[FR]
-

Organisation pratique d’ateliers d’IA – Conclusions
Dans un blog précédent, nous avions introduit l’initiative prise par Smals Recherche en collaboration avec les analystes business d’organiser des ateliers dans le but de capturer les opportunités d’intelligence artificielle (IA) chez nos membres. Pour rappel, l’objectif de ces ateliers était d’une part de partager les connaissances et bonnes pratiques et d’autre part, de détecter
-

Protection des données par la pseudonymisation préservant la structure des numéros de registre national
De plus en plus de données personnelles sensibles sont stockées sous forme numérique,tandis que les cyberattaques deviennent de plus en plus avancées. Aussi l’amélioration de la protection des données à caractère personnel fait-elle l’objet d’une attention de tous les instants.
-
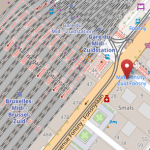
Géocodage : quel outil pour quel besoin ?
Pour être capable de positionner une adresse sur une carte, pour calculer un itinéraire ou pour identifier l’ensemble des commerces dans un quartier donné, il est nécessaire de passer par une étape fondamentale : le géocodage. Cette opération consiste, à partir d’une adresse postale, comme “Av. Fonsny 20, 1060 Bruxelles”, d’une part à la “standardiser” (partie bordeaux de l’image ci-dessous),…
-

Picovoice Rhino – Speech-to-Intent engine
(FR) Picovoice Rhino est un logiciel speech-to-intent qui permet aux utilisateurs d’interagir vocalement avec une application. Picovoice Rhino se distingue dans l’exécution de la reconnaissance d’intention, celle-ci étant réalisée en une seule étape de l’entrée audio à l’intention. Dans les approches plus traditionnelles, l’entrée audio doit d’abord être transposée en texte avant d’y appliquer la
-

Inleiding tot confidential computing
Cet article est aussi disponible en français. Over het algemeen wordt aangenomen dat data zich in drie toestanden kunnen bevinden. Data die zijn opgeslagen, bijvoorbeeld op een harde schijf of in een database, worden ‘in rust’ genoemd, data die van de ene computer naar de andere worden verzonden, bijvoorbeeld via een netwerk, zijn ‘in beweging’ en data
-
Introduction à l’informatique confidentielle
Dit artikel is ook beschikbaar in het Nederlands. On considère généralement que les données peuvent être dans trois états. Celles stockées, par exemple sur un disque dur ou dans une base de données, sont dites « au repos », celles envoyées d’un ordinateur à un autre, par exemple via un réseau, sont « en mouvement, » et les données traitées par
-

Organisation pratique d’ateliers d’IA
Il y a un intérêt pour l’intelligence artificielle (IA) dans les différentes institutions de la sécurité sociale et de nombreuses initiatives ont vu le jour chez nos membres. En soutien à ces initiatives, Smals organise pour ses membres une série d’ateliers visant à mener en collaboration avec les agents une réflexion sur l’utilisation de l’intelligence
-
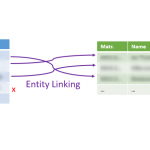
Dédoublonnage et couplage : comment ça marche ?
Dans un article précédent à propos du webscraping, nous avons été confrontés à une situation où nous obtenions une liste de commerces, avec un nom et une adresse. Nous voulions, pour chacun de ces commerces, le lier à une liste de commerces “officielle”, à savoir celle de la Banque Carrefour des Entreprises, ayant une structure
-
Haystack – NLP framework for document search and QA
Haystack est une librairie Python open-source qui permet la construction de systèmes de questions-réponses (QA) et de systèmes de recherche sémantique de documents basé sur des modèles de langage type Transformer. Cette librairie intègre d’autres projets open-source tels que Elasticsearch, FAISS et HuggingFace. Haystack is een open-source Python library die toelaat om question answering en
-

« Synthetic Data » – Webinar by Smals Research (december 01,2022)
“Fake it till you make it” : une introduction aux données synthétiques (Nederlandstalige tekst : zie onder) Un ensemble de données synthétiques est un ensemble de données fictives qui reproduit le plus fidèlement possible les caractéristiques d’un ensemble de données réelles. Un ensemble de données synthétiques correctement constitué peut, comme il s’agit de données purement fictives, être
Keywords:
analytics Artificial intelligence big data blockchain BPM chatbot cloud computing cost cutting cryptography data center data quality development EDA egov Event GIS Information management Machine Learning Managing IT costs methodology Mobile Natural Language Processing Open Source Privacy Productivity Security social software design software engineering standards