In May 2018, the much-discussed GDPR will be enacted. Besides identified data and anonymous data, the European regulation introduces a new category of data, called pseudonymous data. This articles presents an approach, based on cryptographic pseudonyms, that can help governments to become GDPR compliant more easily in case personal data originating from different sources need to be combined for analysis purposes.
Introduction
We focus on the following situation. What if a research team wants to analyse large sets of personal data? Say it needs medical, financial and demographic data of all citizens with a wage of at least € 40.000, born in or after 1990 and who are self-employed as a secondary activity. Data sets managed by different government organizations would need to be linked together. Such requests are common, and any government should be able to answer them. Yet is it possible with due respect for the privacy of citizens in an era of big data?
Before answering this question, let’s first clarify the distinction between the three categories of data defined in the GDPR: Anonymous data, identified data and the new category, pseudonymous data.
- Anonymous data can impossibly be linked to a natural person. An example are statistical medical data. The GDPR is not applicable on anonymous data.
- Identified data are linkable to a natural person without additional information. An example are medical records that contain the citizen’s social security number. The GDPR fully applies on identified data.
- Pseudonymous data is linkable to a natural person, but only with extra information that is stored elsewhere. An example are medical records where the citizen’s social security number is replaced by a unique code. The mapping between these codes and the citizens’ social security numbers is stored separately. The GDPR still applies, but some provisions are relaxed. The GDPR encourages the use of pseudonymous data.
By replacing identifiers by pseudonyms, we convert identified data into pseudonymous data. However, completely removing the identifiers does not necessarily result in anonymous data and should in many cases still be considered as pseudonymous data. Imagine, for instance, that the medical records contain the social security number, the gender, date of birth, the ZIP code and some medical data, such as the disease the citizen is suffering from. Imagine that only the identifiers are removed. If Bob knows the date of birth, gender and ZIP code of Alice, he is often able to link this de-identified medical record uniquely to Alice, and is, hence, able to learn sensitive medical data about her.
In a traditional approach, the data-delivering government organizations send the required data on a regular basis to a central data warehouse that stores the personal data. Data of the same citizen are trivially linkable to each other. If a research team wants to analyse data, it receives a pseudonymized subset of the data. Although linking of data originating from different sources becomes trivial, the approach comes with several risks:
- The data-delivering government organizations lose all control over the personal data for which they are still legally accountable. These government organizations have, as data controllers, indeed still responsibilities and duties according to the GDPR. How is it sure that the data are not used for purposes incompatible with the purpose for which they have been initially collected?
- In case of a data breach of the data warehouse, the consequences are dramatic, not only for the institution managing the data warehouse, but also for the millions of citizens whose privacy is severely affected. We see indeed that hacking attempts become increasingly professional and that the amount of personal data amassed by organizations and companies explodes. Both aspects contribute to the increase in risk.
- Even when pseudonimized, the data entrusted to the research team generally remain sensitive. If these data are stolen or made public, the consequences for citizens’ privacy can still be considerable.
Can we do better? Can we use technology to reduce these risks? How well can we protect personal data by using cryptographic pseudonyms? By answering these questions, we also shed light on what future analysis on personal data originating from multiple sources might look like.
The Data Archipelago – Central Ideas
The core idea is to have, instead of one big data warehouse, several ‘data islands‘ which are maximally isolated. As illustrated in the figure below, we distinguish between the long-term domain islands, with strong isolation, and the short-term project islands, with a somewhat weaker isolation.
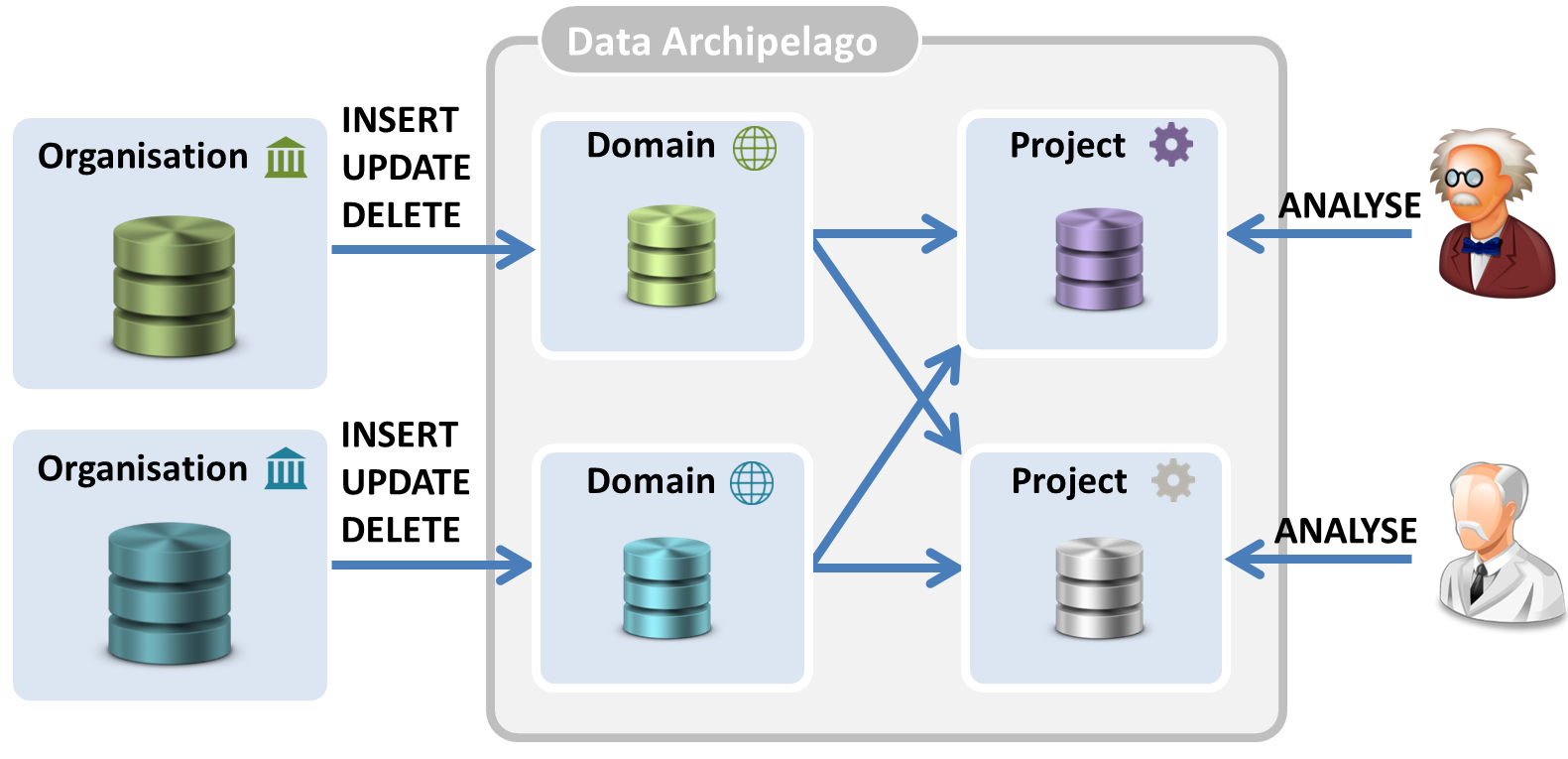
Domain islands. Each data-providing organization controls its own domain island (or islands) and keeps the contained data up-to-date. It only uploads these personal data to the domain islands that might be made available for data analysis projects. The data in the domain island is, hence, a subset of all the personal data controlled by the government organization. We use two principles to maintain perfect isolation between domain islands:
- Island-specific pseudonyms, instead of identifiers, are used for personal data on the domain islands. Different domain islands use a different, unlinkable pseudonym for the same citizen. Only after a procedure in which the involved government organizations give their consent with a secret cryptographic key, data about the same citizen can be linked together, without revealing any identifiers (see later).
- Attribute partitions. There is no overlap between the attributes stored by the domain islands. If domain island A stores your gender, no other domain island will contain it. Hence, If an entity has access to multiple islands, (s)he will be unable to link any of the records to each other based on attributes.
Hence, an attacker cannot know whether a record in domain island A and another record in domain island B belong to the same citizen. Only with the proper cryptographic keys, which are controlled and kept secret by the data-providing government organizations, it is possible to do this linking.
Domain islands can be stored in the central data warehouse, or on infrastructure of the controlling government institution. However, the data warehouse should be able to communicate with the domain islands.
Project islands. For each approved project, personal data originating from different domain islands are selectively linked together and stored on a project island. The project island only contains relevant attributes of the involved citizens. The lifetime of a project island is restricted to the duration of the project. Also, the project islands stay under the exclusive control of the data warehouse. Researchers are allowed to do certain data queries on the project island, but are never allowed to have full access to the raw data. Hence, we bring the calculations to the data instead of the data to the calculations.
Also, for the project islands, isolation is maximized, although at a lower level than the domain islands. We again apply the concept of island-specific pseudonyms. For each (domain or project) island, the same citizen is known under a different pseudonym. Note, however, that based on shared attributes, it might be possible to link records on a project island to other (domain or project) islands. Therefore, it is still important to sufficiently protect the project islands and minimize not only their lifetime, but also the data they store. Maybe the project does not need the exact date of birth, but just an age category.
By applying this approach, we arrive at the situation shown in the figure below. Although records of the same citizen are known by organizations under the same social security number, the citizen’s personal data are known under a different pseudonym on each island.
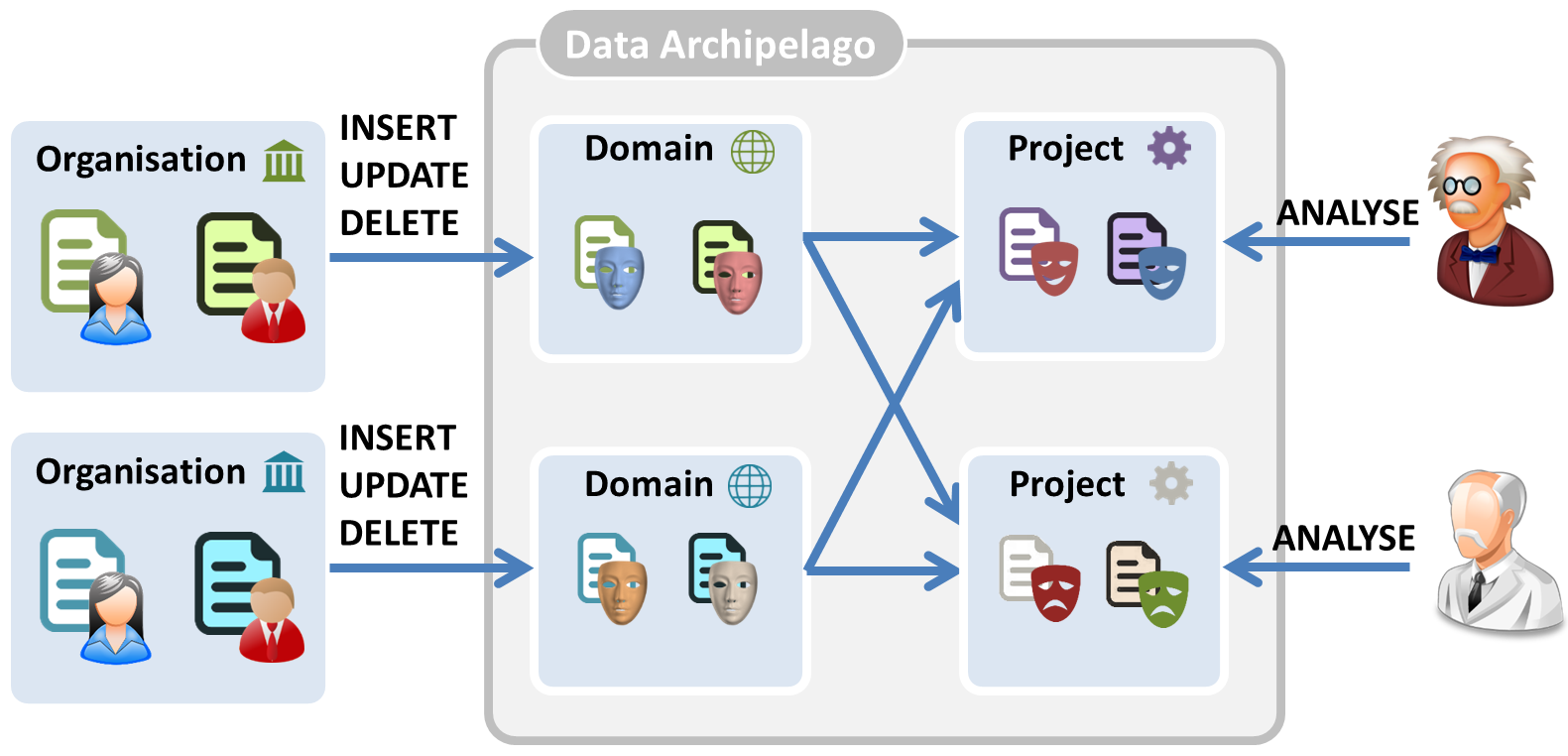
This results in the following properties:
- Maximal control by organizations. We give the data-delivering government organizations full control over what happens with their data. They receive a description of the new analysis project and only if it is compatible with the purposes for which it has originally been collected, the data is delivered to the project.
- Smaller impact in case of data breach & better privacy. In case a hacker has access to data in several islands, or in case data are leaked into the public, the damage is limited. Data on the permanent domain islands are in any case unlinkable. The linkability of data on project islands is minimized, by the use of project-specific pseudonyms and by limiting the data on and the lifetime of project islands. This way, we maximize the isolation between the islands, and, hence, the privacy of the citizens. Indeed, the more data of the same citizen you can link, the easier it becomes to identify this person.
Linking records with cryptography
The use of cryptographic keys is sketched in the figure below. Organizations and islands have keys, which are used to convert identifiers into pseudonyms or pseudonyms into other pseudonyms. Pseudonym conversion is indicated by a dashed line near the corresponding key.
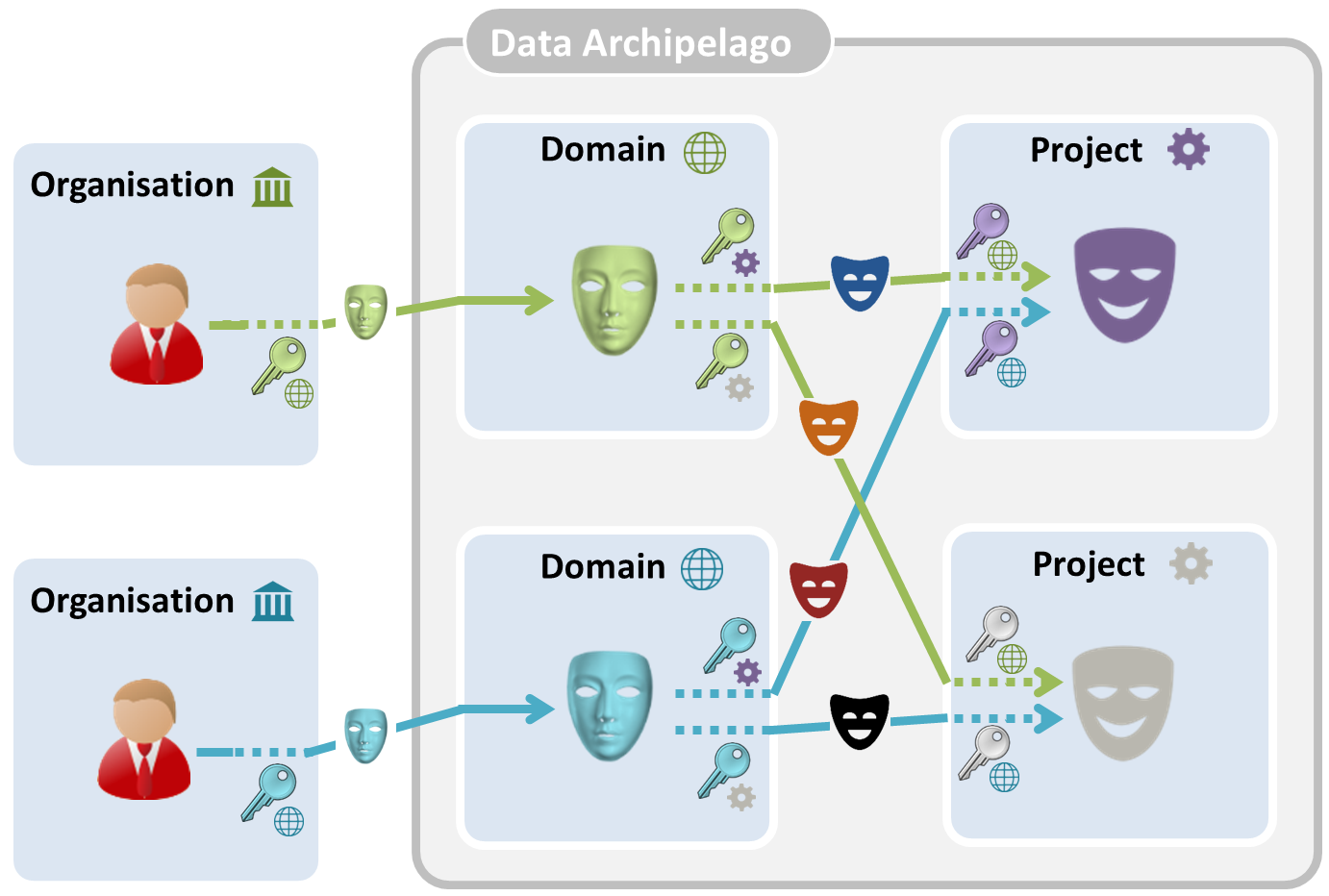
Each organization has a master key, each domain island has a key per project that it delivers data to, and each project island has one key per domain that it receives data from.
All government organizations in Belgium use the same social security number to identify a citizen. Using their master key, they convert it into a pseudonym that is used on the level of the domain island. Each government institution has its own master key. The same social security number converted with two different master keys results in two different, without the cryptographic keys unlinkable, domain pseudonyms. A subset of the data controlled by the data-providing government organization is sent to the domain island, whereby the social security numbers are replaced by these pseudonyms.
When a project is created, the involved domain islands each obtain a project-specific key, and the project island obtains a domain-specific key per involved domain island. Domain pseudonyms are converted with the project-specific key into unique transfer pseudonyms. When these transfer pseudonyms are received by the project island, they are converted with the domain-specific key into a project pseudonym. The transfer pseudonyms are deleted after the data transfer. Once all data is delivered by the domain islands to the project island, the associated keys in the project and the islands should be removed. The government organizations should, however, maintain their master keys.
By properly choosing the keys in the system, the following properties are achieved:
- Different domain pseudonyms corresponding to the same citizen are always converted into the same project pseudonym. Hence, different, unlinkable pseudonimized records of personal data received from different domain islands become again linkable on the project island.
- Domain pseudonyms of different citizens are converted into different project pseudonyms on the same project island.
- The same citizen is known under different, unlinkable pseudonyms on different project islands
In summary, a citizen is known under a different, unlinkable pseudonym on each island that contains personal data about him or her.
An example to illustrate the protocol
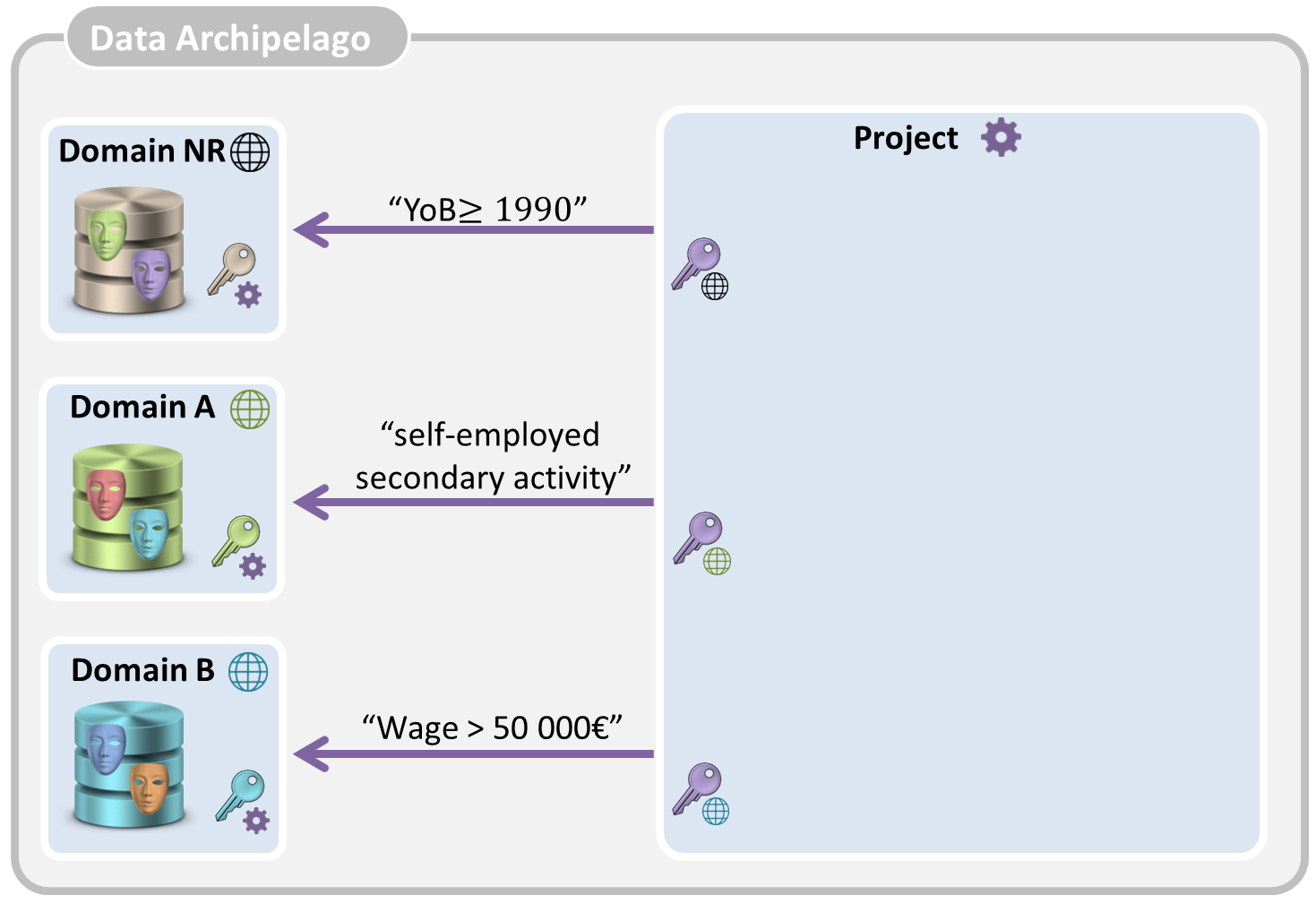
Let’s have a look at the example described in the introduction. A research team wants to analyse large sets of personal data. Say it needs medical, financial and demographic data of all citizens with a wage of at least EURO 40.000, born after 1990 and who are self-employed as a secondary activity. For the moment, we restrict our example to three domain islands and assume that the required personal data are stored in the second and third domain island:
- The first is the domain island of the National Register (Rijksregister) which contains for each citizen data about date of birth, gender, place of residence, nationality, etc.
- The second, the RSVZ island, contains data about independents in Belgium, and, hence, knows who is self-employed as secondary activity.
- The third one, the RSZ island, has the data about employees, and, hence knows the wage of each citizen.
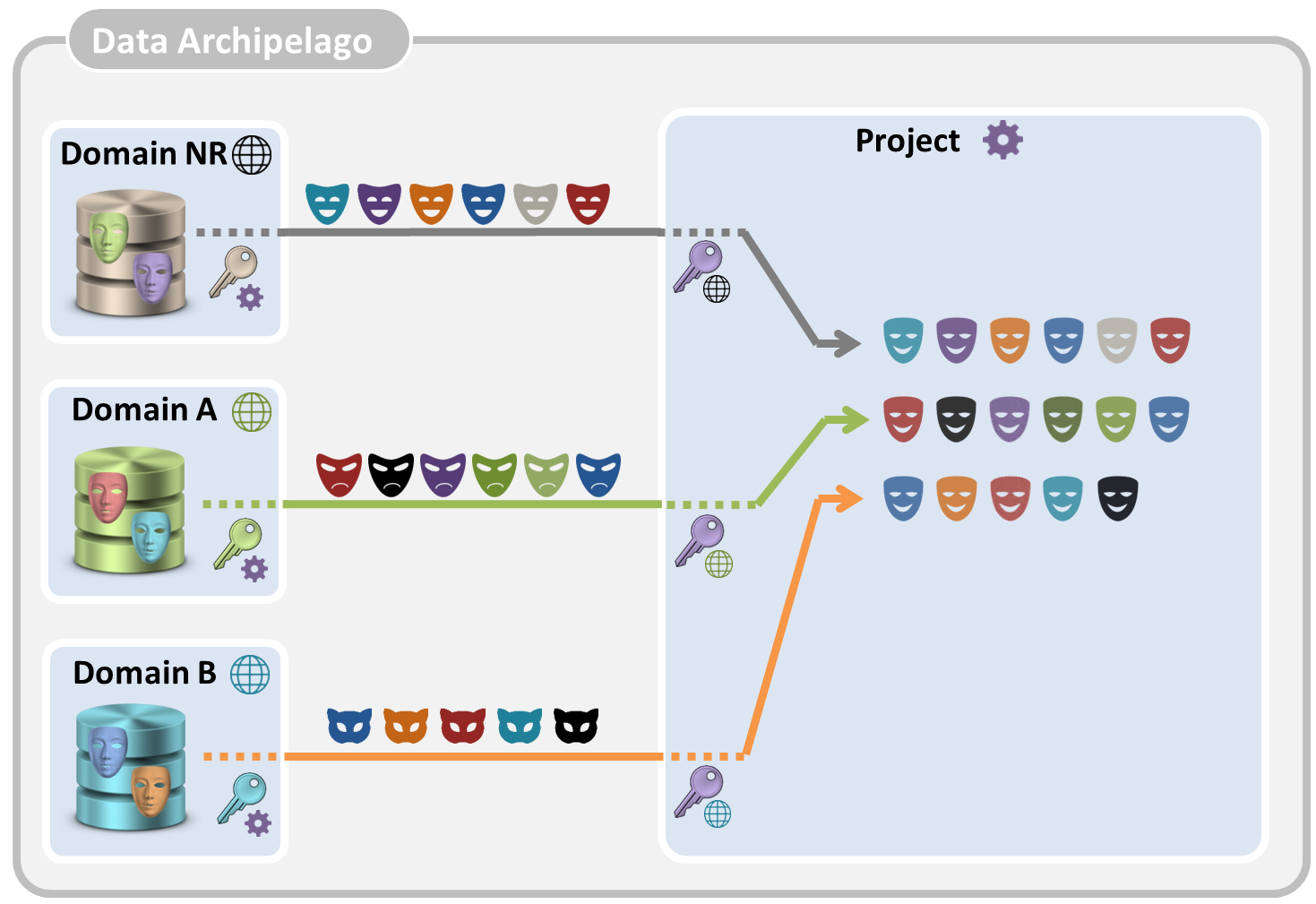
In order to obtain the required data, the following steps, illustrated in the four pictures below, are performed:
- The project island asks each of the involved domain islands for the relevant pseudonyms. It asks the domain island of the National Register to provide the pseudonyms of all citizens that are born in or after 1990, it asks the RSVZ island to provide pseudonyms of all citizens who are self-employed as secondary activity and it asks the RSZ island for the pseudonyms of citizens who have a salary of at least 40 000 €.
- Each of the involved islands retrieves locally the relevant domain pseudonyms, converts them into transfer pseudonyms and sends them to the project island. The project island converts each of the received transfer pseudonyms with the proper key into project pseudonyms. For each involved domain island, the project island now has a separate set of project pseudonyms.
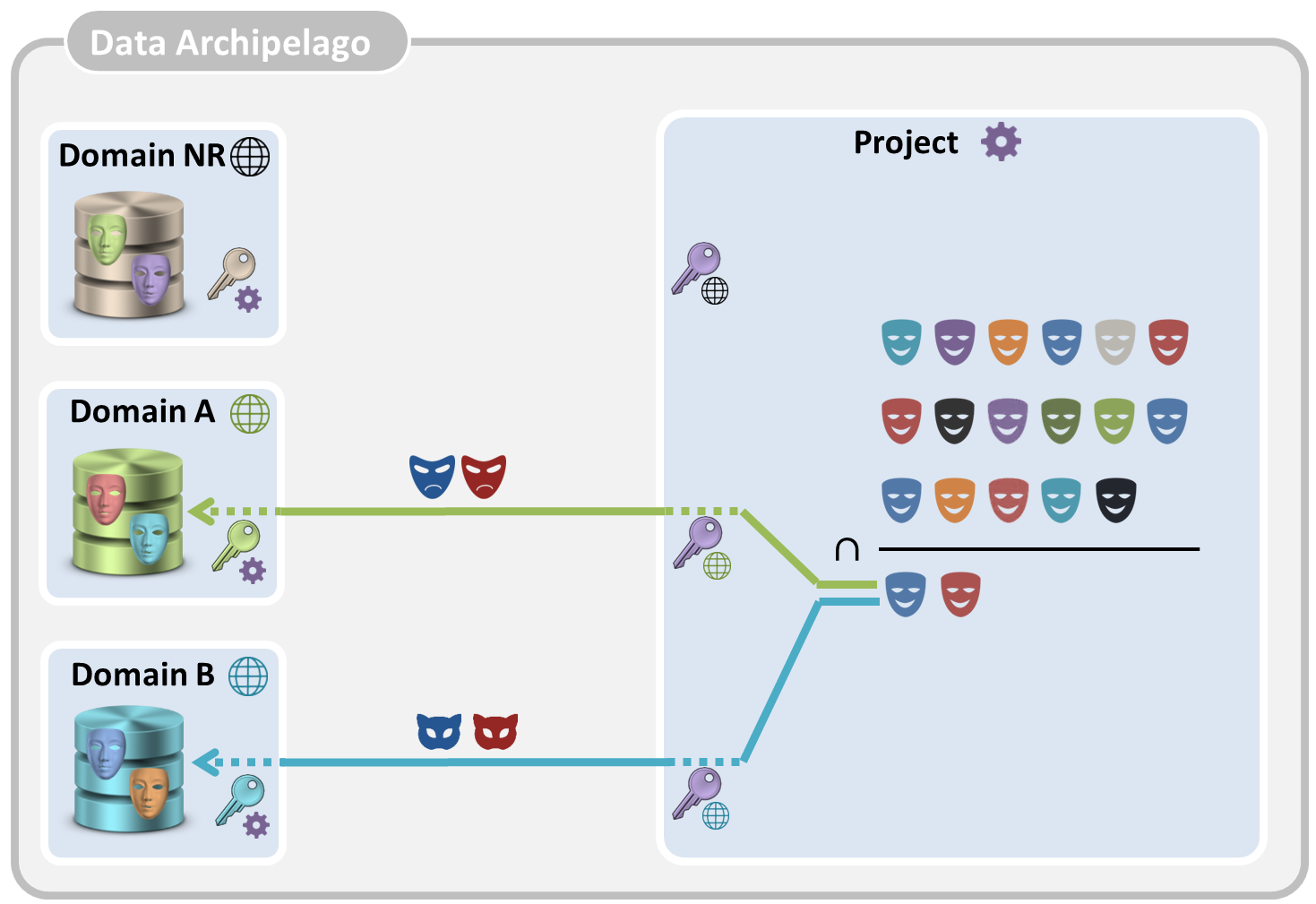
- The project island now takes the intersection of the three pseudonym sets, resulting in the set of project pseudonyms of the citizens of which the project islands needs data.
- For each domain island of which data are needed, these pseudonyms are again converted into transfer pseudonyms, sent to the domain island, which converts the transfer pseudonyms back into domain pseudonyms.
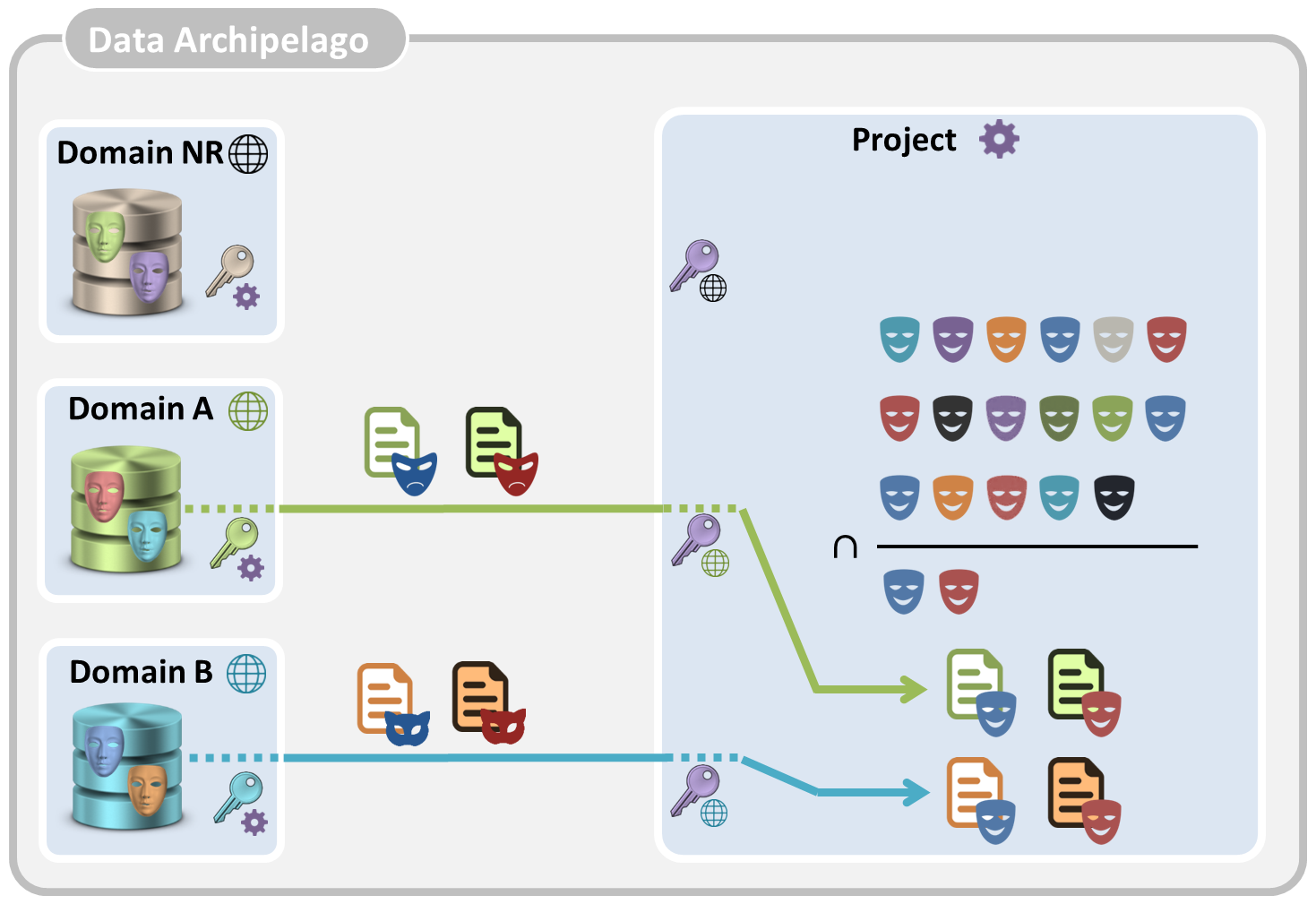
- The domain islands now select for each of the resulting domain pseudonym the relevant data and sends for each of the pseudonyms the relevant data to the project island. Again, the domain pseudonyms are converted into transfer pseudonyms by the domain islands before the data is sent to the project island
- Upon receipt of the data records, the transfer pseudonyms are again converted into project pseudonyms. Each received data record now has a project pseudonym. If and only if two data records have the same project pseudonym, they belong to the same citizen and they can be trivially linked.
 Step 1 |
 Step 2 |
 Steps 3 and 4 |
 Steps 5 and 6 |
In case data needs to be retrieved from other domain islands, besides the ones of the RSVZ and the RSZ, steps 4,5 and 6 are also executed between the project island and each involved domain island. This way, the project island can also obtain, for instance, medical data.
The proposed approach ensures that the data-providing government organizations maintain maximal control over what happens with the data, since they control the cryptographic keys of their domain islands. The approach also ensures that the domain island does not learn more personal data than strictly necessary.
The presented approach, however, has some drawbacks.
- Personal data leaks to the domain islands. In our example, the RSVZ island learns that the pseudonyms received in step 4 belong to people born in 1990 or later with a salary of over 40 000 €. Similarly, the RSZ learns new personal information.
- The project island can ask too much data from the domain islands. In step 4, the domain islands cannot know whether the received pseudonyms belong effectively to the intersection calculated in step 3. This enables the project island to request also data about pseudonyms that are not in the intersection.
Both drawbacks can be prevented. We refer to our detailed report for more details.
Conclusions
In this article, we sketched the main ideas of the Data Archipelago, which we invented three years ago. Since then the concept has only gained importance, especially given the upcoming GDPR. Indeed, this European regulation encourages the use of privacy by design, which is exactly what we did here, as well as the use of pseudonyms. We presented a very specific case, linking together personal data for data analysis purposes, but we are convinced that the use of cryptographic pseudonyms can and should also be applied in many other contexts to better protect the privacy of citizens. In that respect, in the meantime we also came up with a blockchain based prescription processing scheme, that uses one-time pseudonyms to protect not only the privacy of the involved citizens, but also the confidentiality of business information. Unfortunately, the use of cryptographic pseudonyms is less straightforward than traditional approaches, which poses to European governments the challenge of obtaining and developing the right competences.
Several aspects have not been discussed in this introductory article. We didn’t talk about key generation, re-identification in case of fraud, or less straightforward combinations such as family configurations. We emphasize that for each of these aspects, we have come up with solutions.
Further information
- The content of this article was presented at InfoSecurity Brussels on 25 March 2017. The slides can be downloaded here.
- We wrote a scientific document were everything is described in detail.
- We also published a more accessible report in Dutch.
If you have questions or suggestions regarding our approach, feel free to contact us.