Oracle definieerde data scrambling ooit als volgt: “the process to obfuscate or remove sensitive data. This process is irreversible so that the original data cannot be derived from the scrambled data.” Als zodanig hoort het zeker thuis onder de privacybevorderende technologieën waarvan eerder spake: het doel is de gegevens zo goed mogelijk af te schermen, maar ze toch (deels) bruikbaar te houden voor derden. In strikte zin is scrambling slechts een vorm van data masking, maar in dit artikel hanteren we een bredere definitie en rekenen we o.a. ook shuffling en substituties ertoe. Deze technologieën worden onder andere toegepast bij banken, waar testers en ontwikkelaars wel een stacktrace moeten kunnen onderzoeken of een programma moeten testen, maar daarbij geen inzage mogen krijgen in de echte bankgegevens van klanten.
Als het doel is om een functioneel alternatief te voorzien voor gevoelige data, zijn tools voor de creatie van synthetische data bij uitstek geschikt. Ze kunnen immers meer dan enkel de bestaande gegevens door elkaar gooien: ze zijn gemaakt om de structuur van gegevens aan te leren, waarna je willekeurig veel nieuwe gegevens volgens dezelfde structuur kan aanmaken. In combinatie met generatoren voor totaal fictieve gegevens, hebben we daarmee alles voorhanden om niet alleen de originele gegevens te verbergen, maar ook om te zorgen dat wat in de plaats komt, realistisch oogt.
Dat betekent echter niet dat het een kwestie is van een druk op de knop. Eén en ander hangt af van allerlei randvoorwaarden en aannames over de inhoud en structuur van de gegevens. Afhankelijk van de beoogde toepassing of het doel, kan het nodig zijn om extra beperkingen en filters op te leggen, of misschien net om bepaalde delen van de gegevens buiten beschouwing te laten. In dit artikel kijken we vooral naar die praktische bekommernissen: wat kom je zoal tegen als data professional die synthetische data moet aanmaken?

Setup
Wie een dataset wil scramblen, heeft uiteraard toegang nodig tot de originele gegevens. Het spreekt voor zich dat het uploaden van gevoelige data naar een cloud service of zelfs het gebruik van een Docker container voorzien door een derde partij, slechts mogelijk is als er grondig is nagedacht over GDPR-compliance, eventueel een Data Protection Impact Assessments (DPIA) is opgesteld, en best ook met de DPO is overlegd. We doen zelf geen enkele uitspraak over de geschiktheid van eender welke tool vis-à-vis de GDPR-wetgeving. Voor al wat volgt gaan we ervan uit dat we werken met tabulaire, tekstuele of numerieke gegevens, die lokaal beschikbaar zijn – met andere woorden, een grote spreadsheet.
De markt
In een vorig artikel vermeldden we al enkele spelers vanuit de optiek van AI-projecten en software testing. Hier ligt onze focus meer op de privacybescherming en data science. Voor het analyseren en synthetiseren van tabulaire gegevens is er een heel sterk groeiende markt. Enkele interessante spelers zijn de volgende – en er zijn er ongetwijfeld nog veel meer:
Open source tools zijn er minder en zijn vaak afkomstig van projecten die op universiteiten zijn begonnen. Benerator vermelden we apart omdat deze al langer bestaat en ook een uitgebreid commercieel aanbod heeft. Jongere open source initiatieven zijn onder andere:
- Synthetic Data Vault (SDV)
- Mimesis
- Synthia
- Data Responsibly‘s DataSynthesizer
- MITRE’s Synthea / SyntheticMass (toegespitst op eHealth)
SDV is momenteel de populairste van de open source tools, en we gebruiken deze voor al wat volgt. In onze Quick Review vind je meer uitleg over deze tool.
Het stappenplan
Het plan van aanpak om synthetische data te produceren is bij de meeste tools heel gelijkaardig. We kunnen het onderverdelen in 6 grote stappen:
- Upload en inlezen van de gegevens. Met name de tekst-encodering kan hier wel eens voor problemen zorgen als de gegevens uit oudere bronnen afkomstig zijn. Problemen hiermee moeten opgelost worden voordat men aan de volgende stappen begint.
- Analyse en typering van de gegevens. Voor elke kolom: welke zijn de minima, maxima, de waarden die voorkomen, zijn er missende waarden, etc. Omdat de computer niet weet wat de achterliggende betekenis van de gegevens is, is het vaak nodig om in deze stap manueel correcties uit te voeren:
- Niet alle getalwaarden kan je zomaar beschouwen als “hoeveelheden” die je vrij kan optellen of aftrekken. Sommige zijn categoriën, zoals NACE codes of postcodes, andere zijn misschien onderdeel van een datum.
- Ontbrekende gegevens zal je in sommige gevallen kunnen gelijkstellen met 0 of met een reeds aanwezige default categorie, maar vaak wil je ze misschien beschouwen als een klasse apart. Een ontbrekende geboortedatum wilt immers niet zeggen dat iemand geboren is in het jaar 0.
- Transformatie van gegevens. Hierbij worden o.a. ontbrekende gegevens afgesplitst, of categorische variabelen omgezet in een getal-encodering om compacter voorgesteld te worden. Deze stap gebeurt vooral achter de schermen, maar het is vaak mogelijk om manueel configuratie-opties toe te voegen: van sommige kolommen willen we bijvoorbeeld forceren dat de waarden altijd uniek zijn, andere kolommen willen we misschien negeren.
- Een generatief model trainen. Dit kunnen zowel “klassieke” statistische modellen zijn als deep-learning varianten. Sommige modellen zijn enigszins in staat om diepere verbanden tussen de gegevens te reproduceren, maar dit blijft erg afhankelijk van de hoeveelheid gegevens en hun distributie.
- Genereren van nieuwe gegevens. Bij gebruik van een generatief model staat er in principe geen limiet op de hoeveelheid gegevens die aangemaakt kan worden.
- Evalueren en visualiseren van de resultaten. De meeste commerciële tools genereren een mooi eindrapport met daarin een verslag van het hele proces en enkele samenvattende grafieken die toelaten om in een oogopslag te zien of er anomalieën zijn, en of er nog andere correcties toegevoegd dienen te worden. Bij open-source tools is dat vaak beperkt tot enkele metrieken en moet je verdere gegevensanalyse zelf bijprogrammeren.
Gegevens
Wie de tools liefst niet uittest op eigen (gevoelige) data, vindt veel datasets op Kaggle. Zelf maakten we voor onze testen onder andere gebruik van een variant op de Adult Census Income dataset.
Praktische bekommernissen
Telgegevens
Sommige datasets bevatten tellingen. Dat kan het resultaat zijn van een COUNT() functie in de SQL-query voor data-extractie. Om dan een correcte inschatting te kunnen maken van de distributies van de andere variabelen, is het nodig om deze telling ongedaan te maken en de tabel te “unrollen”. Een nieuw gegenereerde tabel moet nadien natuurlijk terug “opgeteld” worden om terug in het originele formaat te staan. Op deze manier kan men desgewenst ook garanderen dat de resulterende tabel ook effectief hetzelfde aantal records voorstelt als in de originele database, zelfs al is er een ander aantal combinaties van variabelen. De kolom met de telvariabele wordt uiteraard niet meegenomen in het generatief model.
Behoud van alle mogelijkheden
Voor sommige toepassingen kan het nodig zijn dat een gesynthetiseerde dataset zeker ook alle mogelijke waarden bevat die voorkomen in de originele dataset – bij wijze van representativiteit voor de originele dataset. Maar met name als bepaalde waarden erg zeldzaam zijn, bestaat er een reëel risico dat ze niet genoeg doorwegen bij de training van het generatief model, waardoor ze achteraf bijna nooit gegenereerd worden. De meeste generatieve modellen laten het conditioneel samplen van gegevens toe: datapunten kunnen gegenereerd worden waarvoor de waarde van een of meerdere variabelen vaststaan. De distributie van de andere waarden volgt dan een conditionele distributie, gegeven deze vaste waarden. Doe dat voor elke waarde die voorkomt in de originele dataset, en men kan garanderen dat elke waarde (alleszins onafhankelijk) voorkomt. Dit vraagt weliswaar wat extra programmeerwerk om gedaan te krijgen, en bovendien impliceert dit ook dat een outputdataset een bepaalde minimumgrootte zal hebben.
Duplicaten en overlap
Het genereren van nieuwe gegevens gebeurt door te samplen uit een generatief model – te vergelijken met het trekken van een lottocombinatie. Zeker als er veel gegevens worden gesynthetiseerd, is het altijd mogelijk dat er twee keer hetzelfde tussenzit. Is dat ongewenst, dan moet een optie toegevoegd worden om duplicaten te verwijderen – en nadien opnieuw gegevens bij te genereren totdat de gewenste grootte opnieuw is bereikt. Eventueel kan men ook forceren dat gesynthetiseerde gegevens zeker niet mogen voorkomen in de originele dataset – dat de twee datasets dus volledig disjunct zijn. Dat laatste voegt echter weinig toe qua privacybescherming: zonder kennis van de originele dataset, kan men steeds bogen op een zekere plausible deniability dat een synthetisch record identiek zou zijn aan een record uit de echte dataset.
Trainingstijd
Zeker bij grote datasets met veel variabelen, en bij gebruik van deep learning tools kan het een lange tijd in beslag nemen om een generatief model te trainen. Dat maakt het moeilijk om iteratief te werk te gaan bij het verfijnen van de opties. Het kan nuttig zijn om tijdens de ontwikkeling, de dataset ten grondslag van de training te beperken tot enkele duizenden willekeurig geselecteerde records. Daarbij mogen we al wat hierboven al werd vermeld natuurlijk niet uit het oog verliezen – bijvoorbeeld, ook hier kan het nuttig zijn om een extra optie te hebben die garandeert dat een selectie uit de trainingset nog steeds minstens 1 datapunt bevat voor elke waarde van elke variabele.
Afhankelijke kolommen
Een kolom die volledig (lineair) afhankelijk is van een of meerdere andere kolommen, moeten we verwijderen en achteraf terug herberekenen. Dat is typisch het geval bij wiskundige afhankelijkheden: een kolom die een som is van twee andere kolommen, of een percentage van een andere kolom voorstelt. We kunnen best niet hopen dat een generatief model dat verband zelf aanleert. Het is veel zekerder om zulke afhankelijke kolommen gewoon te verwijderen uit de dataset, en nadat een nieuwe dataset is gegenereerd, deze kolommen terug te berekenen op basis van de gesynthetiseerde data en dan pas toe te voegen.
Constraints
Iemands geboortedatum valt altijd vroeger dan iemands sterfdatum. Dat is logisch, maar als men voor een fictief persoon een nieuwe geboortedatum en sterfdatum genereert uit het generatief model dat werd getraind op de distributies van alle geboorte- en sterfdata in een dataset, dan kan het voorvallen dat deze logische beperking niet altijd gerespecteerd blijft. Het kunnen opleggen van constraints – de ene variabele is altijd groter of kleiner dan een andere, of altijd positief of negatief, etc. – is een belangrijke feature. Eenvoudige beperkingen, zoals zonet aangehaald, zijn eventueel nog eenvoudig te implementeren door “rejection sampling”: voldoet een gesynthetiseerd record niet aan alle constraints, wordt het gedeleted en wordt een nieuw gegenereerd, totdat alle records voldoen. Worden de constraints ingewikkelder of strikter, dan kan het nodig zijn om zelf de nodige filters te programmeren, of om een post-processing stap te definiëren waarin correcties uitgevoerd kunnen worden.
Kolommen bevriezen
Willen we een dataset scramblen met een kolom geslacht en een kolom woonplaats, dan is het eigenlijk voldoende om enkel de kolom met woonplaatsen door elkaar te husselen om een goed gemengde dataset te bekomen. Het geslacht is daar onafhankelijk van, en kunnen we even goed negeren. Het bevriezen van kolommen, in feite gewoon het verwijderen voor de verwerking en terug eraan plakken na het einde, kan zo een grote tijdswinst opleveren. Het is weeral een kolom minder waarvan de distributie aangeleerd moet worden.
Kolommen bevriezen, impliceert weliswaar een voorwaarde: ofwel dat de gesynthetiseerde dataset even lang moet zijn als de originele zodat de dimensies overeenkomen, ofwel dat de gegevens in de bevroren kolom(men) helemaal willekeurig verdeeld zijn, dus op geen enkele manier gesorteerd of gegroepeerd, zodat de bevroren kolom(men) zonder effect op de gegevensdistributie kunnen verkort of verlengd worden. Dat laatste kan echter moeilijk te bewijzen zijn.
Maar zeker als het de bedoeling is dat een gesynthetiseerde dataset even groot is als de originele, wat toch vaak voorkomt, is het een enorm grote tijdswinst als van een dataset met 60 kolommen, er slechts 6 moeten gesynthetiseerd worden om een voldoende gescramblede dataset te krijgen. Bovendien zal een generatief model met minder kolommen meestal ook accurater getraind kunnen worden, dus is het resultaat waarschijnlijk zelfs kwalitatief beter. Eventueel kan de synthetische dataset achteraf nog eens geshuffled worden om enige overgebleven structurele gelijkenis met de originele dataset te verbergen.
Rapportering en grafieken
De gescramblede dataset moet nog vergeleken worden met het origineel, om te verifiëren dat de procedure wel goed verlopen is en of er bepaalde parameters beter aangepast zouden kunnen worden. Het visualiseren van datasets is een uitdaging op zich, waarbij rekening moet worden gehouden met het type van variabele en de waarden die ze kan aannemen. Boxplots zijn vaak een goede keuze voor continue variabelen, en staafdiagrammen voor categorische variabelen. Daarbij moet aandacht worden besteed aan de assen, die overeen moeten komen om in een oogopslag te kunnen vergelijken. Het kan nodig zijn hier en daar extra te groeperen of aggregeren om grafieken van complexe categorische variabelen overzichtelijk te houden. Voor de verbanden tussen twee variabelen kan men verschillende vormen van bivariate plots, heatmaps en correlatiematrices benutten. Werkt men in Python dan zijn matplotlib en seaborn nuttige grafische libraries.
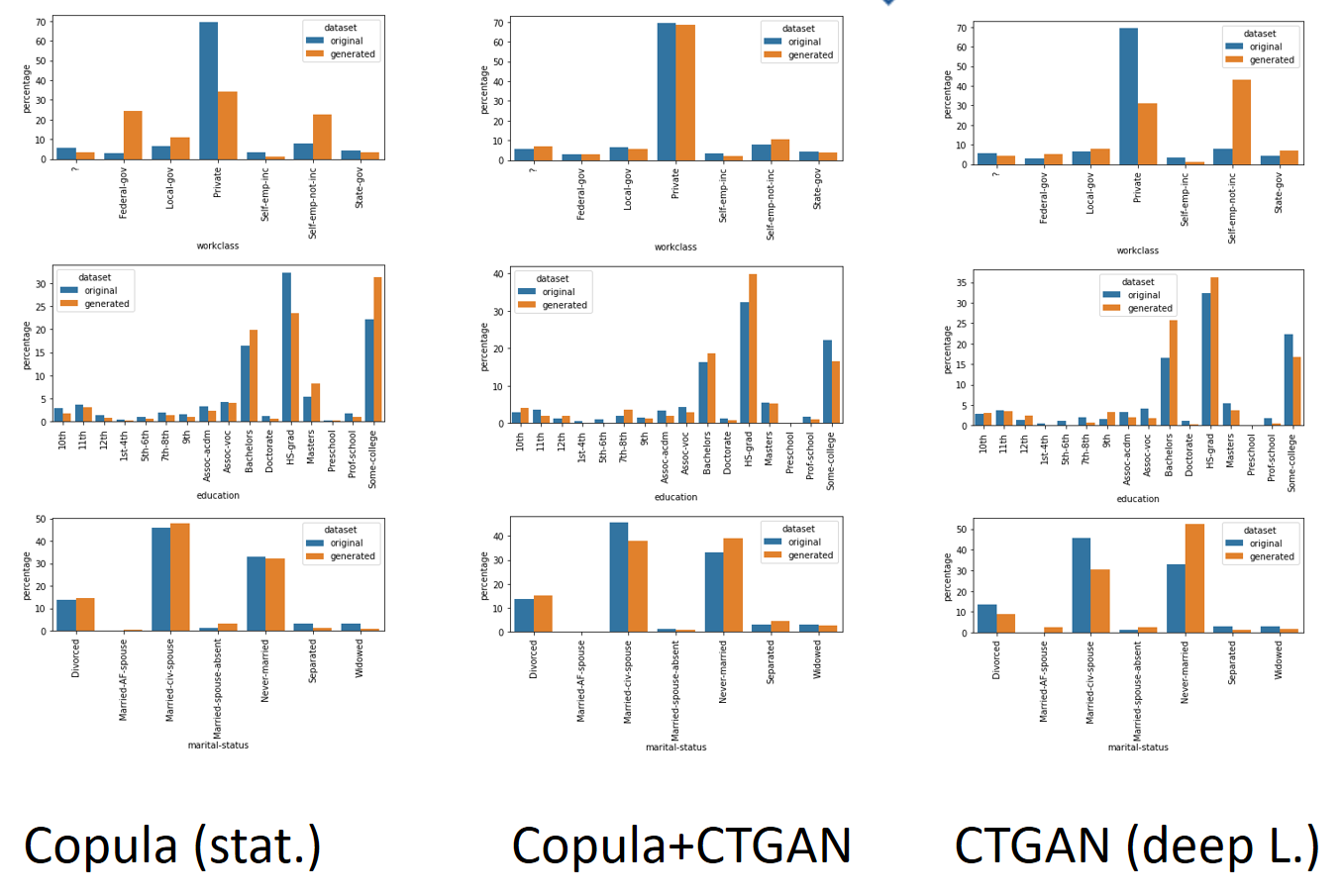
Conclusie
Met synthetische data generatoren hebben we een krachtige tool in handen om data scrambling te kunnen doen. We kunnen er bovendien meer mee dan enkel de gegevens door elkaar haspelen: desgewenst interpoleren ze ook tussen minimum- en maximumwaarden, of tussen datums, en zo kunnen ze ook fictieve gegevens genereren volgens dezelfde structuur als de originele dataset. Het aanmaken van een echt goede synthetische dataset vergt vaak een iteratieve aanpak, om het achterliggend generatief model te finetunen.
We merken in de praktijk dat er heel wat extra checks en balances komen kijken bij het werken met echte datasets. Het is zelden zo dat een generatief model gegenereerd uit een willekeurige dataset met default parameters, vanaf de eerste keer optimaal is. Met name erg ongelijke distributies zorgen voor problemen in het leerproces en voor statistische instabiliteit in het resulterende generatief model. Bij wijze van voorbeeld: als een dataset slechts 1 persoon bevat met een zeldzame ziekte, en het is toevallig een 43-jarige Limburger, dan riskeren we dat het systeem leert dat alle personen met deze ziekte per definitie 43-jarige Limburgers moeten zijn. Bovendien merken we dat we de beste resultaten bekomen als een dataset weinig variabelen heeft, en voor elke waarde van elke variabele veel datapunten (rijen, samples). Dit alles maakt dat we de beste resultaten vaak bekomen door zoveel mogelijk kolommen te bevriezen, en het aantal te scramblen kolommen te beperken tot het minimum noodzakelijke om het doel van scrambling te bereiken. Die oefening kan voor elke dataset anders zijn.
Een vraag die regelmatig terugkomt is: kunnen we dezelfde analytics op de dusdanig gescramblede / gesynthetiseerde dataset loslaten en leidt dat dan tot dezelfde conclusies? Het antwoord is: het hangt ervan af hoe diep je wilt gaan. De structuur van de gegevens wordt in het generatief model immers approximatief aangeleerd. Daarbij merken we:
- De statistieken en verdeling van individuele variabelen (minimum, maximum, gemiddelde etc.) blijven meestal relatief goed behouden,
- De verbanden tussen twee variabelen (correlatie etc.) blijven matig behouden, en hoe gelijkmatiger en stabieler deze variabelen zijn verdeeld hoe beter dat dat lukt,
- De verbanden tussen meerdere variabelen (regressies etc.) blijven relatief slecht behouden of gaan verloren.
Voor complexe analyses zijn scrambled of synthetische data dus zeker geen drop-in replacement voor de echte data. Ze zijn wel erg nuttig voor het testen of ontwikkelen van data processing scripts of analyse-pipelines, omdat we wel een goed beeld hebben van welke waarden er allemaal voorkomen en in welk bereik deze vallen.
We hebben nog heel wat andere potentiële struikelblokken die we in de praktijk kunnen tegenkomen niet besproken. Er kunnen afhankelijkheden bestaan tussen rijen – bijvoorbeeld, een tabel die verschillende records bevat per persoon. Er kunnen ook verbanden zijn in de tijd – bijvoorbeeld datasets die bestaan uit opeenvolgende kwartalen, of datasets waarin de datums die voorkomen alleen maar werkdagen zijn en nooit weekenddagen, wat maakt dat je niet zomaar eender welke datum kan synthetiseren. Een dataset kan ook bestaan uit meerdere tabellen die met elkaar verbonden zijn. Zulke complexere problemen zijn mogelijk nog voer voor een vervolg-artikel later dit jaar.
______________________
Dit is een ingezonden bijdrage van Joachim Ganseman, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.
Leave a Reply