Veel aspecten van Natural Language Processing (NLP) steunen op een of andere vorm van classificatie. Als we een tekst automatisch willen analyseren of begrijpen, zal het immers snel nodig zijn om labels aan (groepen van) woorden of zinnen toe te kennen. Op basis van die labels of annotaties kan de analyse verdergezet worden.
Classificatie is hét typevoorbeeld van machine learning, en bij uitbreiding artificiële intelligentie. Het algemene probleem is als volgt: gegeven een bepaalde input (onze gegevens), welke output (een label) hoort daarbij? Die output geeft dan weer of de input tot een of meerdere categorieën behoort: bvb. de bloedtypes “A”, “B”, “AB”, “O”, of nog simpeler: “ja”, “nee”. Een classifier (*) is een algoritme dat we kunnen trainen om deze vraag te beantwoorden. Die training vereist dat we het algoritme voeden met hopen voorbeelden: een dataset van input-output-paren die we al ter beschikking hebben.
Bij NLP bestaat onze input uit tekst. Tekst bestaat uit zinnen, zinnen uit woorden, woorden uit letters, en op elk van die niveau’s kunnen we classifiers trainen en toepassen. Omwille van de grote woordenschat en variabiliteit in vele talen (denk aan alle vervoegingen en verbuigingen) moet een trainingsdataset voor NLP-classifiers vaak enorm groot zijn. Bovendien kan je een classifier getraind op één taal niet zomaar toepassen op een andere: daarvoor moet de classifier meestal volledig opnieuw getraind worden met een dataset uit die andere taal.
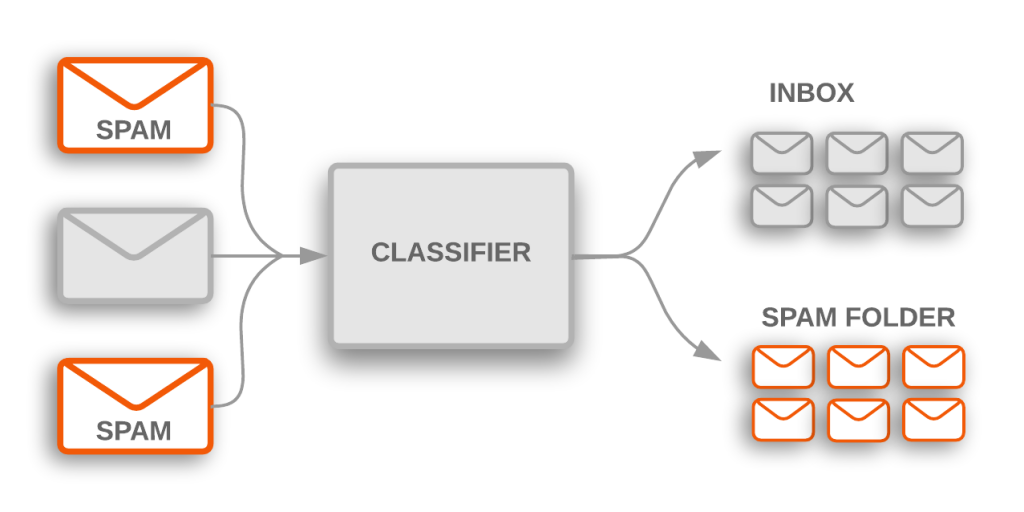
Bron: https://developers.google.com/machine-learning/guides/text-classification/
Een courante tekstclassifier die we allemaal dagelijks gebruiken is de spamfilter: gegeven een email, beslist die of het spam is, ja of nee. In dit artikel wil ik echter focussen op een fijnmaziger niveau: de classificatie van een woord, of een kleine woordgroep, binnen eenzelfde zin.
(*) Er bestaat een brede waaier aan algoritmes voor classificatie, waaronder decision trees, support vector machines, probabilistische modellen, graaf-gebaseerde modellen en neurale netwerken in allerlei geuren en kleuren. Ze zijn in principe allemaal inzetbaar voor de NLP-problemen beschreven in dit artikel; “classifier” mag in deze tekst dus breed geïnterpreteerd worden.
Grammatica
In de context van parsing (zinsontleding) willen we bijvoorbeeld achterhalen tot welke woordsoort een woord behoort. Dit probleem staat bekend als Part-of-Speech (POS) tagging. Naamwoorden worden in veel talen verbogen, en werkwoorden vervoegd. Ter vereenvoudiging wordt daarom vaak eerst een vorm van stemming of lemmatisering toegepast, waarbij men ieder woord eerst terug brengt tot zijn stam.
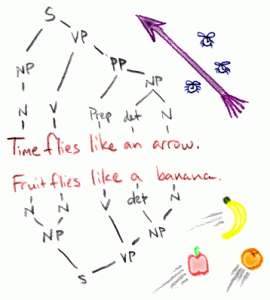
Bron: SpecGram.com
Dan nog is er ambiguïteit mogelijk. Neem het woord “werken” in de volgende voorbeelden:
- De 12 werken van Hercules
- Er zijn ook onderzoekers die werken bij Smals
Dit illustreert de noodzaak om met context rekening te houden. Net daar komt machine learning van pas: we hebben een systeem nodig dat bepaalt dat het in de eerste zin het gaat om een zelfstandig naamwoord, en in de tweede zin om een werkwoord.
Een classifier die dat moet bepalen zal je daarom trainen met voorbeelden waarin ook enkele woorden rondom worden meegenomen (zogenoemde n-grams). Neem bijvoorbeeld 2 woorden voordien en 1 woord nadien als context:
- “De 12 werken van” → werken = zelfst. nw.
- “onderzoekers die werken bij” → werken = werkwoord
Een geschikte classifier die zo voldoende wordt getraind, zal ook van onbekende woorden de meest waarschijnlijke woordsoort kunnen afleiden. Dit is handig omdat we dan in zekere mate kunnen omgaan met neologismen of nieuwe woordenschat:
- “Hij schreef 7 ghjkl in zijn leven” → ghjkl = zelfstandig naamwoord
Disambiguatie
Ook binnen eenzelfde woordsoort kan een woord verschillende betekenissen hebben, dit zijn de homoniemen. Voor ons is het evident dat als een “muis” knoppen heeft om op te drukken, je waarschijnlijk spreekt over de computermuis en niet over de veldmuis. Een computer moet eerst getraind worden om de juiste betekenis te selecteren. Dit vraagt om een classifier die je traint op een hoop zinnen waarin het woord “muis” voorkomt, in de hoop dat de classifier aanleert in welke context “muis” verwijst naar de computermuis en in welke context niet.


In de computationele linguïstiek heet dit Word Sense Disambiguation, een klassiek probleem waarvoor dan ook grote datasets bestaan voor training en evaluatie van algoritmes. Een basisdataset is het Engelstalige WordNet. Het Europees project BabelNet breidt dat uit tot een honderdtal andere talen via Wikipedia-crosslinks, terwijl Open MultiLingual Wordnet een lijst bevat van andere datasets gelinkt aan WordNet.
Data genoeg, zo lijkt het, maar dat maakt het niet noodzakelijk gemakkelijk om goede resultaten te krijgen. Zelfs de beste algoritmes halen momenteel een F1-score (een maat voor accuraatheid) die maar weinig hoger ligt dan die van de eenvoudigste strategie: “kies altijd de meest voorkomende betekenis”. Volgens de laatste resultaten presteren neurale netwerken en traditionelere classifiers daarbij op ongeveer hetzelfde niveau, en doen deze classificatiegebaseerde systemen het net iets beter dan rule-based systemen.
Het spreekt vanzelf dat grammaticale en semantische disambiguatie allebei erg nuttig zijn voor automatische vertaling, waar ik in een vorige blogpost al kort over schreef.
Named Entity Recognition
In een tekst vind je al snel referenties terug naar mensen, bedrijven, plaatsnamen, bedragen, tijdstippen, kunstwerken, etc. Vaak gaat het om eigennamen of jargon: woorden die je niet zomaar in het woordenboek terugvindt. Dit noemen we entiteiten, en een vaak voorkomende vraag is: kunnen we deze automatisch herkennen en markeren in een tekst?
Het probleem staat bekend als Named Entity Recognition (NER), en je kan dat aanpakken op verschillende manieren:
- Als je je kan beperken tot een overzichtelijke eindige lijst: gewoon kijken of een woord in dat lijstje voorkomt. Handig voor o.a. plaatsnamen of de namen van de maanden.
- Als de term een gestructureerde vorm heeft, kan je werken met een reguliere expressie. Nuttig voor datums in een vaste vorm, identificatienummers, telefoonnummers, emailadressen of URLs.
- Als een entiteit beschreven kan worden op teveel manieren om op te sommen, kan je die met een getrainde classifier proberen te herkennen. Deze aanpak wordt vaak gehanteerd voor het herkennen van persoonsnamen en organisaties, of wanneer een tekst veel spelfouten kan bevatten.

Ter illustratie, het volgende experiment: in een gescand juridisch document (een vonnis, een arrest, een brief van een advocaat), waaruit de tekst werd geëxtraheerd met behulp van Optical Character Recognition (OCR), willen we alle verwijzingen naar wetteksten markeren. Dit is nuttig om bijvoorbeeld de binnenkomende post onmiddellijk intern te kunnen doorsturen naar de jurist die gespecialiseerd is de wet waarvan sprake, of om de tekst te verrijken met links naar andere informatiebronnen over die wet (Entity Linking), wat een hoop manueel opzoekwerk kan besparen.
Een referentie naar een wettekst kan op veel manieren verwoord worden:
- Wet ter bescherming van persoonsgegevens,
- Wet ter bescherming van de persoonlijke levenssfeer ten opzichte van de verwerking van persoonsgegevens,
- Wet van 8 december 1992,
- Belgische Privacywet,
- …
Al deze referenties zouden we op een of andere manier willen herkennen. We doen dat door trainingsvoorbeelden te geven aan een classifier die antwoord geeft op de vraag: is dit woord onderdeel van een wetsverwijzing, ja of nee? De trainingsdata neemt de vorm aan van individuele zinnen waarin een wetsverwijzing voorkomt, en de beginpositie en eindpositie van die wetsverwijzing. In de volgende frase markeerden we een verwijzing naar een wetsartikel van letter 26 tot letter 65:
- terwijl overeenkomstig de artikelen 87 tot 94 Wet Strafuitvoering een gevangenisstraf kan worden omgezet in een werkstraf
Zonder hier dieper in te gaan op de details, zal een NER-classifier proberen om in een nieuwe tekst de beginposities en eindposities van alle entiteiten terug te vinden. Een geschikte classifier zal daarbij rekening moeten kunnen houden met de context, of misschien gebruik maken van systemen zoals attention, die kunnen zorgen voor een consistentere output.
In onderstaand voorbeeld proberen we ook met machine learning te detecteren welke woorden plaatsnamen en organisaties zijn. Dit omdat de input afkomstig is van een beeldscanner met OCR, waarvan het resultaat inherent spelfouten bevat. Na een minimale training is een eerste resultaat:
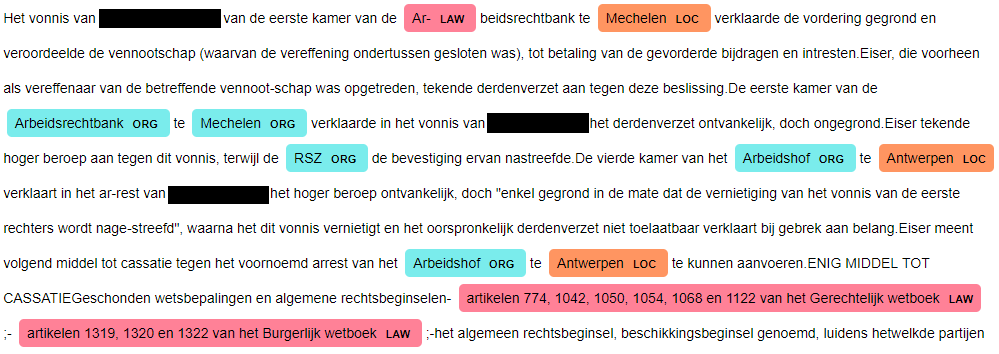
Hieruit blijkt alvast:
- De spelfouten en splitsingstekens in de input maken het moeilijker voor NER. In plaats van “Ar-beidsrechtbank” als organisatie te markeren, wordt “Ar-” als apart woord aanzien, dat de computer blijkbaar eerder doet denken aan een wetsverwijzing – vermoedelijk omdat het begint met dezelfde letters als “artikel”.
- Dat “Mechelen” soms als organisatie wordt aangeduid, is vermoedelijk omdat in de trainingsdata soms een plaatsnaam voorkomt in de naam van een organisatie. Dat zal iedere classifier in de war brengen. (Hetzelfde probleem doet zich voor bij het onderscheid tussen persoonsnamen en bedrijfsnamen: nogal wat bedrijfsnamen bevatten een persoonsnaam.)
Met extra trainingsvoorbeelden kan dat uiteindelijk geremedieerd worden, maar duiken er elders misschien nieuwe problemen op. Helaas vergt het samenstellen van een trainingsdataset voor gespecialiseerde toepassingen zoals deze, nog altijd veel manueel werk. Crowdsourcing kan daarvoor eventueel een oplossing bieden. En dan nog is het onbegonnen werk om alle mogelijke variaties en nuances te vatten, zodus zal er altijd met een zekere foutenmarge rekening gehouden moeten worden.
Met de entiteiten die wél goed gedetecteerd worden, kunnen we alvast aan de slag. Een link naar een andere toepassing met nuttige info over die wettekst is snel gelegd: bijvoorbeeld naar de integrale gepubliceerde wetteksten, die in Europa sinds kort online beschikbaar worden gesteld via een gestandaardiseerd systeem, de European Legislation Identifier (ELI).
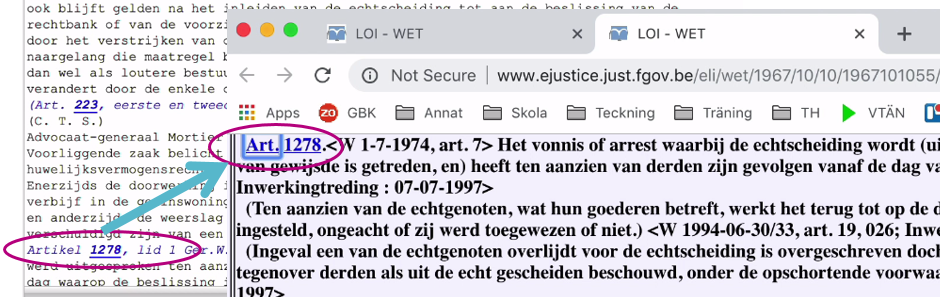
Dit werd als proof-of-concept uitgewerkt op de NLP4Gov Hackathon georganiseerd door Informatie Vlaanderen in 2018. Daar ging een team van startup TheMatchbox aan de slag met een dataset die Smals Research voorstelde samen met RSZ-ONSS en IGO-IFJ, op basis van de gepubliceerde arresten van het Hof van Cassatie. Om af te sluiten, hun filmpje dat het eindresultaat presenteert: