijn van de data: zij encapsuleren de databases (of maken deel uit van een algemenere Data as a Service aanpak) en hebben meerdere applicaties als klant.
Uiteindelijk leidt deze opdeling in services tot een heel ander ecosysteem: niet één van monolithische of tiered applicaties, maar één van intergeconnecteerde microservices. En deze grote groep microservices kan dan “ten dienste” staan van specifieke “client”-componenten die een UI bevatten en dus de gebruikers toelaten dit ecosysteem te gebruiken op verschillende manieren. Dezelfde achterliggende dienst kan bijvoorbeeld een rol spelen binnen een web-toepassing, maar ook in een mobiele toepassing.
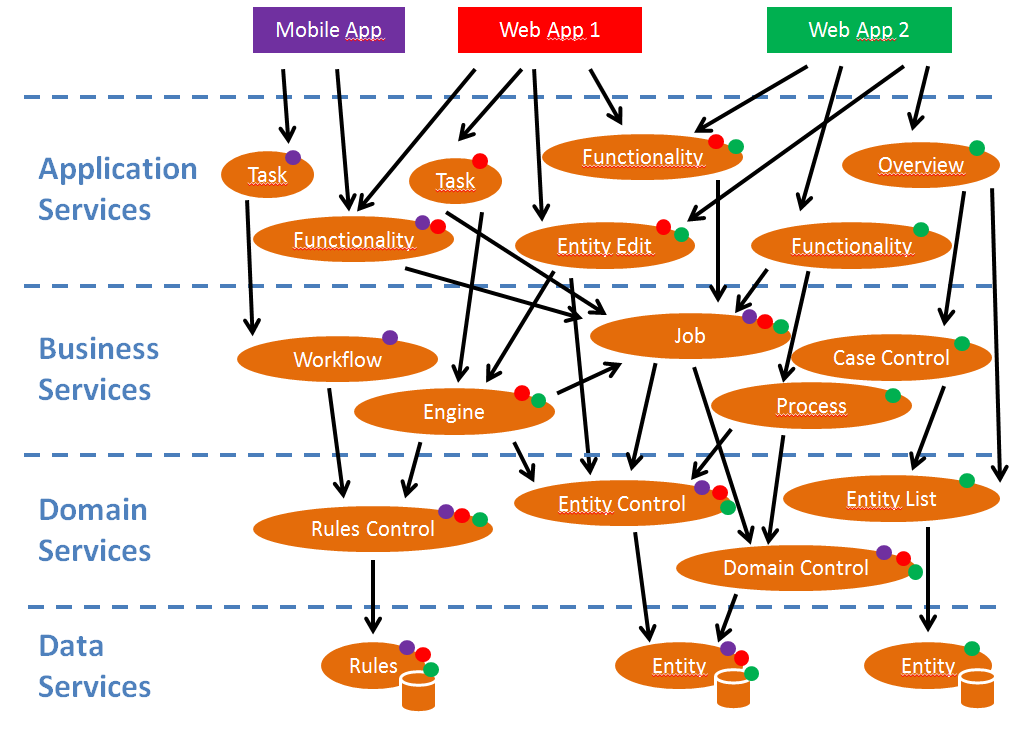
Een fictief voorbeeld van een microservice applicatie-ecosysteem, conceptueel voorgesteld. Bovenaan zijn er meerdere eindgebruikers-componenten, die een UI bevatten (de clients). Deze maken gebruik van onderliggende microservices die bepaalde functionaliteiten (b.v. “plaats een product in een winkelmandje”) ondersteunen en zo samen de applicatielogica van een applicatie vormen. Op hun beurt maken deze diensten gebruik van allerlei services die de business capabiliteiten, onafhankelijk van applicaties, ondersteunen (b.v. “plaats een bestelling”). Deze laatste maken dan weer gebruik van business diensten van een lager niveau: diensten die het beheer op zich nemen van de specifieke business entiteiten (zoals “klant”, “bestelling”, “factuur”). Op het laagste niveau krijgen we een eerder technische dienstverlening (b.v. “database voor klantgegevens”). Het komt in deze tekening niet veel voor, maar het is niet verboden dat diensten in een bepaalde laag gebruik maken van diensten die zich niet in de laag er direct onder bevinden. Deze opdeling in lagen is in principe ook slechts een voorbeeld; er zijn mogelijk nog andere manieren om de microservices te klassificeren. (In de tekening is met gekleurde bolletjes aangeduid welke microservices uiteindelijk deel uitmaken van welke applicatie.)
Eén probleem is dat deze sterke interconnectiviteit tussen een steeds groter wordende groep microservices kan gaan lijken op een onbeheersbaar kluwen (zogenaamde point-to-point integraties). Er zijn echter een paar zaken die dit effect tegengaan:
- Enerzijds is de point-to-point integratie slechts een integratie op conceptueel niveau. Op technisch vlak zal dit worden opgevangen door middleware-technologie, zoals de ESB. Zolang een dienst een logisch en leesbaar adres heeft, kan deze op die manier worden aangesproken. De werkelijke localisering en verbinding is de verantwoordelijkheid van een onderliggend platform.
- Daarnaast kan men ook twee reeds eerder besproken principes toepassen: die van Data-Centric IT, en die van Event-Driven Architecture. Deze zijn compatibel met elkaar en met Microservices, en zorgen samen voor een beheersbaar “inter-service” communicatiemodel: samen kunnen deze methodieken er namelijk voor zorgen dat een dienst enkel moet weten welke data en events er nodig zijn en hoe deze kunnen worden geadresseerd. Er zijn uiteraard nog externe zaken nodig die geen data of Event zijn, maar dit zijn dan meestal generieke en nuttige diensten, zoals het genereren van pdf’s of het aanroepen van eerder technische capabiliteiten, zoals authenticatie of logging.
- Ten slotte komen er specifiek voor deze problematiek ook oplossingen te voorschijn onder de noemer van API management. De publieke interface van een microservice kan namelijk gezien worden als een API (Application Programming Interface). Naast het beheer van een veelvoud aan APIs, richten deze platformen zich ook vaak op het beheer van de levenscyclus van de erachterliggende diensten.
Besluit
Microservices zijn als deployment architectuur een perfecte match voor Agile software ontwikkeling, en verankeren de goede principes van Service Oriented Architecture. Ze maken het mogelijk software op een flexibeler manier te ontwikkelen, met vele kleine componenten, waardoor er sneller kan worden ingespeeld op veranderende behoeften. Ze laten herbruikbaarheid toe op een fijnmazige manier, en verhogen de efficiëntie in het gebruik van resources. Ook met de huidige ontwikkelingen op vlak van infrastructuur: Containers, gaan ze heel goed samen. Samen daarmee, en met EDA en REST, vormen ze een blauwdruk om een applicatie-ecosysteem future-proof op te bouwen.
Nice article. How do you garantee transactionality in a micro services architecture ?
Hi Koen,
Usually, transactionality can be achieved by implementing certain communication schemes and/or protocols between mutually cooperating microservices, along with a phased commit internal to the separate microservices. An example can be found on http://blog.aspiresys.com/software-product-engineering/producteering/distributed-transactions-in-microservices/ .