Het wordt steeds makkelijker om grote hoeveelheden persoonsgegevens te verzamelen en te verwerken. Dit creëert enerzijds heel wat opportuniteiten, zoals het doen van statistische analyses ter verbetering van de gezondheidszorg. Tegelijkertijd moet echter rekening gehouden worden met de privacy van de burger, wat een juridische basis vindt in de GDPR. Met traditionele aanpakken en technologieën kan het omslachtig tot zelfs onmogelijk zijn om functionele noden en privacyvereisten met elkaar in balans te brengen. De behoefte naar meer geavanceerde technologieën groeit dan ook. Privacybevorderende technologieën, of privacy-enhancing technologies (PETs), kunnen hier een uitweg bieden en laten met behulp van cryptografie en/of statistiek zaken toe die zelfs intuïtief onmogelijk kunnen lijken.
Doordat PETs een elegant alternatief kunnen bieden op meer omslachtige traditionele aanpakken, kan hun gebruik bovendien leiden tot een vereenvoudiging van bestaande procedures, niet alleen op technisch, maar ook op juridisch vlak. In deze gevallen worden de procedures dan ook sneller en goedkoper, terwijl ook de veiligheidsrisico’s afnemen. Een aantal redenen daartoe kunnen zijn:
- Een reductie van het aantal informatiestromen
- Een reductie van het aantal TTPs (Trusted Third Parties)
- Een reductie van het vertrouwen dat in TTPs gelegd dient te worden
- Maatwerk maakt plaats voor een meer uniforme aanpak.
Dit artikel wil een leidraad zijn bij het selecteren van de juiste PET. Wel moet beseft worden dat dit maar een selectie van PETs en use cases is, dat niet alle PETs vandaag volledig matuur zijn en dat steeds nagedacht moet worden over de correcte toepassing ervan. Dit artikel is een aanzet en zal, met voortschrijdend inzicht en voortschrijdende technologische evoluties in de toekomst verder verfijnd worden.
In het buitenland werden reeds gelijkaardige, uitgebreidere oefeningen gedaan. We verwijzen graag onder meer naar Privacy Enhancing Technologies Adoption Guide door het Centre for Data Ethics and Innovation, naar Protecting privacy in practice van The Royal Society en naar het meer academische A taxonomy for privacy enhancing technologies door Johannes Heurix, Peter Zimmermann, Thomas Neubauer en Stefan Fenz.
PETs selectieboom
Onderstaande figuur geeft onze eigen, adviserende PET-selectieboom weer, die focust op behoeften vanuit de publieke sector. De boom heeft (momenteel) acht bladeren, die elk een groep van use cases voorstellen. Elk van deze bladeren wordt onder de figuur toegelicht. Voor details over de PETS zelf voorzien we doorverwijzingen/links.
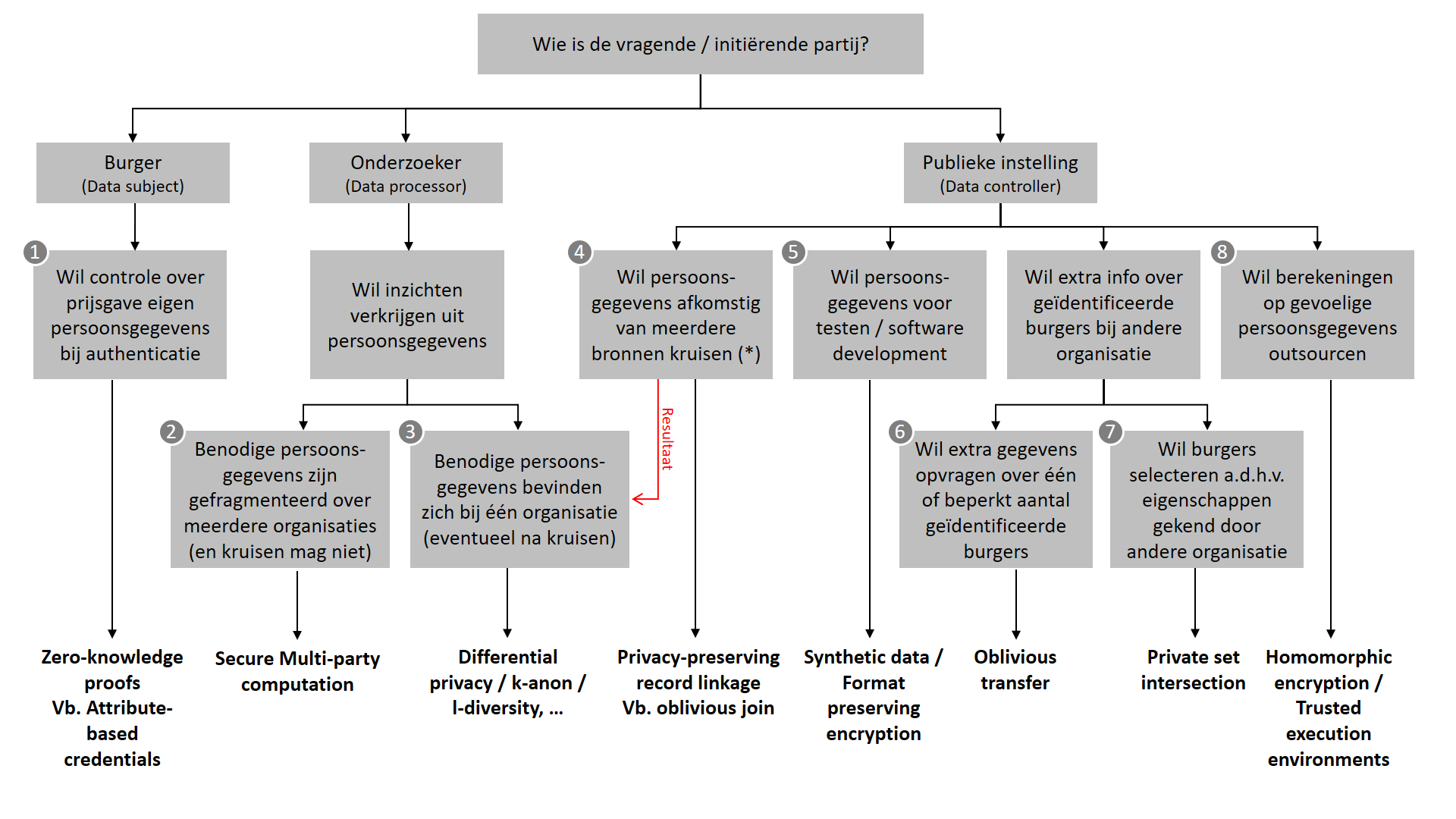
1. Burger wil controle over prijsgave eigen persoonsgegevens bij authenticatie
De burger moet zich geregeld, zowel online als offline, authentiseren, wat wil zeggen dat ze bepaalde eigenschappen over haarzelf dient te bewijzen. Een aantal voorbeelden:
- Om alcohol te kopen moet ze bewijzen dat zij volwassen is
- Om een auto te huren moet ze bewijzen dat ze over een rijbewijs van het juiste type beschikt en verzekerd is.
- Om recht te hebben op korting bij een museumbezoek, moet ze bewijzen dat ze in die bepaalde gemeente woont.
In elk van voorgaande voorbeelden wordt in de praktijk m.b.v. de identiteitskaart en/of andere documenten veel meer informatie prijsgegeven dan strikt noodzakelijk. Om alcohol te kopen moet de burger bijvoorbeeld enkel kunnen bewijzen dat zij volwassen is. Om korting te krijgen in het museum volstaat te bewijzen dat haar postcode behoort tot de postcodes van die gemeente. Haar exacte geboortedatum, haar identiteit, exacte postcode, geslacht en andere informatie op de eID doen er niet toe en blijven vanuit een privacy-standpunt beter verborgen. Dergelijke selectieve prijsgave van attribuutinformatie wordt mogelijk dankzij zero-knowledge proofs, wat we terugvinden in self-sovereign identity (SSI) oplossingen, zoals attribute-based credentials. Ook zijn er oplossingen, zoals Sovrin, die zero-knowledge proofs integreren in blockchain technologie.
2. Onderzoeker wil inzichten verkrijgen uit persoonsgegevens die gefragmenteerd zijn over meerdere organisaties.
Dit kan gaan over een combinatie van gezondheidsdata, socio-economische data, etc. die gefragmenteerd zijn over meerdere organisaties. Gegeven de huidige stand der techniek, geven we er de voorkeur aan om eerst de data te kruisen (zie puntje 4), en vervolgens ter beschikking te stellen van de onderzoeker (zie puntje 3). Indien dit kruisen (samenbrengen van gegevens) omwille van strikte privacy- of andere redenen echt niet mogelijk is, moeten we echter terugvallen – als laatste redmiddel – op een andere aanpak.
Bij die andere aanpak worden de scripts/queries van de onderzoeker gedistribueerd uitgevoerd, wat wil zeggen dat de verschillende participanten met elkaar interageren, zonder een centrale partij. De (persoons)gegevens beheerd door de verschillende organisaties worden daarbij op geen enkel moment prijsgegeven. De onderzoeker krijgt enkel het resultaat van zijn script/query te zien en voor de rest lekken er geen persoonsgegeven, noch naar de onderzoeker, noch naar andere data bronnen.
Dit is in theorie mogelijk met secure multiparty computation (SMC). Vandaag is deze aanpak eerder experimenteel en blijft het doorgaans nog erg moeilijk om dit ook in de praktijk om te zetten.
3. Onderzoeker wil inzichten verkrijgen uit persoonsgegevens die zich bij één organisatie bevinden.
De onderzoeker die inzichten wil bekomen uit gezondheidsdata, socio-economische data, etc. van burgers kan niet zomaar toegang gegeven worden tot de ruwe geïdentificeerde persoonsgegevens. Het vervangen van de identifiers door codes (pseudoniemen) zal niet volstaan, gezien records via combinaties van attribuutwaarden te herleiden kunnen zijn naar unieke personen. Er zijn een aantal benaderingen om hiermee om te gaan, waaronder de volgende:
- De onderzoeker krijgt slechts toegang tot een vervaagde (gegeneraliseerde) versie van de dataset. Daarbij gaat onvermijdelijk informatie verloren: de data wordt in het beste geval minder nuttig maar blijft wel bruikbaar, terwijl de identificatierisico’s significant dalen. In het slechtste geval wordt de data compleet nutteloos indien we de identificatierisico’s aanzienlijk willen reduceren. De voornaamste technologieën hiervoor zijn k-anonymity en l-diversity.
- De onderzoeker krijgt geen toegang tot de data zelf, maar kan wel queries uitvoeren. Het resultaat van de query wordt vervaagd voor het aan de onderzoeker doorgegeven wordt. Gezien het voorzien van ruis later gebeurt dan in voorgaande bullet zal het effect op het uiteindelijk resultaat beperkter zijn. Deze aanpak steunt op differential privacy.
- De scripts/queries van de onderzoeker worden in een beveiligde omgeving uitgevoerd en de onderzoeker krijgt enkel toegang tot het uiteindelijke resultaat. Dit vereist geen PET, maar leek ons desondanks het vermelden waard.
4. Publieke instelling wil persoonsgegevens afkomstig van meerdere bronnen kruisen
Dit kan noodzakelijk zijn voor de uitvoering van de opdracht van de publieke instelling zelf, of het kan gebeuren naar aanleiding van een specifieke vraag van een onderzoeker. In dit tweede geval krijgt de onderzoeker in een volgende stap op een gecontroleerde manier toegang tot de gekruiste persoonsgegevens (zie puntje 3).
Cruciaal bij het kruisen is dat het resultaat enkel de minimaal noodzakelijke gepseudonimiseerde gegevens bevat en dat er verder geen ongewenste lekken van persoonsgegevens zijn. Traditionele aanpakken zijn inefficiënt, en daardoor traag en duur.
Privacy-preserving record linkage technieken trachten hier een antwoord op te bieden, al focussen ze doorgaans op situaties waarbij er geen gedeelde burger identifiers zijn – zoals het rijksregisternummer – en er aan string matching gedaan wordt, bijvoorbeeld van – mogelijks verschillend gespelde – persoonsnamen in combinatie met een geboortedatum. Oblivious join – een innovatie van Smals Research – gaat wel uit van gedeelde identifiers en kreeg vorm op basis van businessvereisten in de context van de Belgische gezondheidszorg en sociale zekerheid.
5. Publieke instelling wil persoonsgegevens voor testen / software development
Bij het ontwikkelen en testen van systemen kan de verleiding bestaan om met echte persoonsgegevens te werken, wat uiteraard risico’s inhoudt. In werkelijkheid volstaan misschien gegevens die daarop lijken, maar geen echte persoonsgegevens zijn. Een dergelijke dataset noemt men synthetic data. Het bewaart de structuur van de individuele records, maar ook bepaalde statistische eigenschappen van de gehele dataset.
Indien de systemen in test- of ontwikkelomgevingen moeten interageren met systemen in productie, zal synthetic data alleen vaak niet volstaan gezien de overeenkomsen (vb. gelijk rijksregisternummer) tussen de interne (synthetische) data en de echte data op de externe systemen vernietigd is. In dat geval kan format preserving encryption als een schil rond de test- of ontwikkelomgeving helpen om rijksregisternummers en andere ‘echte’ persoonsgegevens afkomstig van systemen in productie die de schil binnenkomen om te zetten in pseudoniemen die dezelfde structuur hebben als rijksregisternummers. Daarbij kunnen eventueel ook bepaalde eigenschappen behouden blijven binnen de schil (zodat bijvoorbeeld een meerderjarige een meerderjarige blijft). Ook de omgekeerde operatie is mogelijk, waarbij bijvoorbeeld fake-rijksregisternummers (dus eigenlijk pseudoniemen) die binnen de schil bestaan terug omgezet worden in het echte rijksregisternummer wanneer er vanuit de test- of ontwikkelomgeving een vraag gesteld wordt aan een extern systeem in productie over de betrokken burger.
6. Publieke instelling wil extra gegevens opvragen over één of beperkt aantal geïdentificeerde burgers
Er kunnen vanuit justitie onderzoeken gevoerd worden naar specifieke burgers, bijvoorbeeld in het kader van terrorismebestrijding of fraudeopsporing. Persoonsgegevens die beheerd worden door derden moeten daarbij opgevraagd kunnen worden. Denk daarbij bijvoorbeeld aan metagegevens over telefoongesprekken gekend door telecomoperatoren of aan de verschillende officiële verblijfplaatsen doorheen de tijd, wat gekend is door het Rijksregister.
Dergelijke data opvragen bij een andere (private of publieke) organisatie over een specifieke burger is op zich geen uitdaging, althans niet op technisch vlak. Helaas lekt de vragende organisatie daarbij de identiteit van de betrokken burger naar de aanleverende organisatie. Dit brengt zowel de privacy van de betrokkenen als de confidentialiteit van het onderzoek in het gedrang. Dit is op te lossen met behulp van oblivious transfer.
7. Publieke instelling wil burgers selecteren a.d.h.v. eigenschappen gekend door andere organisatie
Stel dat een wetshandhavingsdienst A wil weten welke van de verdachten die het volgt ook door wetshandhavingsdienst B met hoge prioriteit gevolgd worden. Een naïeve aanpak is dat B een lijst bezorgt aan A met alle verdachten die het met hoge prioriteit volgt en dat A dan eenvoudigweg de doorsnede berekent van haar eigen verdachtenlijst met die van B. B geeft zo echter veel te veel gevoelige persoonsgegevens aan A, dat inderdaad de volledige lijst van personen te weten komt die door B met hoge prioriteit gevolgd worden, terwijl de doorsnede volstaat. Dit wordt opgelost met behulp van private set intersection (PSI).
8. Publieke instelling wil berekeningen op gevoelige persoonsgegevens outsourcen
Bij overwegingen om opslag van en berekenen op gevoelige persoonsgegevens te outsourcen, typisch naar de cloud, is een garantie dat de (cloud) provider zelf op geen enkel moment toegang tot de data zelf kan verkrijgen een noodzaak.
De sterkste garanties worden geleverd door Trusted execution environments (TEEs) en, meer nog, door homomorphic encryption (HE).
- Een TEE biedt een door hardware beveiligde, afgeschermde omgeving aan op een processor, waarbinnen de confidentialiteit en integriteit van de data en correcte uitvoering van code wordt gewaarborgd. TEE blijft helaas gevoelig voor side-channel attacks.
- HE laat toe om berekeningen te doen op de vercijferde data in plaats van op de data zelf. HE is vandaag doorgaans erg inefficiënt. In het bijzonder blijkt het erg lastig te zijn om ondersteuning te voorzien voor o.a. vergelijkingen condities en array lookups.
Conclusies
Privacy-enhancing technologies (PETs) zijn vandaag vaak nog emerging, waarmee we bedoelen dat de ontwikkeling tot enterprise-ready producten nog bezig is en/of dat praktische toepassingen nog zeldzaam zijn. Toch bieden ze heel wat opportuniteiten, zeker in een publieke sector die de privacy van de burger au serieux neemt. In de komende jaren zullen we dan ook ongetwijfeld een boom in de uptake van deze technologieën zien. Het lijkt uw auteur logisch dat de publieke sector hier een voortrekkersrol in speelt.
De PETs die in dit artikel vermeld worden zijn natuurlijk niet de enige. Bovendien moeten we de meeste hier vermeldde PETs eerder zien als afzonderlijke categorieën van PETs. Zo is oblivious transfer reeds een levend onderzoeksdomein op zich, waarbinnen heel wat verschillende protocollen met uiteenlopende eigenschappen voorgesteld werden en worden.
Smals Research heeft gelukkig reeds heel wat kennis in huis, met zelfs eigen innovaties en implementaties. Ook daarbuiten wordt hard aan de weg getimmerd, onder meer binnen de academische wereld, waarmee Smals Research goede contacten onderhoudt.
Ten slotte geven we nog mee dat PETs ook voor heel wat andere — soms verrassende — toepassingen kennen. Zo kan je met private set intersection (PSI) testen of je paswoord gelekt is, zonder je paswoord zelf prijs te geven. Of je kunt ermee nagaan of je een erfelijke ziekte hebt, zonder je genetische informatie zelf prijs te geven.
We kijken er alvast naar uit om samen met u na te gaan hoe PETs kunnen helpen bij het realiseren of optimaliseren van uw concrete use case.
Dit is een ingezonden bijdrage van Kristof Verslype, cryptograaf bij Smals Research. Het werd geschreven in eigen naam en neemt geen standpunt in namens Smals.
Leave a Reply