[FR]
-

Anomalies & Transactions Management System (ATMS) : enjeux, concepts, réalisations et travail en cours
Cet article de blog a pour objet d’introduire le concept d’ATMS (Anomalies & Transactions Management System) : après en avoir montré l’importance fondamentale dans le cadre du « back tracking » récemment évoqué dans un article de blog de mai 2018, nous en rappelons les principales références ; nous en évoquons ensuite les concepts généralisables, le ROI, l’originalité ainsi
-

Cognitive Search: l’évolution des moteurs de recherche d’entreprise
« Data is the New Gold » : voici une citation que l’on a maintes fois vue et entendue quand il s’agit de parler de science des données ou d’intelligence artificielle. Ce blog se concentre sur les données non structurées et textuelles et une des nouvelles techniques qui permettent d’extraire « l’or » contenu dans celles-ci. Les entreprises et organisations
-
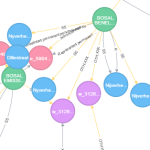
Sept (bonnes) raisons d’utiliser une Graph Database
Ces dernières années, les bases de données orientées graphes (ou Graph DB, présentées dans nos blogs précédents [1, 2]), et plus généralement les bases de données NoSQL, ont énormément gagné en popularité et en visibilité. Pour preuve, Neo4j, le leader actuel du marché des Graph Databases, apparaît depuis 2014 dans le “Magic Quadrant for Operational
-
Le marché du travail salarié en Belgique : une analyse réseau (partie 3/3)
Dans le premier article de notre série consacrée à l’analyse réseau du marché du travail en Belgique, nous avons présenté les données constituant le graphe (ou réseau) de Dimona, sur lequel se base cette série de trois articles, et montré quelques métriques, permettant par exemple d’évaluer le nombre de personnes actives à un moment donné,
-
Le marché du travail salarié en Belgique : une analyse réseau (partie 2/3)
Dans notre article précédent, nous avons montré quelques éléments d’analyse réseau appliquée à la base de données “Dimona”, qui recense, en Belgique, les relations de travail entre tous les employeurs et leurs employés. Nous y avons principalement analysé la notion de degré, permettant de voir le nombre d’employeurs par employé, et le nombre d’employés par
-
Le marché du travail salarié en Belgique : une analyse réseau (partie 1/3)
Le marché du travail nécessite partout une attention constante de la part des autorités. Cette attention ne peut se faire qu’en ayant une connaissance descriptive approfondie du secteur, raison pour laquelle de nombreuses analyses statistiques sont faites en permanence dans ce domaine (ONSS, Statbel, SPF Emploi, Actiris…). Si ces analyses sont incontournables, nous avons montré
-

Data Quality & « back tracking » : depuis les premières expérimentations à la parution d’un Arrêté Royal
Thomas Redman compare une base de donnée à un lac, alimenté par des flux aquatiques continus. La métaphore illustre l’approche qui sera évoquée dans ce blog en vue d’améliorer la qualité des données. 1. Les enjeux de la qualité des données : rappel et exemple En effet, nettoyer “à l’infini” le fond du lac (via des algorithmes de
-
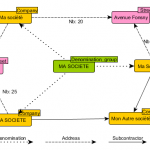
Gérer les doublons dans une Graph Database
Dans nos blogs précédents (1, 2, 3, 4), nous avons mis en évidence le fait que les structures de graphes étaient très adaptées à la recherche de comportement frauduleux. En étant plongés quotidiennement dans des données issues de diverses bases de données officielles, nous sommes également confrontés en permanence à la présence d’une grande quantité
-

Portal vs message broker – 2 approches complémentaires
Dans un récent projet impliquant de nombreux partenaires devant s’échanger des données, le débat broker versus portal (ou portail en français) â fait l’objet de nombreuses discussions. Avec, comme à l’habitude, sur des sujets aussi stratégiques, une tendance malheureuse à polariser les discussions. Cette polarisation n’a pas lieu d’être : chacune de ces approches a sa part
-

La préservation du patrimoine scientifique à l’heure du numérique (31/01/2018, ULB)
Rencontre « Data quality » FNRS-ULB-Smals le 31/01/2018 à l’Université libre de Bruxelles La prochaine réunion du groupe de contact FNRS « Analyse critique et amélioration de la qualité de l’information numérique » se tiendra le mercredi 31 janvier 2018 à 14h00 à l’Université libre de Bruxelles (auditoire AY2.108, bâtiment A, campus du Solbosch). Téléchargez les slides d’Isabelle Boydens (1MB) et d’Anthony Leroy (16MB).
Keywords:
analytics Artificial intelligence big data blockchain BPM chatbot cloud computing cost cutting cryptography data center data quality development EDA egov Event GIS Information management Machine Learning Managing IT costs methodology Mobile Natural Language Processing Open Source Privacy Productivity Security social software design software engineering standards